Datawhale X 魔搭 AI夏令营 第四期魔搭-AIGC文生图方向Task1笔记
Pluses 2024-08-12 12:31:01 阅读 70
(赛题链接:可图Kolors-LoRA风格故事挑战赛_创新应用大赛_天池大赛)
(学习链接:从零入门AI生图原理&实践)
速通指南
1、开通阿里云PAI-DSW试用
(阿里云链接:阿里云免费试用)
最后使用成功,关闭即可
2、在魔搭社区进行授权
(ps:据说在阿里云网站也可以找到运行的地方,可以不用去魔搭社区,魔搭社区可能会在使用高峰期流量过大而加载很慢,想要探索一下的小伙伴可以去找找阿里云的,启动速度会比魔搭要快的,但是整体的运行还是和魔搭社区同步的,以下附上简易版阿里云进入途径)
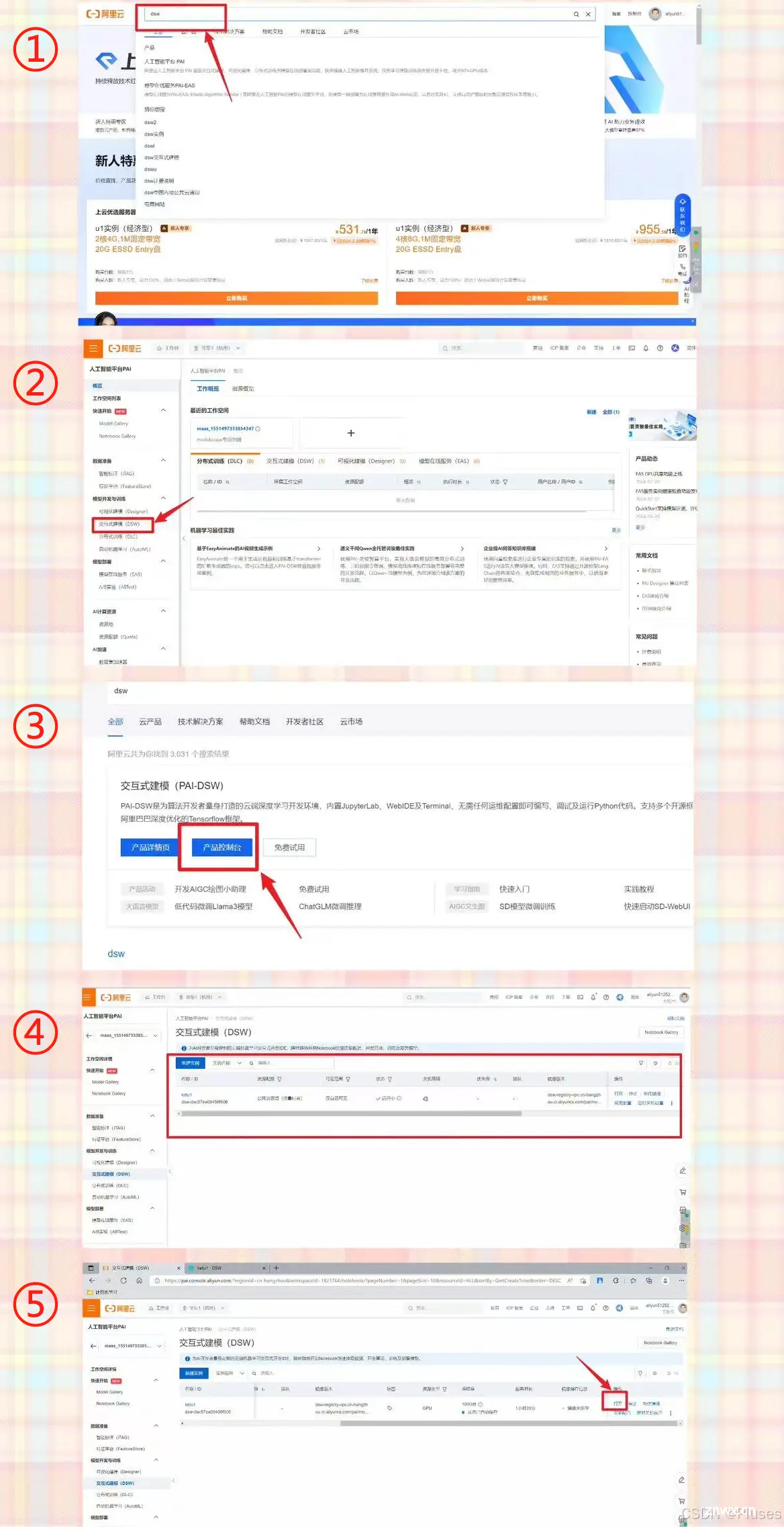
(魔搭链接:我的Notebook · 魔搭社区)
(ps:如果5000小时试用已经过期了可使用魔搭的免费Notebook实例,如下)
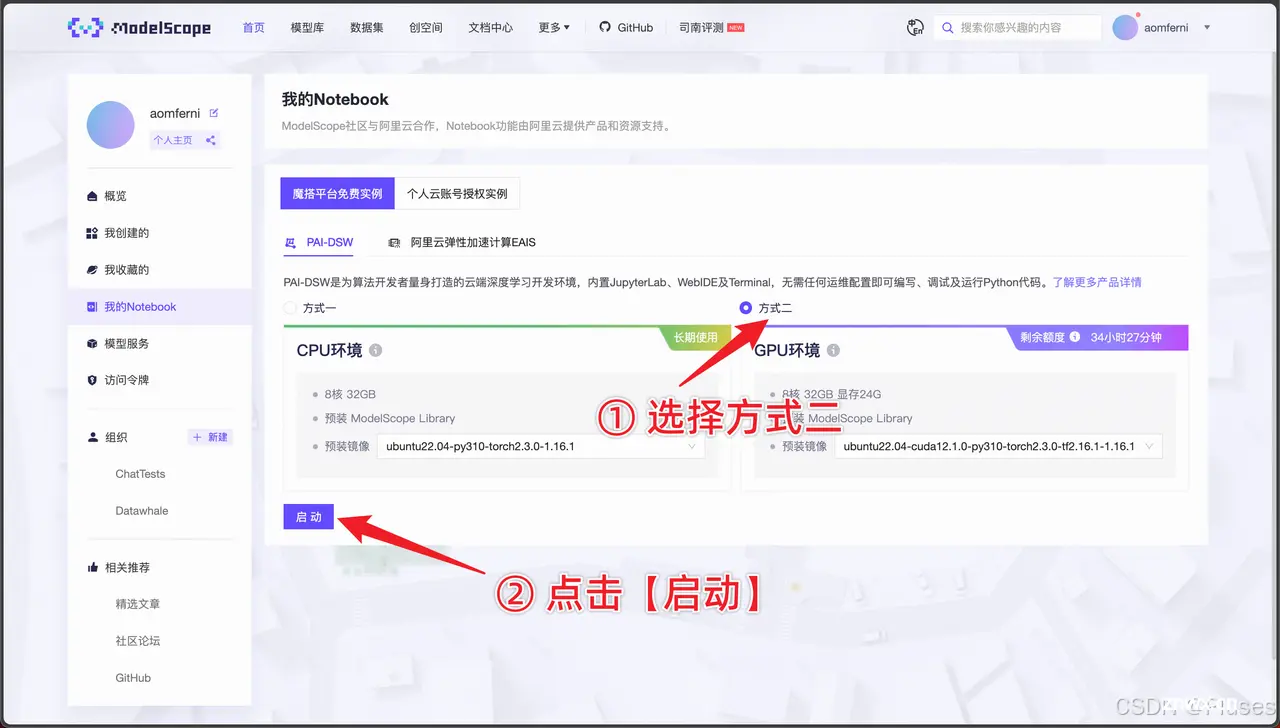
如果Notebook的试用也用完了,那就只能付费使用阿里云了,暂时没有别的解决方法
3、跑通baseline

