Datawhale AI夏令营第四期 魔搭-AIGC方向 task01笔记
linghyu 2024-08-10 13:01:01 阅读 77
目录
赛题内容
可图Kolors-LoRA风格故事挑战赛
baseline要点讲解(请配合Datawhale速通教程食用)
Step1 设置算例及比赛账号的报名和授权
Step2 进行赛事报名并创建PAI实例
Step3 执行baseline
Step4 进行赛题提交
微调结果上传魔搭
lora 调参参数介绍及 SD 的基础知识点(拓展)
文生图基础知识介绍
提示词
Lora
从零入门AI生图原理&实践 是 Datawhale 2024 年 AI 夏令营第四期的学习活动(“AIGC”方向),基于魔搭社区“可图Kolors-LoRA风格故事挑战赛”开展的实践学习。
Datawhale官方的速通教程链接:Task 1 从零入门AI生图原理&实践
接下来我将对跑通 baseline 的细节和涉及到的知识点进行一些介绍和记录。
赛题内容
参赛者需在可图Kolors 模型的基础上训练LoRA 模型,生成无限风格,如水墨画风格、水彩风格、赛博朋克风格、日漫风格......
基于LoRA模型生成 8 张图片组成连贯故事,故事内容可自定义;基于8图故事,评估LoRA风格的美感度及连贯性
样例:偶像少女养成日记

相关作品在比赛品牌馆讨论区
可图Kolors-LoRA风格故事挑战赛
baseline要点讲解(请配合Datawhale速通教程食用)
Step1 设置算例及比赛账号的报名和授权
开通阿里云PAI-DSW试用
链接:https://free.aliyun.com/?spm=5176.14066474.J_4683019720.1.8646754cugXKWo&scm=20140722.M_988563._.V_1&productCode=learn
请根据教程开通免费试用,新用户需要注册并实名账号,建议使用支付宝进行登录,可以减少一些基础信息的填写。
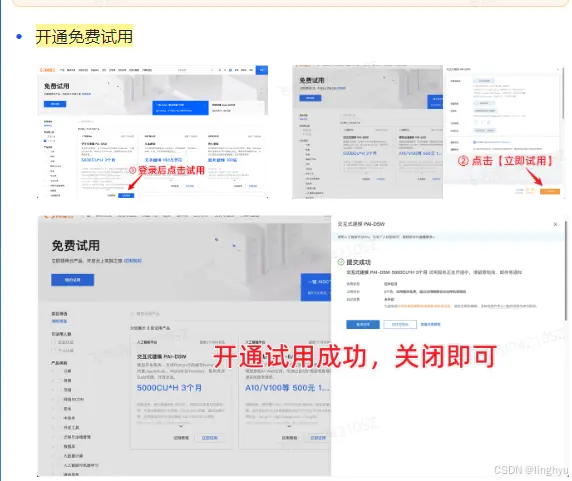
在魔塔社区进行账号授权
链接:https://www.modelscope.cn/my/mynotebook/authorization
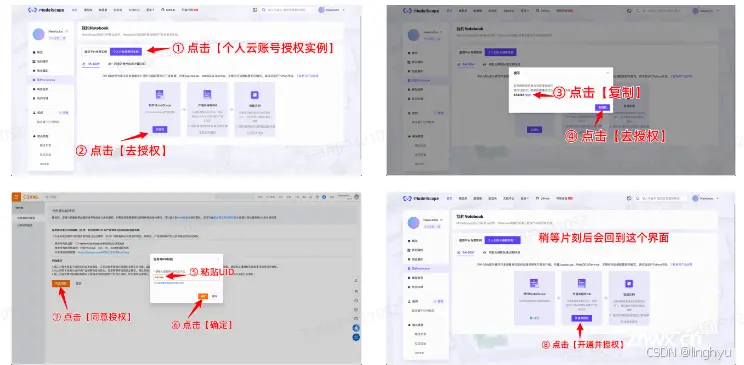
需要注意的是新用户需要先注册和绑定阿里云账号
