【Datawhale AI夏令营第四期】魔搭-AIGC方向 Task01笔记
百里香酚兰 2024-09-01 11:31:01 阅读 98
报名参加了和鲸的AI夏令营,出于任务要求,也出于我一贯的学习习惯,写篇笔记记录一下自己学习过程中遇到的困难,和积累的资源、经验等。
课程链接:
https://space.bilibili.com/1069874770/channel/collectiondetail?sid=3369551
传送门
1.1文生图的历程与基石-历史沿革与基础理论
第一课的视频介绍了文生图的历史,以及扩散模型生成图片的过程。
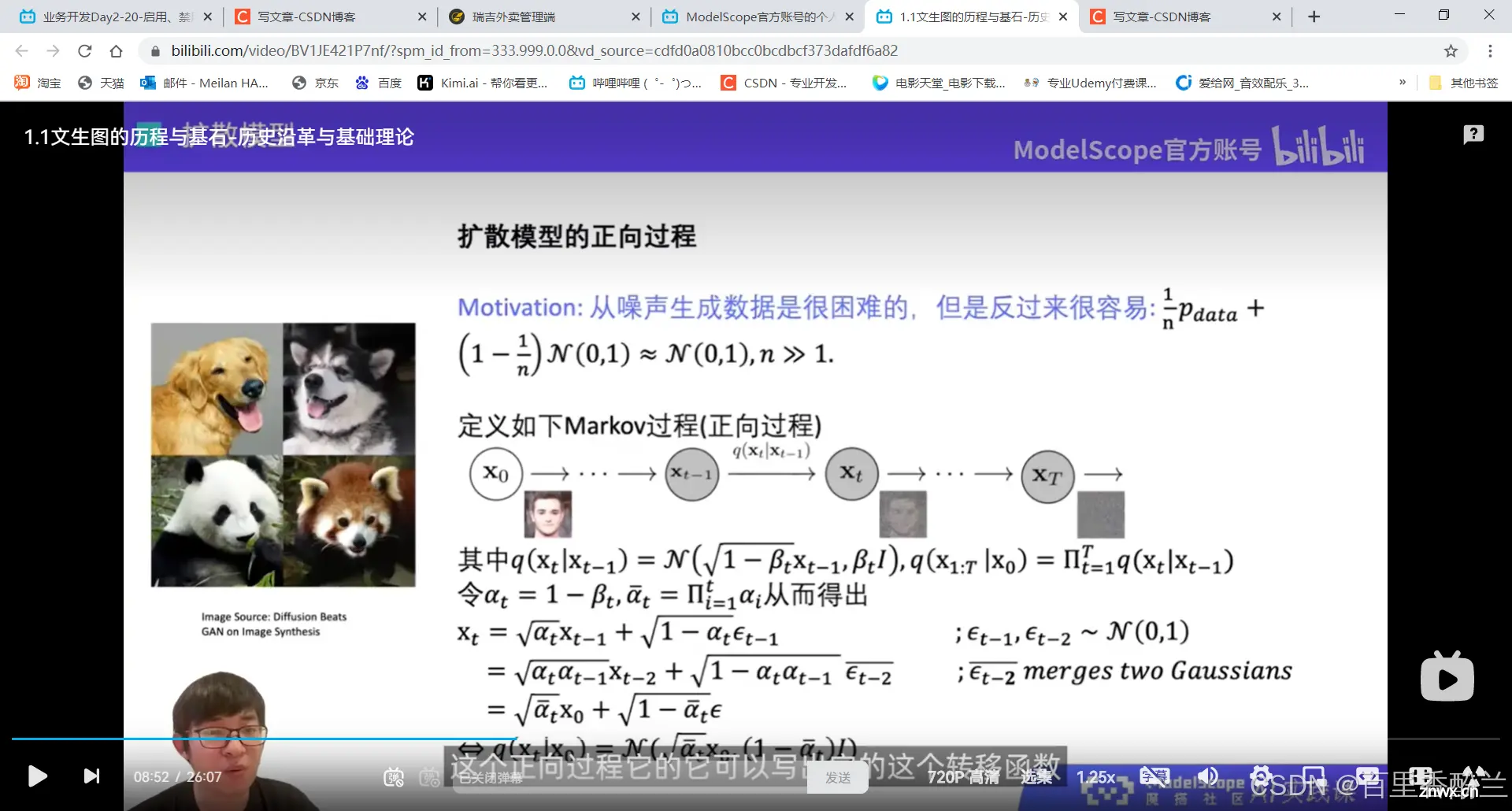
如果跟我一样看得一脸懵逼,面对下图这样一句话的核心思想也是不明就里的话,没关系。

之前在看另一门b站的付费课《图灵的猫:人人都能听懂的AI通识课》时,发现了对这一过程很好的通俗解释——粉条包子。
