
本书内容系统、全面,实例丰富,共有10章,包括51个实操案例解析和80个行业案例分析。通过学习本书,读者可以从零开始,逐步掌握人工智能的核心技术,成为合格的AI训练师。本书附赠了同步教学视频+PPT教学课件+素...

大家通过一系列的操作,应该多多少少明白了sovit4.1的一些基本步骤,当然,训练一个自己喜欢的声音需要花费很大量的时间,不过为了自己喜欢的角色,就算等待一会也是完全值得的!!!因为这篇博客只是介绍了最基本的流程...
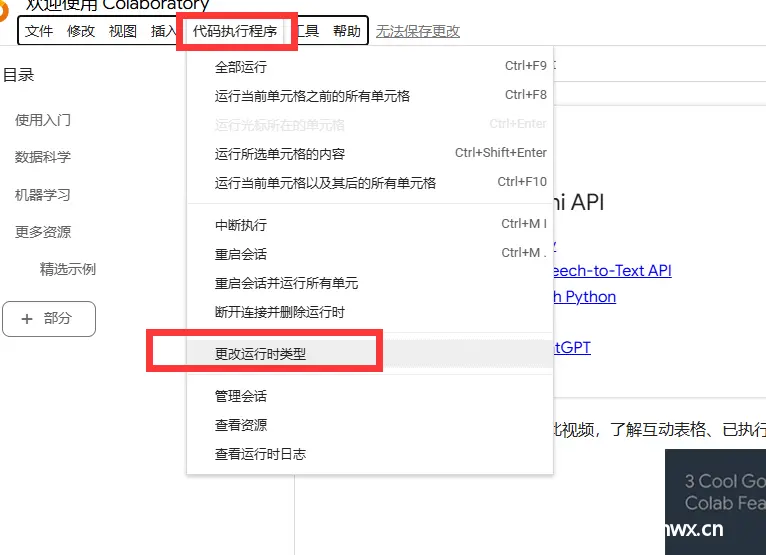
\t一般情况下,大家都是在自己电脑上进行训练模型,\t作为一名学生党,但是怎么找到一些靠谱,实惠,还得方便的云服务器呢\t这几天我找了好久,对比了好多家,今天给大家介绍一下。_ai训练云服务器...

接下来就要结合安卓开发了,这边采用的模拟滑动方案,用到了谷歌无障碍服务accessabllity,客户端传入滑块url地址,请求POST接口,成功得到目标图片滑块X轴距离值。计算出问题比如一个椅子,...

在AI训练过程中,优化器不收敛(OptimizerNotConverging)是一个常见且令人头疼的问题。优化器的有效性直接影响模型的训练效果。本文将详细探讨这一问题的成因,并提供多种调整和解决方案。关键词:A...
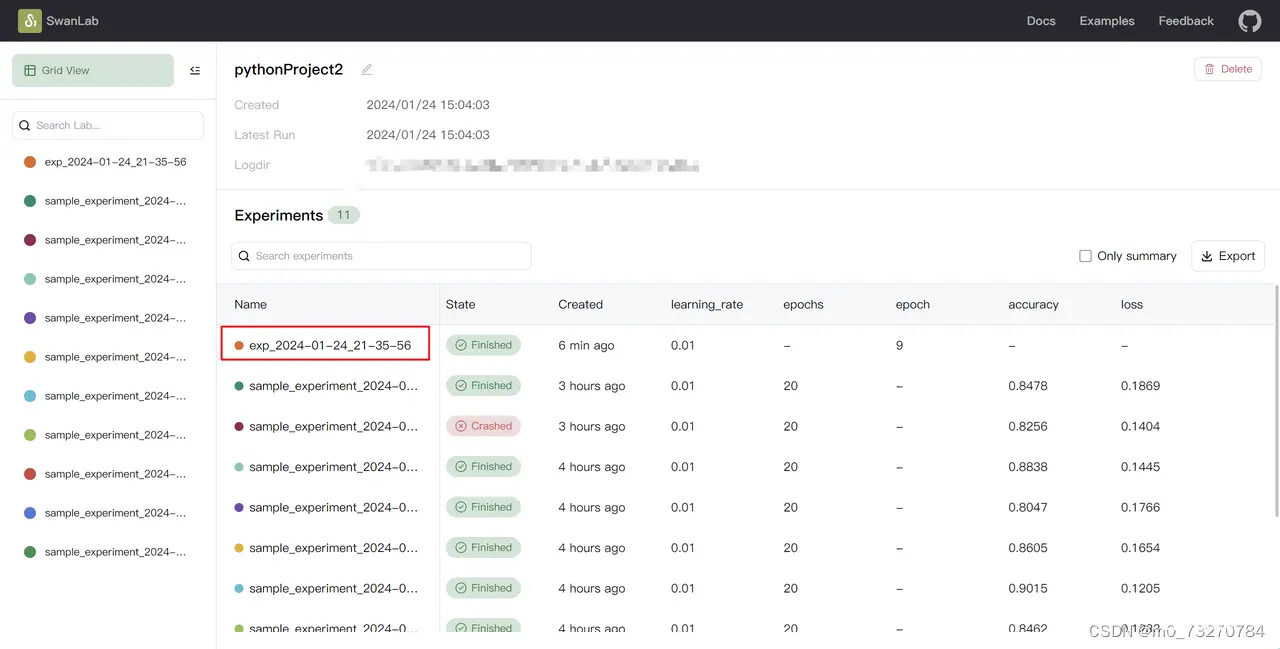
SwanLab是一款完全开源免费的机器学习日志跟踪与实验管理工具,为人工智能研究者打造。有以下特点:基于一个名为swanlab的python库可以帮助您在机器学习实验中记录超参数、训练日志和可视化结果能够自动记录...

