从0开始训练基于自己声音的AI大模型(基于开源项目so-vits-svc)
哆啦Ci梦 2024-10-04 09:31:04 阅读 70
写在前面:
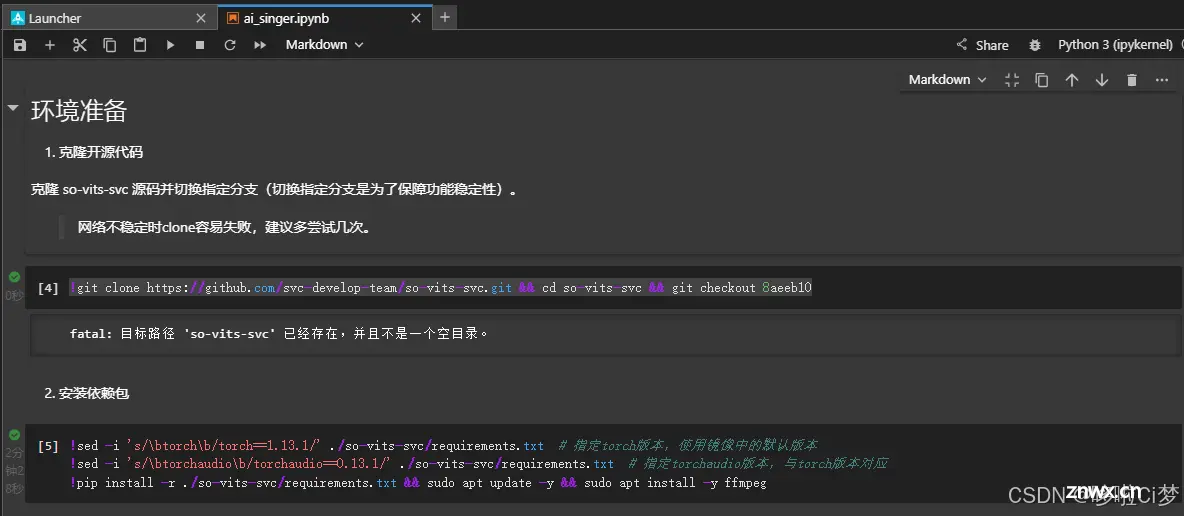
本文所使用的技术栈仅为:Python
其他操作基于阿里云全套的可视化平台,只需要熟悉常规的计算机技术即可。
目录
Step 1:注册及登录阿里云主机
Step 2:找到大模型项目
Step 3:创建大模型环境实例
Step 4:进入Ai_singer教程
Step 5:环境及预训练模型下载
Step 6:训练数据准备
Step 7:数据预处理和切分配置
Step 8:生成音频特征数据
Step 9:训练
Step 10:推理
Step 11:人声与伴奏合并
结语:
准备工作:Chrome浏览器+一个专注的环境
Step 1:注册及登录阿里云主机
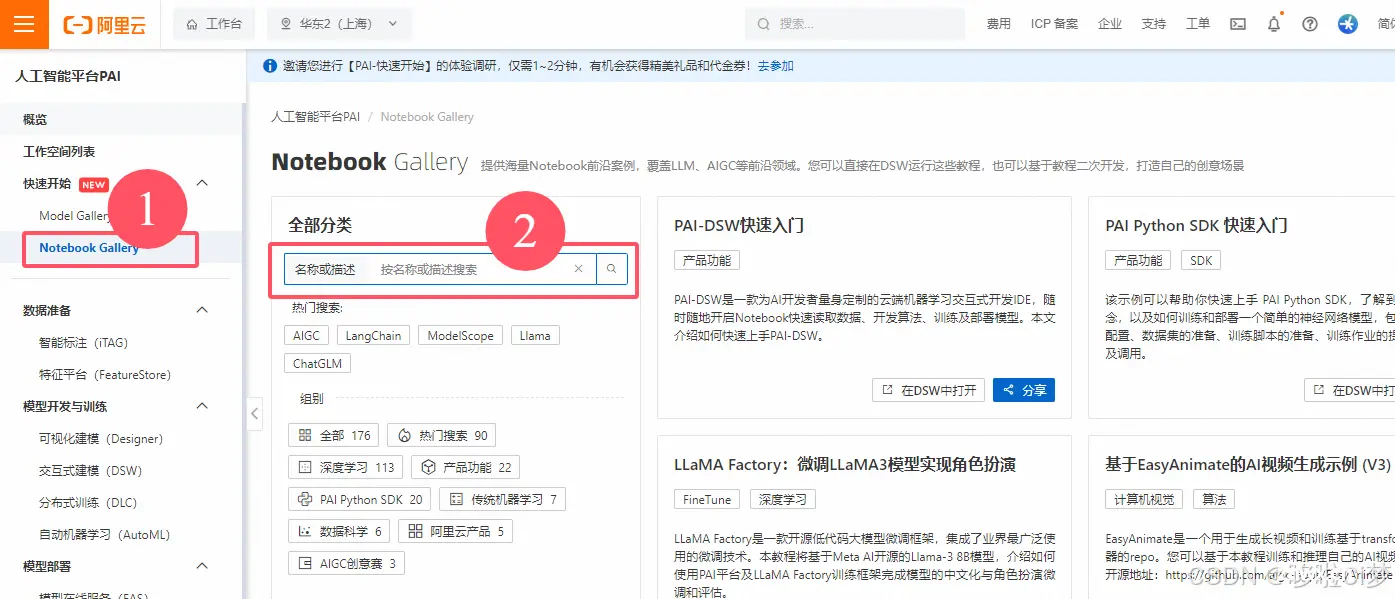
打开阿里云官网,登录个人阿里云账号,在左侧产品目录,进入人工智能平台PAI。
1、选择左侧Notebook Gallery,这是一个基于Notebook方式的可视化平台,易于操作和二次开发。
2、在全部分类里,我们可以直接搜索开源项目so-vits-svc(也就是前段时间很火的AI孙燕姿用的模型项目)
Step 2:找到大模型项目
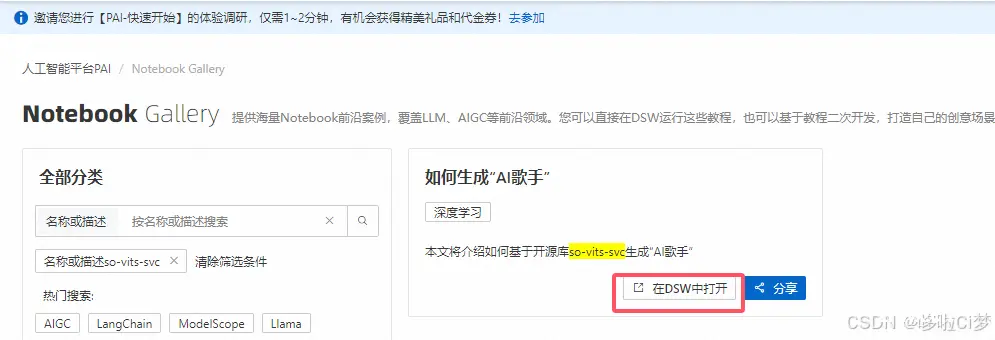