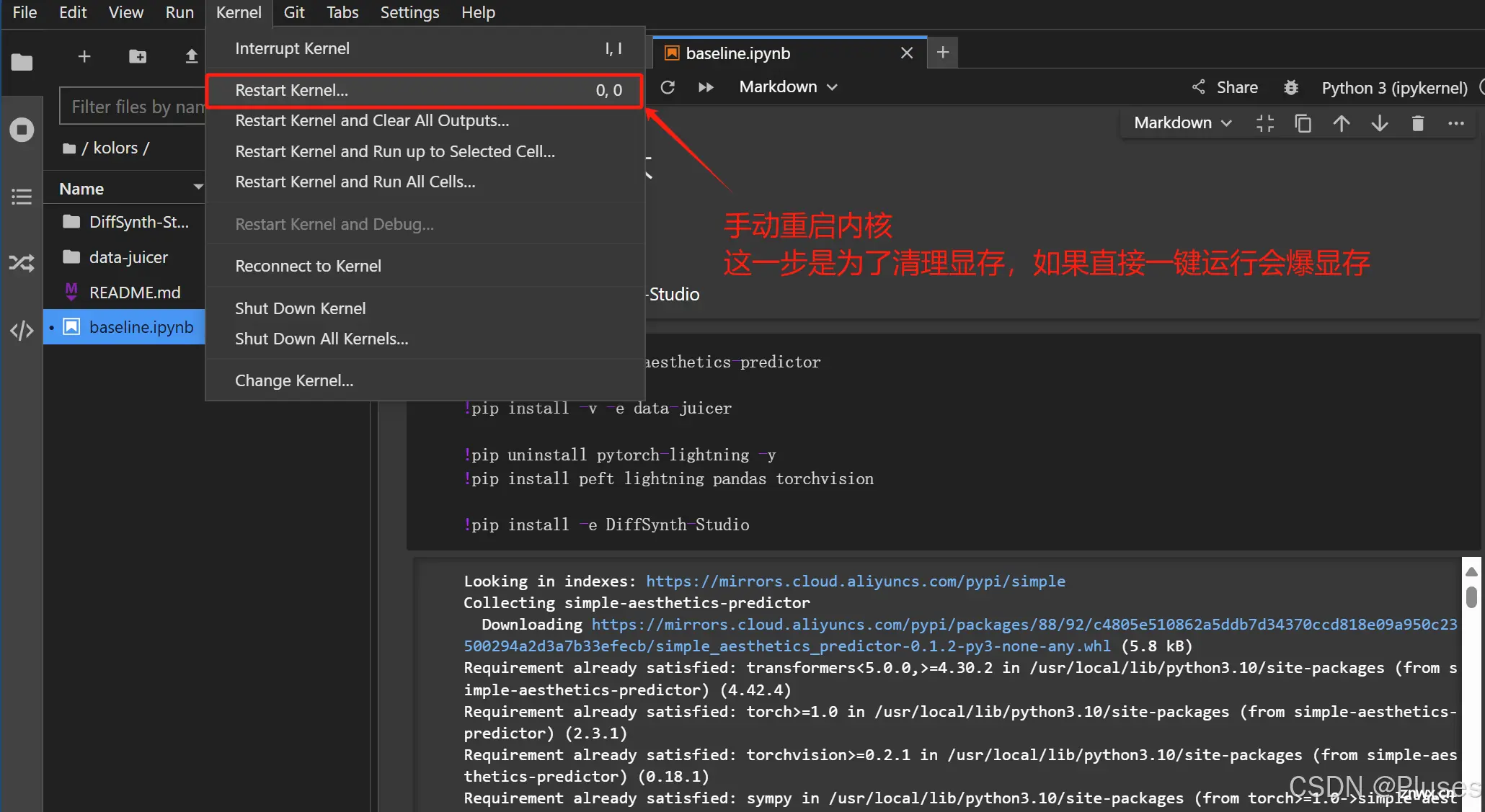
然后依次点击每一个模块的运行按钮(第一次的时候要这样,后面就可以直接点击>>按钮一键运行了)
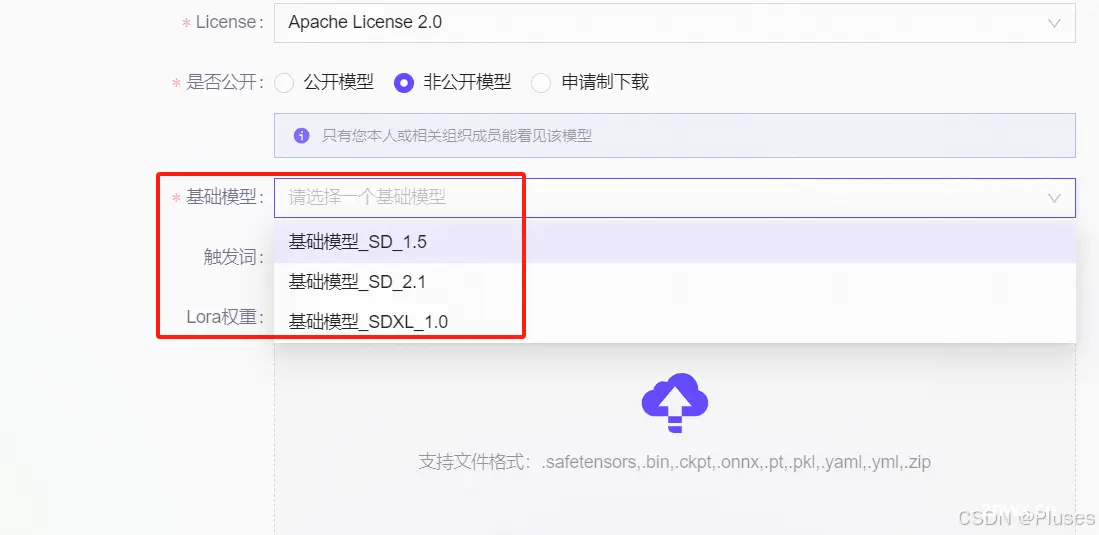
提交的时候,这个基础模型三个都可选噢~
赛题解读
1、赛题内容

