Datawhale AI夏令营第四期魔搭- AIGC文生图方向 task01笔记
Flyinggg_love 2024-08-17 08:01:03 阅读 52
目录
分任务1:跑通baseline
第一步——搭建代码环境
第二步——报名赛事
第三步——在魔搭社区创建PAI实例
分任务2:相关知识学习以及赛题理解
赛题理解:
文生图基本认识:
1. Diffusion Model(扩散模型)
2. LDMs(潜空间扩散模型)
3.基础文生图模型优化的三大方向
4.LORA(Low-Rank Adaptation) ——轻量级大模型微调方法
附:
DataWhale开源组织网站主页:Datawhale
DataWhaleAI夏令营第四期AIGC方向学习手册:Doc
赛事链接:可图Kolors-LoRA风格故事挑战赛_创新应用大赛_天池大赛-阿里云天池的赛制
分任务1:跑通baseline
第一步——搭建代码环境
1. 进入阿里云免费试用区,免费使用算力时:
阿里云社区

https://free.aliyun.com/?spm=5176.14066474.J_4683019720.1.8646754cugXKWo&scm=20140722.M_988563._.V_1&productCode=learn
2. 登录or注册自己的阿里云账号:
3. 点击立即试用
领取成功之后关闭页面即可
4 .进入魔搭社区授权
魔搭社区
https://www.modelscope.cn/my/mynotebook/authorization
第二步——报名赛事
可图Kolors-LoRA风格故事挑战赛
https://tianchi.aliyun.com/competition/entrance/532254