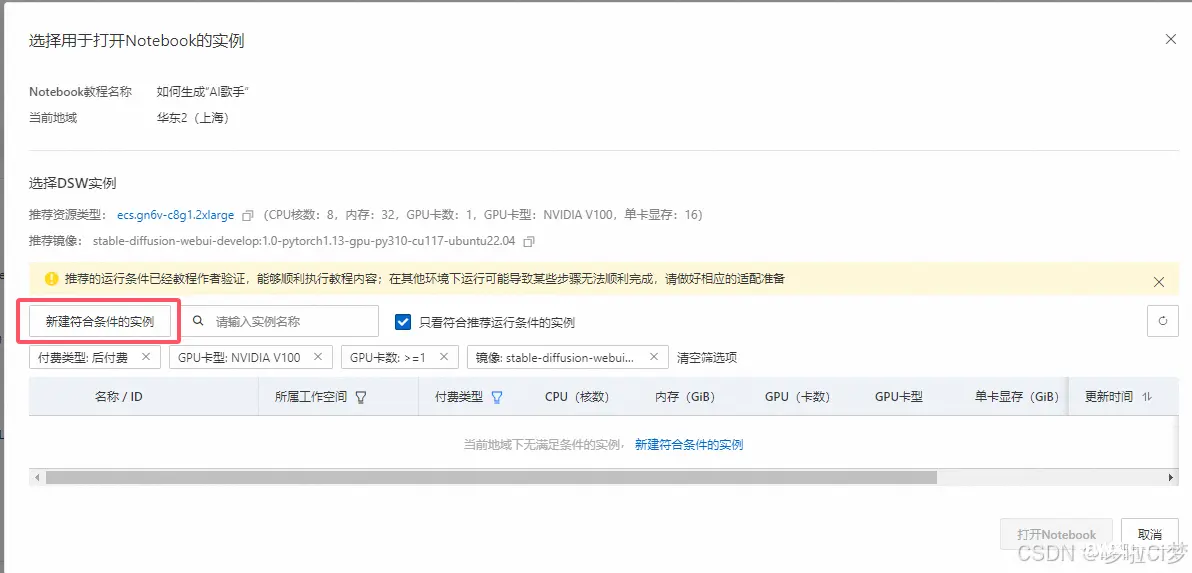
在搜索结果中,找对生成“AI歌手”这个项目,然后点击【在DSW中打开】。这个DSW全称是,data science workshop,类似于一个深度训练的云平台。华为云也有类似产品。

然后,会跳转到新建实例页面。也就意味着,要为这个大模型在云空间里创建一个运行实例,即,虚拟的运行环境,包括操作系统,cpu,gpu规格。这里可以直接使用推荐的配置。注意,涉及到大模型训练,一定要配置英伟达的GPU。阿里云这里会有免费3个月的试用,一般够小型模型训练。
Step 3:创建大模型环境实例
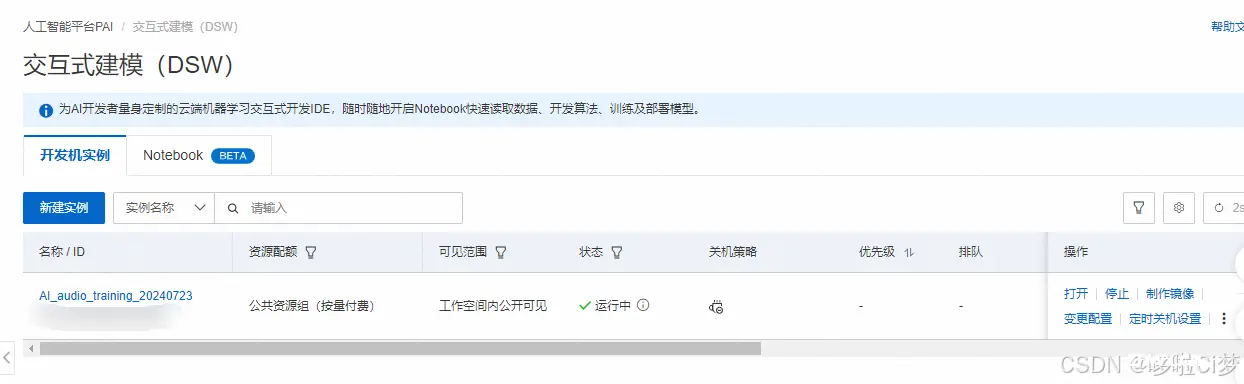
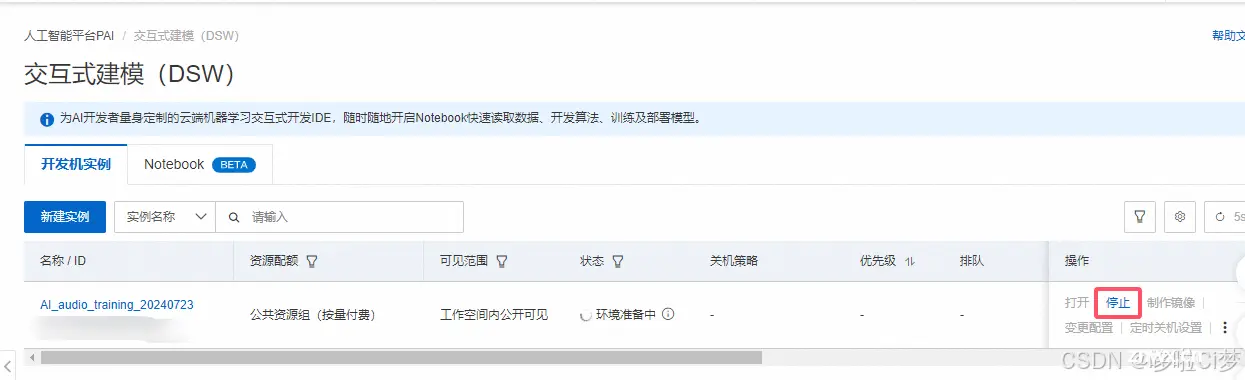
新建完成后,回到PAI平台,在左侧选择交互式建模(DSW),就可以看到创建好的实例,在操作栏,点击启动,然后会像下图这样先准备环境loading,

启动完成后就可以点击打开,直接进入DSW对应的项目,这里就是AI歌手项目(ai_singer)
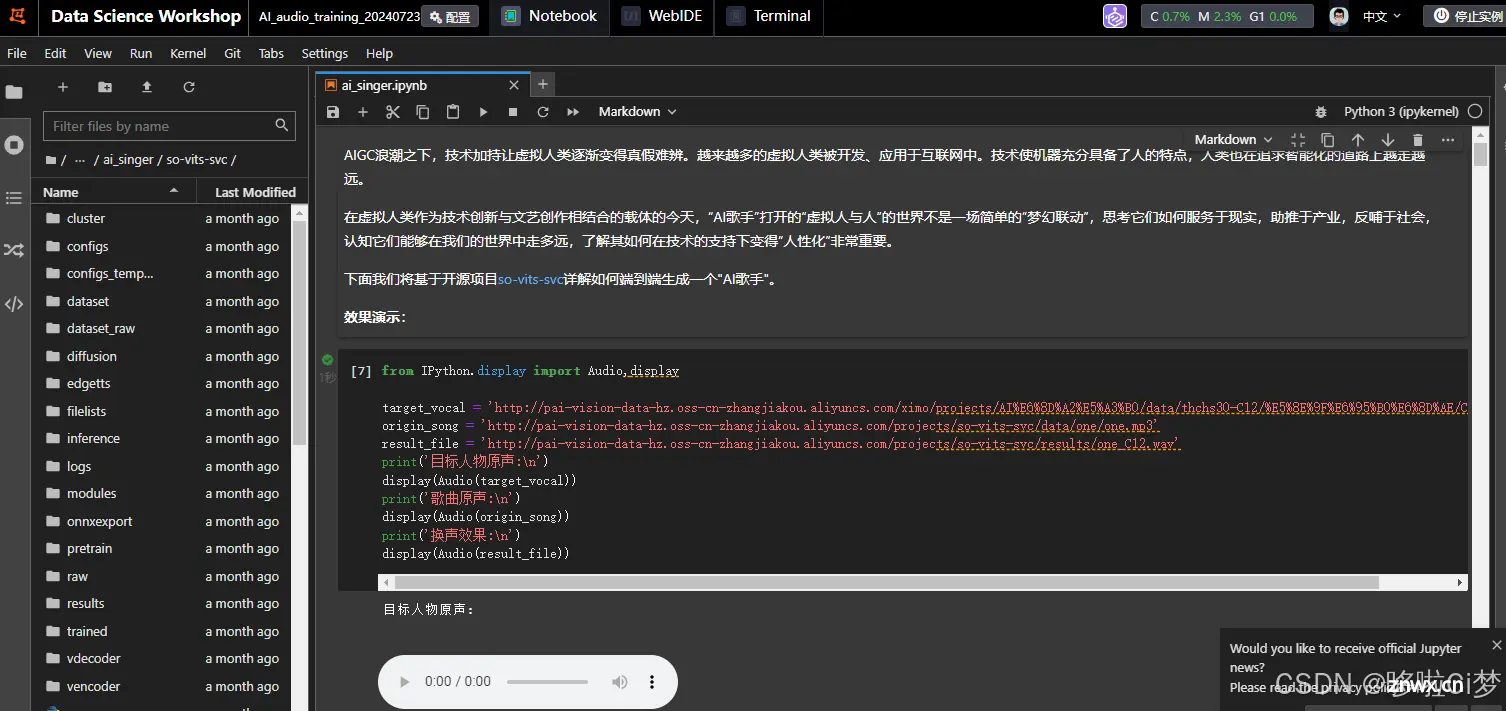
点击打开后,浏览器会新开一个页面,就是DSW的工作台,里面类似于其他开发工具,左侧是目录结构,右侧是文件内容。我们接下来的操作就在这里。
Step 4:进入Ai_singer教程
