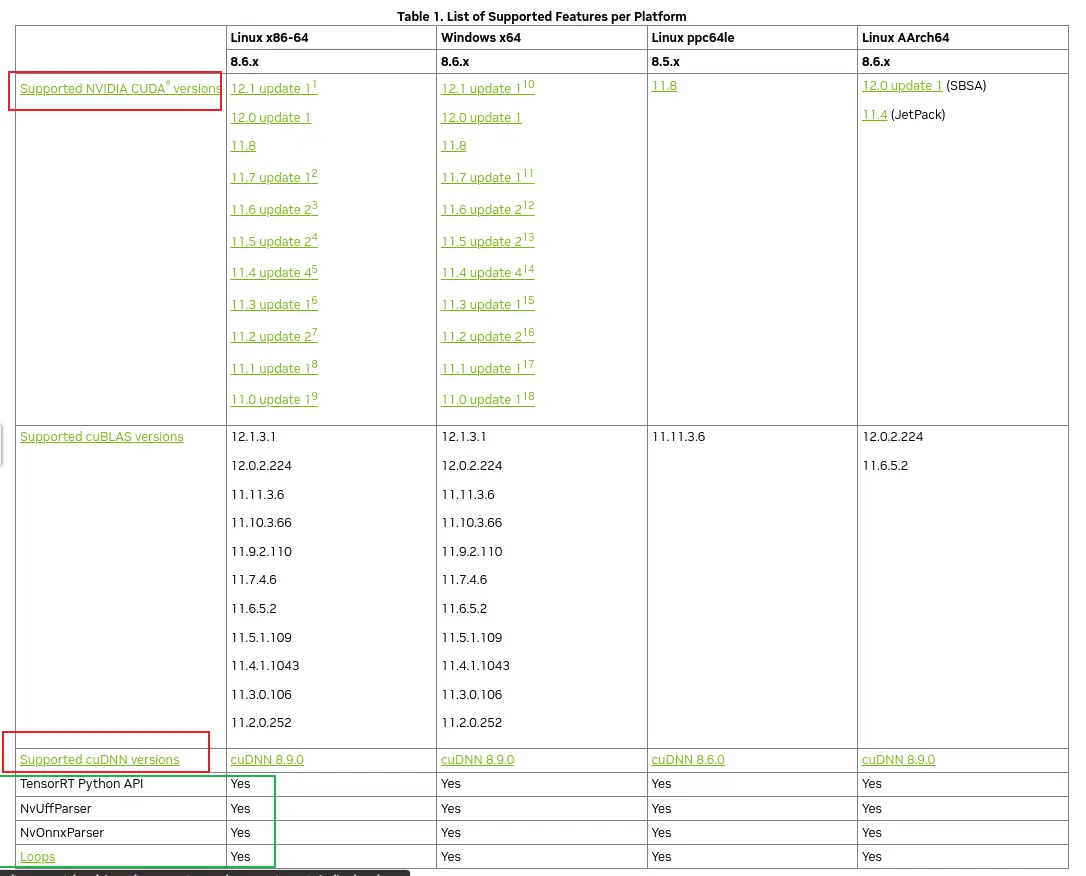
到graphsurgeon目录下,安装graphsurgeon,_ubuntu安装tensorrt...
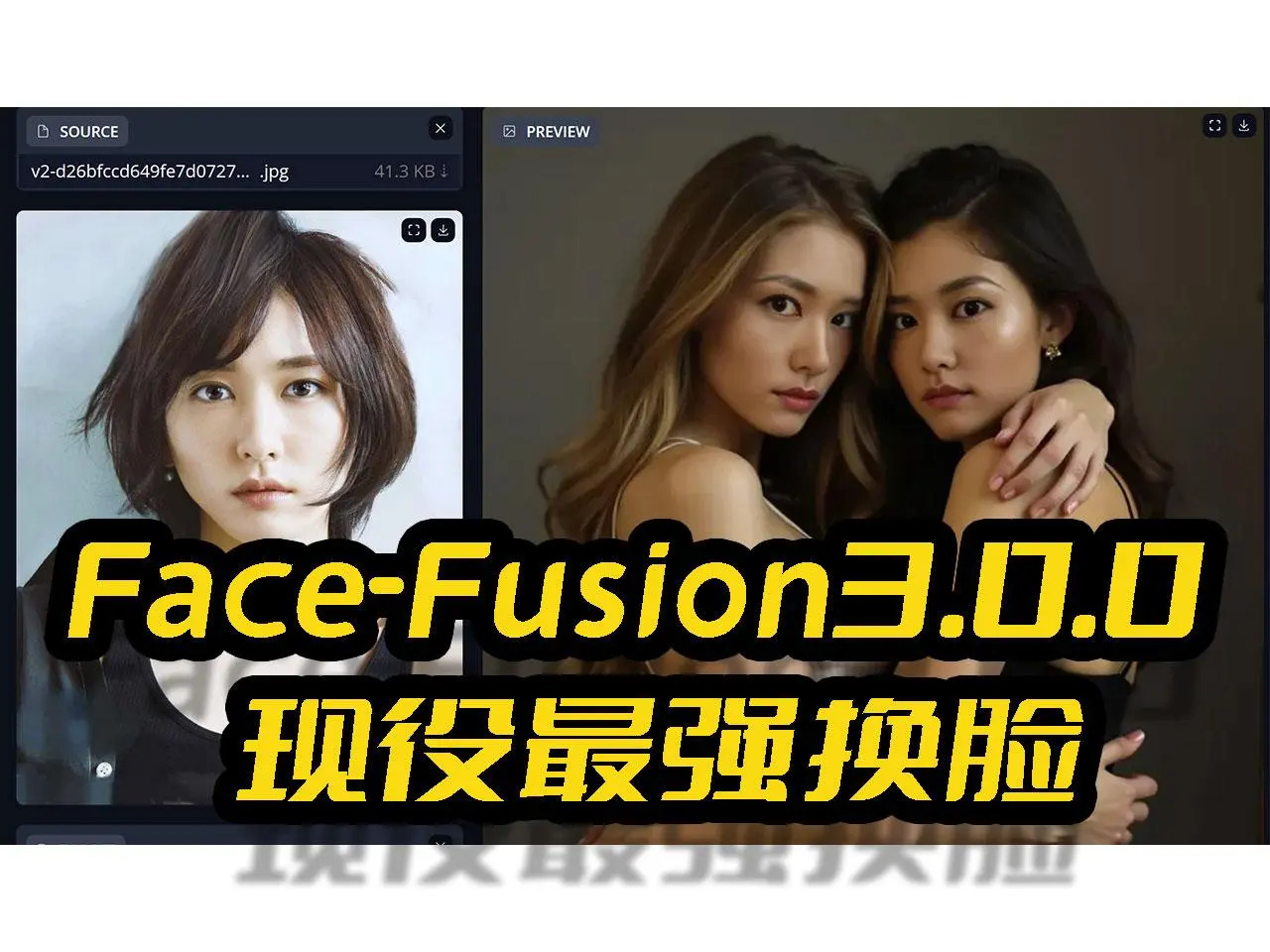
FaceFusion3.0.0大抵是现在最强的AI换脸项目,分享一下如何在Win11系统,基于最新的cuda12.6配合最新的cudnn9.4本地部署FaceFusion3.0.0项目,并且搭配Tensorrt10.4,提高推理速度和效率,让甜品级显卡也能爆发...

TensorRT是NVIDIA开发的一款高性能深度学习推理引擎,旨在优化神经网络模型并加速其在NVIDIAGPU上的推理性能。它支持多种深度学习框架,并提供一系列优化技术,以实现更高的吞吐量和更低的延迟...

推理服务器和推理后端介绍TensorRT+Triton环境搭建Bert模型转化为ONNX中间表示ONNX中间表示编译为TensorRT模型文件Triton服务端参数配置Triton服务端代码实现Triton服务端启动...
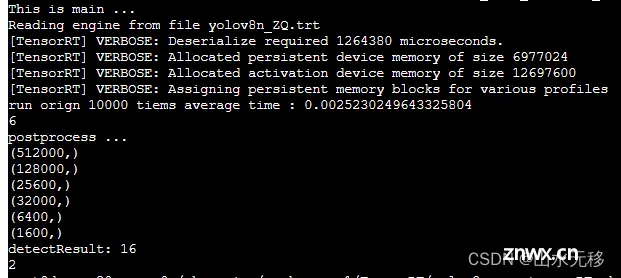
模型和完整仿真测试代码,放在github上参考链接。因为之前写了几篇yolov8模型部署的博文,存在两个问题:部署难度大、模型推理速度慢。该篇解决了这两个问题,且是全网部署难度最小、模型运行速度最快的部署方式。相...
