ai唱歌---So-VITS-SVC使用教程
千万小白 2024-10-08 16:31:01 阅读 92
目录
配置要求
介绍
下载整合包
数据集配置
开始训练
利用Tensorboard查看训练状态
Losses 详解
推理 (如果你只是想尝试一下,看到此即可)
特征编码器
关于浅扩散
聚类模型
特征检索
配置要求
一张支持CUDA的N卡并至少拥有6G显存
至少30G虚拟内存(软件是这样提示的,但经测试30G远远不够满足训练和推理需求)
windows10/11
介绍
So-VITS-SVC可以通过训练某人的音声,使音频转化为目标声音,实现歌声转换的功能,本篇文章将教你如何从0开始训练自己的模型并用其来推理
下载整合包
整合包下载
点击上面链接,下载b站大佬羽毛布団制作的整合包,下载完成后打开UVR5文件夹,双击UVR_v5.6.0_setup.exe,根据提示安装UVR5
slicer-gui下载
点击上面链接到github,然后点击绿色的“code”按钮,再点击download zip下载,下载后解压
数据集配置
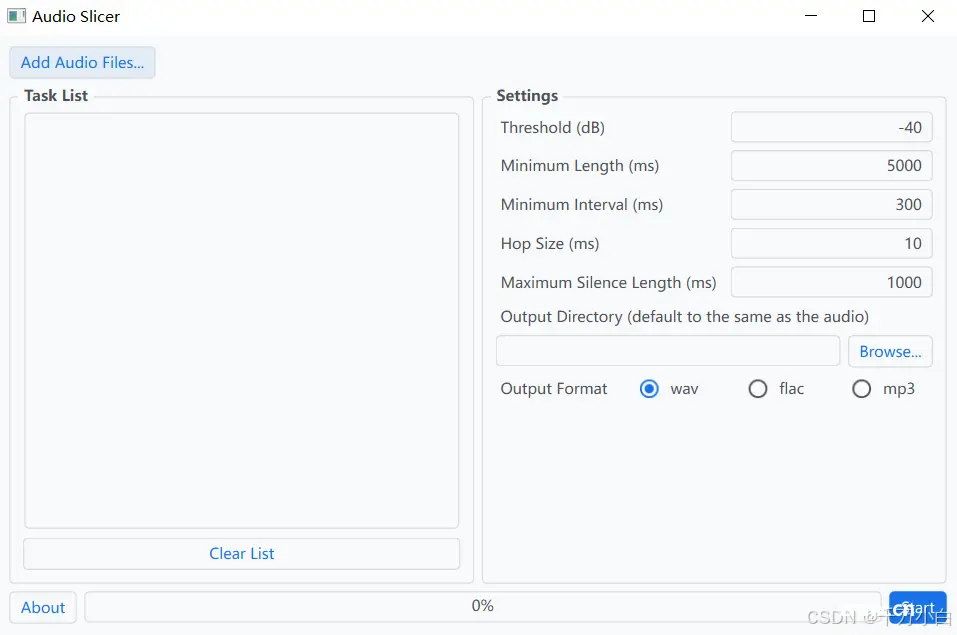
首先我们要搜集训练目标的说话数据集(至少30分钟纯人声或歌声,1-2小时最佳),如果该音频不是纯人声,我们要用UVR5提取人生,如果不会用UVR5可以用以下设置来提取