我们找到 ai_singer.ipynb这个文件,里面已经用ipython(Jupyter)的方式引导我们来一步一步训练模型。但是,这个示例我们是要自己改造的,因为我们不是用示例的数据,而是用自己的数据,只有这样才能训练一个基于自己声音的大模型(也避免有什么不清楚的版权问题)。
看一下整体的步骤(目录):

Step 5:环境及预训练模型下载
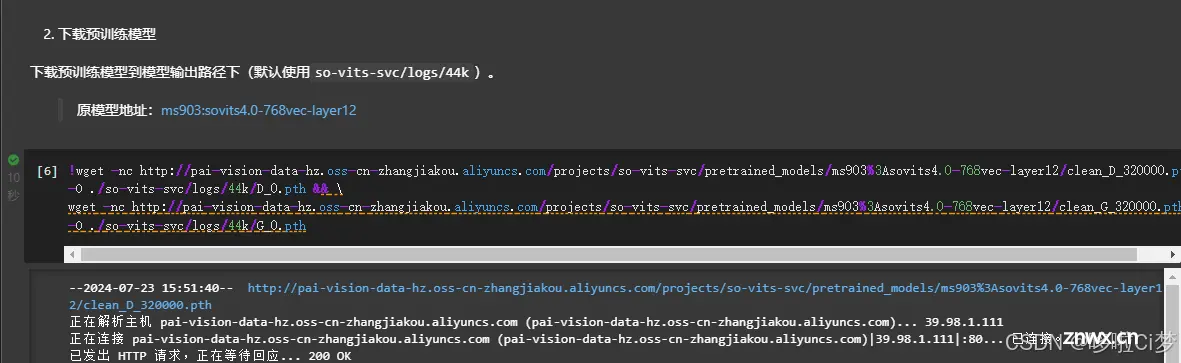
跟着目录往下,把预训练模型准备和数据下载的代码点击运行:
注意:这里如果在执行过程中,少了什么组件,可以自己通过 pip 安装。
Step 6:训练数据准备
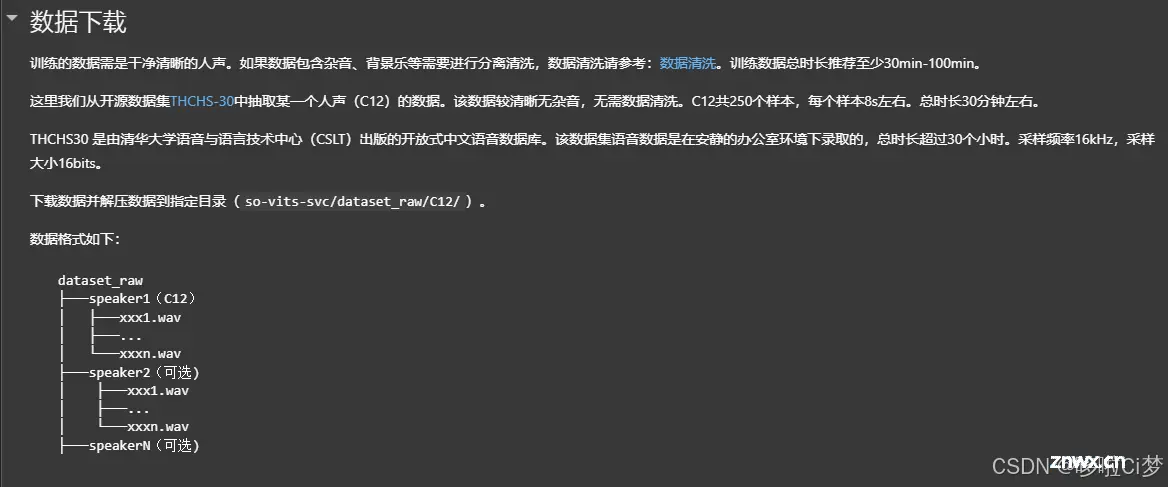
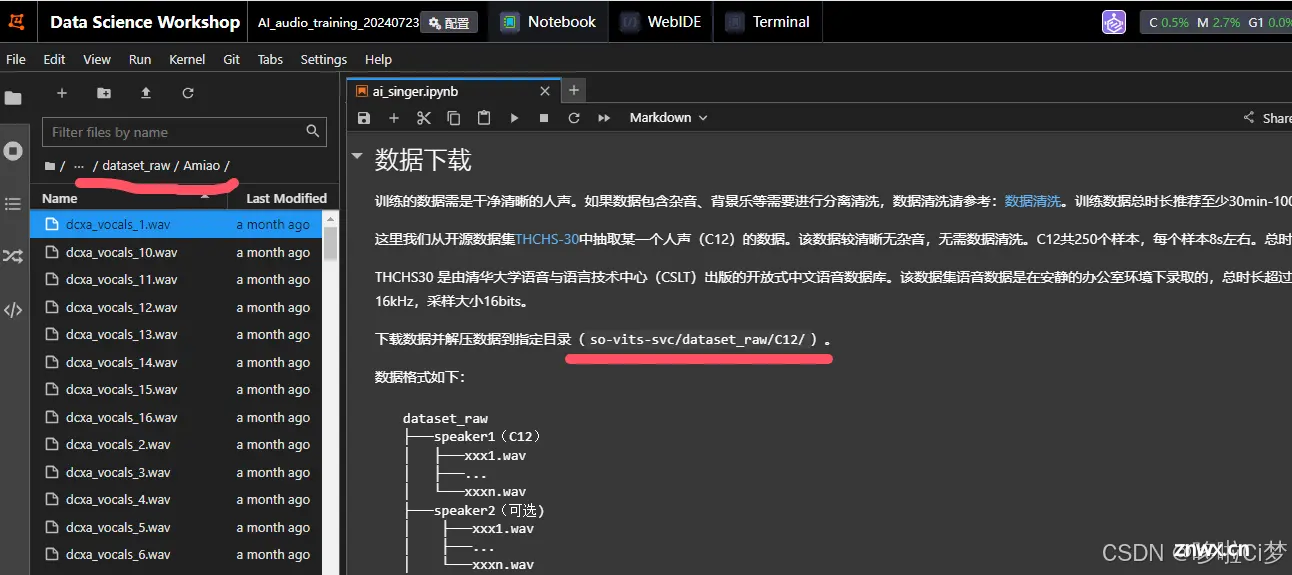
数据下载,这一步很关键。要将自己准备好的声音放上去,而不是用步骤里自带的。
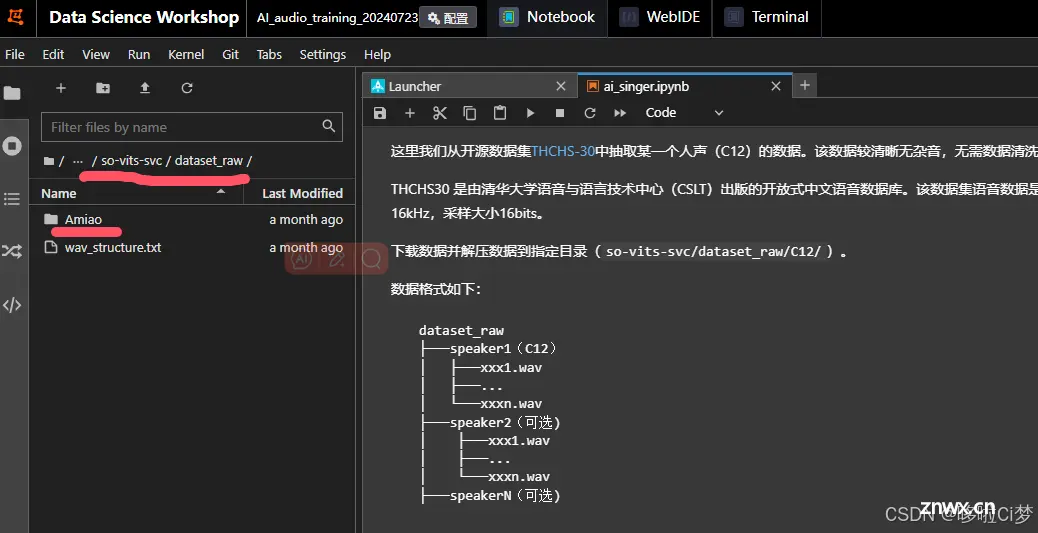
注意放置的目录在:so-vits-svc/dataset_raw/
笔者这里自己创建了一个文件夹Amiao,没有用系统的C12数据。
这里插入说一下数据清洗(见ai_singer.ipynb文件中目录的附录第一点),我们要用自己的数据来训练模型,就必须准备好自己声音文件,需要进行人声伴奏抽取、音频切片。
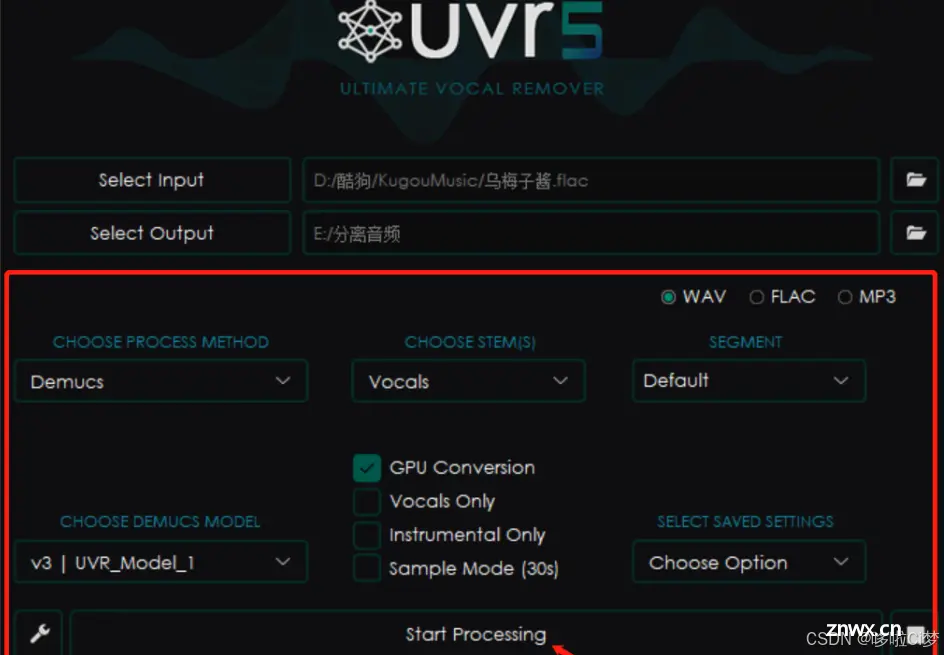
1)人声伴奏抽取:
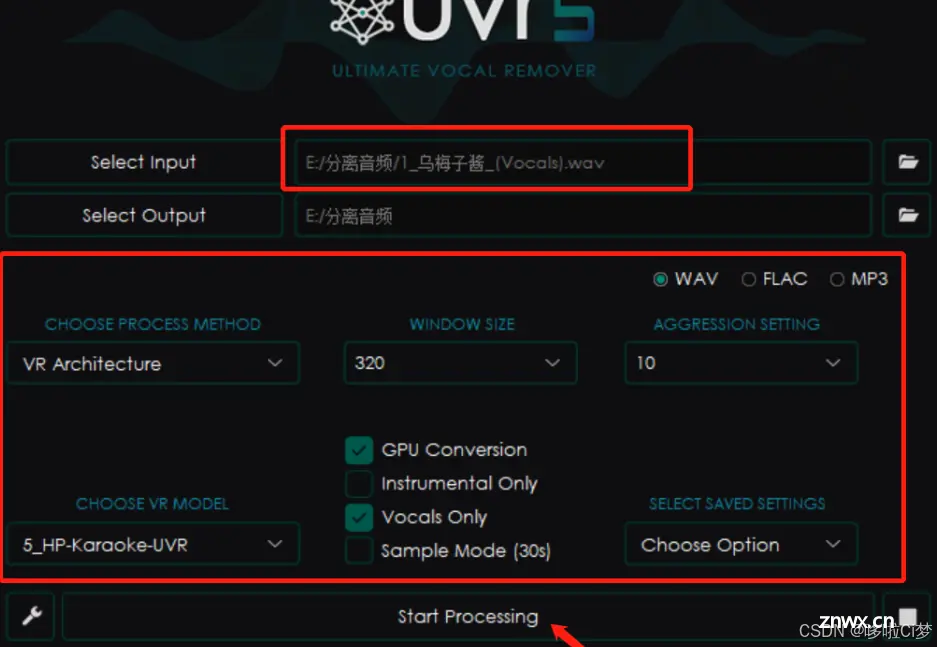