2、作品提交

(模型上传链接:魔搭模型库 和 LoRA 上传地址)
(作品发布链接:比赛品牌馆讨论区)
3、评分标准

Baseline代码解读
1、环境安装
<code>!pip install simple-aesthetics-predictor
!pip install -v -e data-juicer
!pip uninstall pytorch-lightning -y
!pip install peft lightning pandas torchvision
!pip install -e DiffSynth-Studio
!符号用于在Jupyter Notebook或IPython环境中执行系统命令。-v标志表示安装时显示详细信息(verbose mode),-e标志表示通过编辑模式(editable mode)安装。在编辑模式下安装的包将链接到当前的开发环境,使得对包的修改能够即时生效。卸载名为pytorch-lightning的Python包,并通过-y标志自动确认卸载过程中的所有提示。peft: 一个用于性能评估的工具。
2、下载数据集
#下载数据集
from modelscope.msdatasets import MsDataset
ds = MsDataset.load(
'AI-ModelScope/lowres_anime',
subset_name='default',code>
split='train',code>
cache_dir="/mnt/workspace/kolors/data"code>
)
import json, os
from data_juicer.utils.mm_utils import SpecialTokens
from tqdm import tqdm
os.makedirs("./data/lora_dataset/train", exist_ok=True)
os.makedirs("./data/data-juicer/input", exist_ok=True)
with open("./data/data-juicer/input/metadata.jsonl", "w") as f:
for data_id, data in enumerate(tqdm(ds)):
image = data["image"].convert("RGB")
image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg")
metadata = {"text": "二次元", "image": [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg"]}
f.write(json.dumps(metadata))
f.write("\n")
使用了 MsDataset 类从指定的数据集加载数据。具体来说:
'AI-ModelScope/lowres_anime' 是数据集的名称或标识符。split='train'code> 表示加载训练集部分的数据。cache_dir="/mnt/workspace/kolors/data"code> 是数据集的缓存目录,数据集可能会在此处进行下载或存储。os.makedirs 函数创建目录:
./data/lora_dataset/train:存储训练集图像的目录。./data/data-juicer/input:存储数据预处理输入文件的目录。open("./data/data-juicer/input/metadata.jsonl", "w") as f 打开文件 metadata.jsonl 用于写入数据预处理后的元数据,jsonl 文件格式是每行一个 JSON 对象,适合存储和处理大型数据集的元数据。for data_id, data in enumerate(tqdm(ds)): 迭代数据集中的每个数据项:
data["image"].convert("RGB") 将图像数据转换为RGB格式。image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg") 将处理后的图像保存到 ./data/lora_dataset/train 目录下,文件名为 {data_id}.jpg。metadata = {"text": "二次元", "image": [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg"]} 创建图像的元数据,包括文本描述和图像文件路径。f.write(json.dumps(metadata)) 将元数据以 JSON 格式写入 metadata.jsonl 文件。
3、处理数据集,保存数据处理结果
data_juicer_config = """
# global parameters
project_name: 'data-process'
dataset_path: './data/data-juicer/input/metadata.jsonl' # path to your dataset directory or file
np: 4 # number of subprocess to process your dataset
text_keys: 'text'
image_key: 'image'
image_special_token: '<__dj__image>'
export_path: './data/data-juicer/output/result.jsonl'
# process schedule
# a list of several process operators with their arguments
process:
- image_shape_filter:
min_width: 1024
min_height: 1024
any_or_all: any
- image_aspect_ratio_filter:
min_ratio: 0.5
max_ratio: 2.0
any_or_all: any
"""
with open("data/data-juicer/data_juicer_config.yaml", "w") as file:
file.write(data_juicer_config.strip())
!dj-process --config data/data-juicer/data_juicer_config.yaml
import pandas as pd
import os, json
from PIL import Image
from tqdm import tqdm
texts, file_names = [], []
os.makedirs("./data/lora_dataset_processed/train", exist_ok=True)
with open("./data/data-juicer/output/result.jsonl", "r") as file:
for data_id, data in enumerate(tqdm(file.readlines())):
data = json.loads(data)
text = data["text"]
texts.append(text)
image = Image.open(data["image"][0])
image_path = f"./data/lora_dataset_processed/train/{data_id}.jpg"
image.save(image_path)
file_names.append(f"{data_id}.jpg")
data_frame = pd.DataFrame()
data_frame["file_name"] = file_names
data_frame["text"] = texts
data_frame.to_csv("./data/lora_dataset_processed/train/metadata.csv", index=False, encoding="utf-8-sig")code>
data_frame
(1)配置说明
