AI训练语音(以游戏角色“白露”为示例)—>So-VITS-SVC 4.1—>新手使用教程
珈百列 2024-10-01 15:01:04 阅读 69
注:So-VITS-SVC 4.1的使用教程推荐:So-VITS-SVC 4.1 整合包完全指南 (yuque.com)【含整合包下载链接】,本文章仅仅总结博主在使用So-VITS-SVC 4.1时所遇到的问题以及使用UVR时的经验。
目录
注:So-VITS-SVC 4.1的使用教程推荐:So-VITS-SVC 4.1 整合包完全指南 (yuque.com)【含整合包下载链接】,本文章仅仅总结博主在使用So-VITS-SVC 4.1时所遇到的问题以及使用UVR时的经验。
一.下载sovit4.1本体
二.训练模型
2.1准备数据集
2.1.1切片处理
2.1.2去除伴奏,和音,混响等
2.2开始训练
三.开始推理
3.1开始调节设置和参数
3.2音频转换
3.3文本转语音
四.UVR去除伴奏,和声,混响
五.总结
一.下载sovit4.1本体
按照所给的链接中下载文件( 这是https://www.yuque.com/umoubuton/ueupp5链接中含有的下载,为了方便起见,放在这里,详情请访问该网址)
在进入文件后找到红框中的文件,双击进入

sovit4.1整合包界面如图(该整合包来自于b站大佬羽毛布団,感谢大佬):
二.训练模型
2.1准备数据集
首先我们要找到我们想要的角色的音频,然和将其整理为数据集,在这里,我们以崩铁的角色白露作为例子,我们从网上找到白露的语音整合(该整合中的语音最好不要有任何的伴奏,混响,和声,否则训练出来的语音会很抽象),然后打开sovit4,开始进行切片处理:
2.1.1切片处理
检查你所得到的音频,如果它们的长度在2-15s,那么你可以不用进行该操作,反之,你应该如下图操作,开始切片:
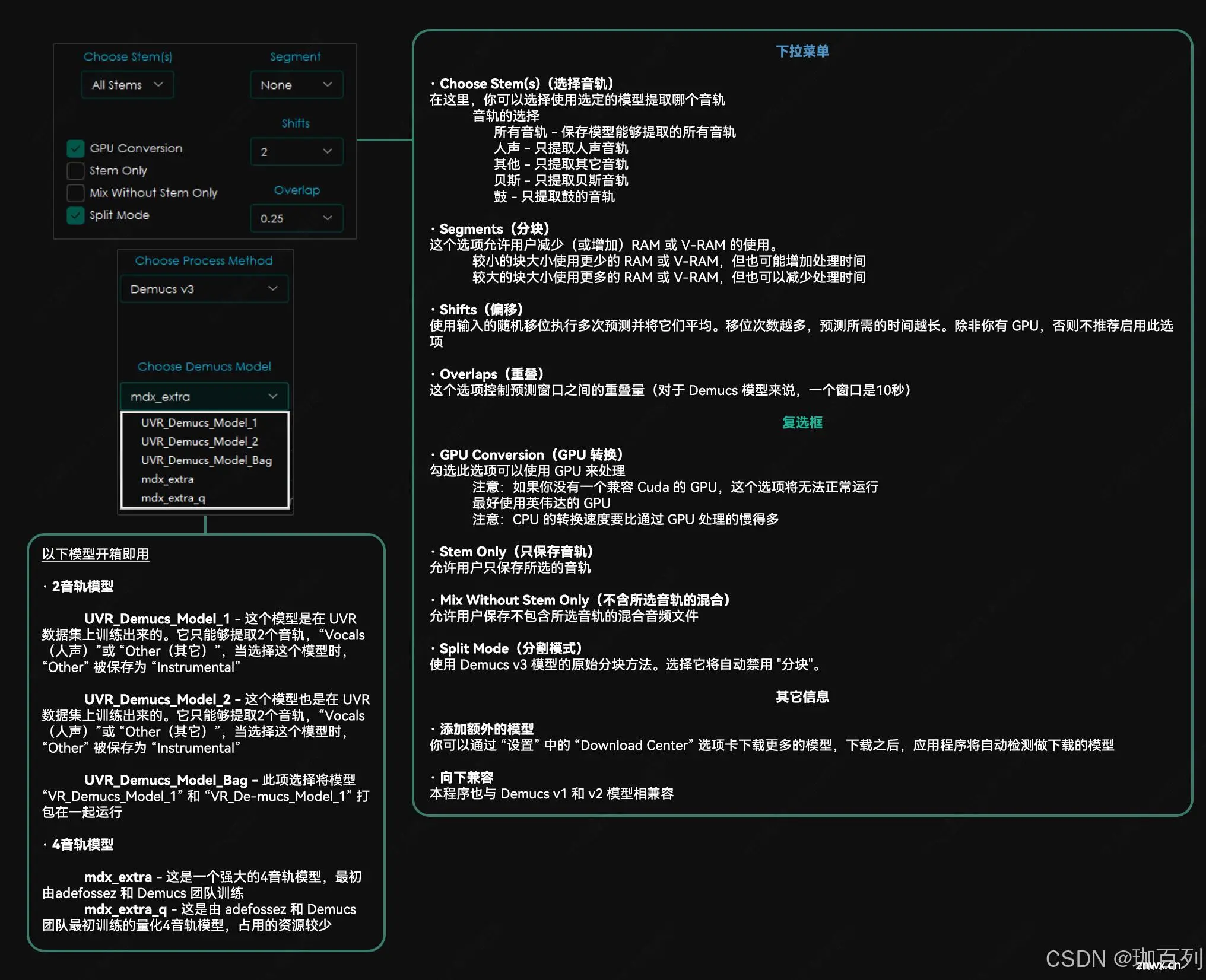