有一家店的粉条包子好吃,但是距离太远,作者不想去吃,那么就买一个包子交给楼下的包子铺,让他们反推出粉条包子的配方,最终得到一个近似的粉条包子。等他们学会了复制做这个包子,就可以自己发挥出独一无二的包子了。但是作为顾客,我们只需要知道如何点单就可以了。
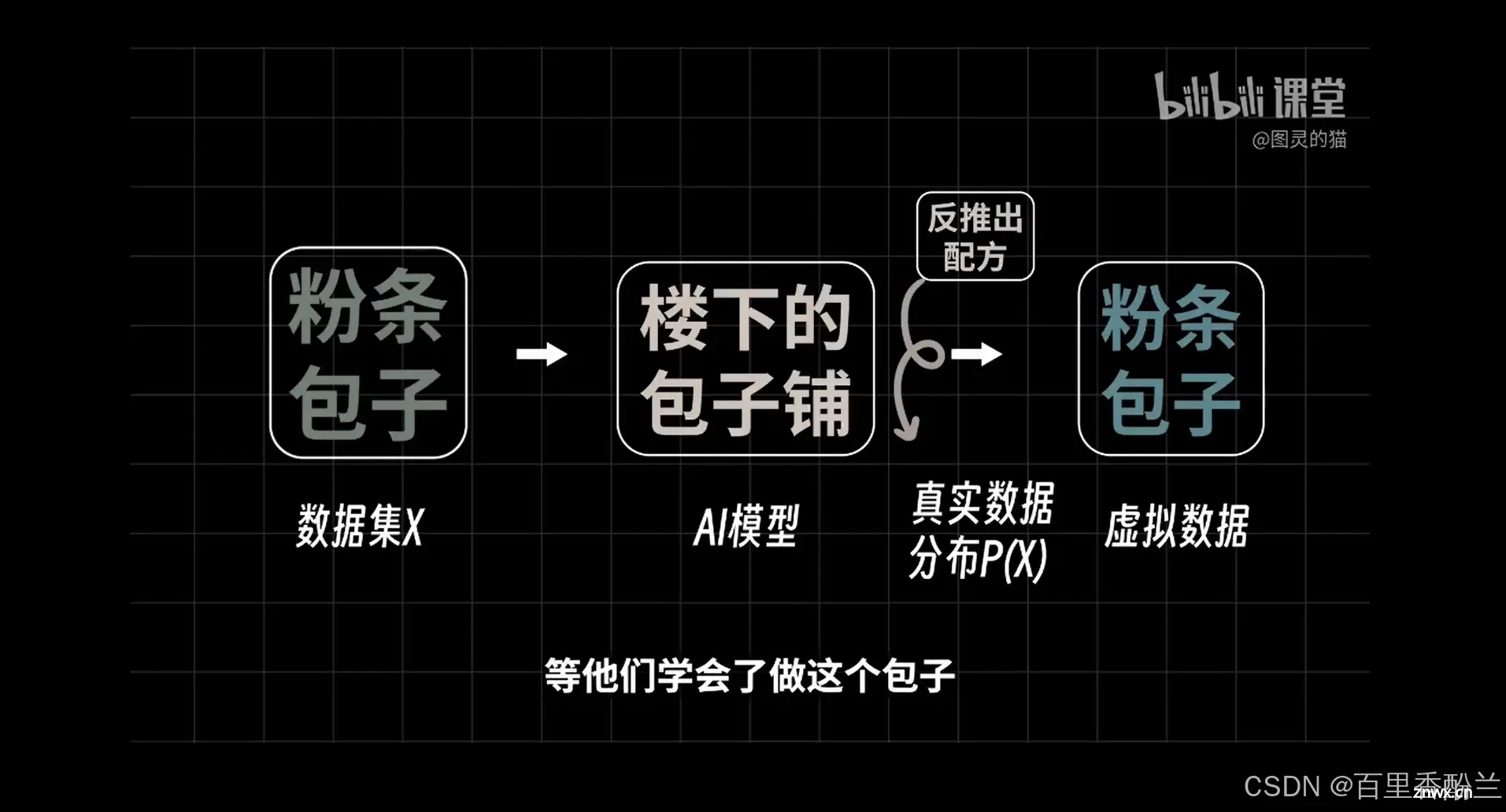
扩散模型的优点就是把画画变成了更利于AI模型理解的去噪过程,从而避开了一些数学上很难达到的条件。
看这个网课的数学过程觉得迷惑的朋友也不必焦虑和害怕,初学AIGC学习的目的主要是掌握应用能力,通过调教AI做出效果出色的作品,如果不是立志要走算法工程师这条路的话,真不用太深究算法里面的原理。
1.2最新图像生成技术研究方向-介绍与分析
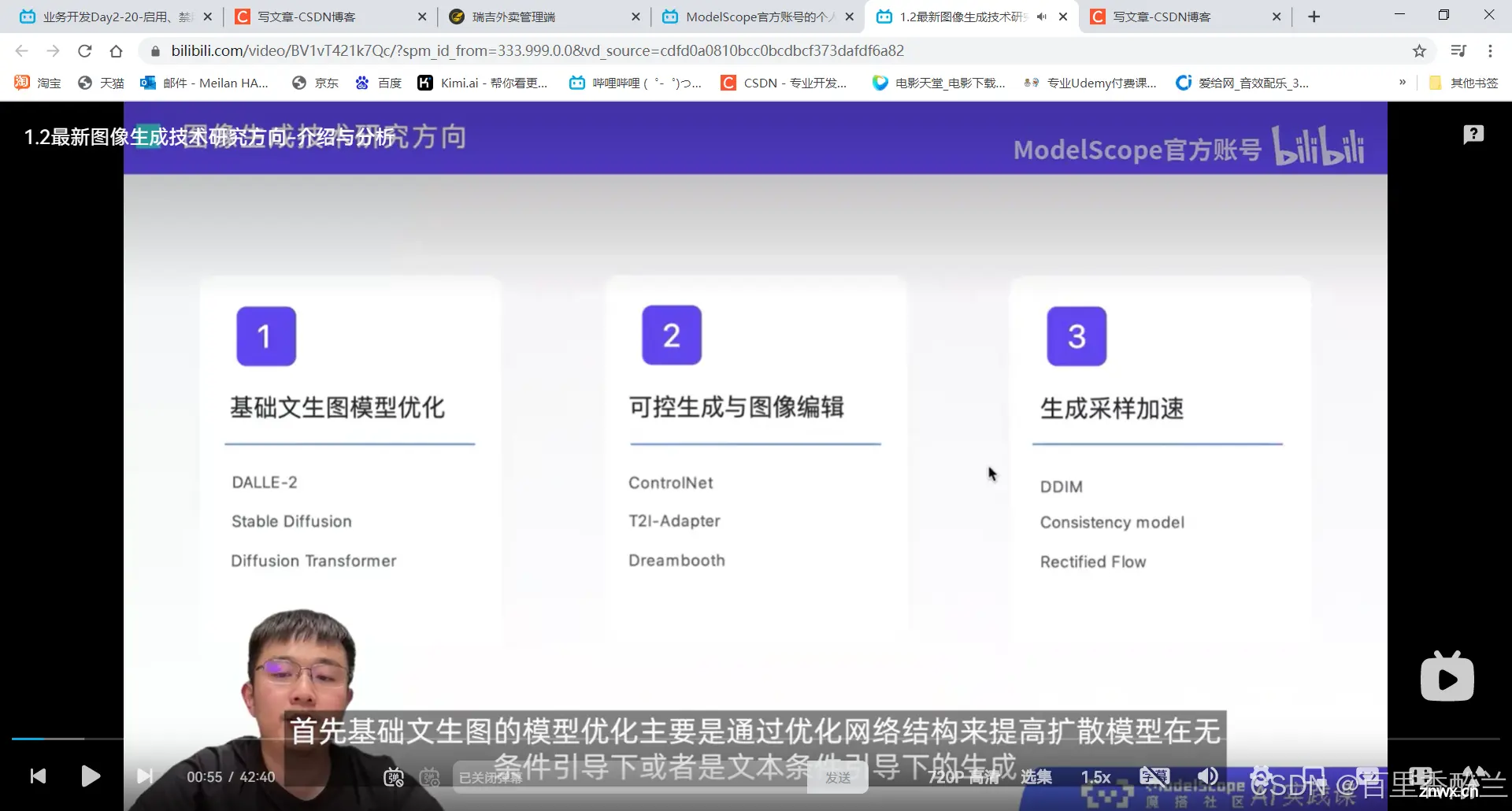
扩散模型的三大研究方向:基础文生图模型优化,可控生成与图像编辑,生成采样加速。
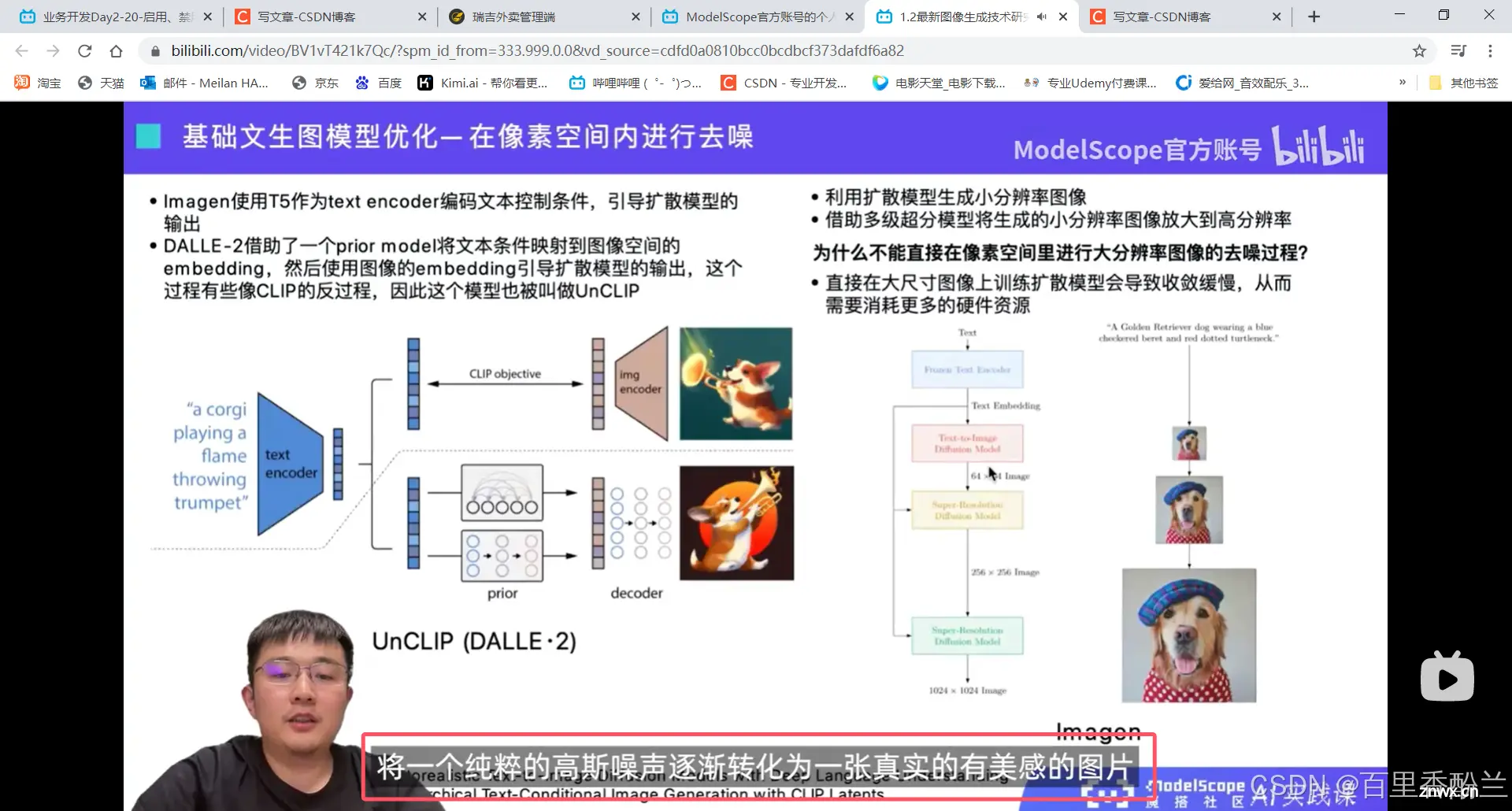
扩散模型的本质:不断去噪,将一个纯粹的高斯噪声转换为真实有美感的图片。