第三步——在魔搭社区创建PAI实例
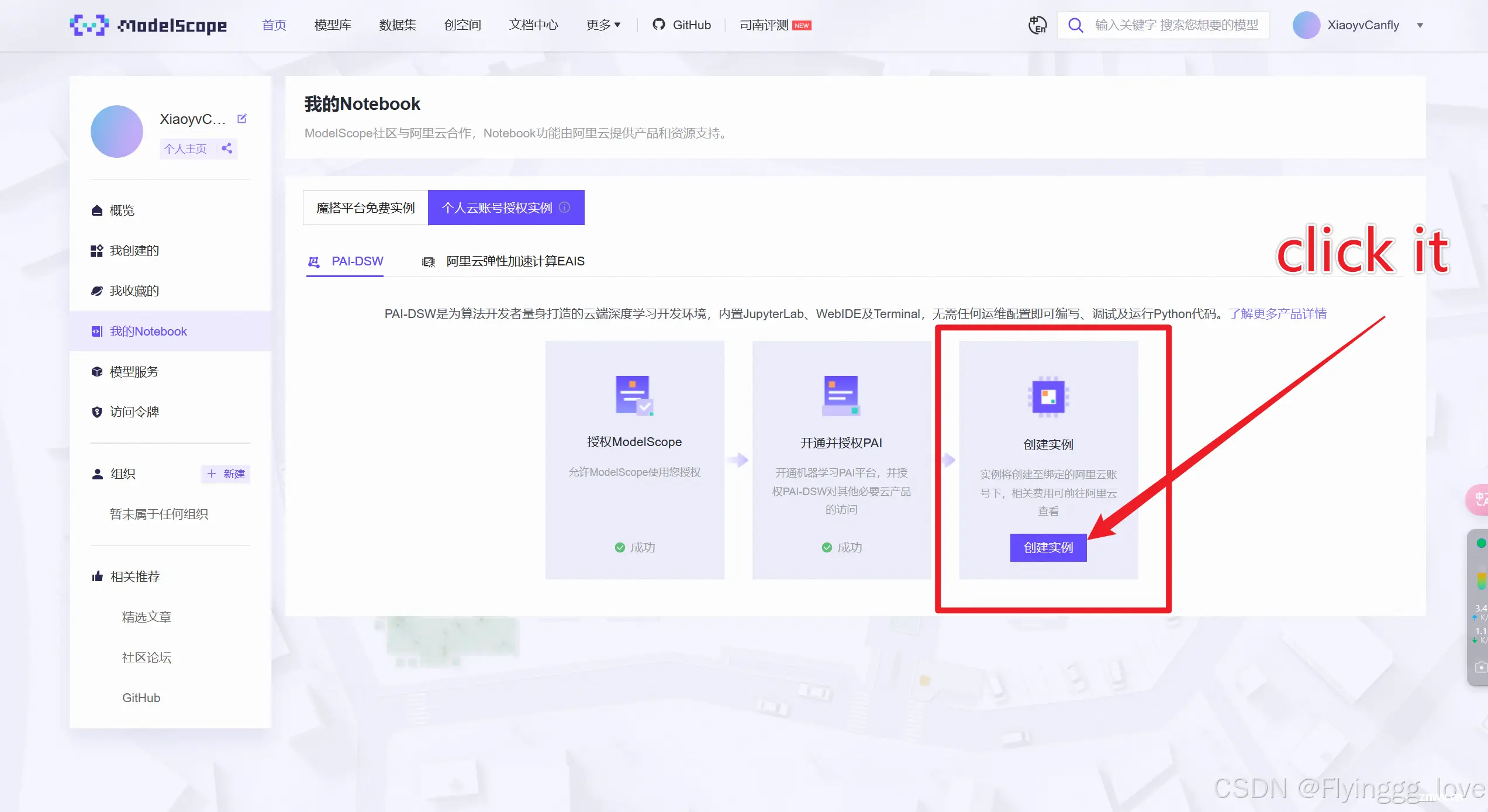
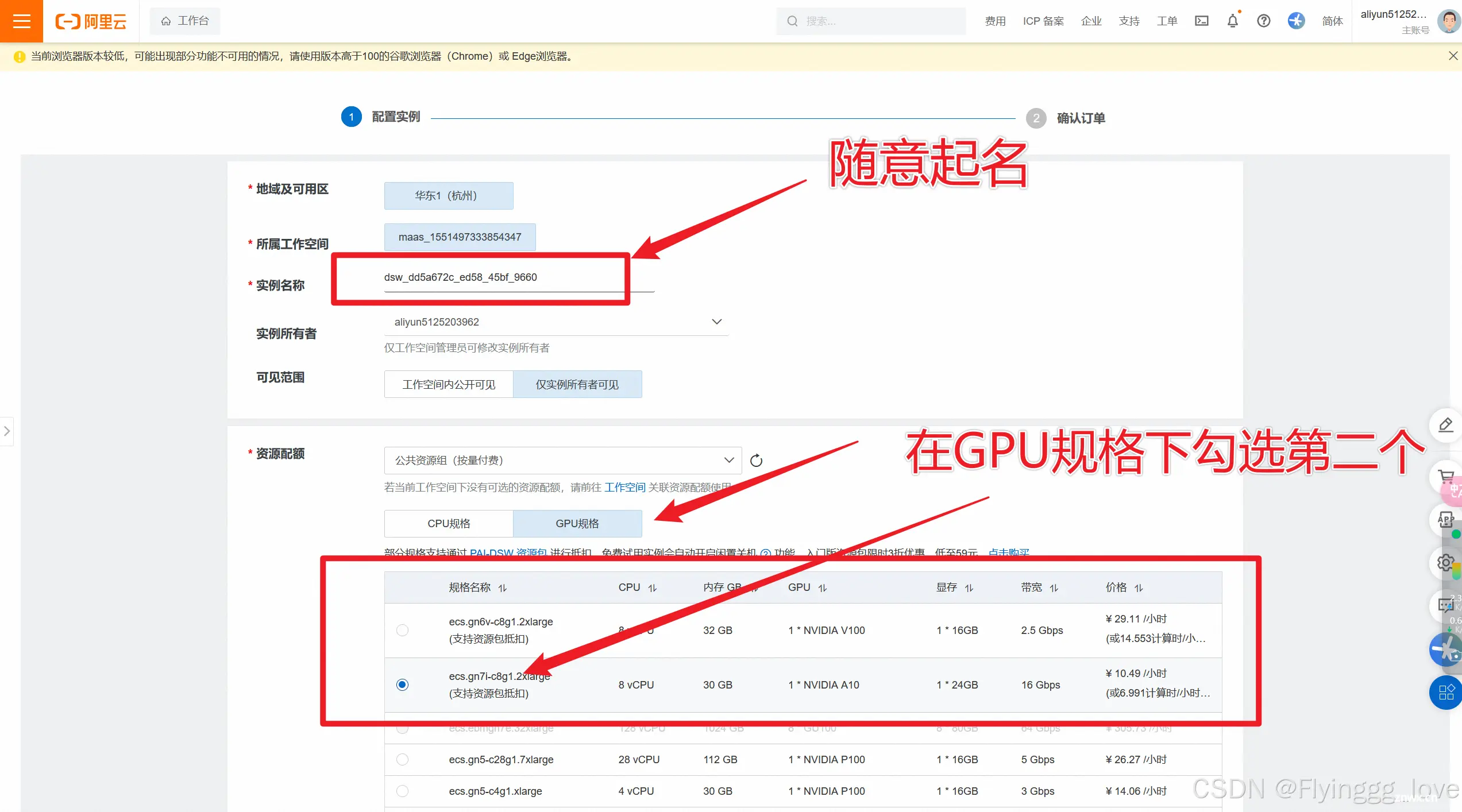

创建完成之后返回魔搭社区,如下图所示,就已经绑定好实例了:
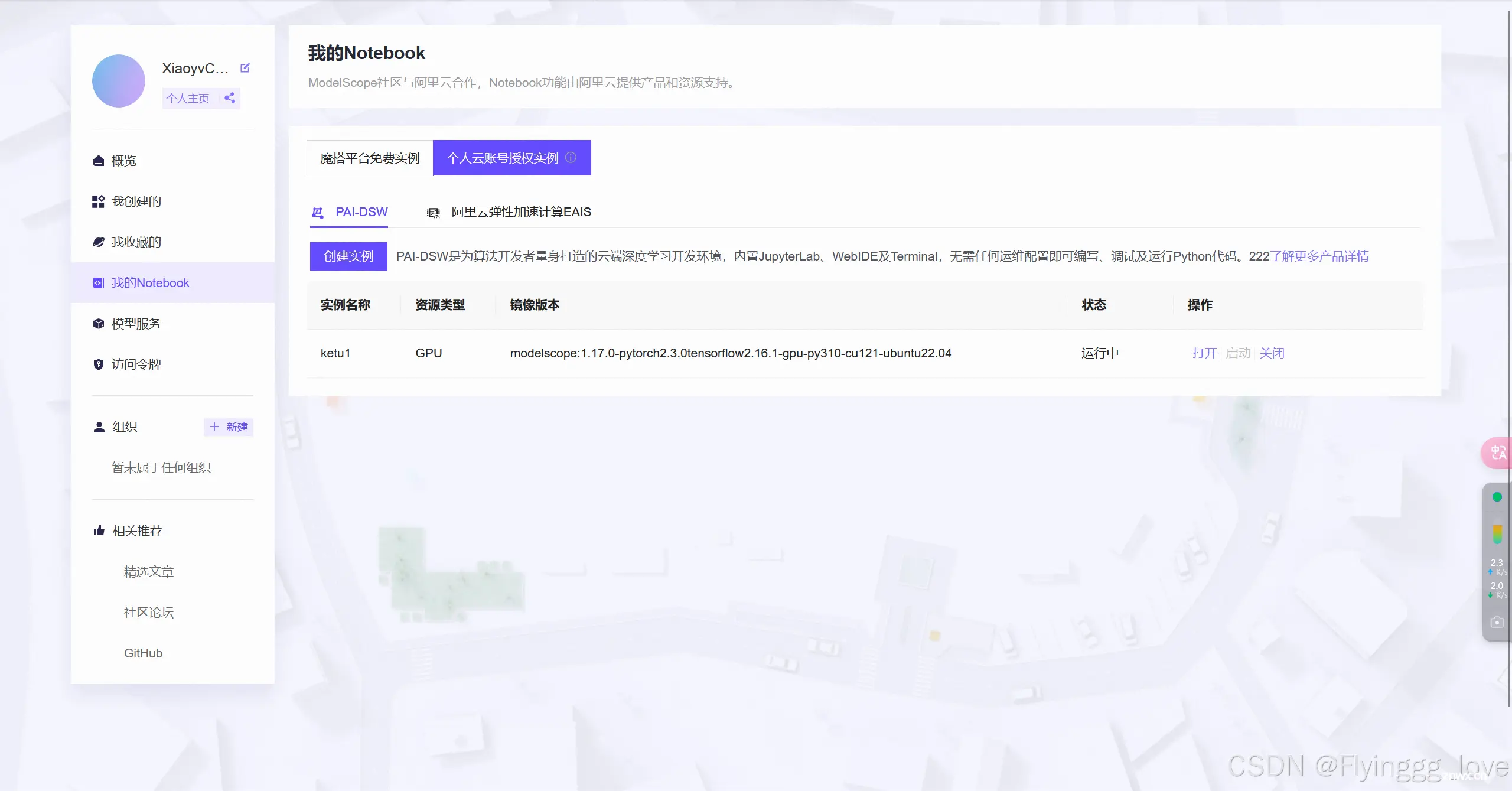
点击打开,因为我这里点击打开没有反应,索性就使用了第二种方法——魔搭的免费notebook
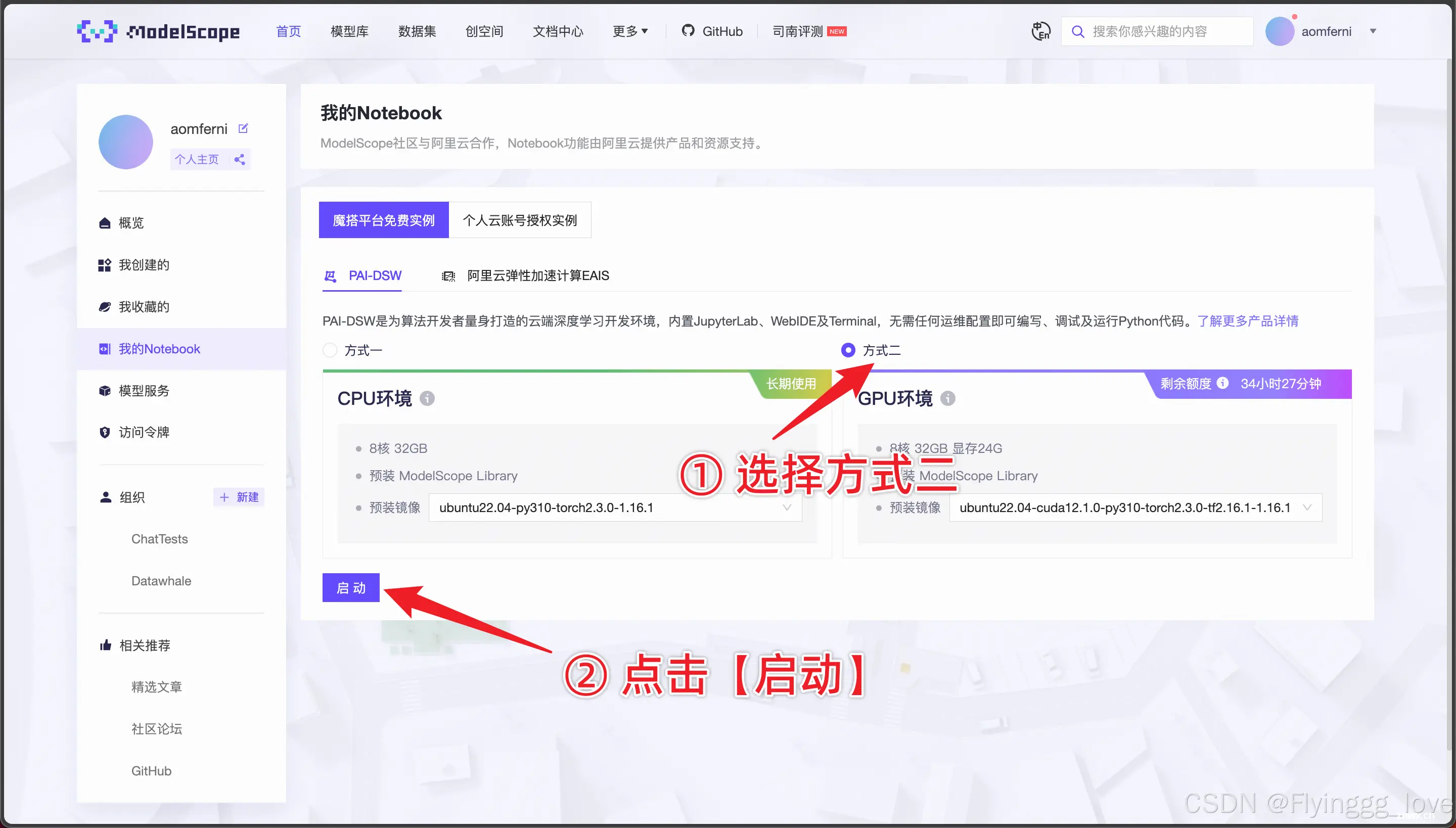
那么实际上,可能是因为魔搭社区的流量限制,使得访问速度很慢,那么我们也可以通过阿里云官网进入实例,
step1:进入阿里云官网
Step2:进入控制台
step3:左侧栏中有DSW这个选择
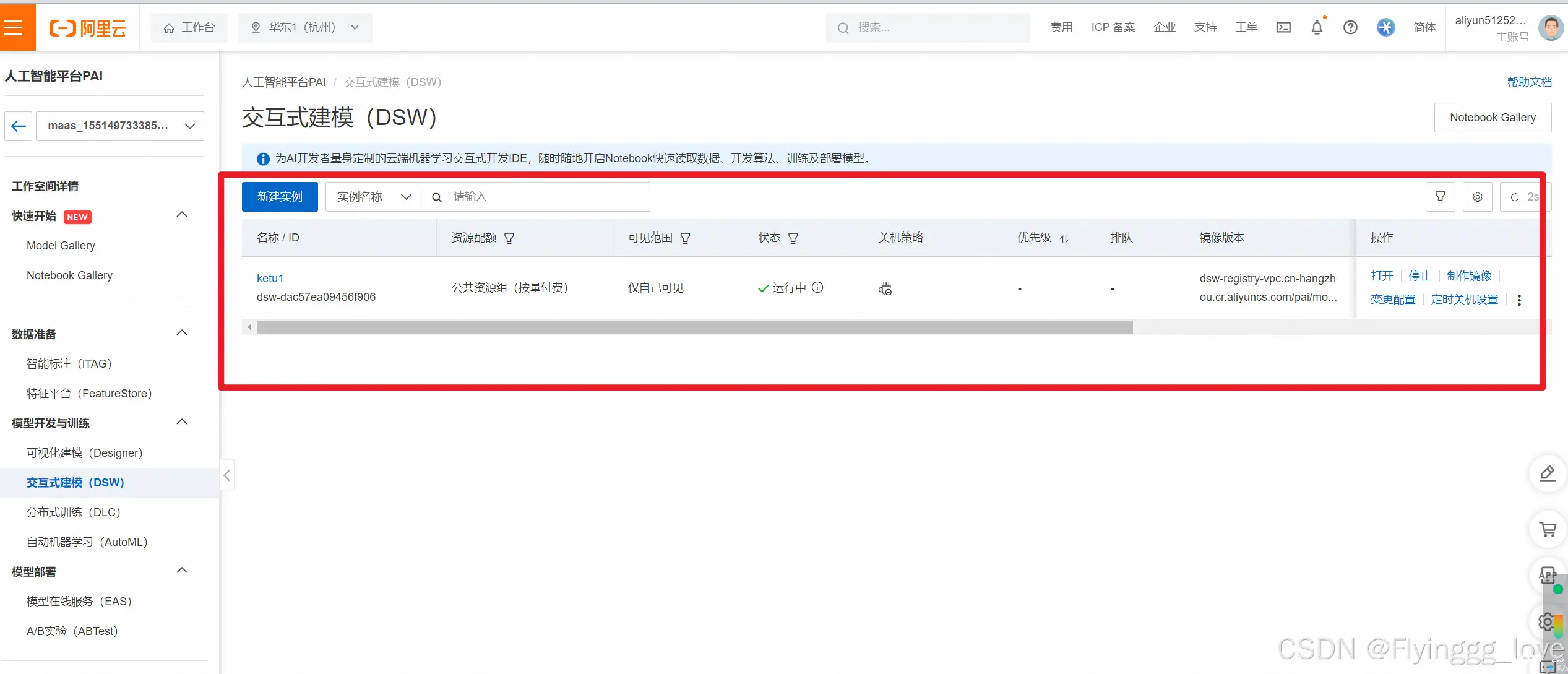
step4:在这里点击打开,进入实例,速度比魔搭社区要快
总之,无论是从A,B还是C进入,都是为了进入我们的notebook实例中。
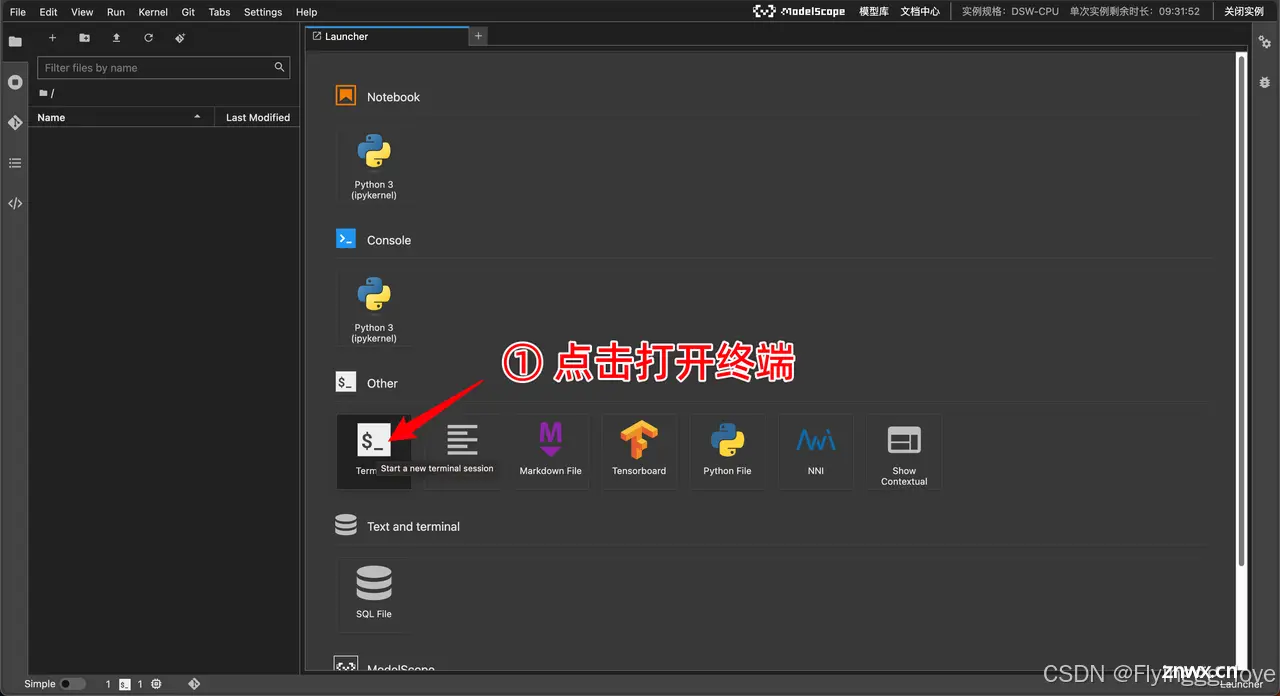
进入notebook之后,要先git下来我们的baseline文件,在哪git呢??
需要进入我们的终端Terminal
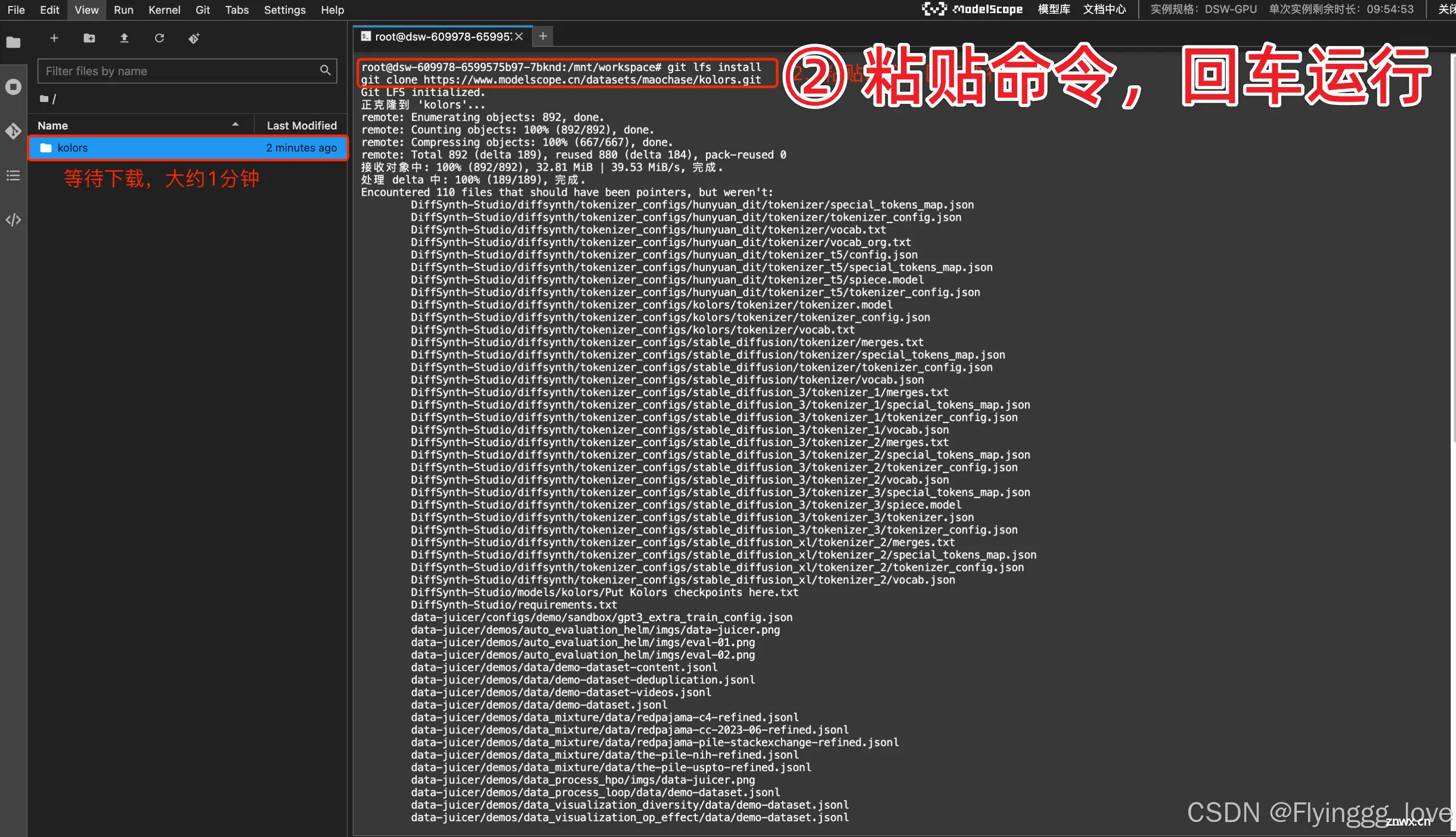
<code>git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors.git
然后就可以跟着教程一步一步进行baseline的运行了,注意,如果出现运行不成功的情况,可以restart一下。