在choose vr model中,你可能没有6_HP-Karaoke选项,这时你需要点击download more model中去下载该模型,勾选上VR Arch下滑找到该模型下载即可
下载好后回到初始页面,并设置好后,点击将数据集拖到select input旁边的框中,然后点击select output选择输出路径,然后点击下面的start processing即可开始提取(可以使用
提取完成后打开audio slicer将处理好的数据拖到task list中,接着点击browse选择输出路径,点击start即可开始对数据进行切片处理

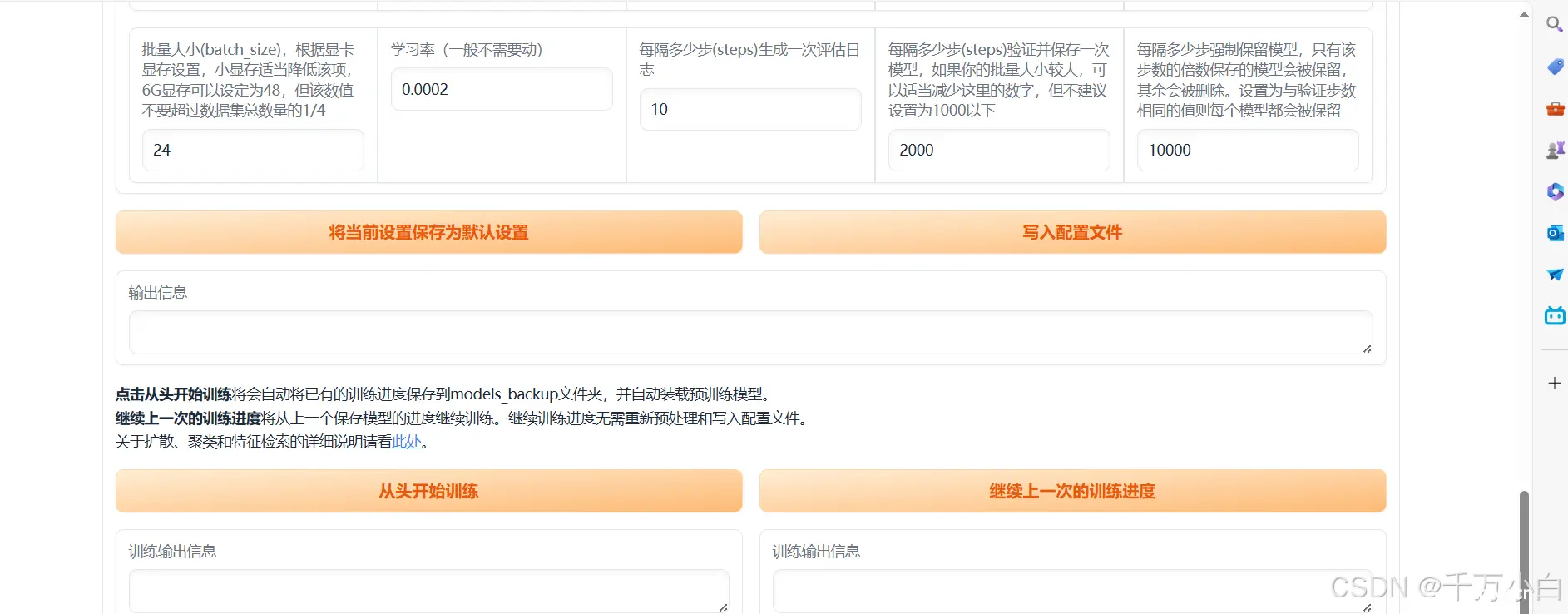
开始训练
将处理好的数据集文件夹改名为speaker0,拖到\So-VITS-SVC新版\新版整合包\so-vits-svc\dataset_raw 路径下,然后回到\So-VITS-SVC新版\新版整合包\so-vits-svc路径,双击打开”启动webui.bat“,可能需要一段时间启动,启动后点击训练界面
接下来点击识别数据集,然后在“选择训练使用的编码器”中选择hubertsoft模型
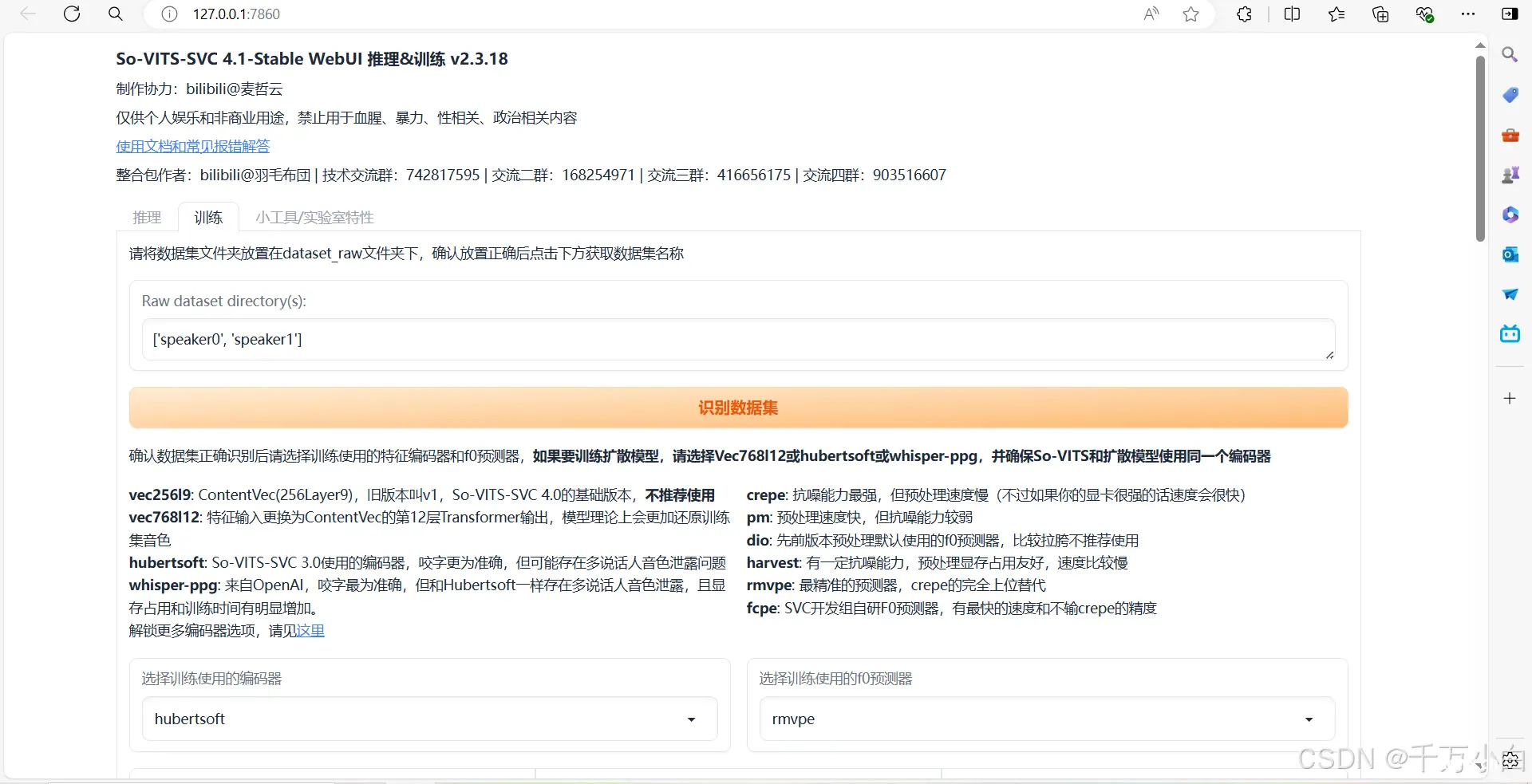
接着点击数据预处理,等待一段时间,处理完成后点击生成配置文件

配置文件生成后,点击写入配置文件,输出信息“配置文件写入完成”就可以开始训练了