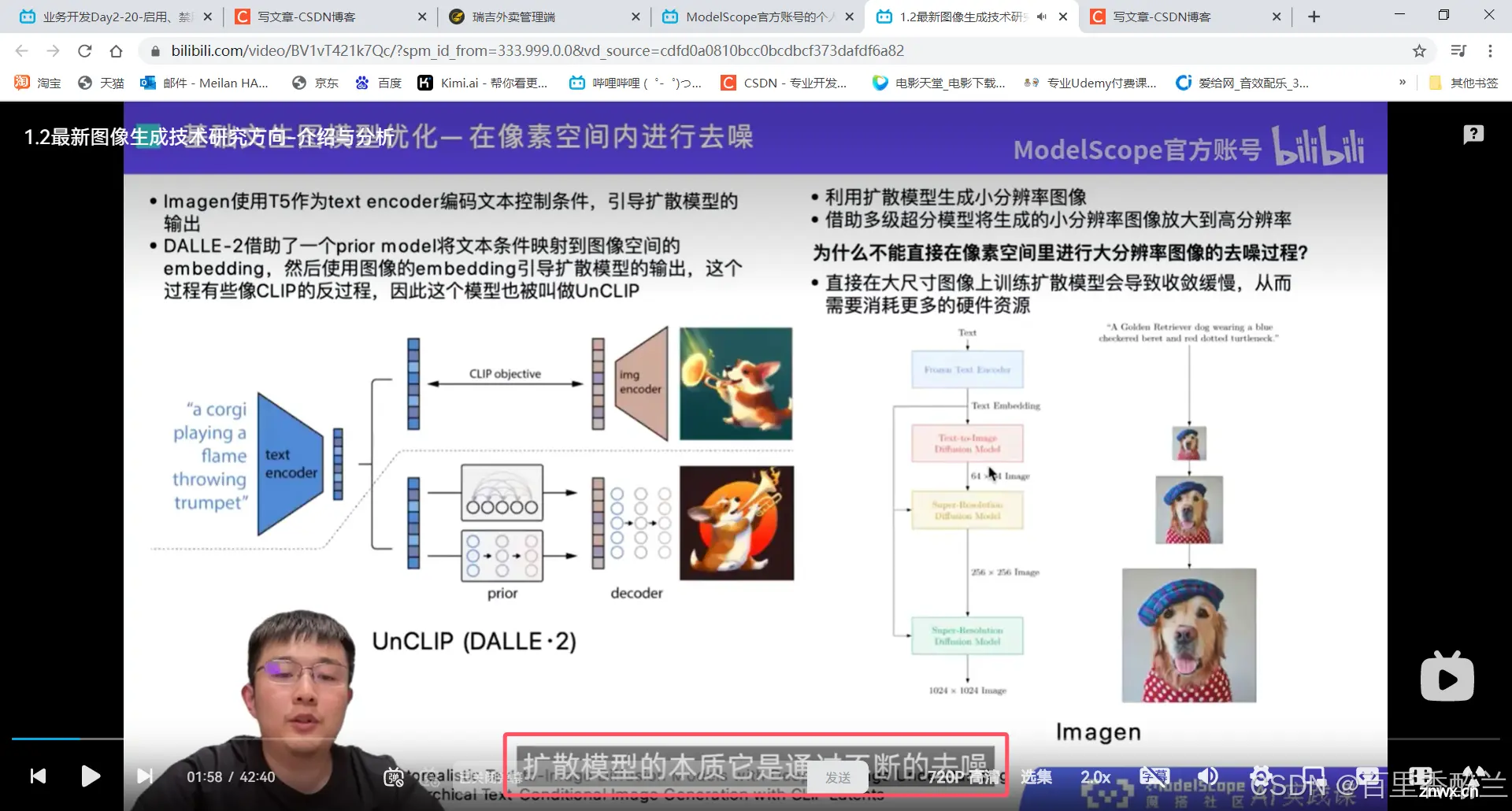
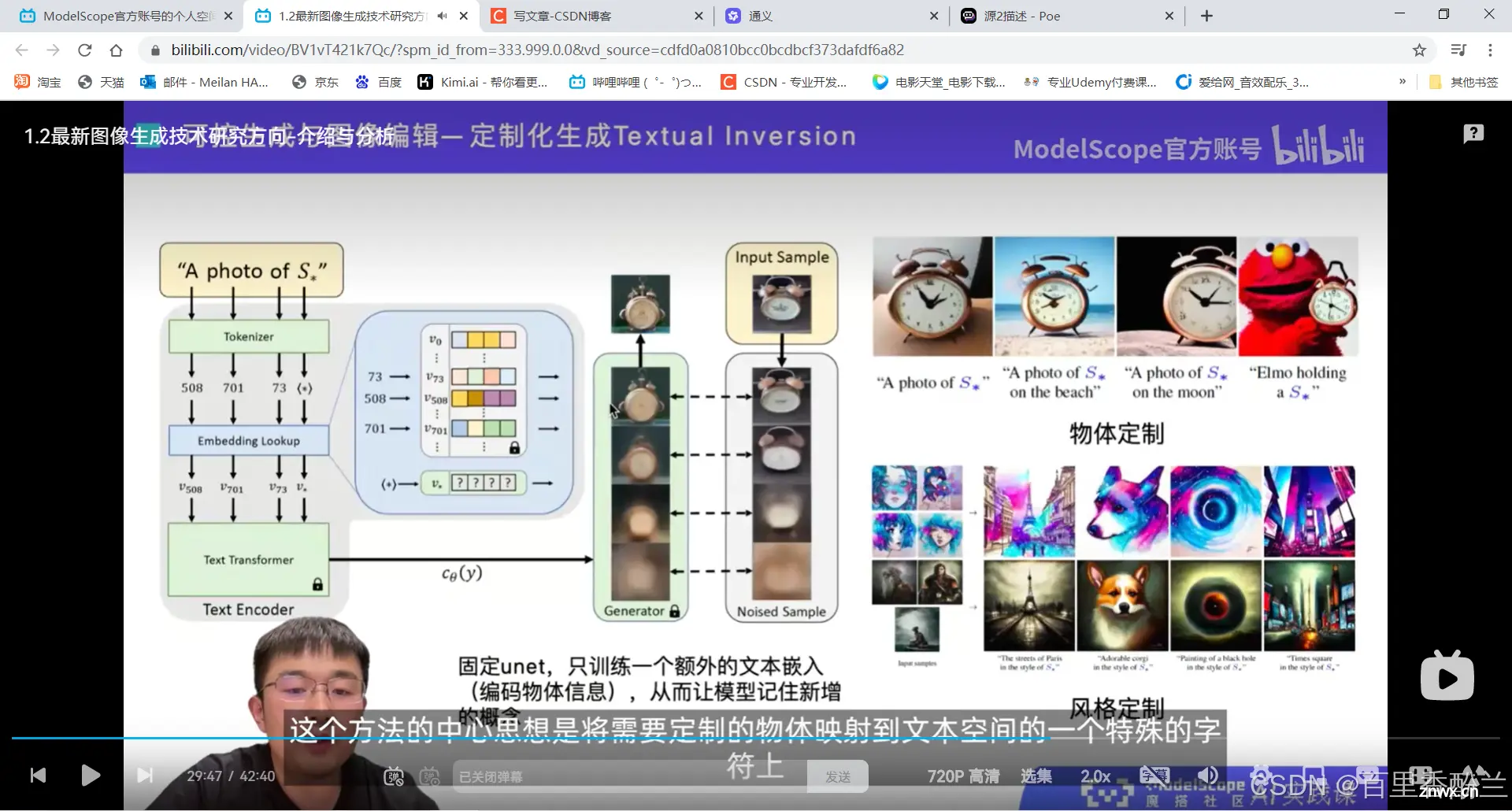

视频中介绍的定制化生成我觉得有很大的应用前景,因为如果要创作长篇系列作品的话,保持角色一致性尤为重要。
我也想过给自己的棉花娃娃呆呆做图片、动画等,但是因为市面上没有专门针对他的模型,AIGC很难精准地生成很符合他的形象的内容。就算是用很好的提示词硬描述出跟他外观相似的角色,也很容易在不停生产作品的时候随机歪掉。

如果能把他的特征作为一个固定的embbeding,每次不管环境如何变化,他这个主体的形象不变,就可以大批量创作了。
市面上现有的视频模型:根据运动幅度和视频长度,梯队分为俩个:Sora、可灵和其他模型(笑死)。
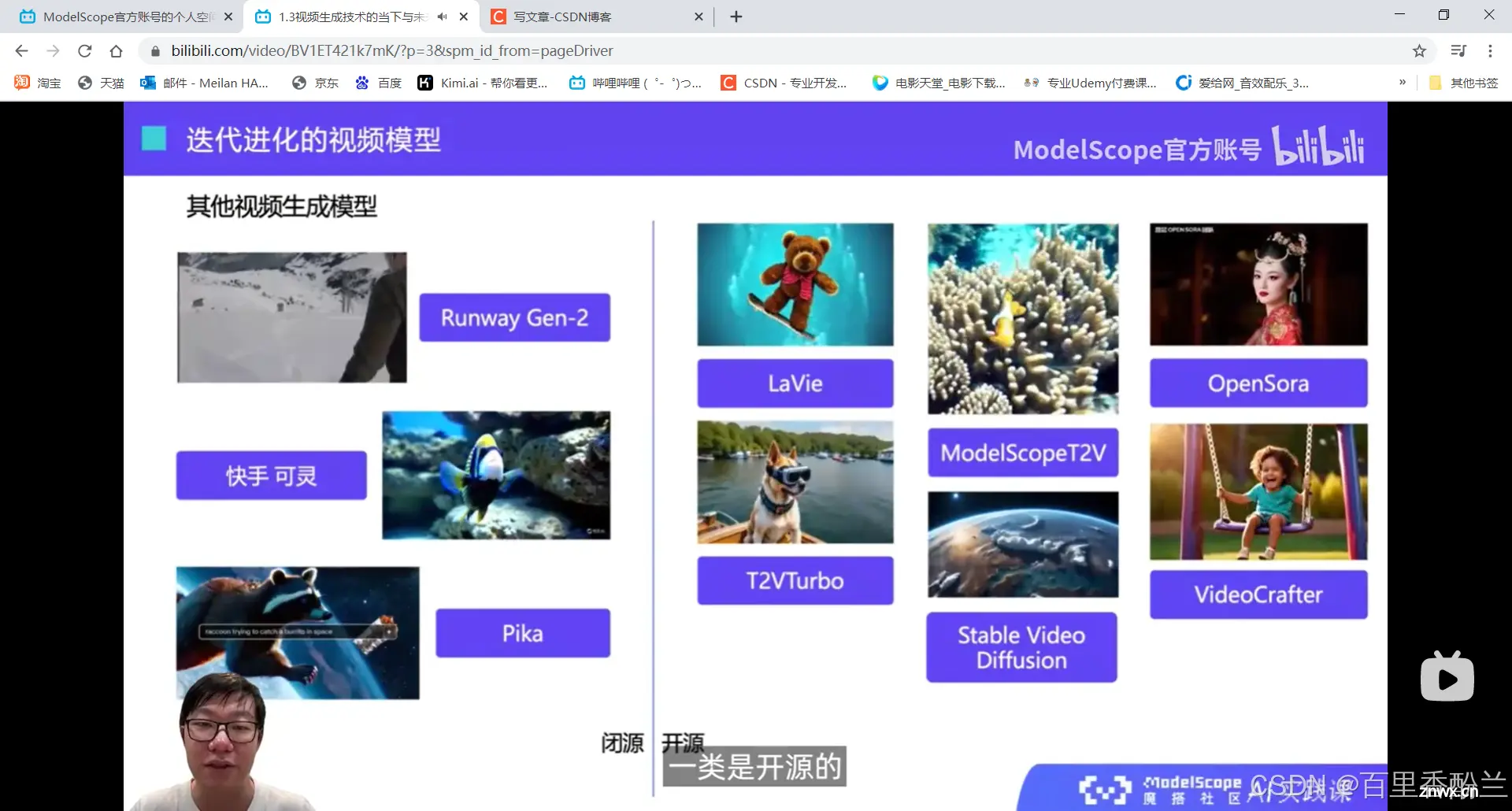
这几个视频看下来感觉老师选的模型是很新很有代表性的,讲解的细节也很详细,如果对算法有兴趣的话值得反复钻研。