至于运行,有两种方式,可以选中一个代码块,同时按下ctrl+enter,或者是点击左边的运行键。

运行成功之后左边会出现绿色的小对号,即代表我们运行成功了这个代码块。
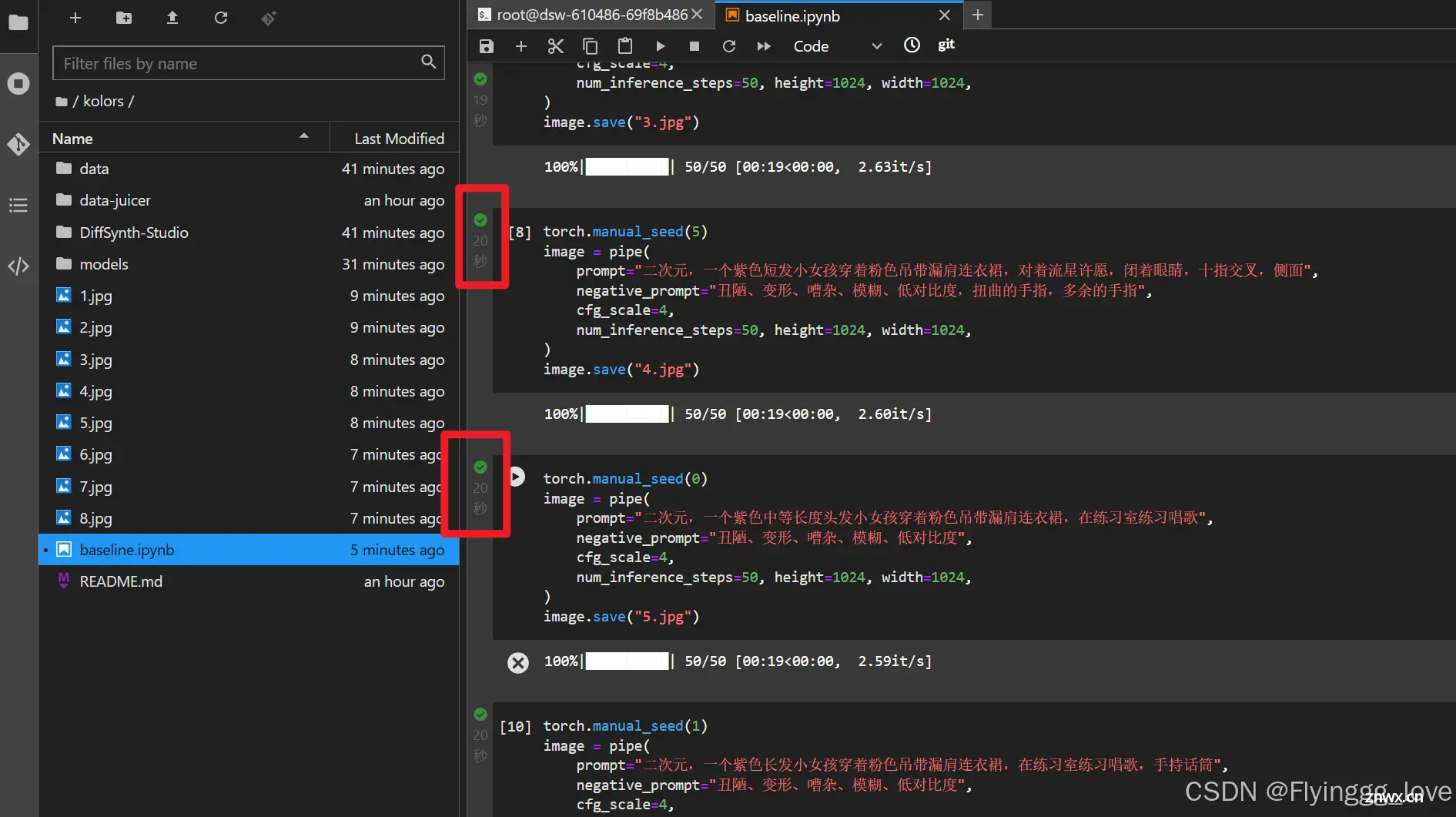
这是我运行完全部代码块后,最终的部分效果:

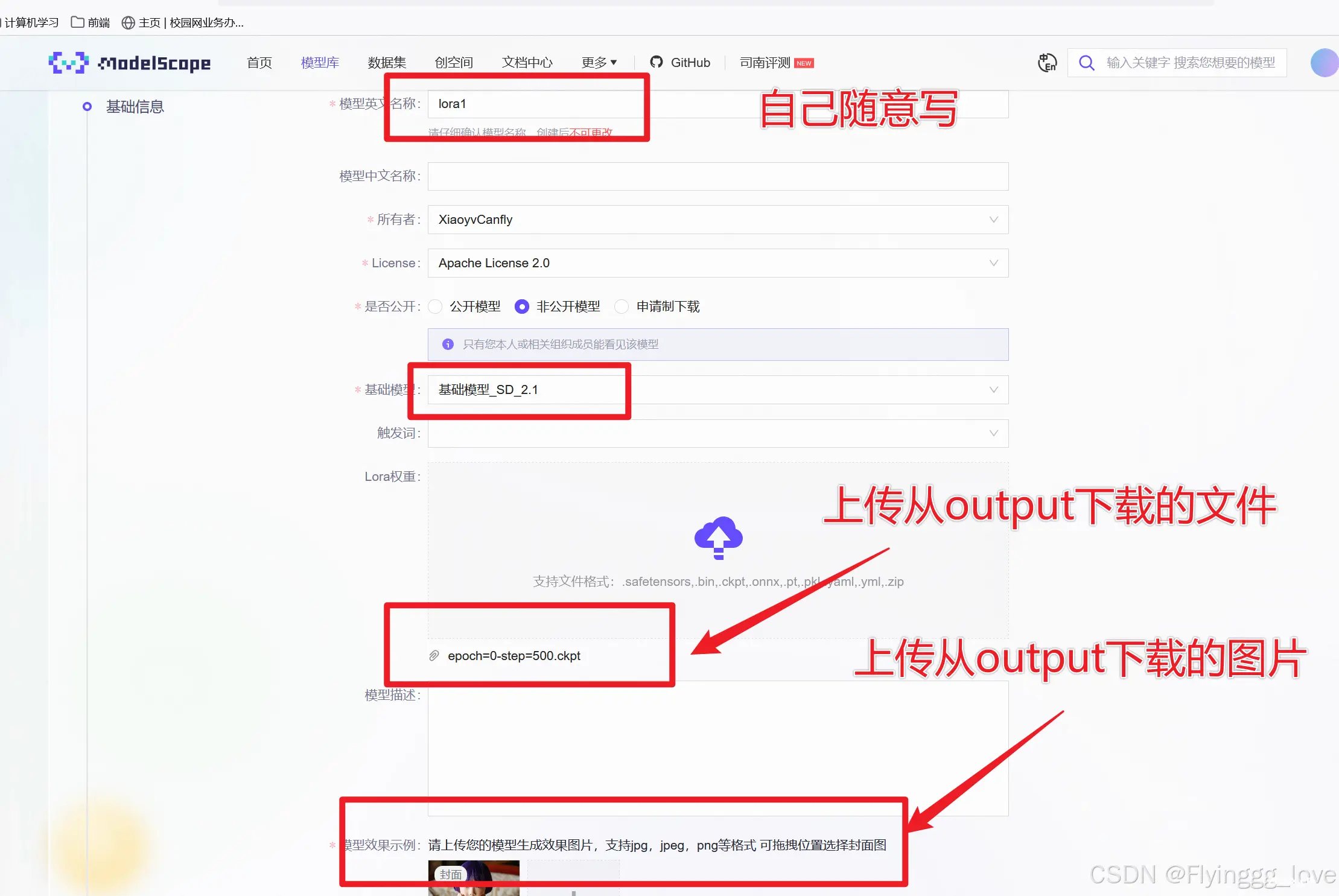
在赛事官网提交相关信息:
魔搭社区-创建模型
分任务2:相关知识学习以及赛题理解
赛题理解:
事实上,我们的赛题作出了以下几点要求:
| 1 | 要求基于LoRA模型生成 8 张图片组成连贯故事,故事内容可自定义;基于8图故事,评估LoRA风格的美感度及连贯性
|
| 2 | 参赛者可以根据自己审美,任意选择自己喜欢的文生图风格,例如水墨风、国风、日漫风等。 |
| 3 | 要求参赛者在赛事官网提交微调后的LoRA 模型文件、LORA 模型的介绍、以及使用该模型生成的至少8张图片和对应 prompt
|
| 4 | 美学分数仅作评价提交是否有效的标准,其中美学分数小于6(阈值可能根据比赛的实际情况调整,解释权归主办方所有)的提交被视为无效提交,无法参与主观评分。 |
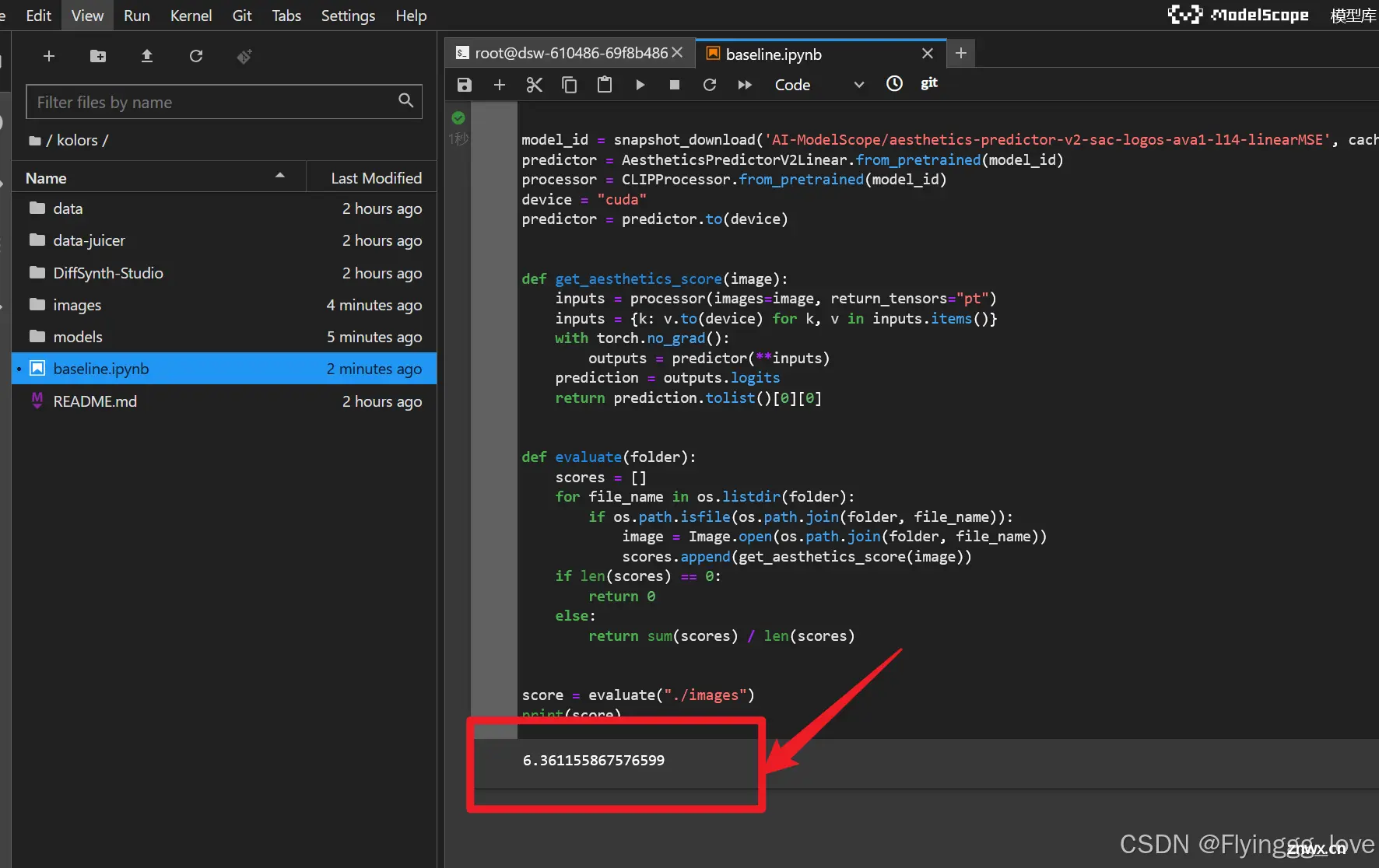
我们需要注意的是,必须保证我们的美学分数高于6,这样我们的作品才能视为有效作品,可以使用以下代码进行美学评分。
<code>
import torch, os
from PIL import Image
from transformers import CLIPProcessor
from aesthetics_predictor import AestheticsPredictorV2Linear