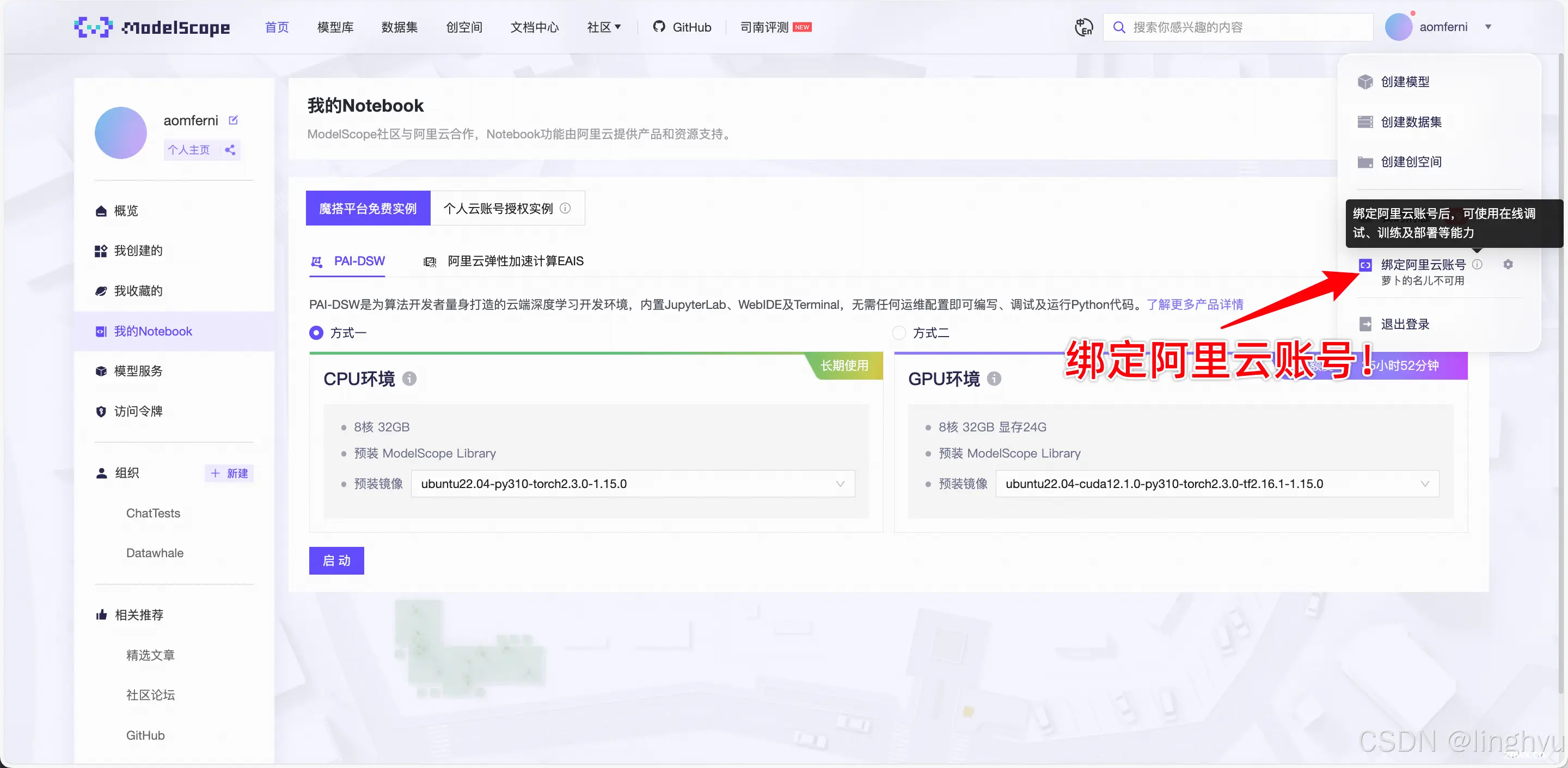
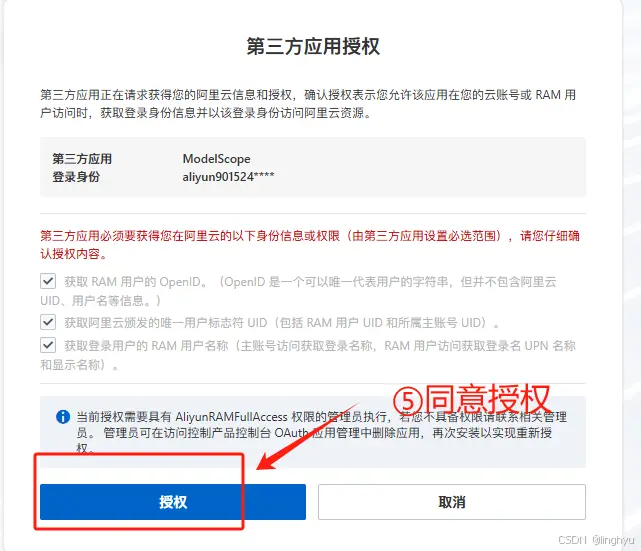
Step2 进行赛事报名并创建PAI实例
赛事链接:https://tianchi.aliyun.com/competition/entrance/532254
PAI实例:https://www.modelscope.cn/my/mynotebook/authorization
如果之前试用的额度已经过期,可使用魔搭的免费Notebook实例
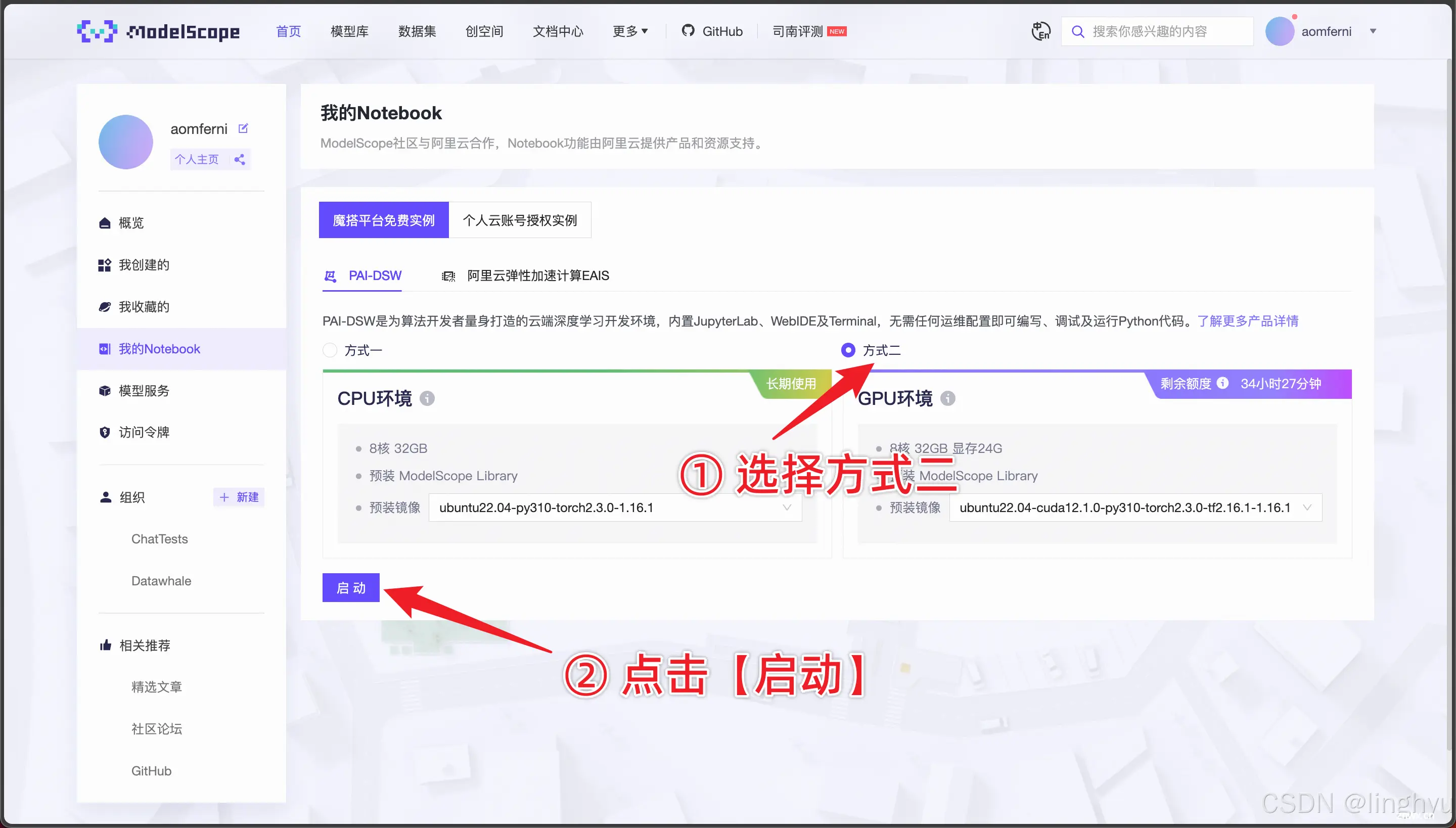
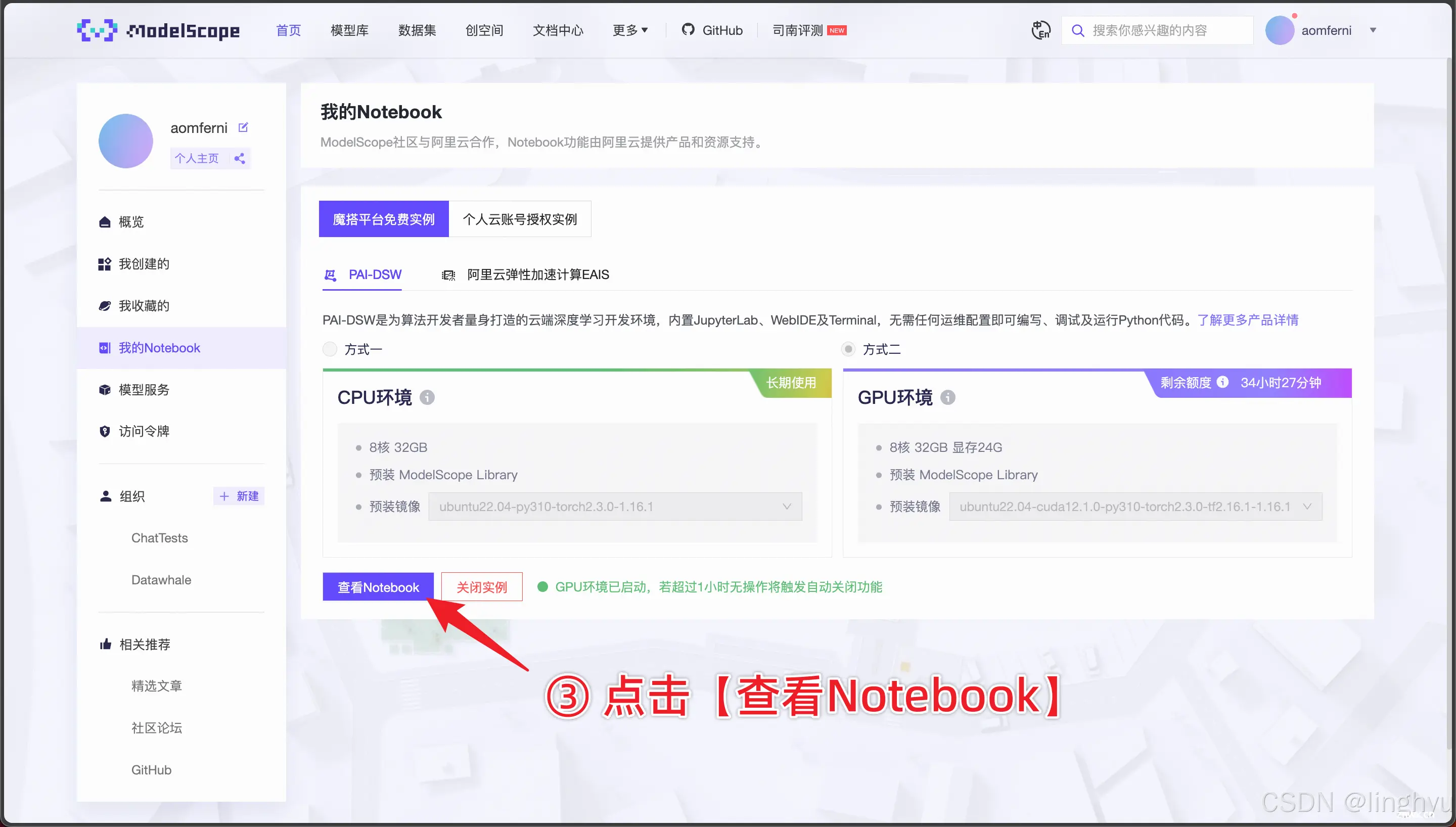
在账号注册、授权及报名参赛的环节不多赘述,速通教程已有详细的步骤指南,记得点开图片仔细查看。
Step3 执行baseline
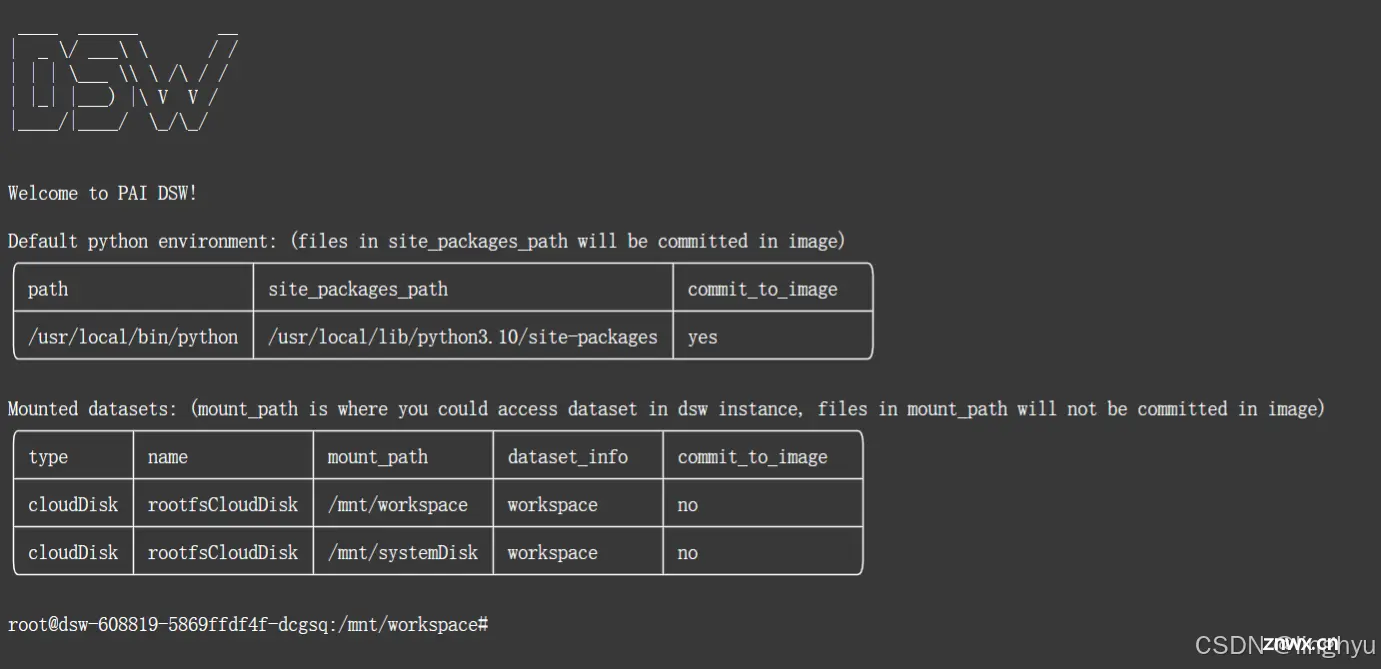
按照教程新建终端,粘贴命令回车执行,这一步是为了拉取远程的baseline文件,需要等待一段时间。相关科普博客:基础git命令使用方法