点击从头开始训练即可开始训练,最少训练800step以后模型才会保存
请严格区分轮数 (Epoch) 和步数 (Step):1 个 Epoch 代表训练集中的所有样本都参与了一次学习,1 Step 代表进行了一步学习,由于 batch size 的存在,每步学习可以含有数条样本,因此,Epoch 和 Step 的换算如下:
Epoch=Stop/(数据集条数/batch size)
训练默认 10000 轮后结束,但正常训练通常只需要数百轮即可有较好的效果。当你觉得训练差不多完成了,可以在训练终端按 Ctrl + C 中断训练。中断后只要没有重新预处理训练集,就可以在 WebUI 中继续上一次保存的训练进度
利用Tensorboard查看训练状态
首先“模型什么时候训练好”是一个没有意义的问题,因为数据集质量,选用模型,f0算法等原因,我们无法知道模型训练的怎么样样了,但我们可以通过tensorboard辅助我们查看训练状态
首先双击“启动tensorboard.bat”运行即可查看
Losses 详解
你不需要理解每一个 loss 的具体含义,大致来说:
loss/g/f0、loss/g/mel和loss/g/total应当是震荡下降的,并最终收敛在某个值loss/g/kl应当是低位震荡的loss/g/fm应当在训练的中期持续上升,并在后期放缓上升趋势甚至开始下降