data_juicer_config 是一个YAML格式的字符串,定义了数据处理的各种参数和操作流程。project_name 指定了项目名称为 'data-process'。dataset_path 指定了原始数据集的路径为 ./data/data-juicer/input/metadata.jsonl,这是之前生成的元数据文件路径。np 指定了并行处理数据的进程数为 4。text_keys 定义了文本数据在元数据中的键为 'text'。image_key 定义了图像数据在元数据中的键为 'image'。image_special_token 定义了特殊的图像标记为 <__dj__image>。export_path 指定了处理后的数据输出路径为 ./data/data-juicer/output/result.jsonl。process 定义了数据处理的操作流程:
image_shape_filter:过滤图像尺寸,保留宽度和高度均大于等于 1024 像素的图像。image_aspect_ratio_filter:过滤图像宽高比,保留宽高比在 0.5 到 2.0 之间的图像。
(2)执行说明
!dj-process 是一个命令行工具,用于执行数据处理任务。--config data/data-juicer/data_juicer_config.yaml 指定了配置文件的路径,告诉命令行工具按照配置文件中定义的流程处理数据。
(3)处理说明
os.makedirs("./data/lora_dataset_processed/train", exist_ok=True) 创建存储处理后数据的目录 ./data/lora_dataset_processed/train。
打开处理后的数据文件 ./data/data-juicer/output/result.jsonl,逐行读取每条数据
(4)保存数据
创建一个空的 Pandas 数据框 data_frame。将 file_names 列和 texts 列添加到数据框中。使用 to_csv 方法将数据框保存为 CSV 文件 ./data/lora_dataset_processed/train/metadata.csv,编码为 utf-8-sig,并且不包含行索引。
4、Lora微调
# 下载模型
from diffsynth import download_models
download_models(["Kolors", "SDXL-vae-fp16-fix"])
#模型训练
import os
cmd = """
python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py \
--pretrained_unet_path models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors \
--pretrained_text_encoder_path models/kolors/Kolors/text_encoder \
--pretrained_fp16_vae_path models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors \
--lora_rank 16 \
--lora_alpha 4.0 \
--dataset_path data/lora_dataset_processed \
--output_path ./models \
--max_epochs 1 \
--center_crop \
--use_gradient_checkpointing \
--precision "16-mixed"
""".strip()
os.system(cmd)
download_models(["Kolors", "SDXL-vae-fp16-fix"]):这行代码调用了 diffsynth 库中的 download_models 函数,用于下载指定的模型。
"Kolors" 是要下载的第一个模型的标识符。"SDXL-vae-fp16-fix" 是要下载的第二个模型的标识符。
模型训练说明
cmd 是一个包含要执行的命令的字符串变量,这个命令将在操作系统的 shell 中运行。--pretrained_unet_path models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors:指定预训练的 U-Net 模型路径。--pretrained_text_encoder_path models/kolors/Kolors/text_encoder:指定预训练的文本编码器路径。--pretrained_fp16_vae_path models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors:指定预训练的半精度 VAE 模型路径。--lora_rank 16:设置 Lora 模型的秩为 16。--lora_alpha 4.0:设置 Lora 模型的 alpha 参数为 4.0。--dataset_path data/lora_dataset_processed:指定训练数据集的路径。--output_path ./models:指定模型训练结果输出的路径。--max_epochs 1:设置最大训练轮数为 1。--center_crop:使用中心裁剪图像。--use_gradient_checkpointing:使用梯度检查点技术。--precision "16-mixed":设置训练精度为混合精度 16 位。
os.system(cmd):通过操作系统的 shell 执行存储在cmd变量中的命令。
5、加载微调好的模型
from diffsynth import ModelManager, SDXLImagePipeline
from peft import LoraConfig, inject_adapter_in_model
import torch
def load_lora(model, lora_rank, lora_alpha, lora_path):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
init_lora_weights="gaussian",code>
target_modules=["to_q", "to_k", "to_v", "to_out"],
)
model = inject_adapter_in_model(lora_config, model)
state_dict = torch.load(lora_path, map_location="cpu")code>
model.load_state_dict(state_dict, strict=False)
return model
# Load models
model_manager = ModelManager(torch_dtype=torch.float16, device="cuda",code>
file_path_list=[
"models/kolors/Kolors/text_encoder",
"models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors",
"models/kolors/Kolors/vae/diffusion_pytorch_model.safetensors"
])
pipe = SDXLImagePipeline.from_model_manager(model_manager)
# Load LoRA
pipe.unet = load_lora(
pipe.unet,
lora_rank=16, # This parameter should be consistent with that in your training script.
lora_alpha=2.0, # lora_alpha can control the weight of LoRA.
lora_path="models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt"code>
)
(1)导入所需的库和模块
diffsynth:包含了模型管理和图像处理流水线的相关功能。
(2)定义加载LoRA模型的函数
model:要加载 LoRA 的模型。
lora_rank:LoRA 的秩(rank)参数,影响适配器层的维度。
lora_alpha:LoRA 的 alpha 参数,用于控制 LoRA 适配器的权重。