<code>git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors.git
拉取baseline后,可以在右侧文件中看到kolor文件夹,双击进入可以看到后缀.ipyhb的baseline文件,点击打开。
相关科普博客:
接下来执行运行环境的代码块,我们需要安装 Data-Juicer 和 DiffSynth-Studio
Data-Juicer:数据处理和转换工具,旨在简化数据的提取、转换和加载过程DiffSynth-Studio:高效微调训练大模型工具
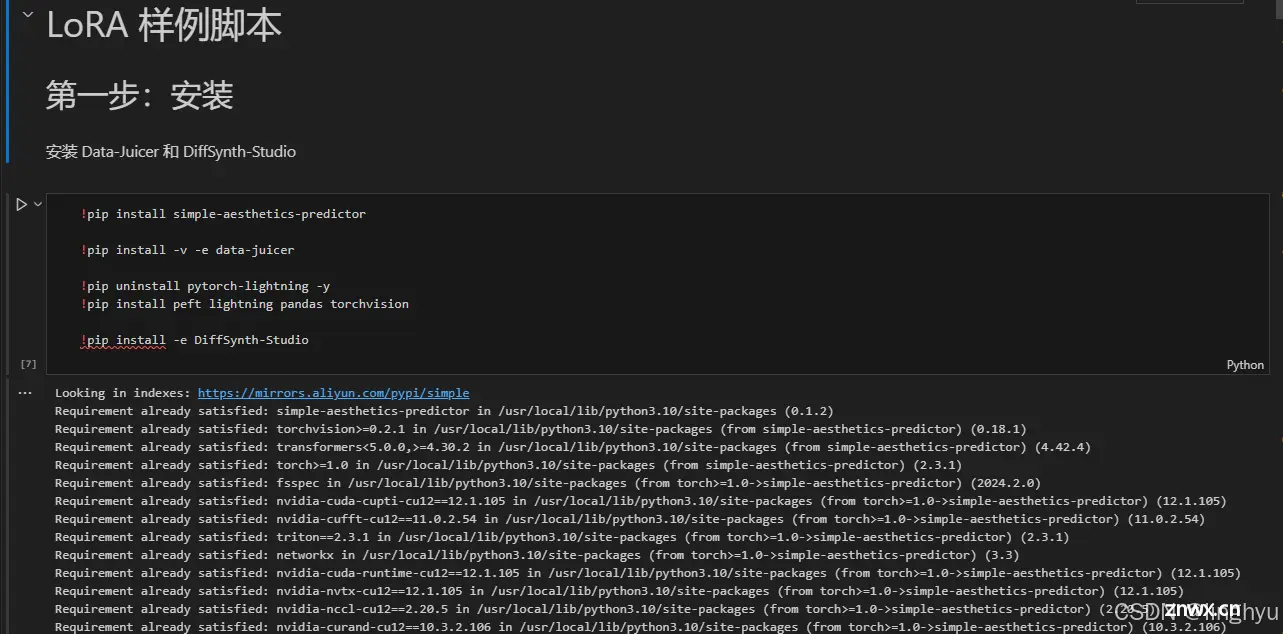
有些时候因为网络及代理的问题,环境的安装容易缺漏,建议多执行几次,代码不会重复安装
安装完成后,重启kernel,不重启容易爆显存影响baseline运行
接下来请依次执行下载数据集、数据处理
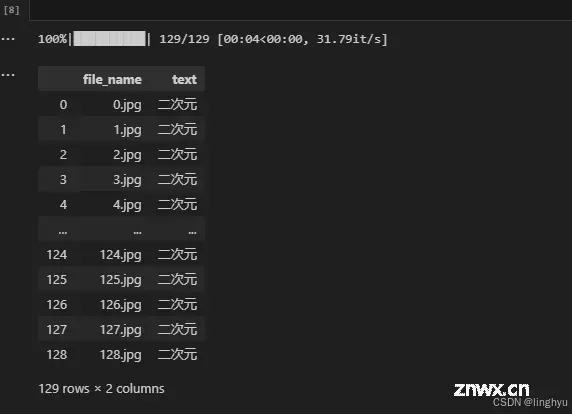
在这里留一个小问题:在模型训练之前,在数据集的处理上有没有更优的方法来让数据集更优质呢?是否需要进行一些转换、模块的引入及数据清洗呢?