推理 (如果你只是想尝试一下,看到此即可)
停止训练后切回推理界面,当然你显卡比较好的话可以一边训练一边推理,首先使用UVR5提取要转化音频的人生(使用instrumental only可以提取伴奏,推理完成后可以将伴奏和音频再合并到一块)
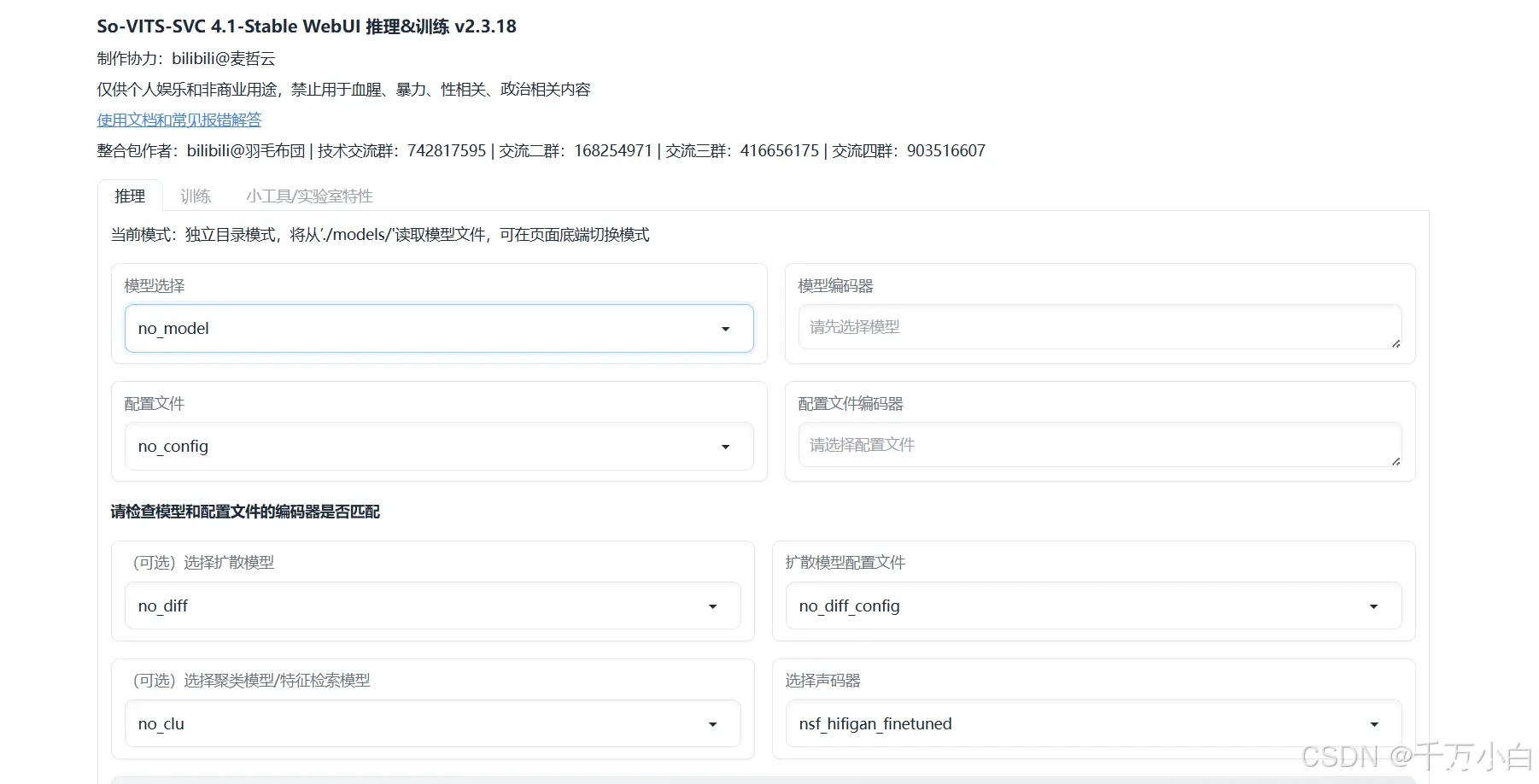
点击模型选择,选择一个模型(一般数越大越好,但实际情况要用耳朵听),然后选择配置文件,下滑点击加载模型,然后在选择音频处选择你要转换的音频,最后点击音频转换等待一段时间即可获得该模型声音的音频了
通过以上教程即可实现声音转换了,以下为其他东西的讲解
特征编码器
特征编码器起到的作用是将数据集中的特征提取出来以供神经网络学习。你必须在训练时指定一个编码器。目前整合包支持 4 个基础编码器:
我将按一下格式来介绍:模型名称---优点---缺点
vec256l9---无---不支持扩散模型
vec768l12---最还原音色、有大型底模、支持响度嵌入---咬字能力较弱
hubertsoft---咬字能力较强---音声泄露
whisper-ppg---咬字最强--音色泄露、显存占用高
关于浅扩散
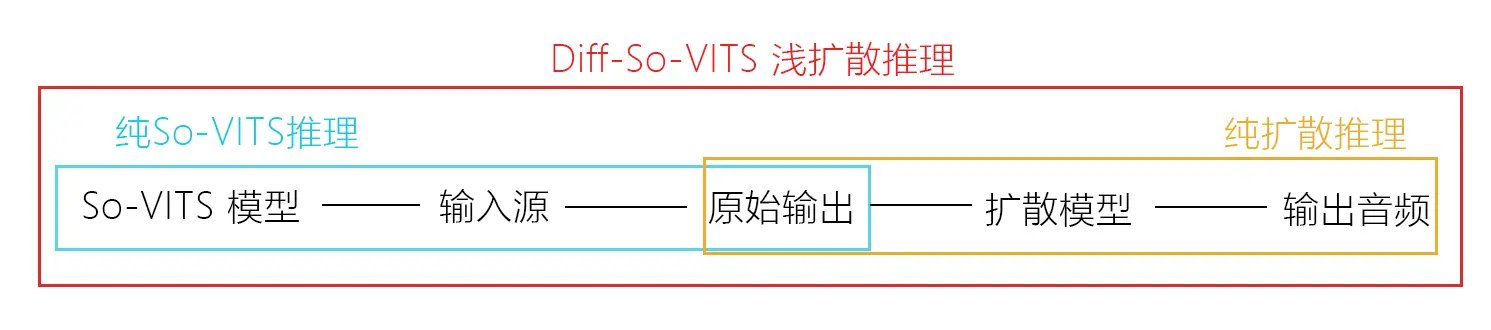