通过自己在全民K歌录制的歌曲,用iPhone自带的快捷指令提取出歌曲为m4a格式,存入电脑。电脑安装UVR软件进行人声和伴奏分离:要两次分离,第一次分离伴奏和人声,第二次提纯人声。
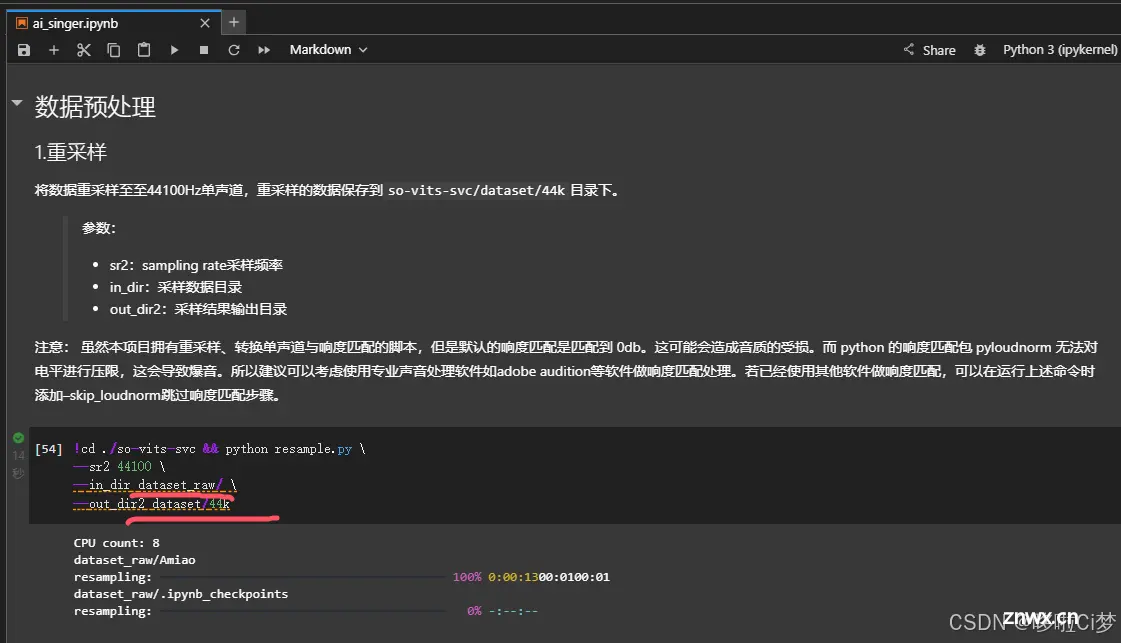
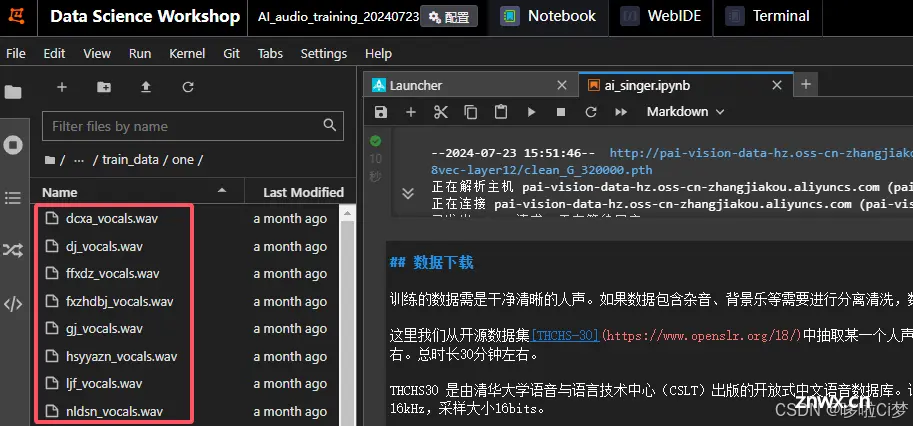
2)音频切片:将分离好的纯人声以wav的格式,上传到自定义的文件夹,我这里用的是trani_data/one/这个目录。
然后修改下图中的命令,把歌曲切片存放在制定目录:

<code># 先把用UVR处理好的声音切片放到train_data目录下再切分。
!mkdir -p ./slice_output/one && python audio-slicer/slicer2.py ./train_data/one/xxx_vocals.wav --out ./slice_output/one --min_interval=50
切分后的音频存储在`slice_output/one`目录下。
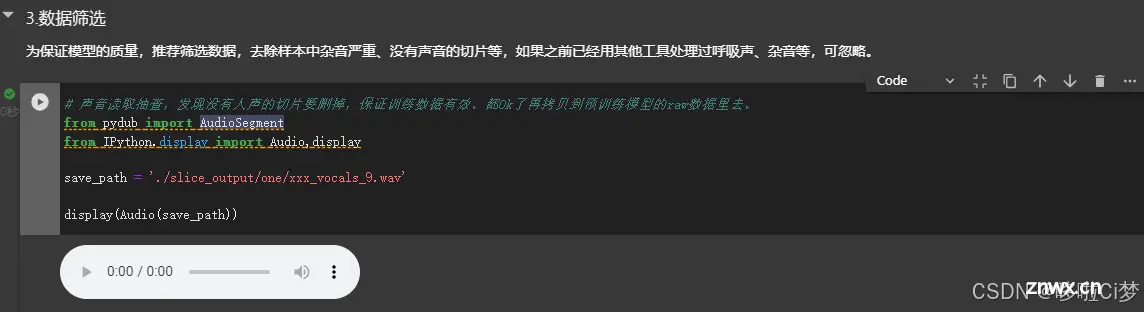
3)数据筛选:把切片好的声音片段,拿出来播放一下,看看有没有正好切到无声的,要删掉。
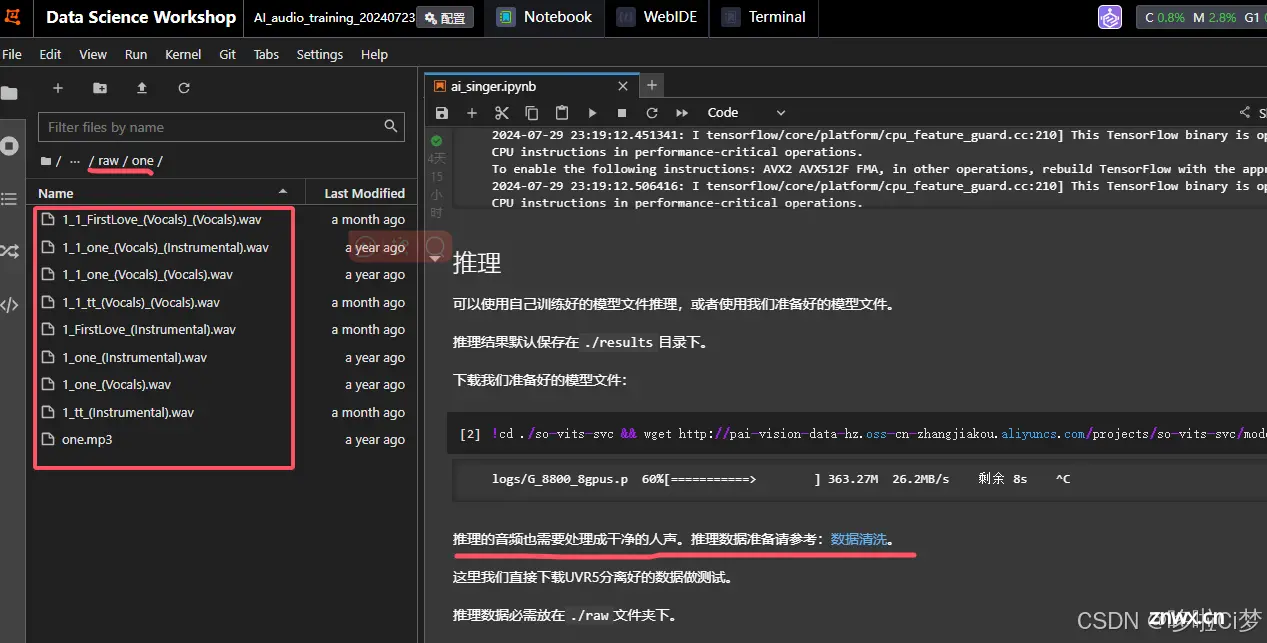
4)把处理好的数据放到训练数据源的目录:demos/ai_singer/so-vits-svc/dataset_raw/Amiao/