from modelscope import snapshot_download
model_id = snapshot_download('AI-ModelScope/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE', cache_dir="models/")code>
predictor = AestheticsPredictorV2Linear.from_pretrained(model_id)
processor = CLIPProcessor.from_pretrained(model_id)
device = "cuda"
predictor = predictor.to(device)
def get_aesthetics_score(image):
inputs = processor(images=image, return_tensors="pt")code>
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = predictor(**inputs)
prediction = outputs.logits
return prediction.tolist()[0][0]
def evaluate(folder):
scores = []
for file_name in os.listdir(folder):
if os.path.isfile(os.path.join(folder, file_name)):
image = Image.open(os.path.join(folder, file_name))
scores.append(get_aesthetics_score(image))
if len(scores) == 0:
return 0
else:
return sum(scores) / len(scores)
score = evaluate("./images")
print(score)
文生图基本认识:
提到文生图,我脑海中蹦出的第一个词就是Stable Diffusion(稳定扩散)
Stable Diffusion是文生图技术的一种实现,它是一种基于Latent Diffusion Models(LDMs)实现的文生图(text-to-image)算法模型,通过模拟物理世界中的扩散过程,将噪声逐渐转化为具有特定结构和纹理的图像。
这里的LDMs,则是在DM(Diffusion Model,扩散模型)基础上发展起来的。
与传统的图像生成方法相比,Stable Diffusion具有更高的灵活性和可扩展性,能够生成更加真实、细腻的图像。在训练过程中,Stable Diffusion使用深度学习技术,通过大量的图像数据来优化模型的参数,利用卷积神经网络(CNN)提取图像特征,并通过扩散模型生成具有这些特征的图像。
相信大家应该捕捉到了一些关键字眼:比如DM,LDMs ,这是SD的基本原理。
1. Diffusion Model(扩散模型)
从技术角度来看,AI绘画热潮的兴起要归功于扩散模型的引入。然而,作为一项早在2015年于国际机器学习会议(ICML)上提出的理论构想,其初现并未引起广泛的关注。
直至2020年6月,来自加州大学伯克利分校的一篇题为DDPM(去噪扩散概率模型)的论文,在更加庞大的数据集上展现出与当时最优的生成对抗网络(GAN)模型相媲美的性能,研究人员方才逐渐领悟到扩散模型在内容创作领域所蕴藏的威力与前景。