接下来开始进行模型微调训练:
下载模型

查看训练脚本传入参数
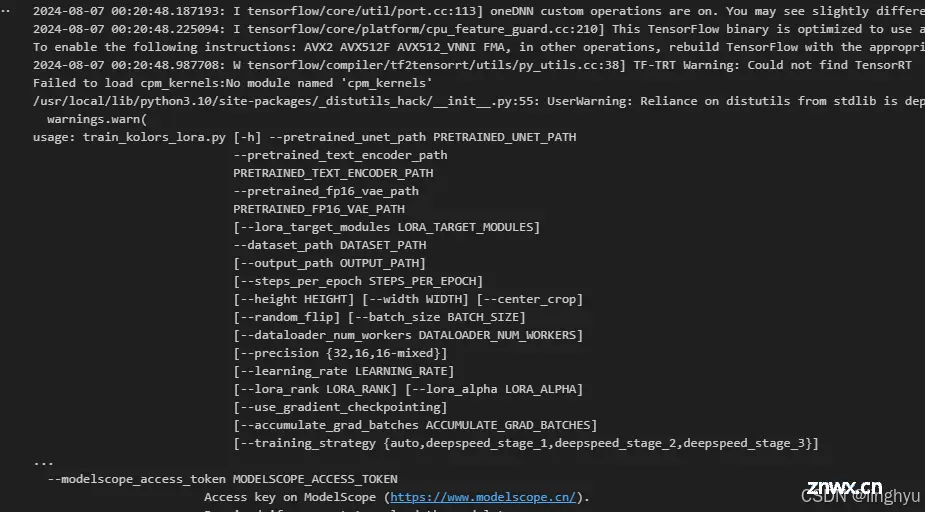
开始训练

调参对于微调模型训练尤关重要,涉及到参数量、优化器类型、训练策略等等...一个好的参数配置可以让微调模型的效果出人意料。
在后面我会附上自己整理的 lora 调参参数介绍及 Stable Diffusion(SD) 的基础知识,感兴趣可以滑下文章尾部进行查看。

最后我们加载我们所微调的模型并进行输出
<code>from diffsynth import ModelManager, SDXLImagePipeline
from peft import LoraConfig, inject_adapter_in_model
import torch
def load_lora(model, lora_rank, lora_alpha, lora_path):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
init_lora_weights="gaussian",code>
target_modules=["to_q", "to_k", "to_v", "to_out"],
)
model = inject_adapter_in_model(lora_config, model)
state_dict = torch.load(lora_path, map_location="cpu")code>
model.load_state_dict(state_dict, strict=False)
return model
# Load models
model_manager = ModelManager(torch_dtype=torch.float16, device="cuda",code>
file_path_list=[
"models/kolors/Kolors/text_encoder",
"models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors",
"models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors"
])
pipe = SDXLImagePipeline.from_model_manager(model_manager)
# Load LoRA
pipe.unet = load_lora(