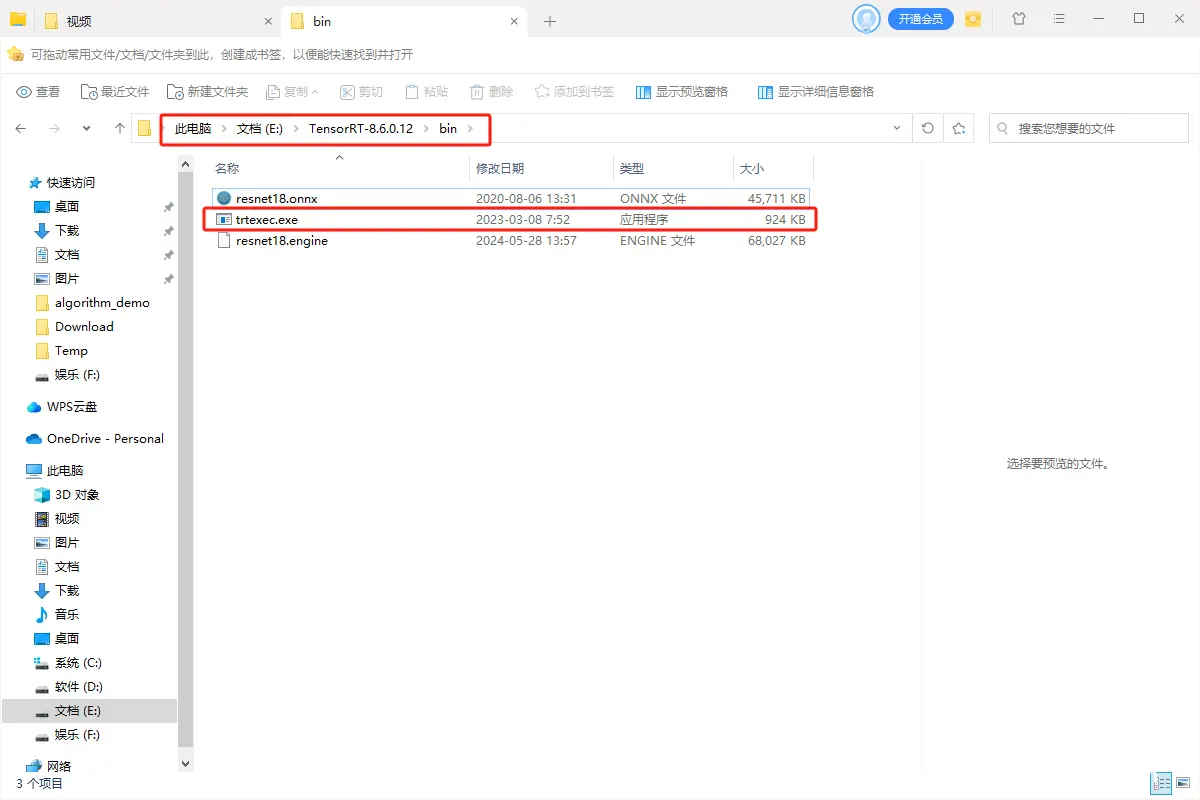
经典的一个TensorRT部署模型步骤为:onnx模型转engine、读取本地模型、创建推理引擎、创建推理上下文、创建GPU显存缓冲区、配置输入数据、模型推理以及处理推理结果(后处理)。_tensorrtc++...
是一个常用选项,用于自动确认所有提示。这意味着在运行命令时,不会提示用户进行确认操作,系统会自动回答“是”并继续执行。中科大:https://pypi.mirrors.ustc.edu.cn/simple/...
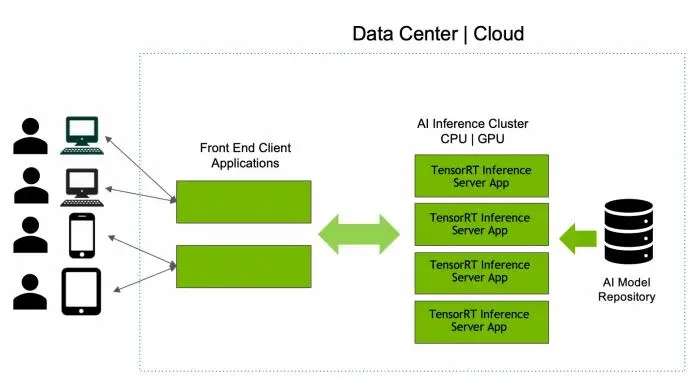
模型库中的每个模型都必须包含⼀个模型配置,该配置提供有关模型的必需和可选信息。)配置,使⽤当前最新的NVIDIA官⽅提供的镜像tritonserver:23.12-trtllm-python-py3,此版本镜像部...
TensorRT是一种,可以为深度学习应用提供的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Py...

TensorRT通过优化深度学习模型来提高推理速度,减少延迟。这对于实时处理应用(如视频分析、机器人导航等)至关重要。:TensorRT优化了模型以在GPU上高效运行,这意味着更低的内存占用和更高的吞吐量。对...