此后,不同国家的研究人员一直在进行着不断地探索,而他的真正出圈,是由于OpenAI 2022年发布的DALLE-2,其呈现出的前所未有的理解和创造能力,加之OpenAI 公司的开放API,使得文生图技术彻底走向大众视野。
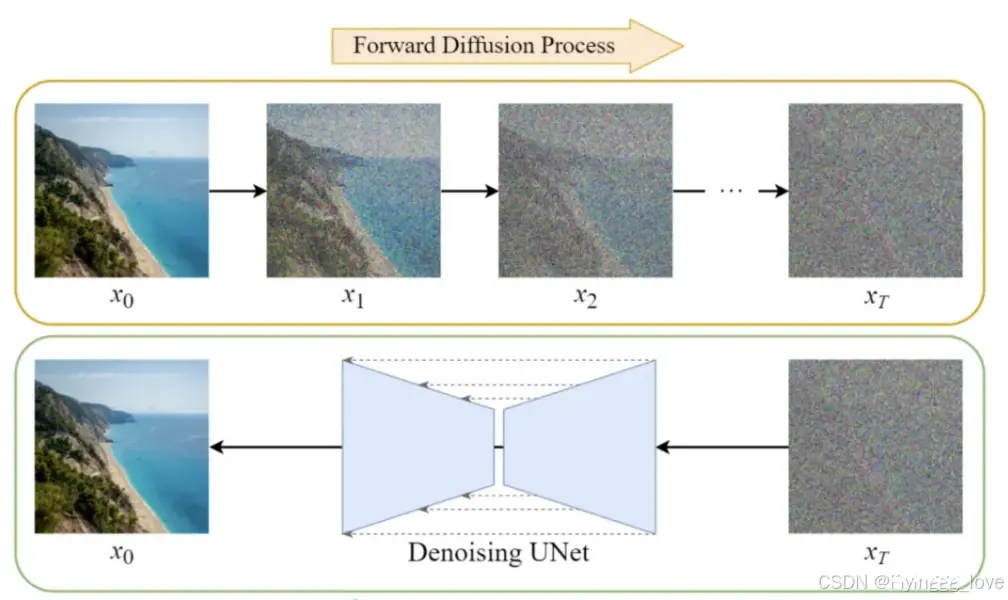
DM『扩散模型』工作原理:通过向原始图像中,连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据。简单来说,包含两个过程:「前向扩散」和「逆向扩散」。
1)前向扩散:前向扩散过程是不断往输入图片中添加高斯噪声,直到原图像模糊;
2)逆向扩散;反向(逆向)扩散过程是将噪声不断还原为原始图片,这一举措会得到一个【模型】(令为模型A),这个模型训练并稳定下来,就能实现在线预测了,即给模型一个 文本提示或原始图像,它就能基于这个模型生成另一幅图像。
2. LDMs(潜空间扩散模型)
笔者认为提出LDMs的主要原因是,我们需要对训练图片进行像素级的处理,而图像的像素空间是巨大的,对于512x512大小RBG三通道的彩色图片,这将是一个768,432(512x512x3)维度的空间。(意味着为了生成一张图,你需要确定768,432个值)
可想而知,这会消耗大量的时间和资源,因此提出了潜空间扩散模型(LDMs),何为潜空间??
由于图像像素之间的信息是大量冗余的,我们训练一个自编码器将图片进行压缩。
大概可以理解成是和像素空间对应的空间,但是容积比像素空间小,即,通过潜空间,我们实现了对原本像素数据的压缩。
然后我们在潜空间中进行扩散操作。
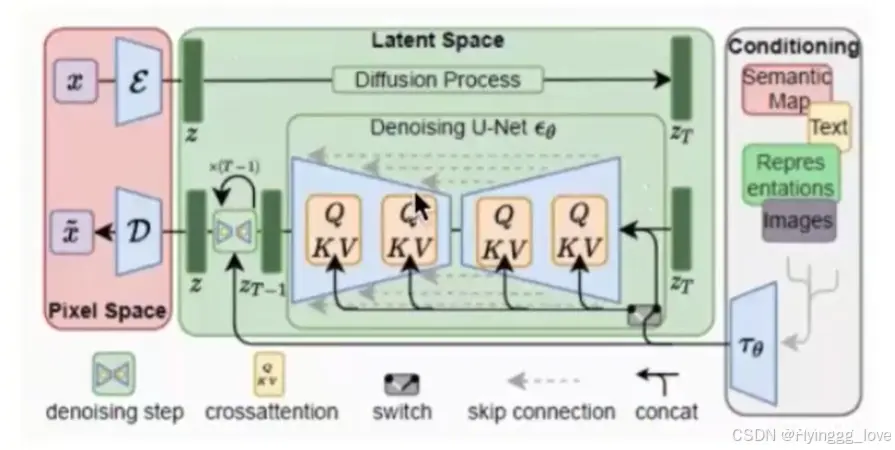