lora_path:LoRA 模型的路径,即预训练模型的权重文件路径。
LoraConfig:使用 peft 库中的 LoraConfig 类来配置 LoRA 的参数,包括秩、alpha 值、初始化权重方式和目标模块。
inject_adapter_in_model:通过 peft 库中的 inject_adapter_in_model 函数将 LoRA 适配器注入到模型中。
torch.load(lora_path, map_location="cpu")code>:加载预训练的 LoRA 模型的权重。
model.load_state_dict(state_dict, strict=False):将加载的权重应用到模型中,strict=False 表示允许部分加载。
(3)加载模型和应用LoRA
ModelManager:使用 diffsynth 中的 ModelManager 类来管理模型,指定了模型的数据类型为 torch.float16,设备为 "cuda"(GPU)。
file_path_list:指定了需要加载的模型文件的路径列表,包括文本编码器、U-Net 和 VAE 模型。
SDXLImagePipeline.from_model_manager(model_manager):使用 ModelManager 创建 SDXLImagePipeline,这是一个图像处理流水线,用于处理图像数据。
pipe.unet = load_lora(...):调用之前定义的 load_lora 函数,将加载的 LoRA 模型应用到 SDXLImagePipeline 的 U-Net 模型 (pipe.unet) 上。
6、图片生成
torch.manual_seed(0)
image = pipe(
prompt="二次元,一个紫色短发小女孩,在家中沙发上坐着,双手托着腮,很无聊,全身,粉色连衣裙",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("1.jpg")
torch.manual_seed(1)
image = pipe(
prompt="二次元,日系动漫,演唱会的观众席,人山人海,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,舞台上衣着华丽的歌星们在唱歌",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("2.jpg")
torch.manual_seed(2)
image = pipe(
prompt="二次元,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,露出憧憬的神情",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度,色情擦边",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("3.jpg")
torch.manual_seed(5)
image = pipe(
prompt="二次元,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙,对着流星许愿,闭着眼睛,十指交叉,侧面",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度,扭曲的手指,多余的手指",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("4.jpg")
torch.manual_seed(0)
image = pipe(
prompt="二次元,一个紫色中等长度头发小女孩穿着粉色吊带漏肩连衣裙,在练习室练习唱歌",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("5.jpg")
torch.manual_seed(1)
image = pipe(
prompt="二次元,一个紫色长发小女孩穿着粉色吊带漏肩连衣裙,在练习室练习唱歌,手持话筒",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("6.jpg")
torch.manual_seed(7)
image = pipe(
prompt="二次元,紫色长发少女,穿着黑色连衣裙,试衣间,心情忐忑",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("7.jpg")
torch.manual_seed(0)
image = pipe(
prompt="二次元,紫色长发少女,穿着黑色礼服,连衣裙,在台上唱歌",code>
negative_prompt="丑陋、变形、嘈杂、模糊、低对比度",code>
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("8.jpg")
import numpy as np
from PIL import Image
images = [np.array(Image.open(f"{i}.jpg")) for i in range(1, 9)]
image = np.concatenate([
np.concatenate(images[0:2], axis=1),
np.concatenate(images[2:4], axis=1),
np.concatenate(images[4:6], axis=1),
np.concatenate(images[6:8], axis=1),
], axis=0)
image = Image.fromarray(image).resize((1024, 2048))
image
(1)图片生成模块
每个 torch.manual_seed(x) 设置了一个特定的随机种子,确保每次生成的图像是确定性的。这在生成对比图时很有用。
使用 pipe 对象生成图像:
pipe 是一个 SDXLImagePipeline 对象,用于处理图像生成任务。prompt 参数包含了描述图像内容的文本。negative_prompt 是描述不希望出现在图像中的内容。cfg_scale=4 是指定了图像生成的缩放因子。num_inference_steps=50 指定了生成图像的推断步数。height=1024, width=1024 指定了生成图像的高度和宽度。
每次生成的图像都使用 image.save("X.jpg") 进行保存,其中 X 是保存的文件名,依次为 1.jpg 到 8.jpg。
(2) 组成图像模块
images 列表加载了之前保存的所有图像。使用 np.concatenate 函数将图像按照 2x2 的网格连接起来,形成一个大图像。Image.fromarray(image) 将连接后的 numpy 数组转换为 PIL 图像对象。resize((1024, 2048)) 将大图像调整为指定的大小。
相关知识介绍
1、文生图的常见模型与技术概念
(1)基础模型
①AE/VAE模型
AE/VAE模型本质上展示了一种"捕捉高维数据的数据特征,并将其映射与压缩成低维表示"的形式,是当前主流生成式模型的基础。它提供了两个重要能力:将高维信息捕捉分解为多个特征,以及将这些特征压缩映射为低维向量。
AE模型
在autoencoder模型中,我们加入一个编码器,它能帮我们把图片编码成向量。然后解码器能够把这些向量恢复成图片。
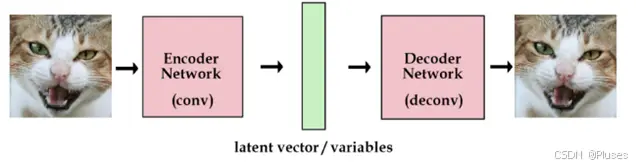
VAE模型
但我们想建一个产生式模型,而不是一个只是储存图片的网络。我们可以对编码器添加约束,就是强迫它产生服从单位高斯分布的潜在变量。正是这种约束,把VAE和标准自编码器给区分开来了。
现在,产生新的图片也变得容易:我们只要从单位高斯分布中进行采样,然后把它传给解码器就可以了,然后我们还需要在重构图片的精确度和单位高斯分布的拟合度上进行权衡。
我们可以让网络自己去决定这种权衡。对于我们的损失函数,我们可以把这两方面进行加和。一方面,是图片的重构误差,我们可以用平均平方误差来度量,另一方面。我们可以用KL散度来度量我们潜在变量的分布和单位高斯分布的差异。
为了优化KL散度,我们需要应用一个简单的参数重构技巧:不像标准自编码器那样产生实数值向量,VAE的编码器会产生两个向量:一个是均值向量,一个是标准差向量。