pipe.unet,
lora_rank=16, # This parameter should be consistent with that in your training script.
lora_alpha=2.0, # lora_alpha can control the weight of LoRA.
lora_path="models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt"code>
)
调整prompt,设置你想要的图片风格,依次修改8张图片的描述

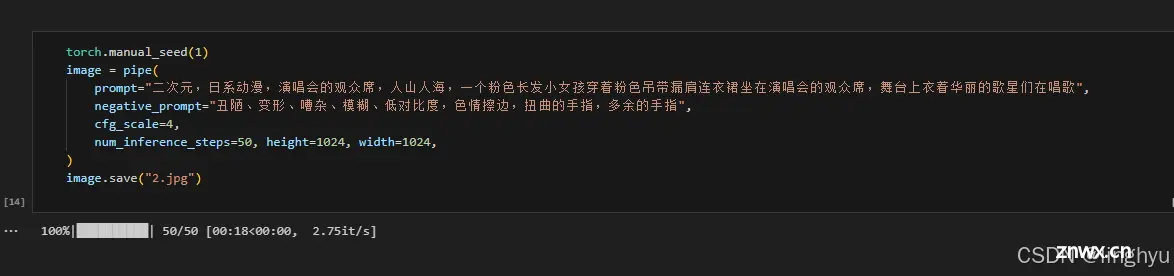
提示词也有一些讲究,比如优质的提示词、提示词的排序(越靠前的提示词影响比重越大)、提示词书写策略、Embedding 模型介入。这些对出图效果也同样重要。同样的,我也会在后面的介绍中讲到,让我们先继续跑baseline。
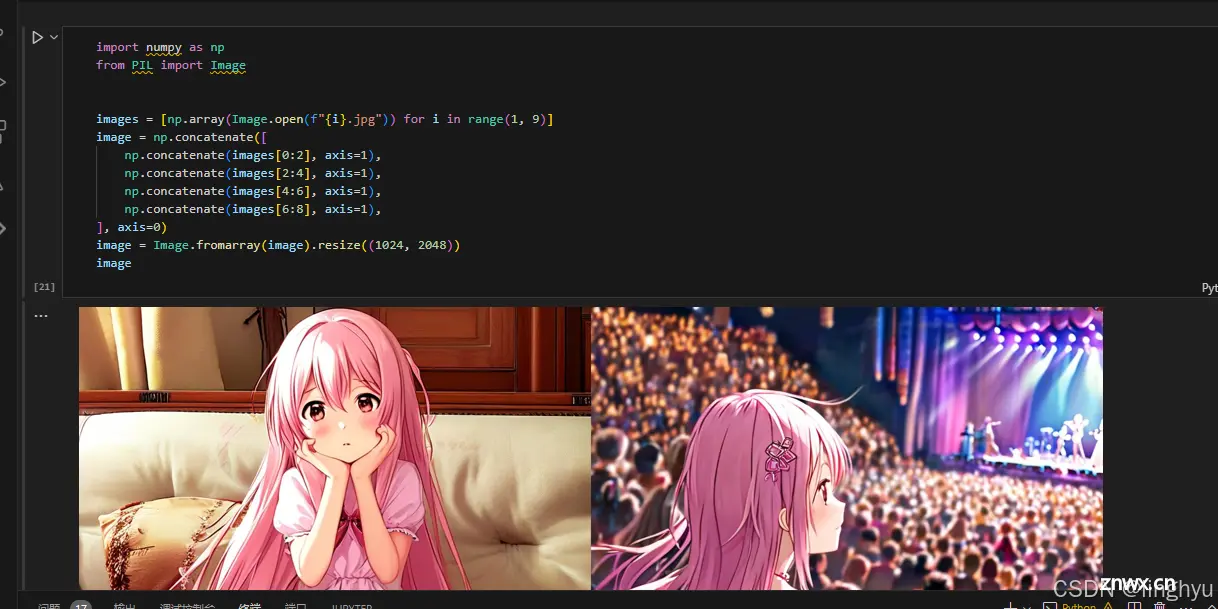
至此,微调训练和模型出图已经全部完成啦

Step4 进行赛题提交
将微调结果上传魔搭
链接:https://www.modelscope.cn/models/create
执行代码后,将模型文件和示例图下载到本地
<code>mkdir /mnt/workspace/kolors/output & cd
cp /mnt/workspace/kolors/models/lightning_logs/version_0/checkpoints/epoch\=0-step\=500.ckpt /mnt/workspace/kolors/output/
cp /mnt/workspace/kolors/1.jpg /mnt/workspace/kolors/output/
点击魔搭链接,创建模型,中文名称建议格式:队伍名称-可图Kolors训练-xxxxxx
在提交过程的中的基础模型,是指你在训练过程及后续复现时使用的底模类型。一般来说SD XL的实现精度会更高,在训练过程中需要同步设置SD XL,在初步跑通 baseline 时使用基础即可,博主在提交的时候是选用的SD2.1,可参考选用。
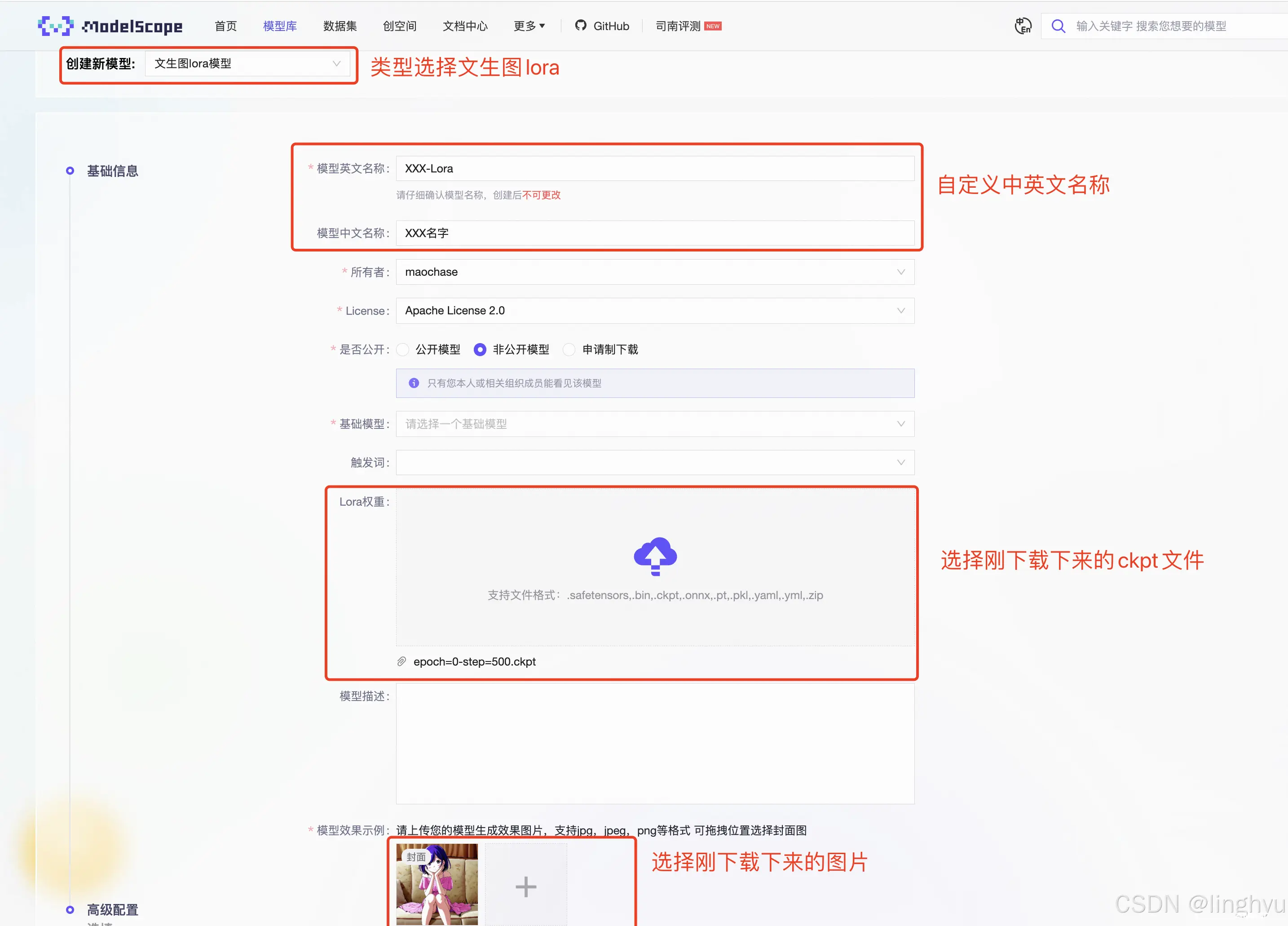
点击创建提交就完成啦!恭喜你已经顺利跑通了baseline。
记得完成后及时关闭你正在运行的实例,别让算力偷偷溜走了
别忘记打卡&在群里接龙!

