Ubuntu TensorRT安装
ytusdc 2024-10-11 12:37:01 阅读 81
什么是TensorRT
一般的深度学习项目,训练时为了加快速度,会使用多 GPU 分布式训练。但在部署推理时,为了降低成本,往往使用单个 GPU 机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如 caffe,TensorFlow 等。由于训练的网络模型可能会很大(比如,inception,resnet 等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如 squeezenet,mobilenet,shufflenet 等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。
而 TensorRT 则是对训练好的模型进行优化。 TensorRT 就只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进 TensorRT中,而不再需要依赖深度学习框架(Caffe、TensorFlow 等)
TensorRT 概述
TensorRT 是由 Nvidia 发布的一个机器学习框架,用于在其硬件上运行机器学习推理。其能针对 Nvidia 系列硬件进行优化加速,实现最大程度的利用 GPU 资源,提升推理性能。在训练了神经网络之后,TensorRT 可以对网络进行压缩、优化以及运行时部署,并且没有框架的开销。
TensorRT 部署流程主要有以下五步:
训练模型
导出模型为 ONNX 格式
选择精度
转化成 TensorRT 模型
部署模型
主要难度在第二步、第四步和第五步。其中 ONNX 格式的导出和运行设备无关,可以在自己的电脑上导出,其他设备上使用。而第四步转化得到的 TensorRT 模型文件是和设备绑定的,在哪个设备上生成就只能在该设备使用。
一般来说,模型训练和导出 ONNX 都在服务器上进行,得到 ONNX 模型。TensorRT 模型转化和部署都是在实际设备上进行。这样的话实际设备不需要 PyTroch 环境,只需要配置好 TensorRT 环境即可。
一、 版本选择
TensorRT需要和CUDA、cuDNN 的版本对应
1.1、查看CUDA和cuDNN版本
可以通过如下命令查看自己的CUDA和cuDNN版本
<code># 查看CUDA版本
nvcc -V
# 查看cuDNN版本
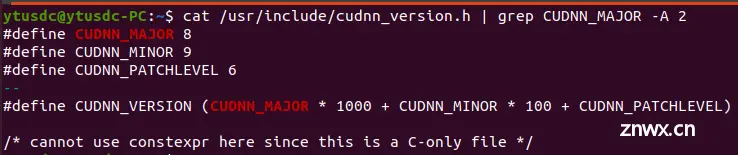
whereis cudnn_version.h # 找到 cudnn_version.h 文件路径
cat Path/cudnn_version.h | grep CUDNN_MAJOR -A 2
下图 cudnn的版本就是:8.9.6
1.2、选择合适的 TensorRT版本
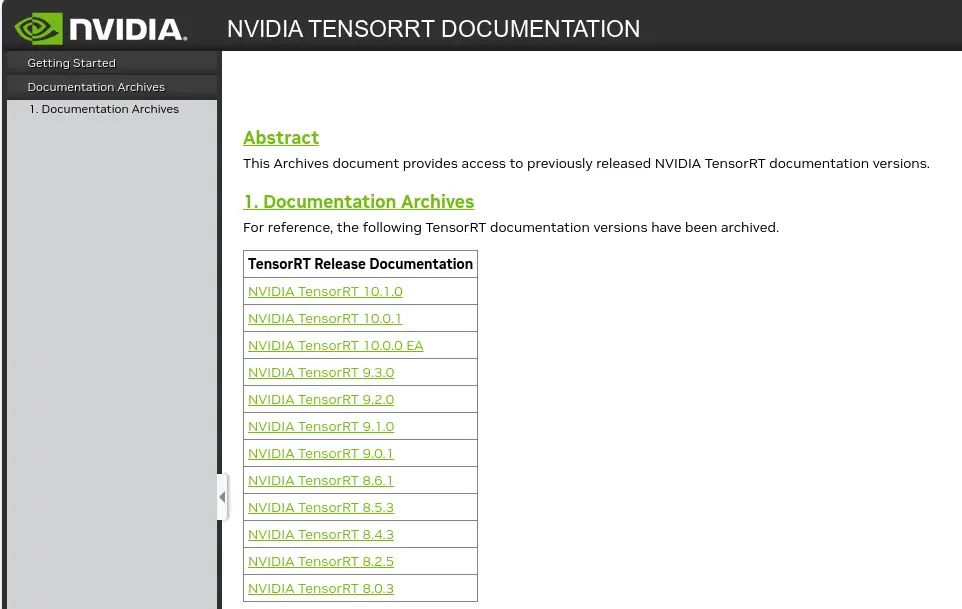
去官网: Documentation Archives :: NVIDIA Deep Learning TensorRT Documentation 查询自己的环境能使用的版本