这是我自定义的目录,没有使用官方教程的C12目录。大概准备了300条左右10s的数据,如果要效果更好,应该准备更多数据,然后声音要有高音和低音,音域要广泛一些。
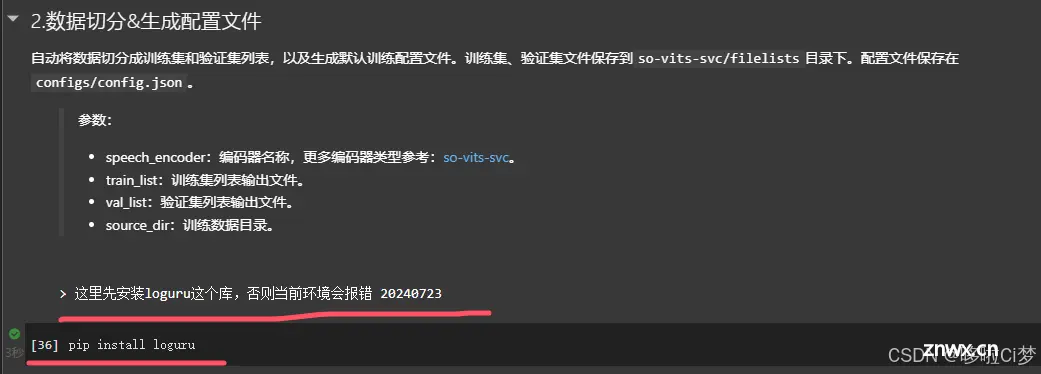
Step 7:数据预处理和切分配置
这一步只需要跟着官方教程走就行,注意路径要使用我们自定义的路径。

过程中有些库要自己安装后才能正常继续下去。
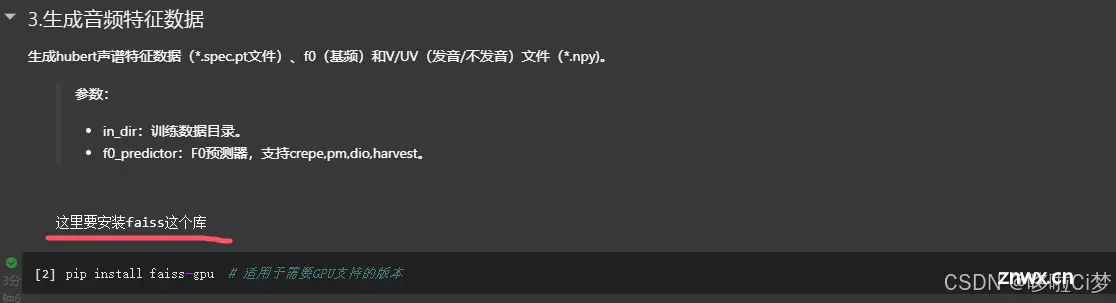
Step 8:生成音频特征数据
像这类库没有安装,在运行时根据控制台报错就能判断。
这样就完成特征数据生成。
Step 9:训练
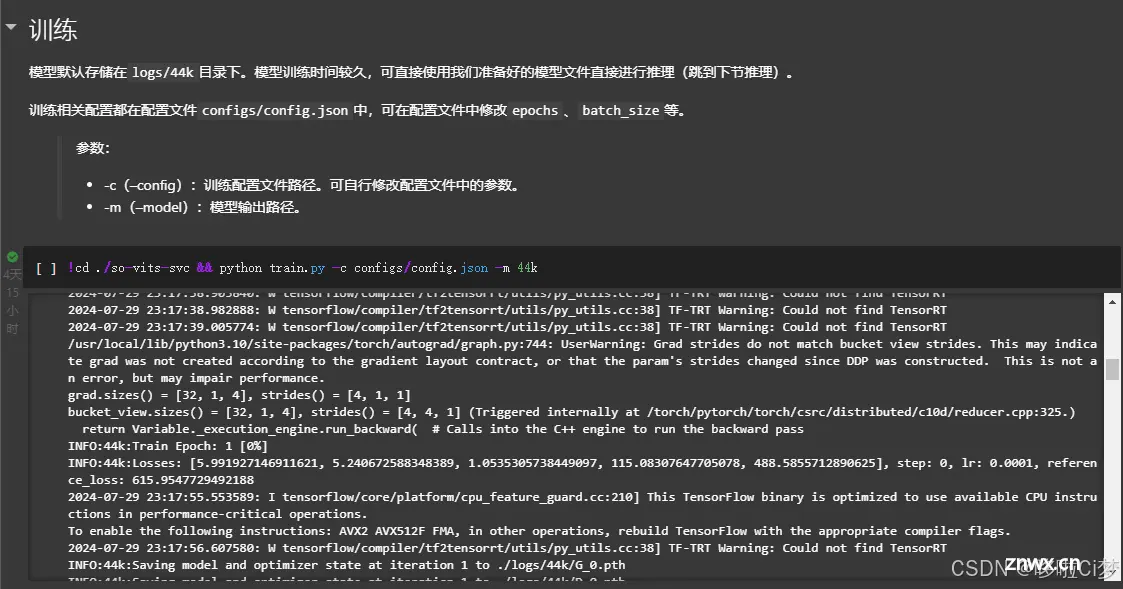
这一步就是用GPU训练大模型的关键步骤,如下图
<code>## 训练
模型默认存储在`logs/44k`目录下。模型训练时间较久,可直接使用我们准备好的模型文件直接进行推理(跳到下节推理)。
训练相关配置都在配置文件`configs/config.json`中,可在配置文件中修改`epochs`、`batch_size`等。
> 参数:
> - -c(--config):训练配置文件路径。可自行修改配置文件中的参数。
> - -m(--model):模型输出路径。
!cd ./so-vits-svc && python train.py -c configs/config.json -m 44k
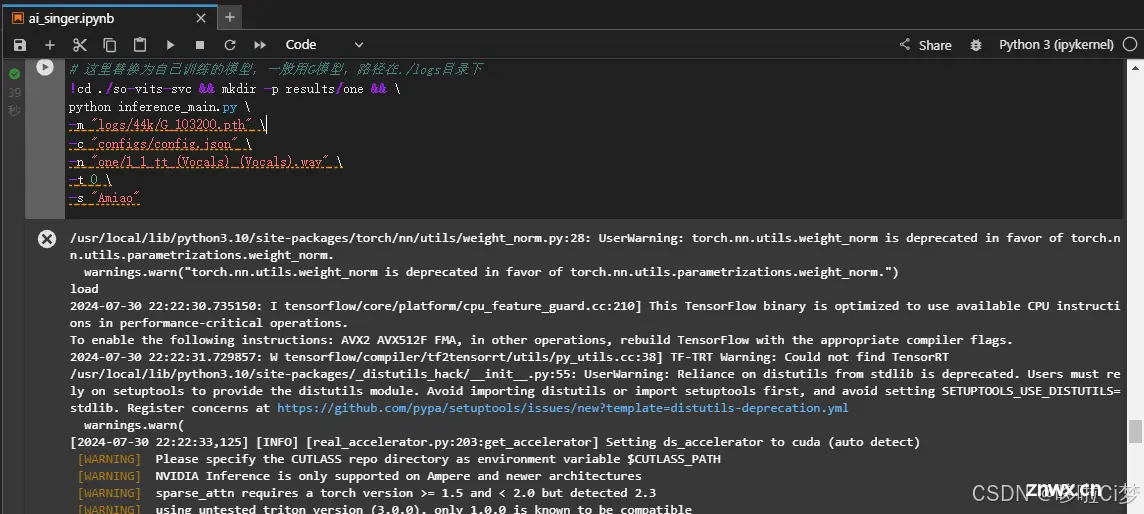