因此S-D处理的并不是直接的像素图像,而是潜空间中的张量(即4*64*64的噪声图),在训练中,我们在潜空间的图像添加潜空间的噪声,而不是像素图添加像素噪声,这样就使得执行速度有了大幅提升。
与此同时,随着隐空间编码带来的速度提升,它的缺点也暴露出来,就是对于图像信息的压缩,会产生一定的损失,那么,对于图像精度要求比较高的场景(高清的街景),解码器输出的图片可能会出现比例失真,肢体扭曲等问题。
3.基础文生图模型优化的三大方向
1. 更大的模型容量
2. 更强的prompt following ability
3. 模型架构选择?
更大的模型容量:通过对比SD 1.4/1.5 ---> SD 2.0/2.1---->SDXL,我们可以发现,参数量的提升确实带来的生成质量的提高。

更强的prompt following ability-----指令遵循能力
啥意思呢??就是(模型生成图片所描述的内容)——【实际得到的】 与(你所给出的文本引导提示)——【你所期望的】的匹配程度。
怎么提高prompt following ability 呢?
方法有二:
其一,使用更长更详细的image caption ,在open AI 官网中关于DELL-E-3的pdf介绍中,建立了一个可以对图像进行精准描述的打标器,我们使用打标器对于训练数据重新生成图像的caption,并进行训练,从而提高模型的prompt following ability 。下图是DELE-E-3论文中对于图像的更加精细的描述。


其二,使用更大更多的text encoder ,可以看到SD 3已经使用三个文本编码器,且嵌入维度也成倍增加。

模型架构的选择——Transformer?or Unet?