首先我们打开sovit,选择最上方的”小工具/实验室特性“,再选择其中的”只能音频切片“,在”原始音频文件夹“中输入你所得到的音频所在的文件夹的绝对路径,最后点击加载“原始音频”
结果如下图所示,切片的最长秒数和切片的最短秒数如图即可,点击”开始切片“,得到符合要求的数据集
看到输出信息中的文字,就说明切片成功了
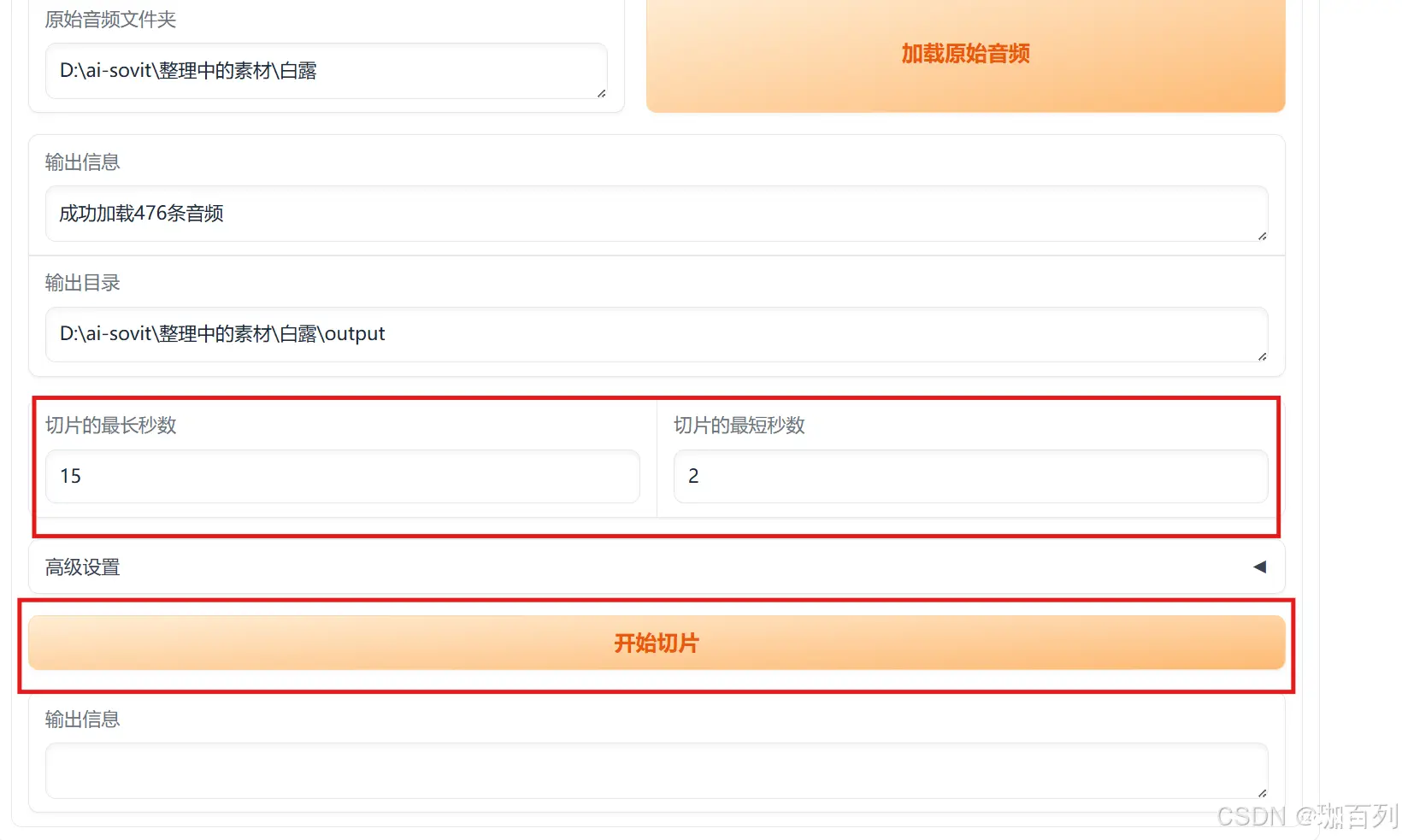
切片后的音频文件就在在原来的未处理的音频所在的文件里(即下图的output里)

将我们得到的output文件剪切到sovit的dataset_raw文件里

切片准备就到此为止了。
2.1.2去除伴奏,和音,混响等
2.2开始训练
打开sovit,点击训练,点击识别数据集,会出现我们保存在dataset_raw的文件夹名称,
注意:保存在dataset_raw的所有音频文件必须是英文名称!!!
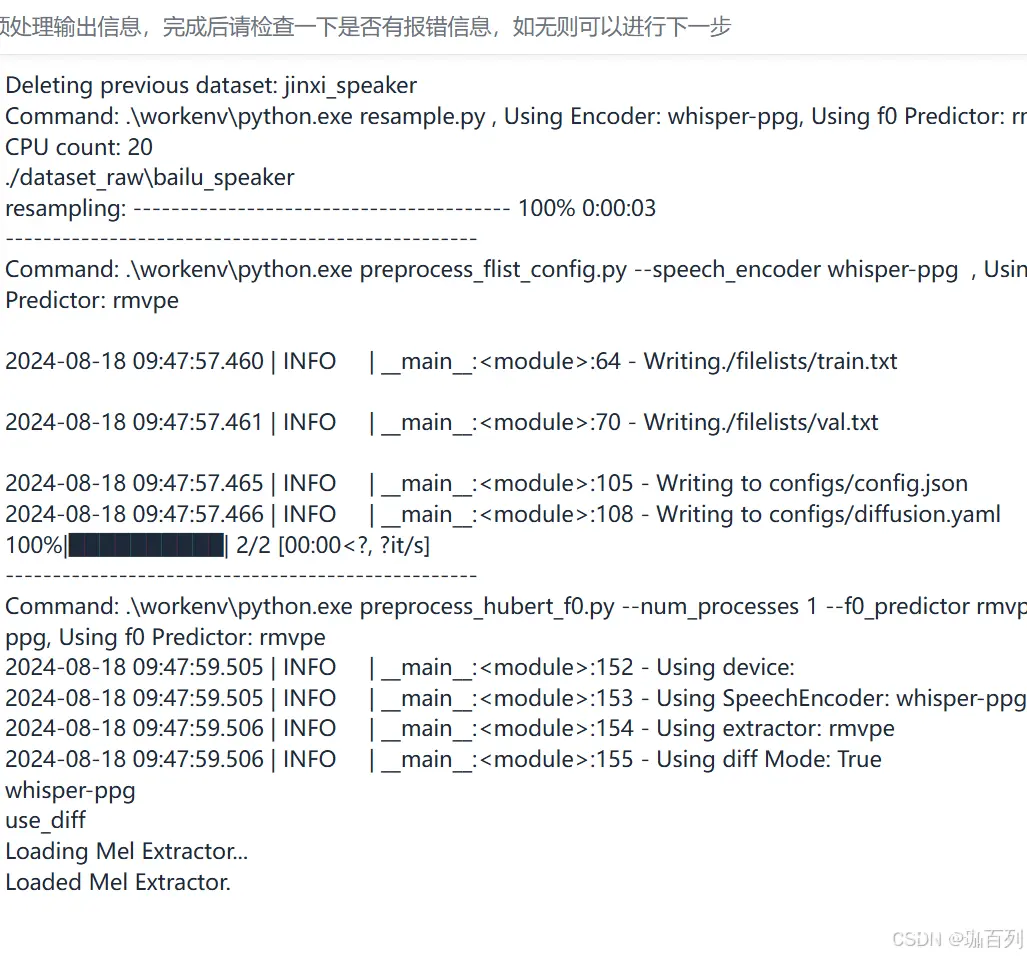
其他的参数按默认即可(即图中的参数),我们点击数据预处理,这会花费你不少时间