lora 调参参数介绍及 SD 的基础知识点(拓展)
文生图基础知识介绍
文生图主要以SD系列基础模型为主,以及在其基础上微调的lora模型和人物基础模型等。
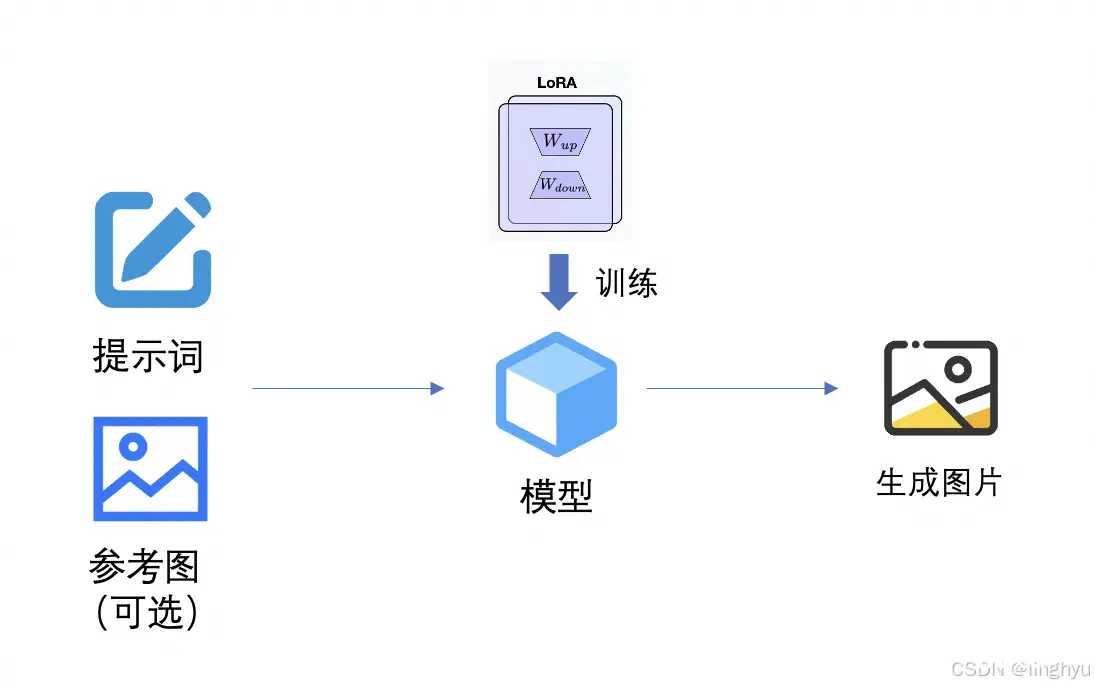
接下来,我们简单了解下提示词、lora、ComfyUI和参考图控制这些知识点。
提示词
提示词很重要,一般写法:主体描述,细节描述,修饰词,艺术风格,艺术家
反向prompt推荐(会更推荐使用英文 prompt,因为底层调用 sd 时是输入 英文prompt的): text, word, cropped, low quality, normal quality, username, watermark, signature, blurry, soft, soft line, curved line, sketch, ugly, logo, pixelated, lowres, vase,
提高出图质量正向prompt推荐: a highly detailed European style bed room,elegant atmosphere,rtx lighting,global illuminations,a sense of understated sophistication,8k resolution,high quality,photorealistic,highly detailed,
Lora
Stable Diffusion中的Lora(LoRA)模型是一种轻量级的微调方法,它代表了“Low-Rank Adaptation”,即低秩适应。Lora不是指单一的具体模型,而是指一类通过特定微调技术应用于基础模型的扩展应用。在Stable Diffusion这一文本到图像合成模型的框架下,Lora被用来对预训练好的大模型进行针对性优化,以实现对特定主题、风格或任务的精细化控制。
那我们 lora 训练的最终目的是什么呢?训练的本质在于找出当前训练集的最优解,优素材取决于不同角度、不同形态、灯光、图片质量。
在Tag类型上,需要包括主题、动作、主要特征、视角、光影效果等其他,如果在训练过程中对某一个特征不打Tag,则将成为固定模型特征。
参考:Stable Diffusion Lora locon loha训练参数设置 - 知乎 (zhihu.com)
出图指引(SD WebUI):
描述内容prompt:主体、表情、服装、场景、环境、镜头、灯光、风格、画质、渲染器
靠前的Tag权重较高,适当运用括号法则、数字法则、混合
采样步数:数越高,细节多渲染慢,建议范围在20~40
采样器:karras去噪快
a噪点不居中,关键词识别度稍低,更具灵活度
DPM 建议使用DPM++SDE karras
文字相关度CFG scale : 建议在4~9
Seed 随机种子:-1随机,其他为已经完成出图的风格编号
常见出图参数说明:
batch_size 并行数量,如果增加bs,需要同步增加学习率对应 根号2 倍率
enable_bucket 开启bucket来支持不同长宽比的训练图片
resolution 训练时图片的分辨率
flip_aug 水平翻转数据增强,要求训练目标对左右方向不敏感
random_crop 随机裁剪数据增强
color_aug 颜色数据增强,要求训练目标对颜色不敏感
shuffle_caption 打乱文本描述
keep_tokens 保证最前面的几个 tag 不被打乱,默认为1
num_repeats 学习次数,每张图片在一个epoch内重复多少次,实物30~100,人像20~30
常见训练参数说明:
pretrained_model_name_or_path:
指向基底模型的路径,支持 .ckpt、.safetensors 和 Diffusers 格式。
output_dir:指定模型保存的路径
output_name:指定模型保存的文件名(不含扩展名)
save_model_as:模型保存格式,ckpt, safetensors, diffusers, diffusers_safetensors.