So-VITS 4.1 近期的一个重大更新就是引入了浅扩散 (Shallow Diffusion) 机制,将 So-VITS 的原始输出音频转换为Mel谱图,加入噪声并进行浅扩散处理后经过声码器输出音频。经过测试,原始输出音频在经过浅扩散处理后可以显著改善电音、底噪等问题,输出质量得到大幅增强。
要使用浅扩散机制:
你必须在原有数据集上训练一个新的扩散模型数据预处理时勾选“训练扩散模型”确保扩散模型和 So-VITS 模型配置文件中的说话人名称一致在推理时加载扩散模型
扩散模型与 So-VITS 模型是独立的,得益于浅扩散机制的向下兼容性,你仍然可以只使用其中任意一个模型进行推理,或者同时使用 So-VITS 和扩散模型进行完整的浅扩散推理。
聚类模型
聚类方案可以减小音色泄漏,使得模型训练出来更像目标的音色(但其实不是特别明显),但是单纯的聚类方案会降低模型的咬字(会口齿不清,这个很明显)。本模型采用了融合的方式,可以线性控制聚类方案与非聚类方案的占比,也就是可以手动在"像目标音色" 和 "咬字清晰" 之间调整比例,找到合适的折中点。
使用聚类只需要额外训练一个聚类模型,虽然效果比较有限,但训练成本也比较低。
特征检索
特征检索和聚类方案一样,可以减少音色泄露,使得模型的输出更像目标音色,但特征检索的咬字比聚类稍好一些。特征检索同样使用了混合比例,可以线性控制特征检索的占比。启用特征检索会稍微降低推理速度(不是很明显)。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。