会出现该信息,等待该处理结束
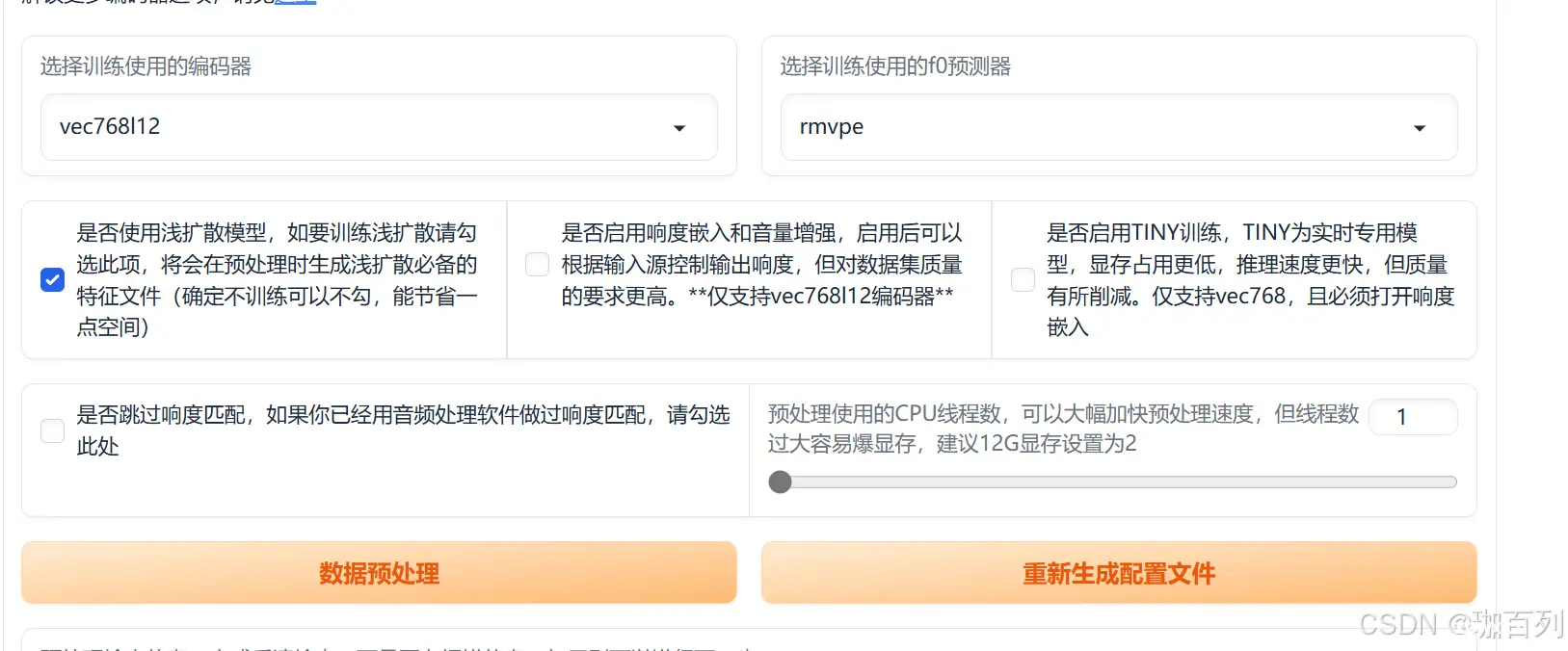
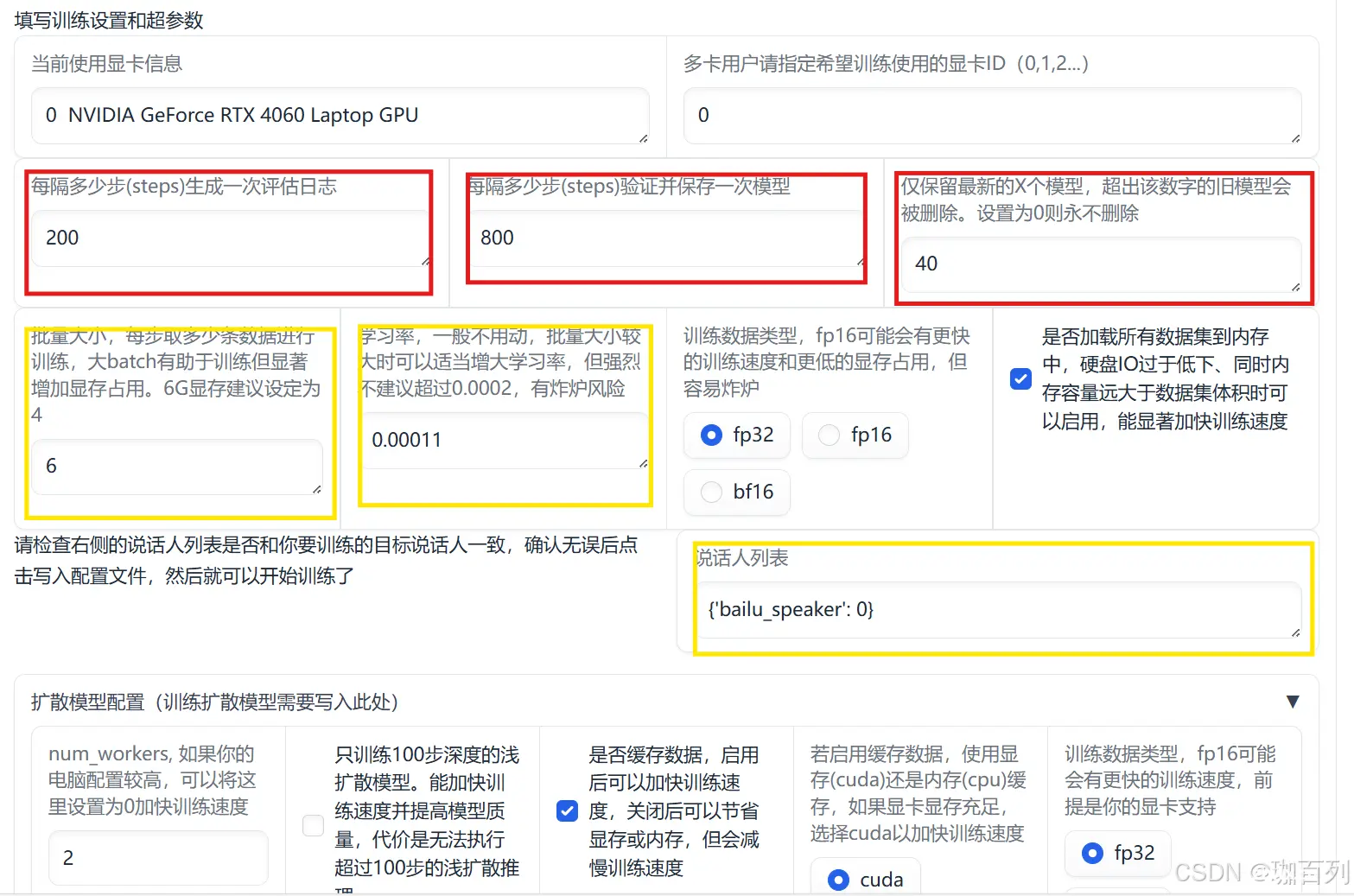
填写训练设置和超参数的详解(仅供参考)
按照上图框起来的部分:
1.每隔多少步(steps)生成一次评估日志:每训练x步,生成一次评估日志;对于该设置没有明确的填写要求,不影响生成的结果,但是为了观察训练的状况,建议填200。
2.每隔多少步(steps)验证并保存一次模型:每训练x步,保存此时训练出来的模型;600(建议),800(建议),1000都是可以的
3.仅保留最新的x个模型:这个设置就是字面意思,仅仅保留最新保存的x个模型;为了我们电脑的内存着想,不建议填0,因为训练时可能会保存很多的模型,这些模型每个都占有不小的内存。
4.批量大小:每步取x条数据进行训练,这个数据理论上讲越多越好,但是考虑到电脑的性能,我们**建议6G显存填4,**我这里是8G显存,填的6(仅作参考)。