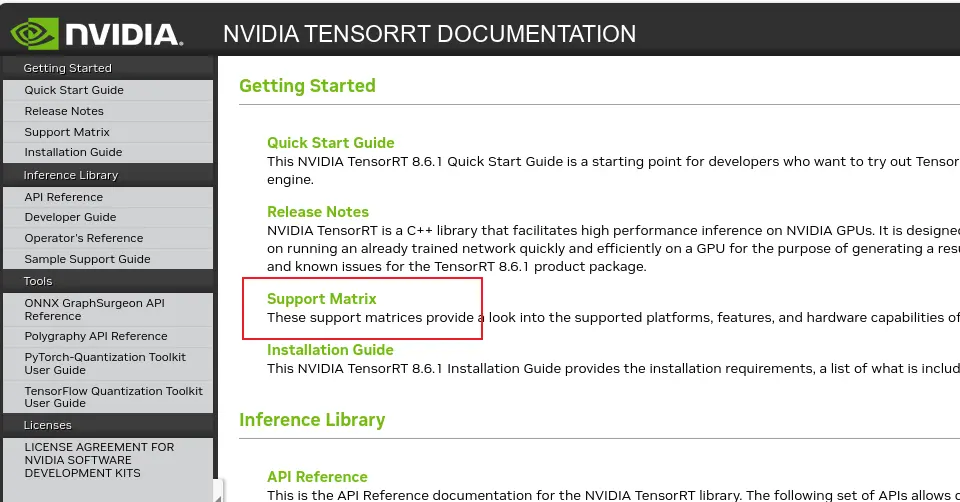
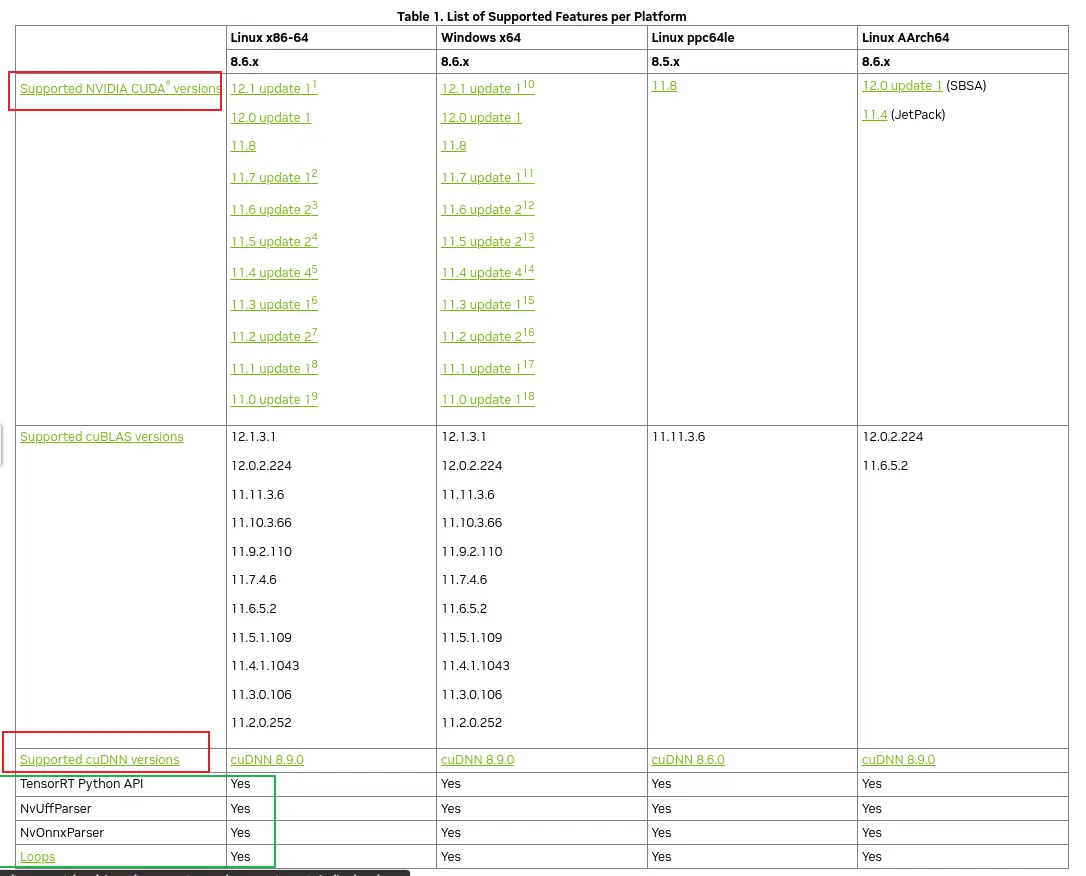
如下图, 首先选择相应的 TensorRT 版本---> 进入后选择 Support Matrix 查看版本对应情况,最后选择自己合适的版本安装
二、下载TensorRT
去官网: Log in | NVIDIA Developer 下载所需要的版本,如图所示,有 TAR、DEB、RPM三种不同的下载包。本文主要介绍 TAR 包的安装方式,其他两种没有测试过,可以看官网的安装教程。
TAR 包安装可以自行选择安装位置

三、安装TensorRT
在1.2节中类似,选择相应的 TensorRT 版本---> 选择:Installation Guide , 找到相应的安装流程,因为下载的是TAR, 所以找到TAR 包得安装方法:

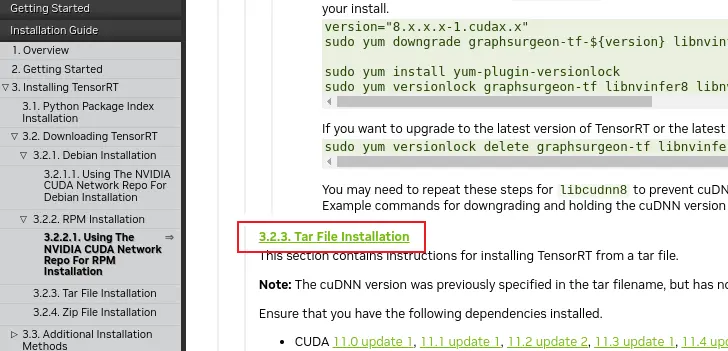
安装流程整理如下:
3.1、下载后解压
解压后得到TensorRT-8.6.1.6文件夹 TensorRT-8.6.1.6
<code>tar -xzvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-11.8.tar.gz
3.2、添加环境变量
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/your_path/TensorRT-8.6.1.6/lib
# 重新加载环境变量
source ~/.bashrc
3.3、安装python版:
到 TensorRT-8.6.1.6/python 目录下,安装TensorRT, 根据自己的python版本选择
cd /Path/to/TensorRT-8.6.1.6/python
python3 -m pip install tensorrt-*-cp3x-none-linux_x86_64.whl
其中 * 在这里是tensor版本号, cp3x根据自己的python选择
3.4、安装UFF,支持tensorflow模型转化
cd /Path/to/TensorRT-8.6.1.6/uff
python3 -m pip install uff-0.6.9-py2.py3-none-any.whl
3.5、安装graphsurgeon,支持自定义结构
cd /Path/to/TensorRT-8.6.1.6/graphsurgeon
pip install graphsurgeon-0.4.6-py2.py3-none-any.whl
3.6、防止转换时候找不到相应的库
为了避免其它软件找不到 TensorRT 的库,建议把 TensorRT 的库和头文件添加到系统路径下
复制到系统目录, 进入TensorRT路径下
sudo cp -r ./lib/* /usr/lib
sudo cp -r ./include/* /usr/include
3.7、测试一下. 进入Python
