“Datawhale X 魔搭 AI夏令营”-AIGC文生图方向Task1笔记
W__hui 2024-08-19 11:31:02 阅读 93
前言
就自己学习过程对于Datawhale AI的夏令营第四期魔搭-AIGC文生图方向,做了个初级版教程,供小白参考,后期有机会也会通过自己的学习总结相关知识教程,期待和大家一起相互学习,共同进步!
正文
第一步:报名参加赛事!
点击赛事链接:
:天池平台,提交队伍名称+联系方式
登录后直接报名即可!
报名赛事!(点击即可跳转)
赛事链接:https://tianchi.aliyun.com/competition/entrance/532254

第二步:方法1;启动魔塔Notebook!(注意是GPU环境)
链接:链接:https://www.modelscope.cn/my/mynotebook/authorization


方法2;可使用魔搭的免费Notebook实例
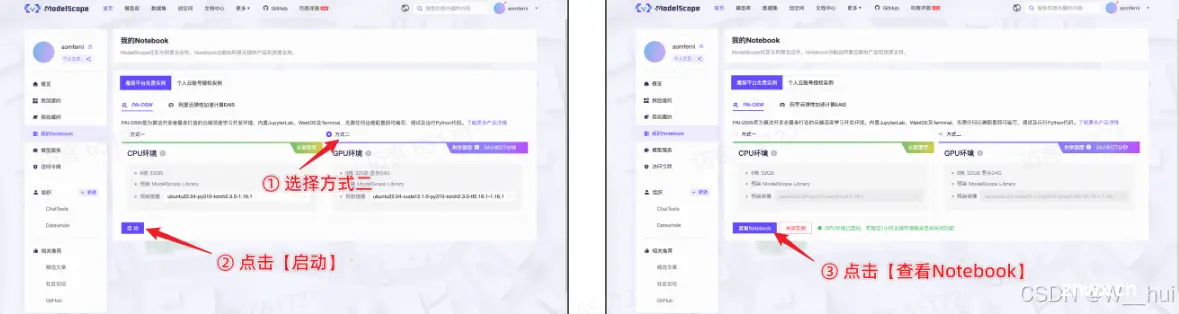
第三步:跑通baseline
下载baseline文件
我们首先粘贴命令然后回车执行,这样就可以得到baseline文件,需要等待一段时间。
git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors.git

拉取baseline后,可以在右侧文件中看到kolor文件夹,双击进入可以看到后缀.ipyhb的baseline文件,点击打开。

接下来执行运行环境的代码块,我们需要安装 Data-Juicer 和 DiffSynth-Studio
Data-Juicer:数据处理和转换工具,旨在简化数据的提取、转换和加载过程
DiffSynth-Studio:高效微调训练大模型工具

有些时候因为网络及代理的问题,环境的安装容易缺漏,建议多执行几次,代码不会重复安装
安装完成后,重启kernel,不重启容易爆显存影响baseline运行

接下来我们继续依次执行下载数据集、数据处理

最后我们加载我们所微调的模型并进行输出
from diffsynth import ModelManager, SDXLImagePipeline
from peft import LoraConfig, inject_adapter_in_model
import torch
def load_lora(model, lora_rank, lora_alpha, lora_path):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
init_lora_weights="gaussian",
target_modules=["to_q", "to_k", "to_v", "to_out"],
)
model = inject_adapter_in_model(lora_config, model)
state_dict = torch.load(lora_path, map_location="cpu")
model.load_state_dict(state_dict, strict=False)
return model
# Load models
model_manager = ModelManager(torch_dtype=torch.float16, device="cuda",
file_path_list=[
"models/kolors/Kolors/text_encoder",
"models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors",
"models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors"
])
pipe = SDXLImagePipeline.from_model_manager(model_manager)
# Load LoRA
pipe.unet = load_lora(
pipe.unet,
lora_rank=16, # This parameter should be consistent with that in your training script.
lora_alpha=2.0, # lora_alpha can control the weight of LoRA.
lora_path="models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt"
)
调整prompt,设置你想要的图片风格,依次修改8张图片的描述
正向描述词:你想要生成的图片应该包含的内容
反向提示词:你不希望生成的图片的内容

提示词也有一些讲究,比如优质的提示词、提示词的排序(越靠前的提示词影响比重越大)、提示词书写策略、Embedding 模型介入。这些对出图效果也同样重要。
下面的代码块按照功能主要分成这几类
使用Data-Juicer处理数据,整理训练数据文件
使用DiffSynth-Studio在基础模型上,使用前面整理好的数据文件进行训练微调
加载训练微调后的模型
使用微调后的模型,生成用户指定的prompt提示词的图片

到这里,微调训练和模型出图已经全部完成。
微调结果上传魔搭
链接:https://www.modelscope.cn/models/create
移动结果文件
创建terminal,粘贴如下命令,回车执行
mkdir /mnt/workspace/kolors/output & cd cp /mnt/workspace/kolors/models/lightning_logs/version_0/checkpoints/epoch\=0-step\=500.ckpt /mnt/workspace/kolors/output/ cp /mnt/workspace/kolors/1.jpg /mnt/workspace/kolors/output/

下载结果文件
创建并上传模型所需内容 点击魔搭链接,创建模型,中文名称建议格式:队伍名称-Kolors-xxxxx
双击进入output文件夹,分别下载两个文件到本地


最后,提交打卡就结束了!

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。