5.学习率:建议保持默认数值(0.0001),学习率的概念:**学习率(Learning rate)**作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
6.请确认说话人列表为你所选择的数据集
7.由于我们这里并不训练扩散模型,所以扩散模型配置所在的参数不用管它,保持默认即可,我们可以先点击”将当前设置保存为默认设置“,这样想一次我们训练时可以不用重复的调参数;
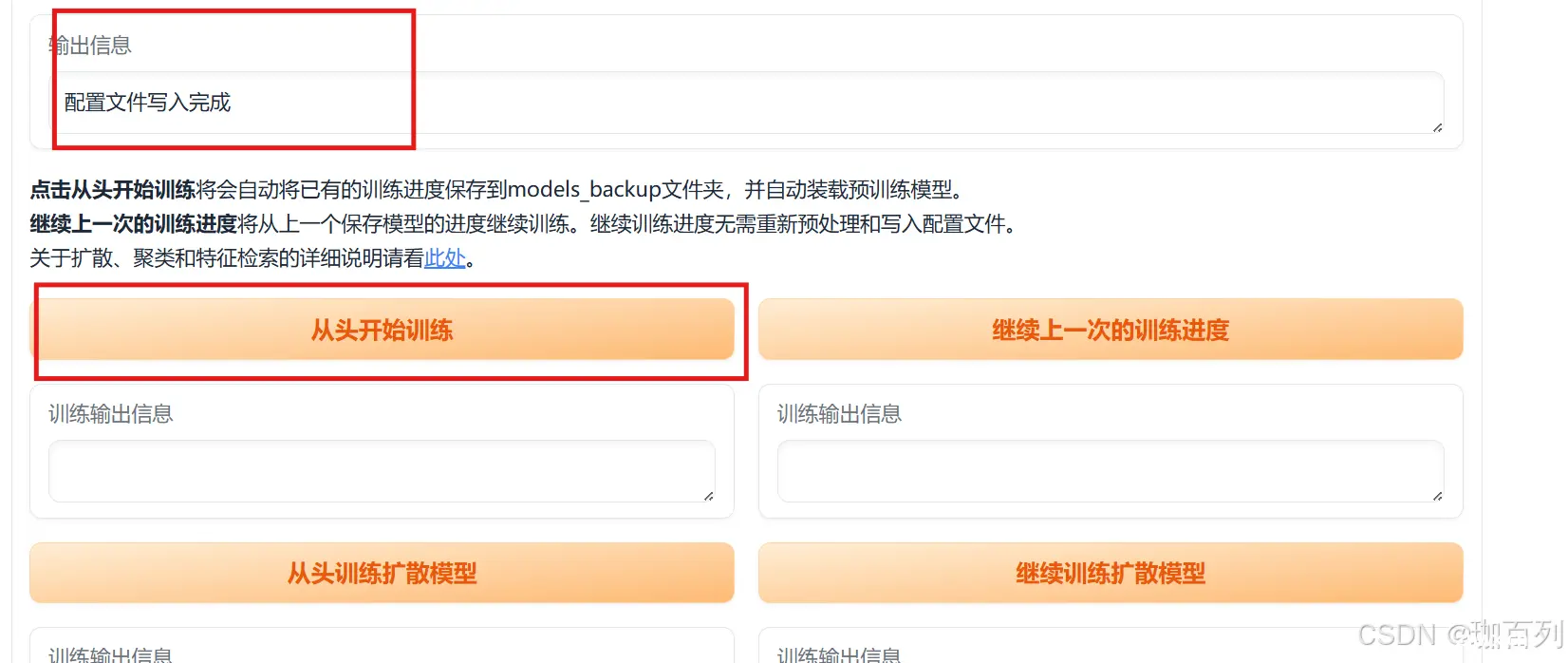
点击”写入配置文件“,

在输出信息一栏会显示”配置文件写入完成“,然后后点击从头开始训练

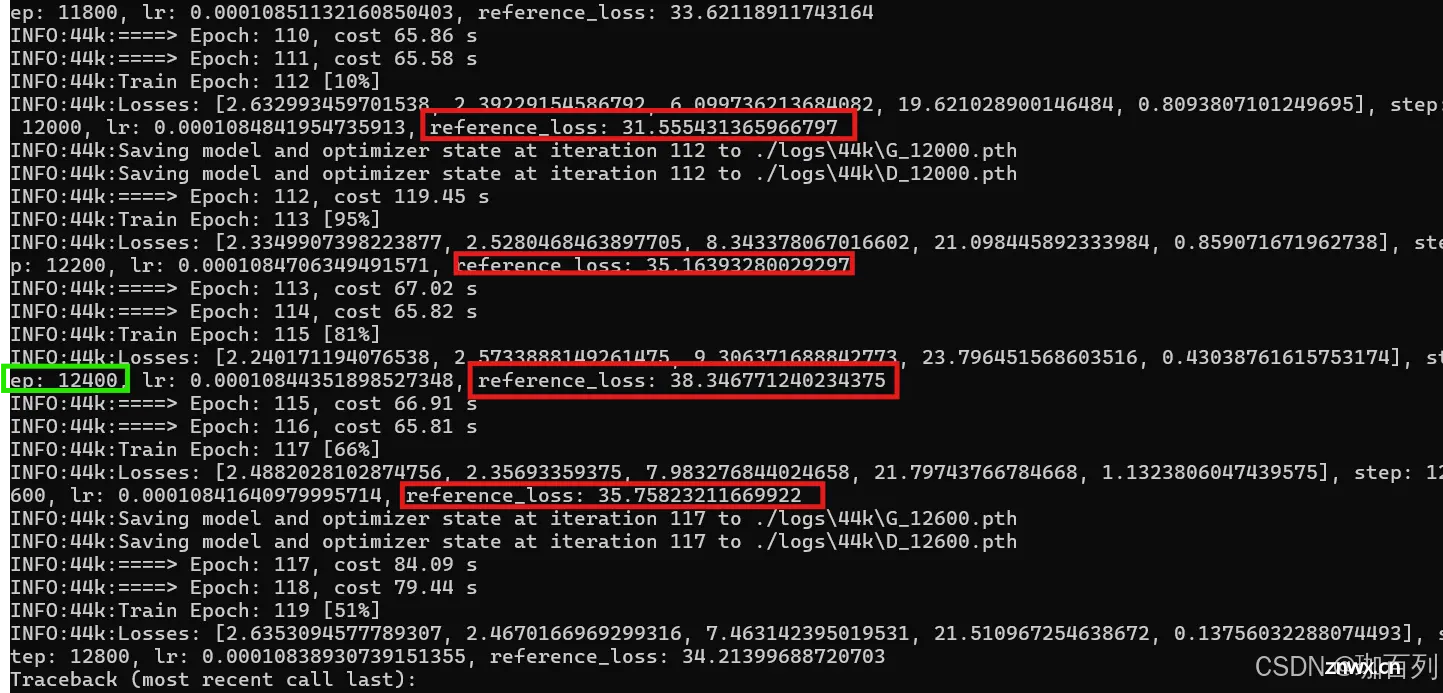
在训练2个小时以后,我挑选出
如图:我们大抵只需要关注两个参数:
1.step:即训练的步数,一般1w——2w步可以得到比较好的效果