对于NLP任务,Transformer 架构具有一骑绝尘的地位,但是在图像领域,SD系列模型采用的是Unet架构。
而对于今年推出的视频生成模型Sora ,则是采用了DIT架构,即 Diffusion transformer 架构
4.LORA(Low-Rank Adaptation) ——轻量级大模型微调方法
大模型的研发是昂贵的,对于小公司或者个人而言,如何调整大模型为自己所用,是我们专注的问题所在。
lora ,顾名思义,就是一种低秩微调的方式,也就意味着我们可以使用少量的权重,进行大模型的微调,对于下图而言,r的维度始终是小于d和k的,在实际训练中,lora可以直接和Transformer中的FFN层对接,也就是下图的左半部分是FFN层,右半部分就是我们训练的Lora,这样的话,不会对原来的权重造成影响,直接加到模型中即可。
基于大模型的内在低秩特性,增加旁路矩阵来模拟全参数微调,LoRA 通过简单有效的方案来达成轻量微调的目的,可以将现在的各种大模型通过轻量微调变成各个不同领域的专业模型。这里推荐阅读http://t.csdnimg.cn/bqbGd,里面有更加通俗详细的lora技术原理。
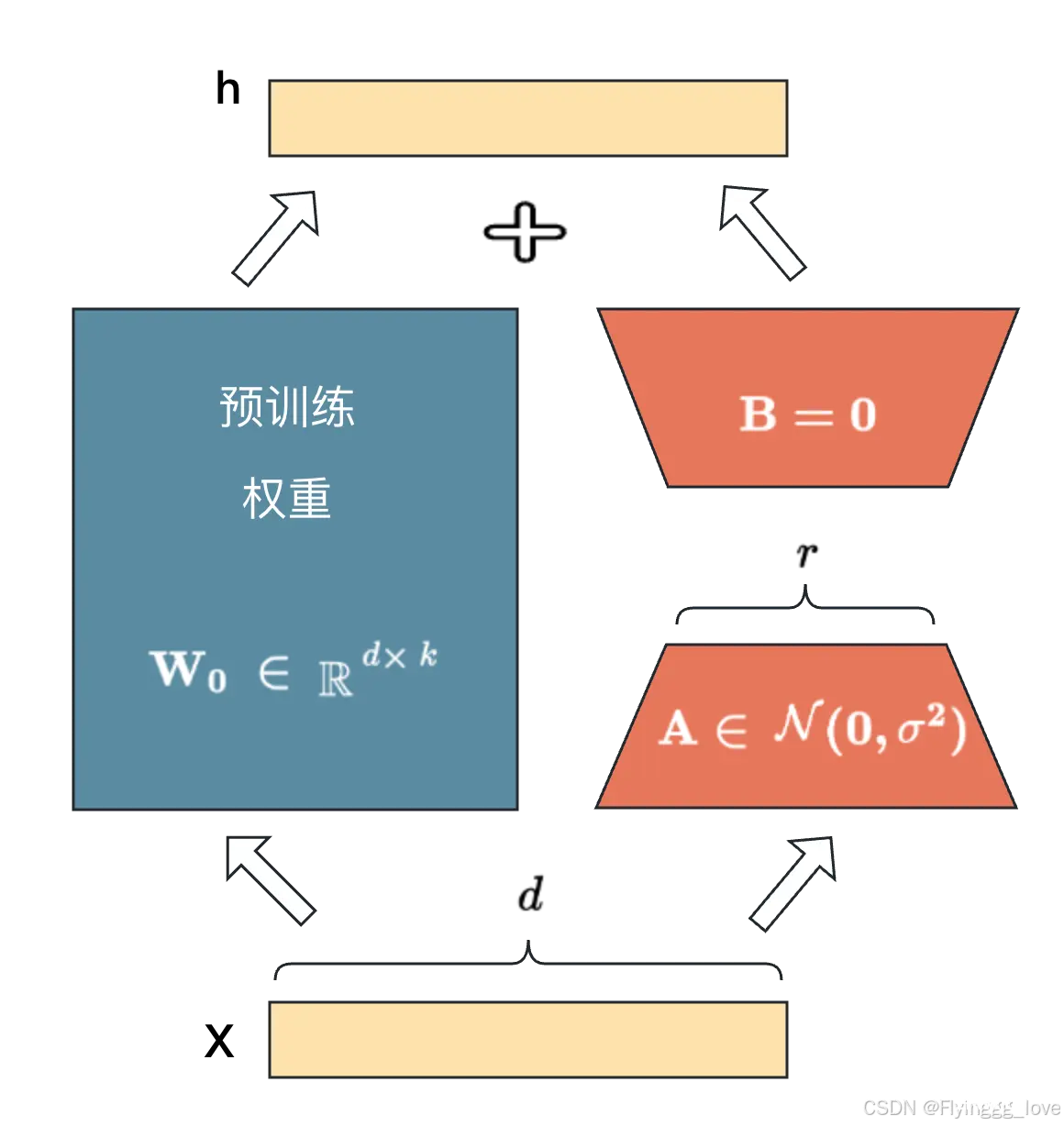
目前 LORA 已经被 HuggingFace 集成在了 PEFT(Parameter-Efficient Fine-Tuning) 代码库里。
在AI绘画领域,我们可以使用SD模型+LoRA模型的组合微调训练方式,只训练参数量很小的LoRA模型,就能在一些细分任务中取得不错的效果。
接下来就实现一下lora:
<code>#导入需要的模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class LoRALinear(nn.Module):
#merge:使用预训练层的时候,要不要把预训练层的参数合并到lora层中,相当于一个开关
#rank:lora层的rank,要降到多少位
#lora_alpha:lora层的缩放系数,即究竟使用怎样的比例和原始的权重进行相加,如果太大的话,可能会对原始权重造成影响
def __init__(self, in_features, out_features, merge,rank=16, lora_alpha=1, dropout=0.5):
super(LoRALinear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.merge = merge
self.rank = rank
self.lora_alpha = lora_alpha
self.dropout_rate = dropout
#构建一个线性映射的层
self.linear = nn.Linear(in_features, out_features)
if rank >0:
#使用zero初始化参数
self.lora_B = nn.Parameter(torch.zeros(rank, out_features))
self.lora_A = nn.Parameter(torch.zeros(in_features, rank))
self.scale = self.lora_alpha / self.rank #究竟以什么样的权重系数放缩之后加入原始权重中
self.linear.weight.requires_grad = False #不需要更新原始权重
# 如果dropout大于0,则构建一个dropout层
if self.dropout_rate > 0:
self.dropout = nn.Dropout(self.dropout_rate)
else:
self.dropout = None
self.intial_weight()
#对lora_A的权重进行初始化
def intial_weight(self):
#海明窗初始化
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
#前向传播
def forward(self, x):
if self.merge and self.rank > 0:
#如果merge为True,则使用原始权重和lora权重相加
#lora_a 矩阵乘法 lora_b ,所以说我们的原始权重是 wx+b w是out_features*in_features,,x 是in_features*batch_size(几维)
output=F.linear(x,self.linear.weight + self.lora_B @ self.lora_A*self.scale,self.linear.bias)
output=self.dropout(output)
return output
else:
#如果merge为False,则使用原始权重
return self.linear(x)
参考资料:
【翻译】How Stable Diffusion Work - 给小白看的StableDiffusion原理介绍
Stable Diffusion一周年:这份扩散模型编年简史值得拥有
什么是 GAN?
深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。