开源短视频生成长视频遇到的“误差累积问题”:每过一帧画面都会发生一点变化,画面质量在变化时也会下降,于是越歪越厉害
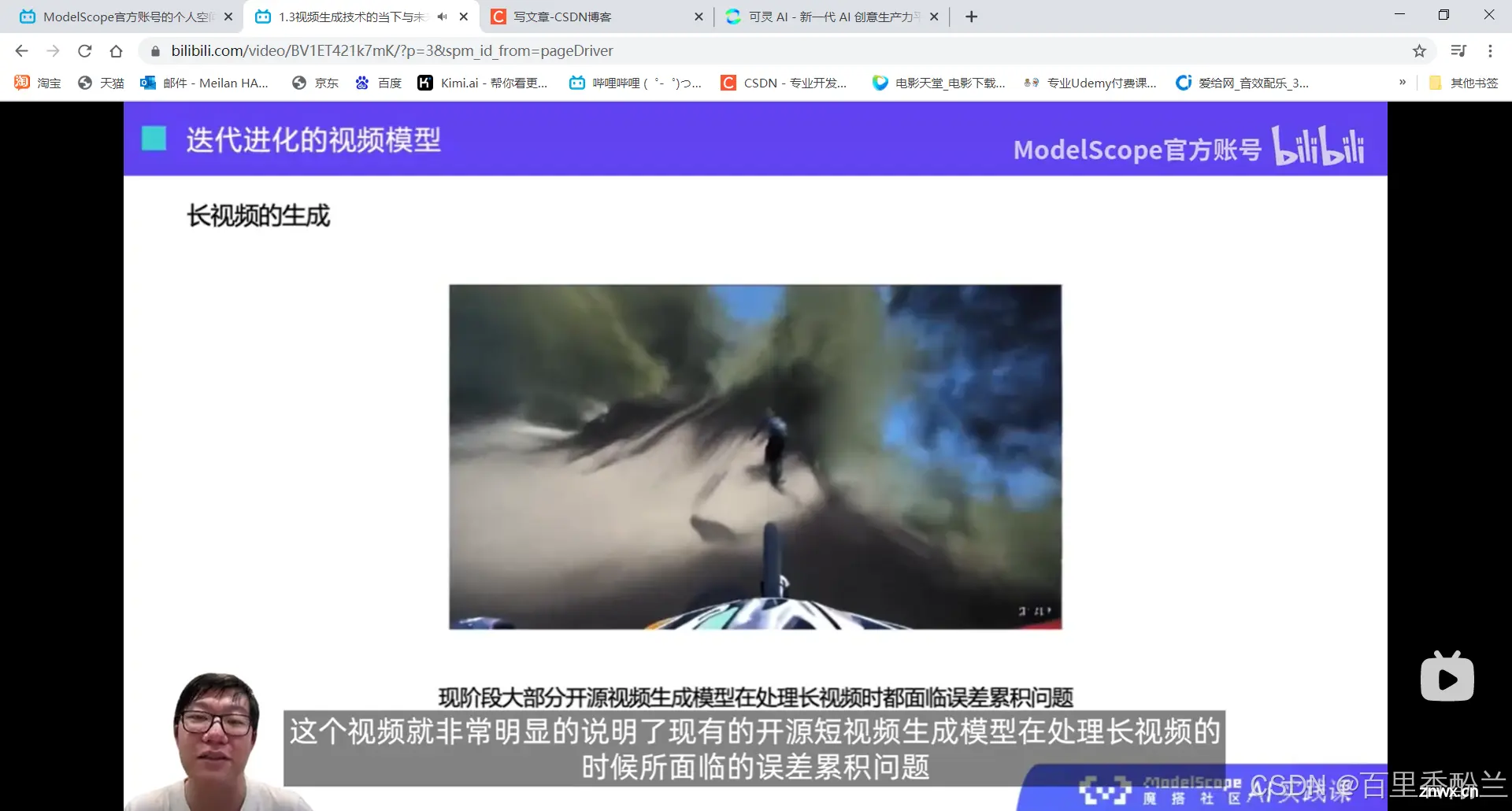
1.3视频生成技术的当下与未来
未来的视频生产技术能做什么?特效制作,老电影修复,3D渲染,
课后作业:
https://github.com/modelscope/DiffSynth-Studio?tab=readme-ov-file
传送门
我试着跑第一个的时候,安装requirements发现老报错误OSError,导致有的库装不上去,经过查询发现要在pip insytall 包名后面加上–user(2个-)。
WARNING: Failed to write executable - trying to use .deleteme logic
ERROR: Could not install packages due to an OSError: [WinError 2] 系统找不到指定的文件。: ‘C:\Python312\Scripts\pygmentize.exe’ -> ‘C:\Python312\Scripts\pygmentize.exe.deleteme’