这个模型训练时间一般要1天甚至更多时间。
Step 10:推理
在声音模型训练完成后,就可以用这个模型,加上目标音乐,进行拟合,也就是推理的过程。推理的结果就是用Ai声音唱好了一首歌。
只需要关注上图划线部分,打叉部分不用处理,因为我要用自己的推理数据(看你让AI唱什么歌就用什么歌)。
这里我选择了宇多田光的《FirstLove》这首歌,非常经典的一首歌~,还是用UVR5这个软件把这首歌进行人声伴奏分离,然后放在raw/one/目录下。
<code>> 参数:
> - -m(--model):模型输出路径。
> - -c(--config):训练配置文件。
> - -n(--clean_names):需要推理的wav文件名列表,放在raw文件夹下。
> - -t(--trans):音高调整,支持正负(半音)。一般女转男可调整至-5~-8,男转女可调整至5~8,仅供参考,实际情况需根据人物的真实声音进行调整。
> - -s(--spk_list):合成目标说话人名称。
开始推理:注意,在44k这个目录下有好几个模型文件,一般用G开头的就行,这里模型文件有什么不一样,笔者暂时不清楚,还要翻阅官方wiki才知道。
# 这里替换为自己训练的模型,一般用G模型,路径在./logs目录下
!cd ./so-vits-svc && mkdir -p results/one && \
python inference_main.py \
-m "logs/44k/G_103200.pth" \