import tensorrt as trt
print(trt.__version__)
历程测试
cd /Path/to/TensorRT-8.6.1.6/samples/sampleOnnxMNIST/
make -j8
cd ../../bin
./sample_onnx_mnist
如下图
四、ONNX转换成TensorRT engine
使用命令行工具<code>trtexec转换成TensorRT engine 或者 trt,只是后缀不同
进入到TensorRT-8.6.1.6/bin 目录下
./trtexec --onnx=path/model.onnx --saveEngine=path/resnet_engine_intro.trt --explicitBatch
# 参数解释
--maxBatch:设置一个最大batchsize上限,用于输入的batchsize不确定情况下
--explicitBatch:根据onnx模型后结构自动推导出明确的batchsize
--fp16:是否使用fp16
注意保存engine的时候不要保存在bin下面 可能会报错的 保存引擎错误
有的时候转engine的时候回报错
onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64
weights, while TensorRT does not natively support INT64. Attempting to
cast down to INT32.
是因为你的onnx是INT64权重生成的,而tensorrt是支持INT32 的所有要将onnx转为更简单的模型。需要用到 onnx-simplifier 使用 pip install onnx-simplifier 就能直接安装了
安装完毕后就可以转了 python -m onnxsim .\flame.onnx .\flame_sim.onnx
推理库:
GitHub - shouxieai/tensorRT_Pro: C++ library based on tensorrt integration
该仓库也包含了 TensorRT Python 模型推理的源码。 对于 YOLO C++ 部署只需要下载文件夹 tensorRT_Pro/example-simple_yolo/即可。
该开源项目有以下优点
依赖少:仅依赖官方的 TensorRT 和 OpenCV
文件少:只有 simple_yolo.hpp 和 simple_yolo.cu 两个文件
使用方便:包含了ONNX 模型转 TRT 引擎,图像输入的预处理和后处理,集成了 NMS 非极大抑制算法,且封装简单,易于使用。
该仓库非常简单易用,根据其 ReadMe 文件操作即可。
实际使用,只需要修改下src/main文件主函数的参数
具体参考这篇文章后半部分,后续再来补充
TensorRT安装及使用教程(ubuntu系统部署yolov7)_ubuntu tensorrt-CSDN博客
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。