比如,本来安装requirements.txt的指令是这样:
pip install -r requirements.txt
现在要写成:
pip install -r requirements.txt --user
然后就可以顺利执行了:
执行之后发现又是一个从来没遇到的乌龙Bug,这就是另一个故事了:详情可以搜索一下《Pytorch、Cuda安装》相关的帖子,比如这个:https://blog.csdn.net/weixin_46726459/article/details/138088057
传送门
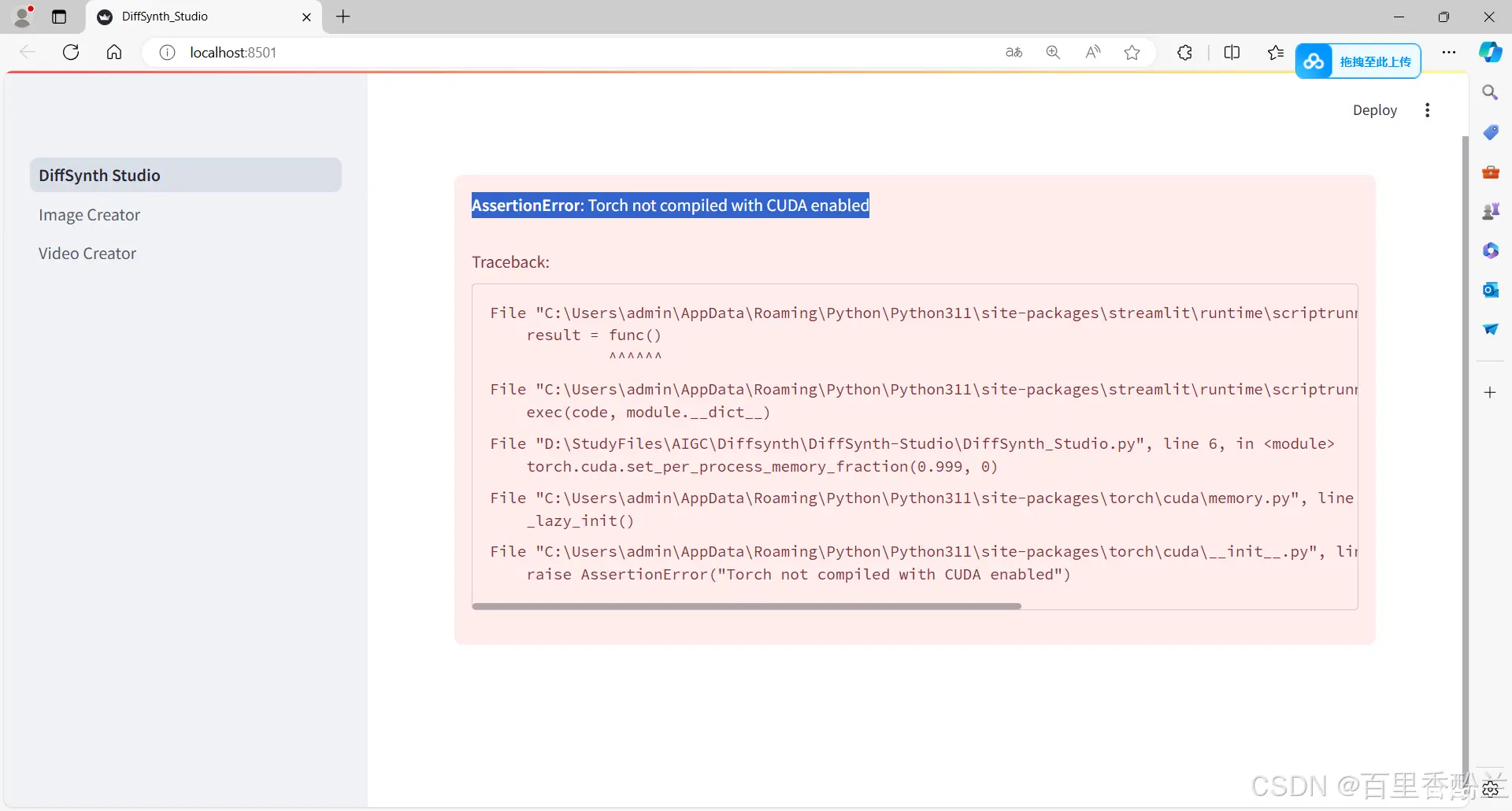
我目前遇到这种电脑环境不配合的问题也只能随缘处理,无论如何都有不能兼容的包:
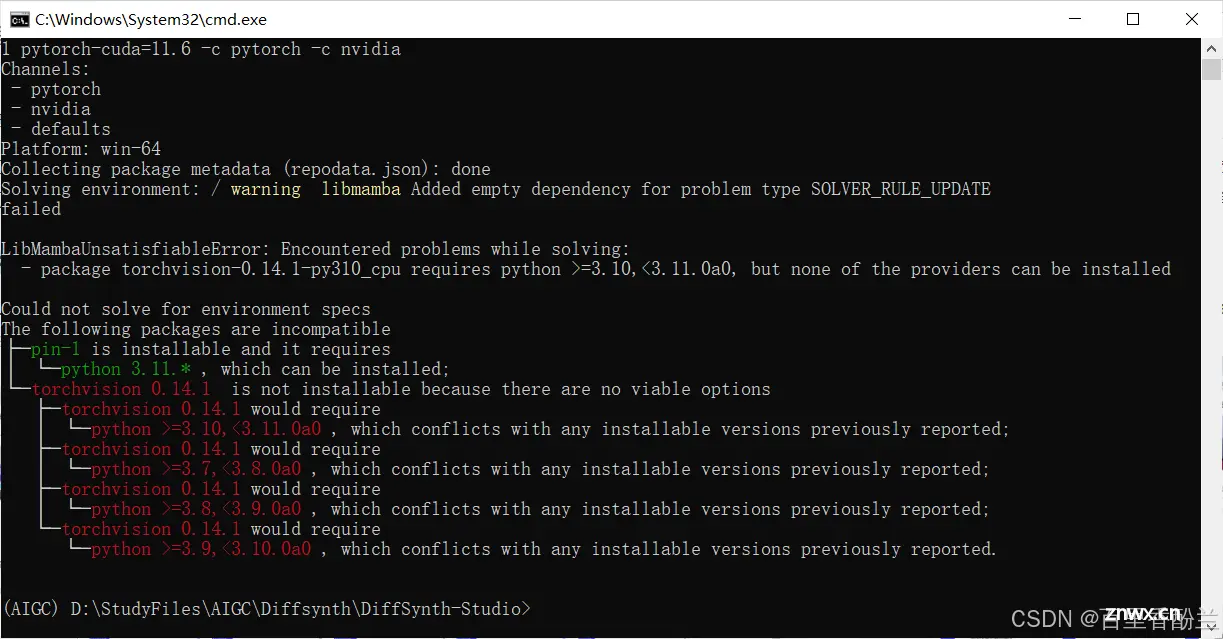