在AI模型训练中,很多开发者会遇到“NaNLoss”问题,这不仅会导致训练失败,还可能影响模型的性能。本文将详细分析“NaNLoss”的成因,提供具体的解决方法,并通过代码案例演示如何避免和解决这一问题。希望这...
有用户反馈称使用微软必应搜索和谷歌搜索发现存在不少知乎乱码内容,即搜索结果里知乎内容的标题和正文内容都可能是乱码的,但抓取的正文前面一些段落内容可以正常查看。从最开始知乎屏蔽其他搜索引擎只允许百度和搜狗到必应搜索结果...
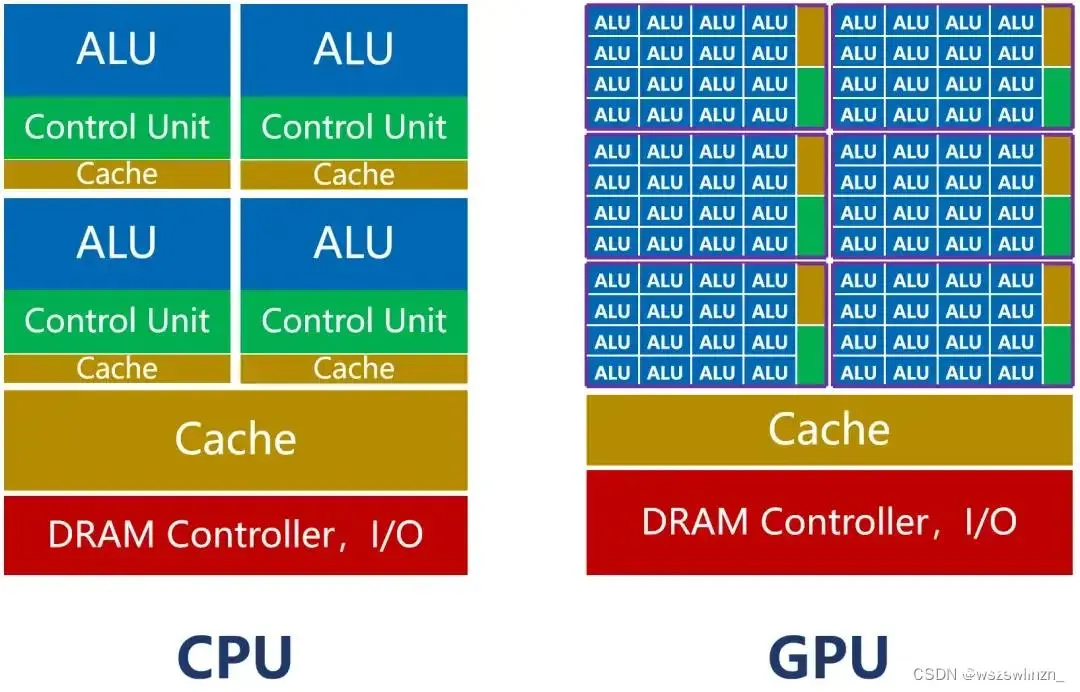
本文探讨了GPU在人工智能领域的关键角色,通过对比CPU,强调了GPU的并行计算能力使其在深度学习训练中的优势,特别是在大规模神经网络模型的处理上,GPU的性能远超CPU,使得GPU成为AI训练的首选平台。...

本文详细介绍了如何使用Python编写一个简单的爬虫,用于从百度图片搜索下载图片。通过分析目标网站、设计爬虫流程、实现代码以及配置代理IP,使得爬虫能够有效地获取图片数据。通过本项目,读者可以学习到基本的爬虫原理...