2.reference_loss:这个值一般越小越好,且该值并不是单调的,它是震荡的,一会高一会低是正常的
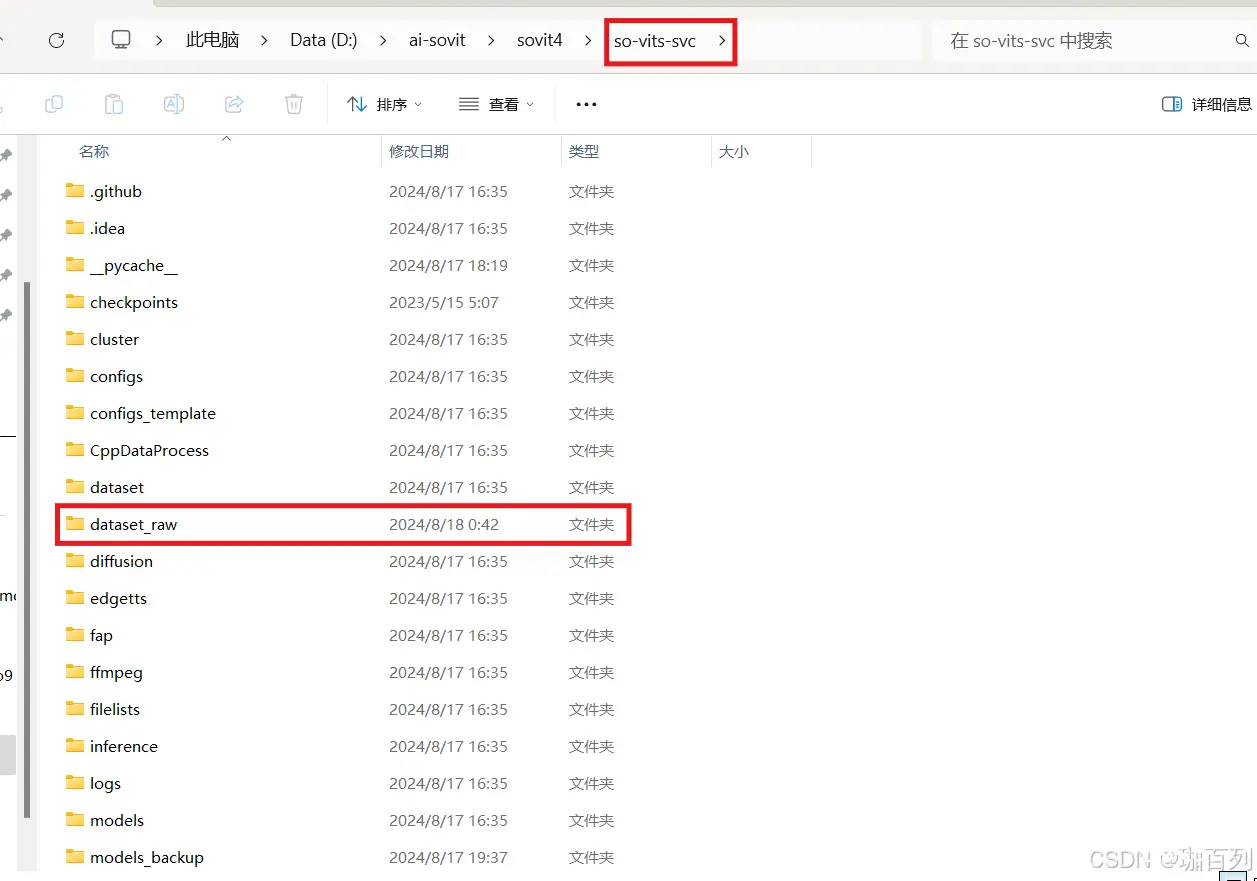
那么我们训练的模型在哪里呢?
我们打开so-vits-svc目录下的logs,然后进入logs,最后进入文件44k,就可以看到我们的模型了
三.开始推理
3.1开始调节设置和参数
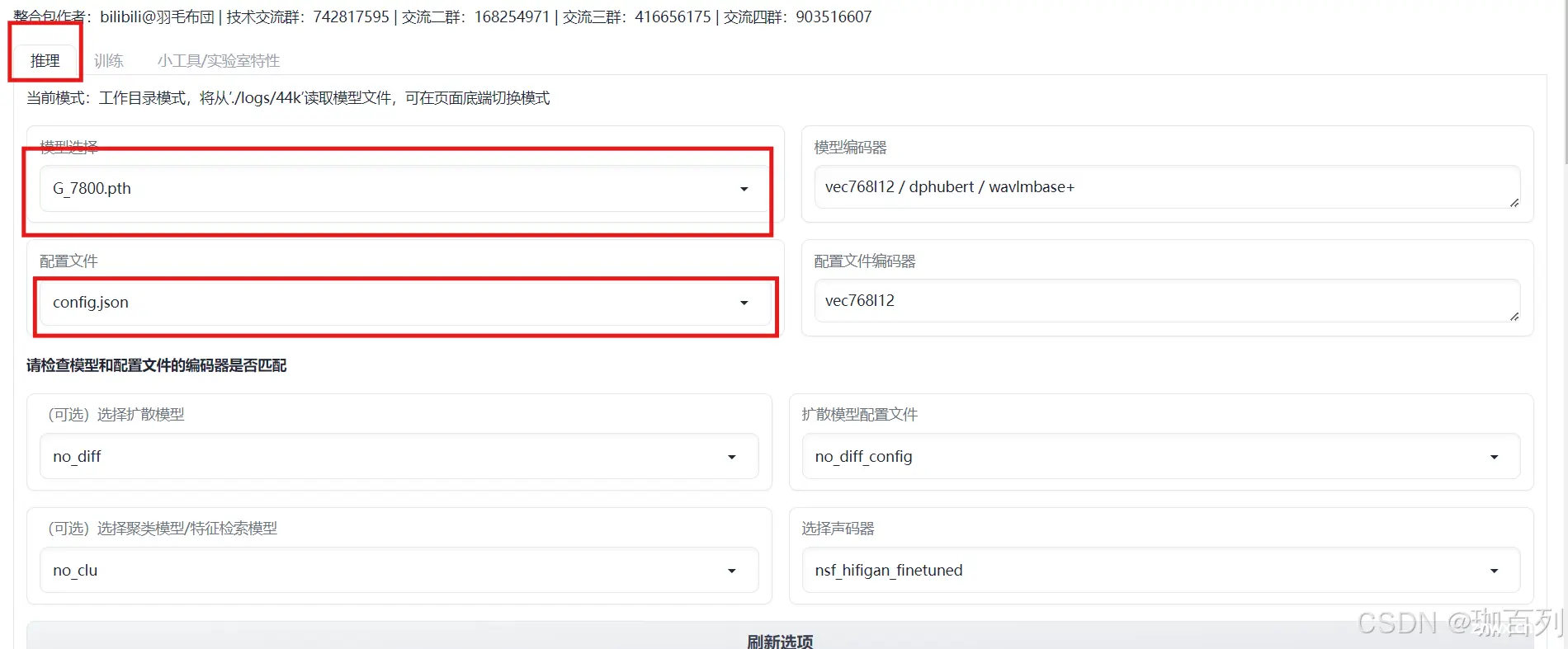
进入推理界面,在“模型选择”中选择reference_los比较低的模型,其格式为:G_xxxx.pth,再在配置文件选择config.json

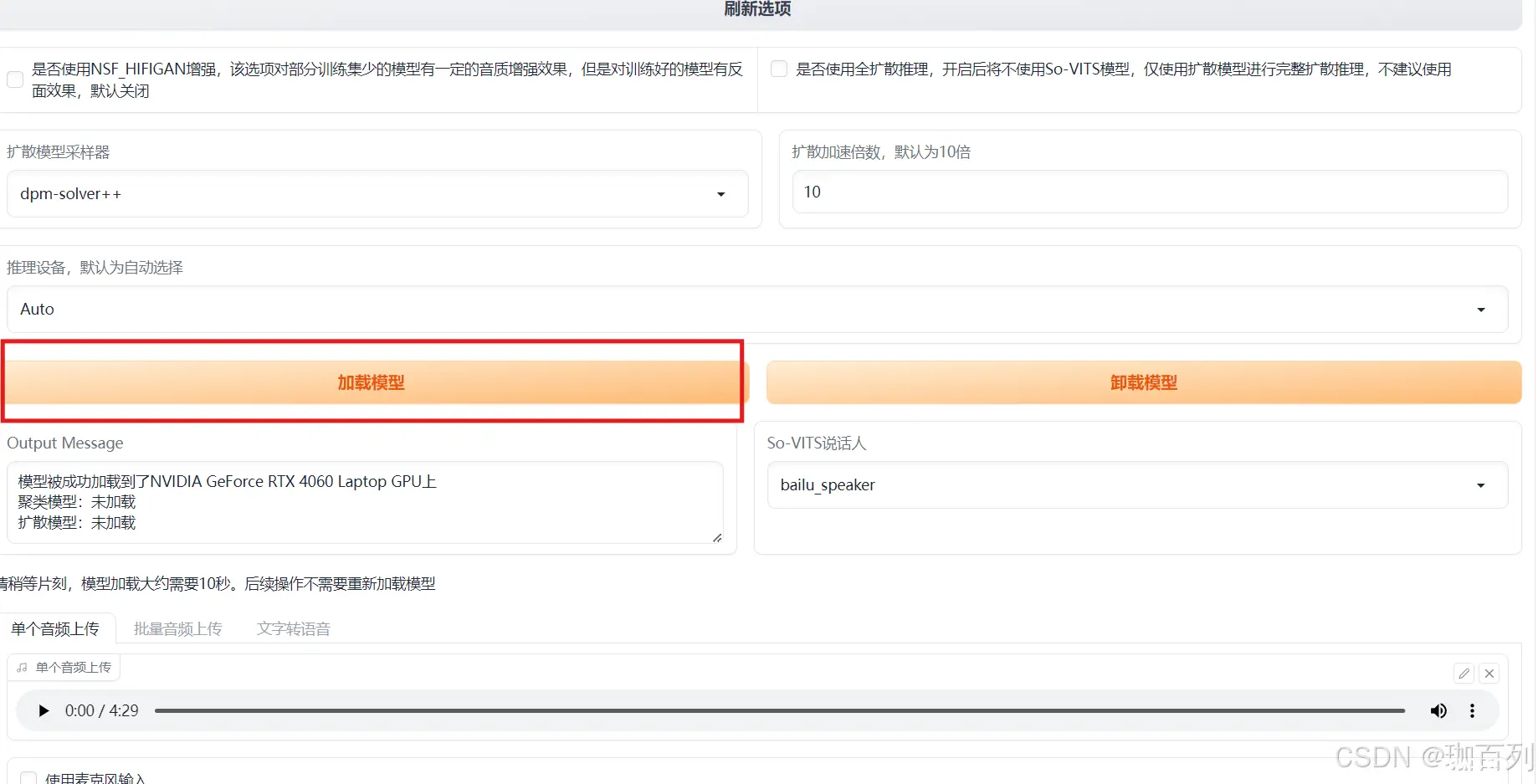
然后选择“加载模型”,在Output Message中会出现相关的信息,如图:
3.2音频转换
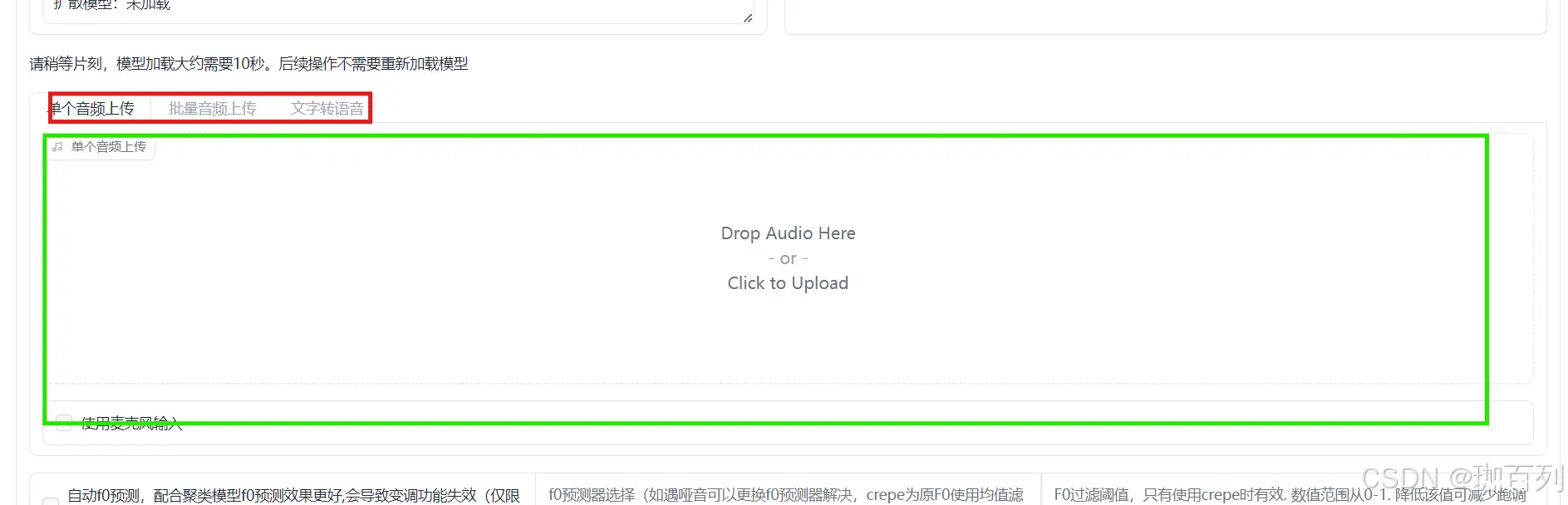
我们选择上传单个音频上传:

注:该音频不能有伴奏,和声,混音!!!关于如何去除这些内容,可以翻阅到该博文第四部分进行操作
参照如图的参数(如果你使用的是整合包,它们是默认的,不用修改)然后点击”音频转换“
等待完成:
我们会得到如下的结果:
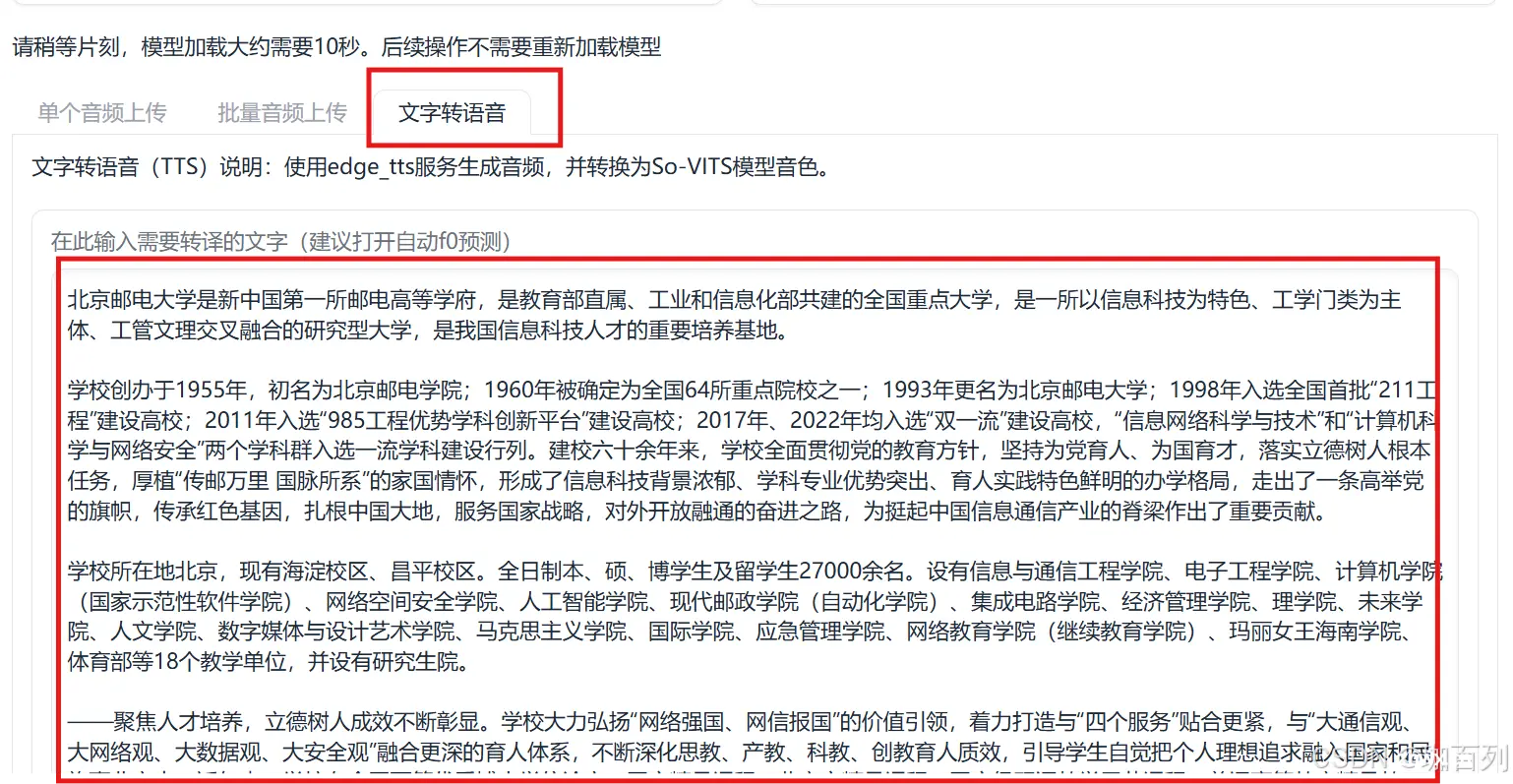
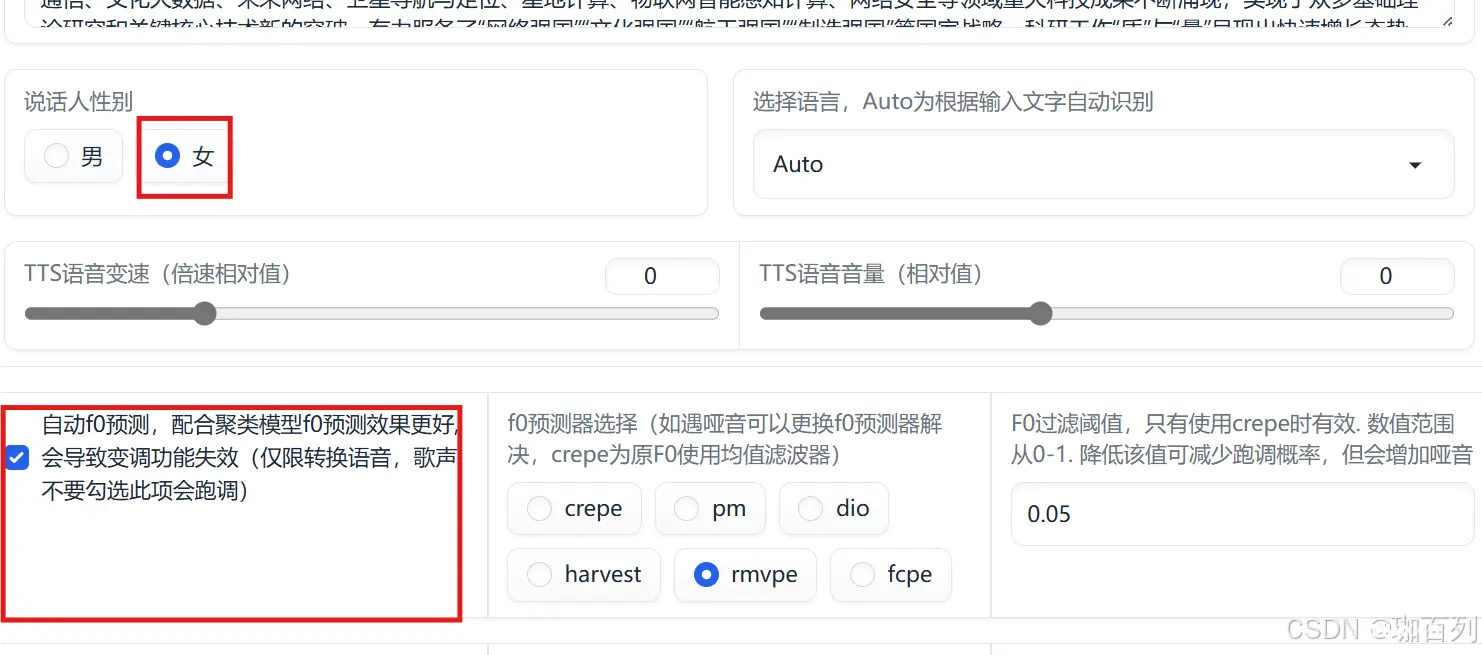
3.3文本转语音
我们复制一段我们想要的文本(该段文字节选于北京邮电大学概况):
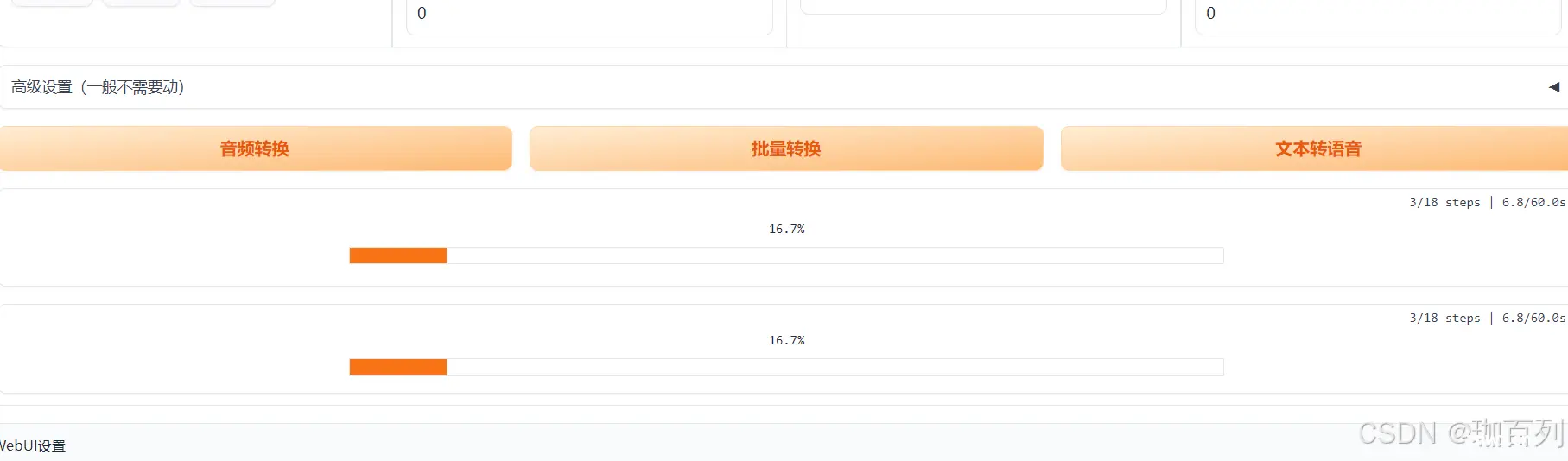
调节相应的设置和参数,如下图所示:
因为我选用的角色是游戏角色白露,所以选择女,其他参数保持默认,
注:使用文本转语音时,开启自动f0预测!!!
这是效果:
sovit4.1——结果示例
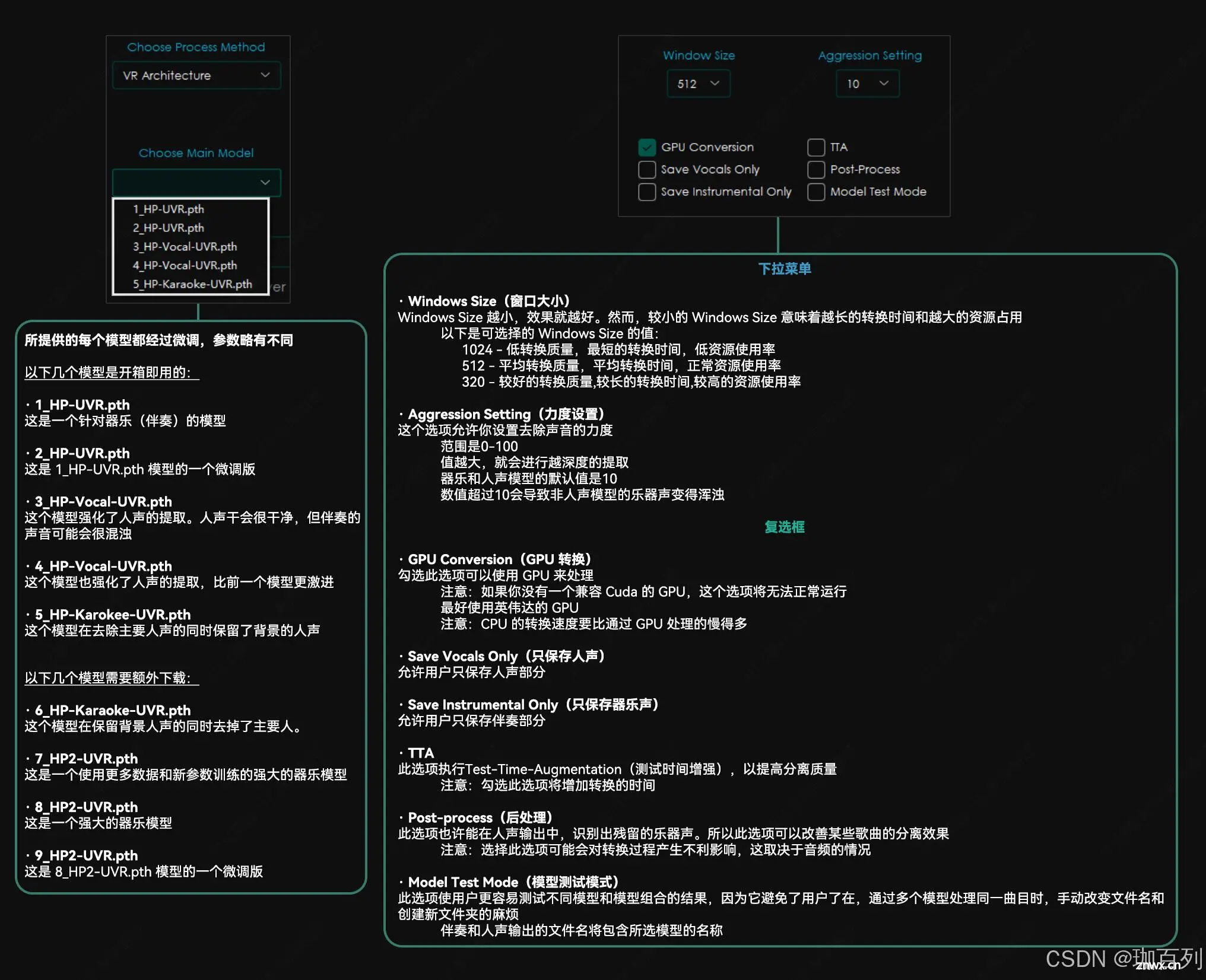
四.UVR去除伴奏,和声,混响
参照以下六张图(注:这些用心的教程图来自于B站的一位up主,但是因为时间太久了,忘记了是哪位up主,大家如果有知道的可以提醒我一下,我会在这里进行标明并放上其主页的链接)



五.总结
大家通过一系列的操作,应该多多少少明白了sovit4.1的一些基本步骤,当然,训练一个自己喜欢的声音需要花费很大量的时间,不过为了自己喜欢的角色,就算等待一会也是完全值得的!!!
因为这篇博客只是介绍了最基本的流程,训练出来的结果可能不会太让你满意,这个时候你就需要对你的成果进行调整,就像示例中白露的文本转音频的成果,会出现吐字不清淅,哑音等等问题。而关于如何润色推理出来的音频,如何应对哑音等等问题,就留给大家自己去慢慢探索啦。
上一篇: AI 赋能大模型:从 ChatGPT 到国产大模型的角逐与发展契机
下一篇: 论文解读《MASTERKEY: Automated Jailbreaking of Large Language Model Chatbots》
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。