最后我还是在云端的这种服务平台上终于跑起来了,但是无法选择要生成的模型,还是玩不了QAQ
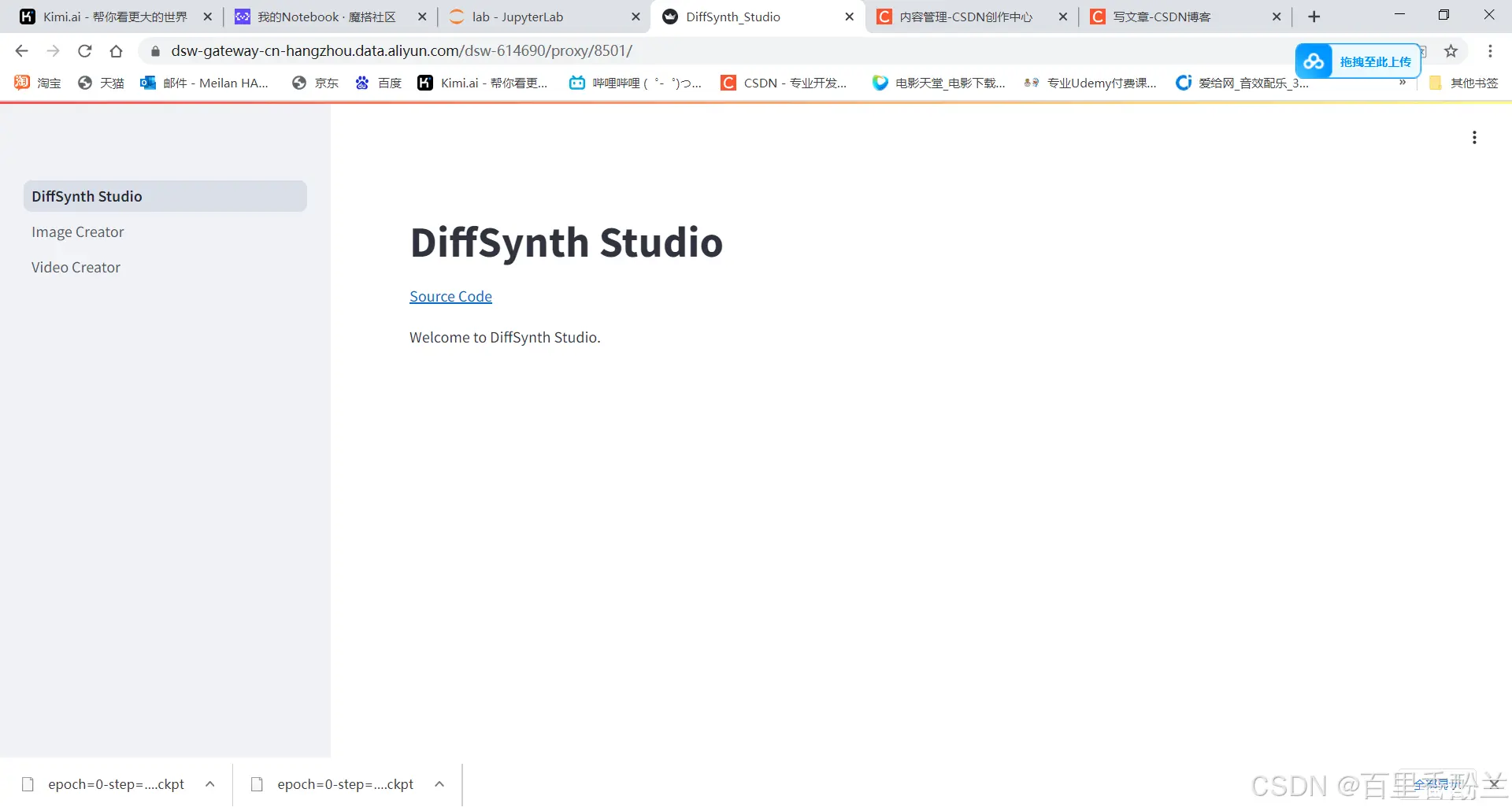
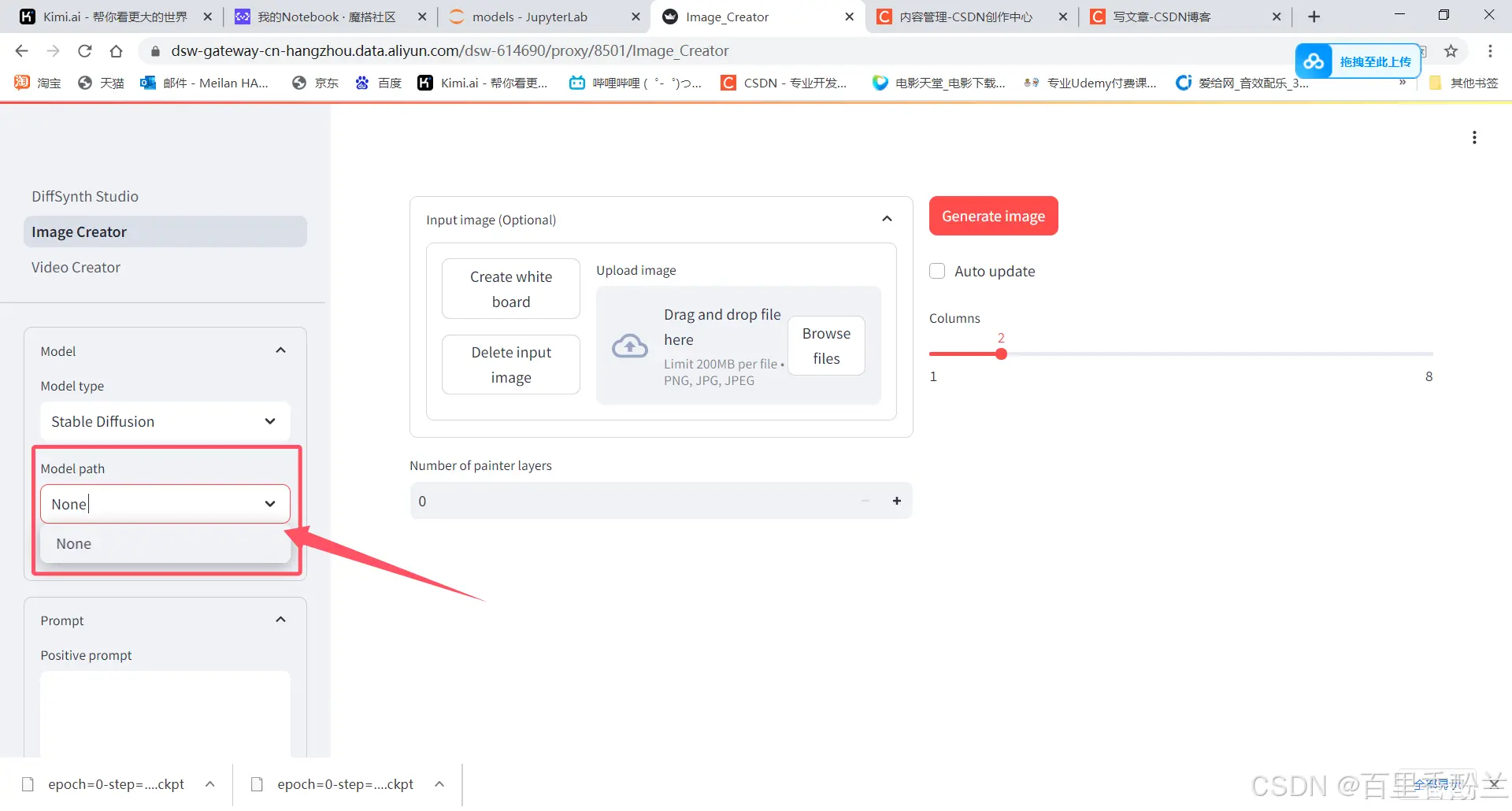
Task1详情:
学习手册 & 打卡链接:
https://linklearner.com/activity/14/10/24
其他链接🔗 :
【学习者手册】
https://datawhaler.feishu.cn/wiki/UM7awcAuQicI4ukd2qtccT51nug
【QA文档】
https://datawhaler.feishu.cn/wiki/K6b1woVtlizjV0klBBgc6ZJUnie
在学习Task1教程案例的过程中,我发现我误操作踩了个雷:无论是大模型应用开发还是AIGC,教程里面提到的都是《选择方式二》,即GPU……但是我之前一直选择的是CPU,于是跑到某一步的BaseLine就会报错。
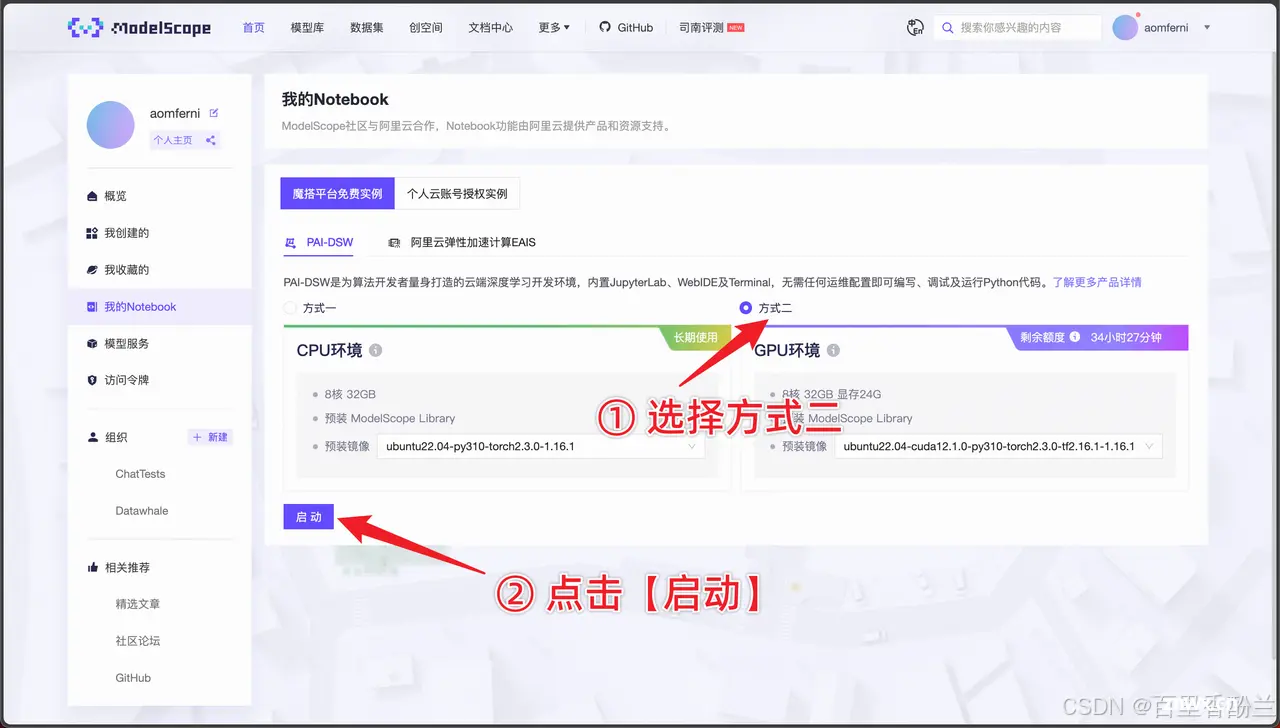