区分AE模型和VAE模型:
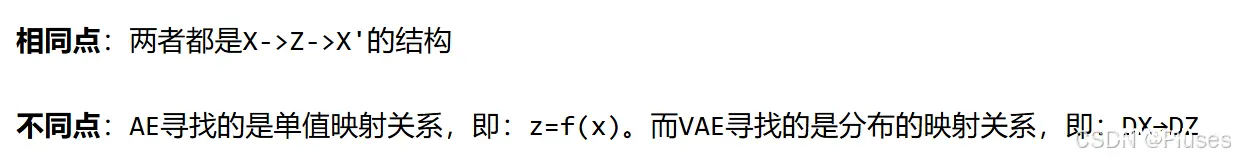
②GAN - 生成式对抗模型
GAN体现一种互相对抗、共同进化的思想,通过生成模型与判别模型的互相对抗,迫使双方的神经网络不断调整参数,最终使生成产物质量与训练集更加相似。
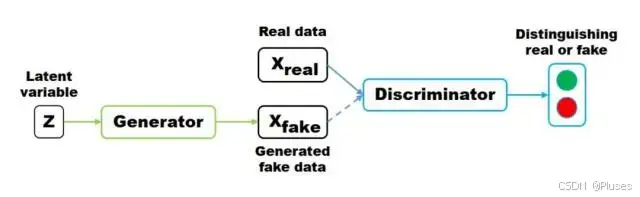
区分AE/VAE模型和GAN模型:

③Diffsion - 扩散模型
从单个图像样来看这个过程,扩散过程q就是不断往图像上加噪声直到图像变成一个纯噪声,下图为扩散过程,从 到最后的 就是一个马尔可夫链,表示状态空间中经过从一个状态到另一个状态的转换的随机过程。

逆扩散过程p就是从纯噪声生成一张图像的过程。

扩散模型包含两个步骤:

基础模型辨析

(2)技术能力
①CLIP跨模态模型
CLIP模型由一个图像编码器和一个文本编码器组成,它们共享参数。图像编码器负责将图像嵌入到语义空间中,而文本编码器则负责将文本嵌入到同样的语义空间中。CLIP模型使用了Transformer架构来实现这两个编码器,这种架构能够处理长距离的依赖关系,并且在大规模数据上进行预训练。

CLIP模型在多个任务上都表现出色,包括但不限于:
图像分类:给定一张图像,预测图像所属的类别。图像检索:给定一段文本描述,检索出与描述相匹配的图像。文本分类:给定一段文本,预测文本所属的类别。文本生成:根据给定的文本描述,生成与描述相匹配的图像。
②U-NET卷积神经网络
U-NET是一种以“提取特征-还原特征”为核心的卷积神经网络。
U-NET将整个分割过程分为收缩路径和扩展路径,原理有点类似扩散模型,只不过训练的并非噪声,而是特征。
在收缩路径过程中,模型会不断的提取图片特征,并逐渐降低图像分辨率,使模型获得从低分辨率图片中提取特征的能力;在扩展路径的过程中,模型会不断在低分辨率的图像上采样提取特征,逐步还原为高分辨率的图片。

③ADD对抗性扩散蒸馏算法
ADD 通过三步过程结合了 GAN 和扩散模型的元素:
初始化:该过程从噪声图像开始,就像扩散模型中的初始状态一样。扩散过程:噪声图像逐渐发生变化,变得更加结构化和详细。ADD 通过提取必要步骤来加速此过程,与传统扩散模型相比,减少了所需的迭代次数。对抗训练:在整个扩散过程中,鉴别器网络评估生成的图像并向生成器提供反馈。此对抗组件可确保图像的质量和真实感得到改善。

(3)现在常用的模型
①Stable Diffusion - 潜在扩散模型
Stable Diffusion是一种用于生成模型的框架,主要应用于文本到图像合成等任务。这一框架结合了扩散过程(Diffusion)和稳定化技术(Stabilization),旨在提高生成模型在长期生成过程中的稳定性和生成质量。