-c "configs/config.json" \
-n "one/1_1_tt_(Vocals)_(Vocals).wav" \
-t 0 \
-s "Amiao"

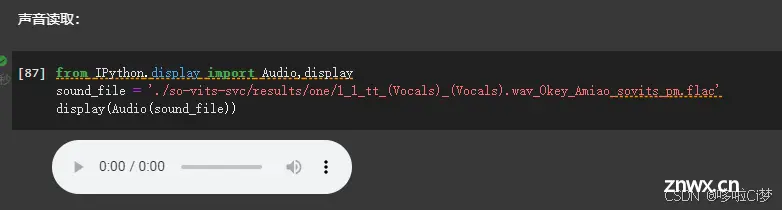
推理完成后,输出的一份纯人声数据,可以先听听看,如下图,
<code>from IPython.display import Audio,display
sound_file = './so-vits-svc/results/one/1_1_tt_(Vocals)_(Vocals).wav_0key_Amiao_sovits_pm.flac'
display(Audio(sound_file))
Step 11:人声与伴奏合并
这是大功告成前的最后一步咯
要先安装这个库,
pip install pydub
然后运行如下代码,注意事项在代码备注里有写了,这里再强调下,
vocal_audio是刚才推理的结果
instrumental_audio是我们分离好的宇多田光这首歌的伴奏
from pydub import AudioSegment
from IPython.display import Audio,display
vocal_audio = './so-vits-svc/results/one/1_1_FirstLove_(Vocals)_(Vocals).wav_-5key_Amiao_sovits_pm.flac'
instrumental_audio = './so-vits-svc/raw/one/1_FirstLove_(Instrumental).wav'
save_path = './so-vits-svc/results/one_Amiao.wav'
sound1 = AudioSegment.from_file(instrumental_audio, format='wav')code>
sound2 = AudioSegment.from_file(vocal_audio, format='flac')code>
# sound2 += 2 # sound2音高+5
output = sound1.overlay(sound2) # 把sound2叠加到sound1上面
# output = sound1.overlay(sound2,position=5000) # 把sound2叠加到sound1上面,从第5秒开始叠加
output.export(save_path, format="wav") # 保存文件code>
print('Export successfully!')
display(Audio(save_path))
结语:
好久没更新了,但是按耐不住对人工智能大模型的好奇,这个项目很简单很微小,但也是一次尝试。留下一点笔记,做个纪念。最后吐槽一下,Ai唱的好像还没有我自己唱的好
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。