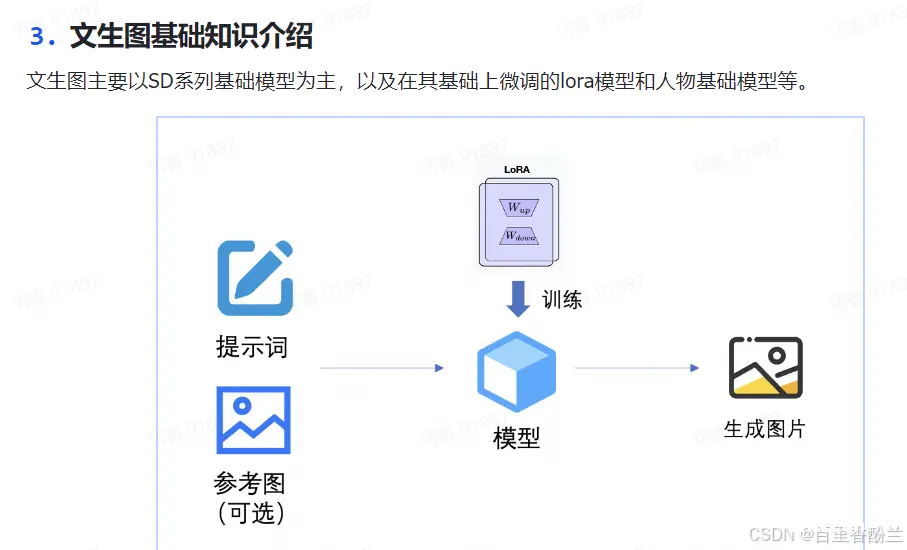
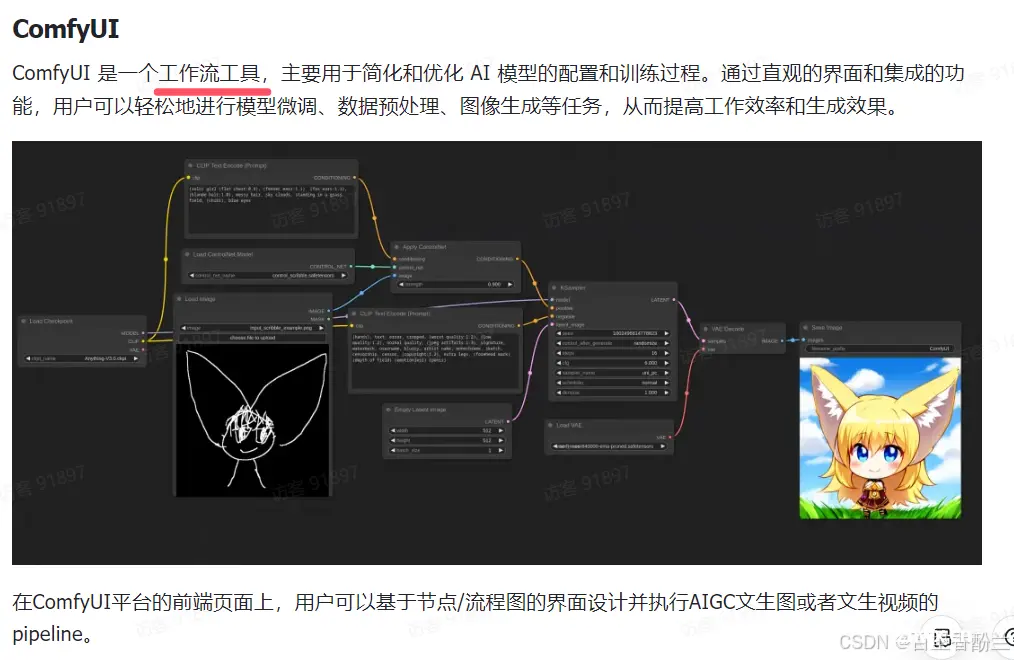
另外,在学习手册中,我留意到了几个BOSS直聘上找AIGC相关工作的常见关键词:Lora,ComfyUI和ControlNet :



比如学习群里助教老师指点的更换参考图片,就是Lora的过程:
听着很高级很吓人,实际上还是没那么可怕的~
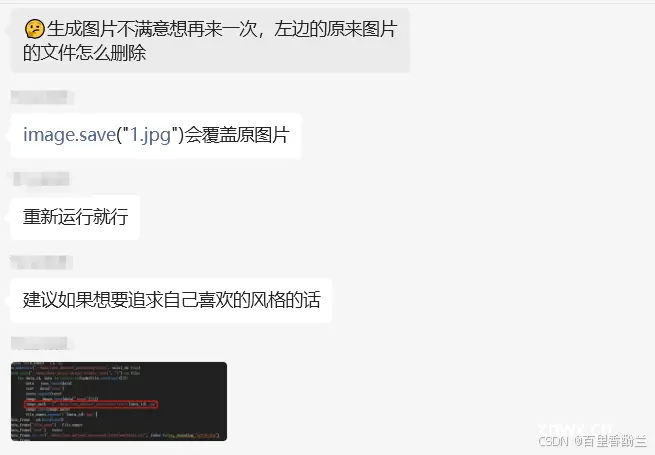
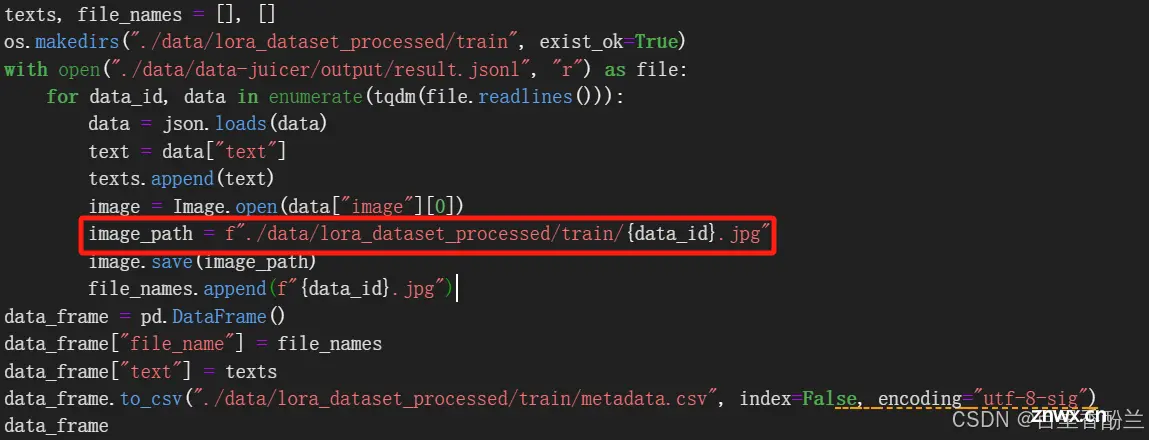
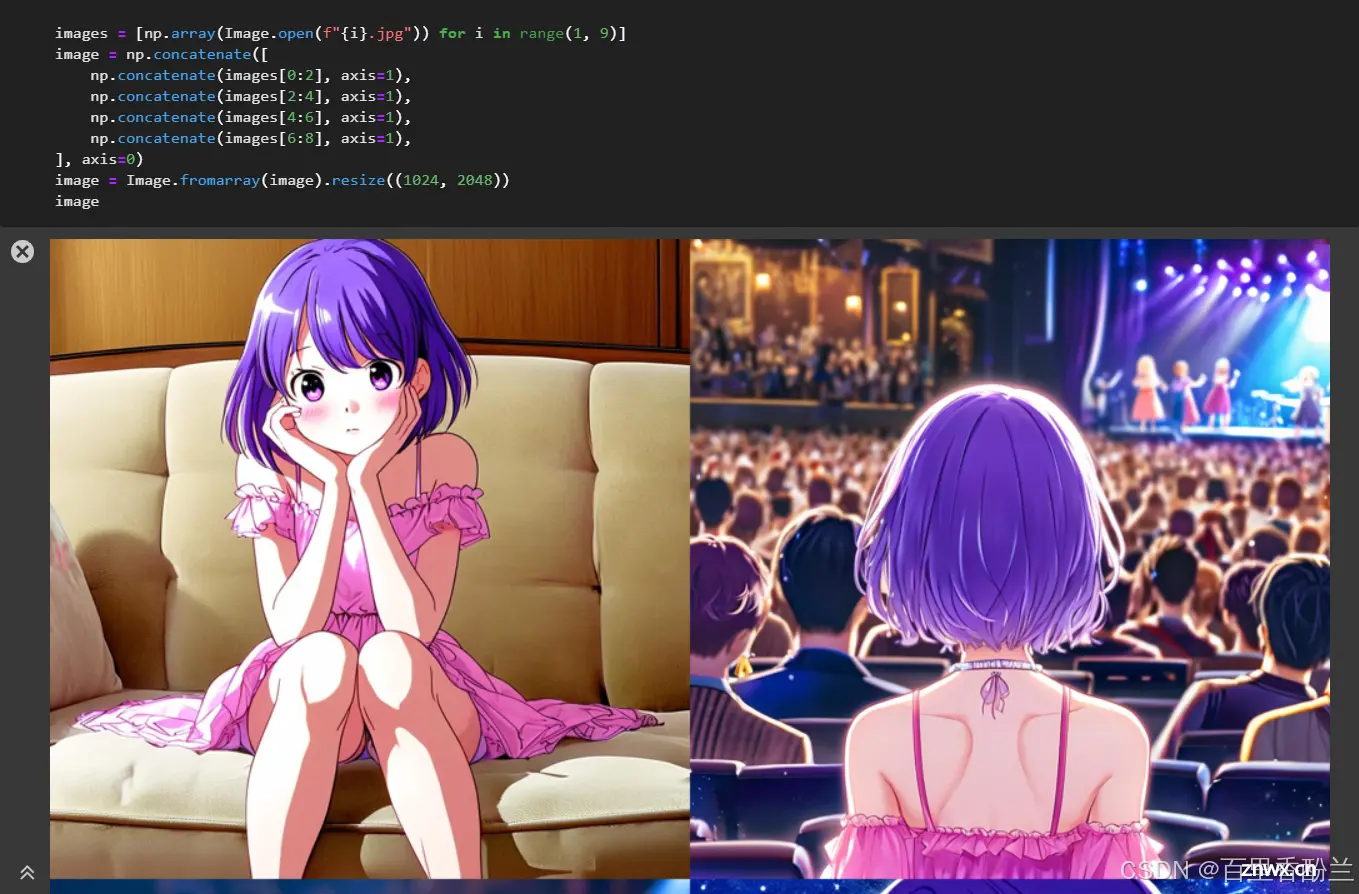

在运行BaseLine代码以后,就可以在左侧的文件夹看到AI生成的图片了。(我个人猜测现在市面上AIGC运营实习生啥的岗位是不是就是会跑模型,然后下面会改这些提示词就行了……?最多再用一下Lora啥的给模型指定一下风格,应该也不需要太多的……技能……吧,当然如果本来就是原画设计大佬当然另当别论了)