dataset_config:指向 TOML 配置文件的路径
max_train_steps:指定训练的steps数,lora总step在1500~6000,checkpoint在30000+
total optimization steps = Imag * repeat * epoch / batch_size
max_train_epochs:指定训练的epochs数,10~15,根据loss值
save_every_n_steps:每隔多少 steps 保存模型
save_every_n_epochs:每隔多少 epochs 保存模型
mixed_precision:使用混合精度来节省显存。
gradient_checkpointing:用于节省显存,但是会增加训练时间。
xformers / mem_eff_attn:用于节省显存。
clip_skip:使用 CLIP 的倒数第几层特征,最好与基底模型保持一致。
network_dim: 学习精细度,为Unet-lr的1/10~1/2,场景128,人物32~128
network_alpha:用于保证训练过程的数值稳定性,防止下溢,默认为1.
network_weights: 加载预训练的 LoRA 模型并继续训练。
network_train_unet_only:只训练 U-Net 的 LoRA
network_train_text_encoder_only:只训练 Text Encoder 的 LoRA
optimizer_type:选择优化器,推荐使用AdamW8bit le-4 , DAdaptation 1
AdamW8bit 对于显存小的用户更友好。Lion 优化器的使用率也很高,学习率需要设置得很小(如AdamW优化器下的 1/3,或者更小)
使用 DAdaptation 时,应当将学习率设置在1附近,text_encoder_lr 可以设置成1,或者小一点,0.5之类。使用DAdaptation 时,推荐将学习率调整策略调整为 constant 。
learning_rate:设置学习率,推荐le-4
unet_lr:对 U-Net 的 LoRA 单独设置学习率
一般可以设为 1e-4,覆盖--learning rate 的设置。
text_encoder_lr:为 Text Encoder 的 LoRA 单独设置学习率
一般可以设为 5e-5,覆盖--learning rate 的设置。
lr_scheduler / --lr_warmup_steps / --lr_scheduler_num_cycles / --lr_scheduler_power:设置学习率 scheduler、warmup. 学习率调度器,有以下几种
["cosine_with_restarts", "cosine", "polynomial", "constant", "constant_with_warmup", "linear"],推荐使用 cosine_with_restarts,它会使学习率从高到低下降,变化速度先慢后快再慢
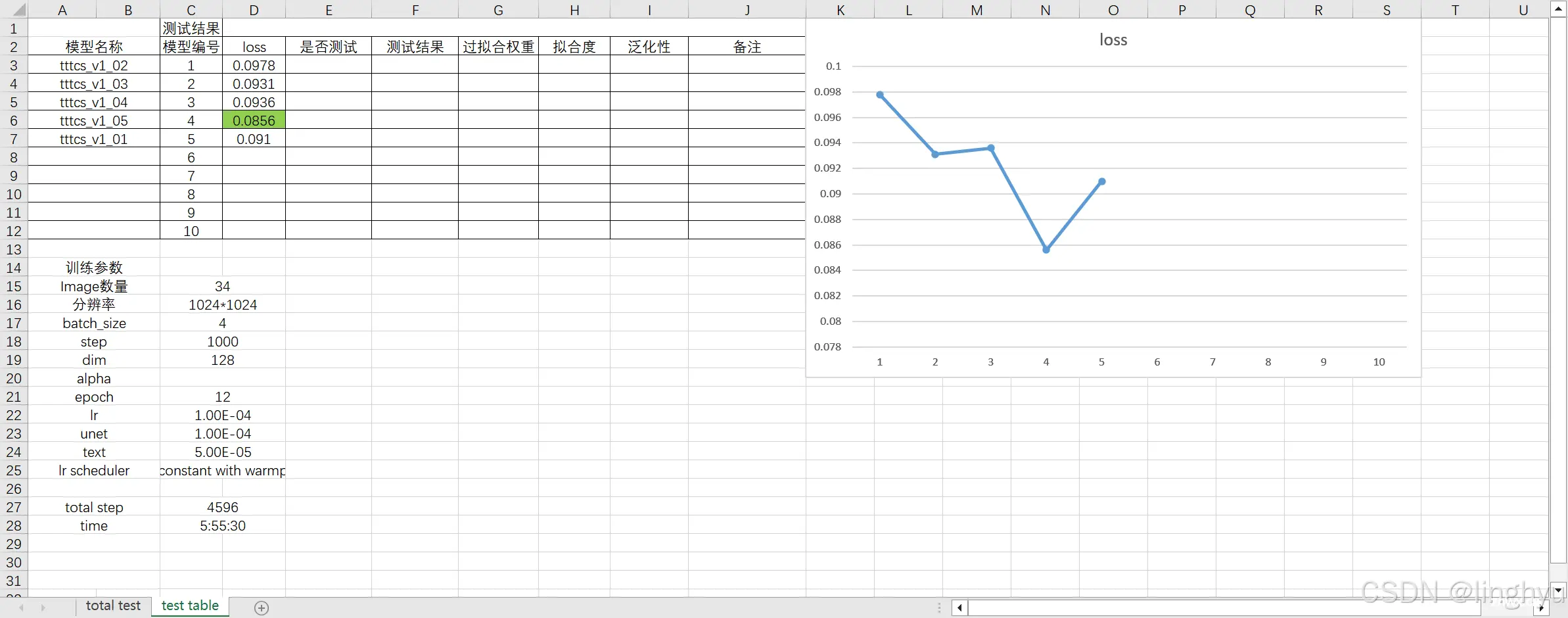
小tip: 在后续进行微调参数的优化训练时建议将每一次的训练参数及效果记录下来,方便进行优化调参,可以很直观的看出训练效果的对比。示例如下:
完成baseline的同学们想过如何让出图变得更稳定一些呢?比如一些线稿?场景?人物动作?那么 ControlNet 可能可以帮到你
ControlNet
ControlNet是一种用于精确控制图像生成过程的技术组件。它是一个附加到预训练的扩散模型(如Stable Diffusion模型)上的可训练神经网络模块。扩散模型通常用于从随机噪声逐渐生成图像的过程,而ControlNet的作用在于引入额外的控制信号,使得用户能够更具体地指导图像生成的各个方面(如姿势关键点、分割图、深度图、颜色等)。
下面附上 ControlNet 导图,可以先了解一下。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。