首先,SD模型被分为三个空间,即像素空间、潜在空间、条件模块。像素空间的所有运算都是高维的,潜在空间的运算都是低维的。
右侧为条件模块。高维数据进入后会经过两道工序处理:1.由CLIP映射为嵌入向量,建立与图像的关联;2.由VA模型将其压缩为低维向量。接着,映射入潜在空间中。
中间为潜在空间。低维数据映射入潜在空间后,由U-NET对低维数据的特征进行提取运算,获得低维的特征向量。同时,它会产生一张随机噪声图,将特征加入噪声图后,在潜在空间中进行扩散运算过程。
最后,模型于潜在空间完成了扩散运算,并将运算结果高维还原为一张符合文本要求的图片输出。
②SDXL Turbo - 实时的文图模型
SDXL Turbo 在传统的稳定扩散模型(SD)的基础上,加入了对抗性蒸馏技术。这项技术通过引入和修改对抗训练,让模型向着更少的除噪步骤进化。
ADD技术主要改动的部位在于潜在空间中的扩散生成过程(Diffusion Process),加入GAN对抗训练加速这一过程。
③LCM - 潜在一致性模型
引入AE技术,把训练集的原始图片映射入潜在空间,降低后续任务的算力负担;运用到无分类器引导技术,这种技术可以让模型在训练过程中不需要外部分类器参与(如:数据标签、文字提示等),只靠自己就可以提高与参考图片的特征相似度。模型在计算原始图片和生成图片的一致性损失时,采用跳步策略,通过跳过某些非关键步骤来加快计算过程。
(4)模型的调整与控制
①LORA - 低秩自适应模型
LORA想要使模型输出全新的需求产物,它采用的方法是:低秩矩阵。
②ControlNet:外置的控制型神经网络
ControlNet则是看向了另一个目标:让模型的输出内容变得有序。
引用自:
用大白话盘点AIGC文生图中的常见模型与技术概念
【VAE】原理篇
万字综述之生成对抗网络(GAN)
综述 - 扩散模型 - Diffusion Models
多模态模型之CLIP模型简介
深度学习| U-Net网络
2、Stable Diffusion框架

(1)扩散过程(Diffusion)
扩散过程是一种生成模型训练的策略,通过逐步增加噪声来改进图像生成的质量。在Stable Diffusion中,这种过程被用来逐步“扩散”或降低图像的清晰度,从而使生成器在更难的任务上进行训练。
(2)稳定化技术(Stabilization)
稳定化技术是指通过不同的方法来提高生成器的训练稳定性和生成图像的质量。在Stable Diffusion中,稳定化技术可以包括对抗训练、正则化方法或特定的优化策略,以确保生成过程不会失控并且生成的图像质量高。
(3)应用于文本到图像合成
Stable Diffusion框架特别适用于文本到图像合成任务,其中文本描述作为输入,生成模型将生成与描述相符的图像。通过扩散过程和稳定化技术,模型能够在生成图像时逐步提升质量,并保持生成的图像与输入文本之间的一致性和真实感。
(4)精细化控制和优化
通过Stable Diffusion中的Lora(Low-Rank Adaptation,低秩适应)技术,可以对预训练的大型模型进行微调,以实现对特定主题、风格或任务的精细化控制。这种方法能够增强模型的适应性和生成能力,使其能够更好地应对复杂的生成需求。
(5)实际应用和未来展望
Stable Diffusion不仅在艺术创作和图像合成领域具有潜力,还可以应用于虚拟现实、增强现实和医学图像生成等多个领域。随着深度学习技术的进步和硬件的提升,预计Stable Diffusion框架将继续发展和优化,为生成模型的训练和应用提供更广泛的可能性和效果。
参考链接:stable diffusion原理解读通俗易懂,史诗级万字爆肝长文!

https://mp.weixin.qq.com/s?__biz=MzI1MjQ2OTQ3Ng==&mid=2247617834&idx=1&sn=2b8f0f56b8b5b25e5ba1240e5705a6a8&chksm=e9e004a1de978db79be4b5d01829959efb839852f818fabc14e5020c0f26b132e5f044c3bf8f&scene=27Stable Diffusion 万字长文详解稳定扩散模型
https://zhuanlan.zhihu.com/p/669570827
3、LoRA模型

LoRA引入了两个矩阵A和B,如果参数W的原始矩阵的大小为d × d,则矩阵A和B的大小分别为d × r和r × d,其中r要小得多(通常小于100)。参数r称为秩。如果使用秩为r=16的LoRA,则这些矩阵的形状为16 x d,这样就大大减少了需要训练的参数数量。LoRA的最大的优点是,与微调相比,训练的参数更少,但是却能获得与微调基本相当的性能。
LoRA的一个技术细节是:在开始时,矩阵A被初始化为均值为零的随机值,但在均值周围有一些方差。矩阵B初始化为完全零矩阵。这确保了LoRA矩阵从一开始就不会以随机的方式改变原始W的输出。一旦A和B的参数被调整到期望的方向,那么W的输出中A和B的更新应该是对原始输出的补充。
LoRA还有相关变体LoRA+、VeRA、LoRA- fa、LoRA-drop、AdaLoRA、DoRA、Delta-LoRA等
引用自:LoRA及其变体概述
hahaha都看到这里了,要是觉得有用的话就辛苦动动小手点个赞吧!
上一篇: 【AI 大模型】OpenAI 接口调用 ② ( MacOS 中进行 OpenAI 开发 | 安装 openai 软件包 | PyCharm 中开发 Python 程序调用 OpenAI 接口 )
下一篇: AI绘画Stable Diffusion 零基础入门 —AI 绘画原理与工具介绍,万字解析AI绘画的使用教程
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。