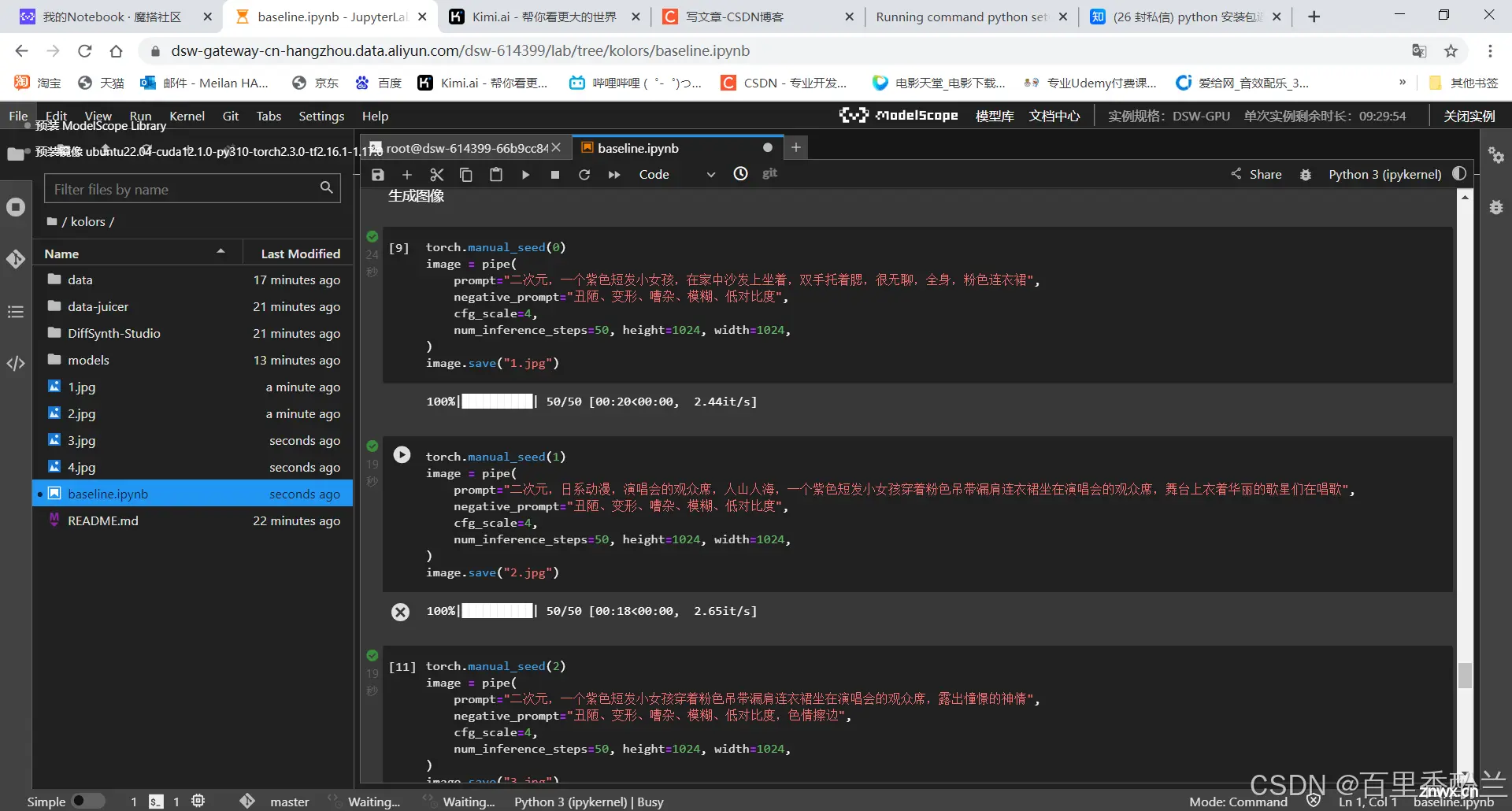
我一开始看到以前的老学员做出的图觉得很惊艳,觉得是这人好厉害能做角色一致性这么高、风格还这么稳定的Sample示例实在是强,结果我自己跑完这些代码以后发现生成的图居然和往届完全一模一样,是因为随机种子还是别的什么原因吗?就算是“紫色中等长发”“粉色连衣裙”这样的表达,也有成千上万种作图的方式才对,为什么就能做到这么精确的原样复制呢?

后面我在Q&A文档里提问了这个问题,感谢助教老师的耐心解答!果然跟我猜测的一样,是随机种子固定了的。

然后按照教程的指示上传需要的打卡资料即可。
别看步骤简单,我感觉这几步里面能挖掘的东西很多,夏令营期间乃至结束都可以继续深入研究钻研一下其中细节的奥妙,看这个答疑Q&A帖子里面都是满满的干货。有很多解决问题的实战经验可以借鉴。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。