AI 赋能大模型:从 ChatGPT 到国产大模型的角逐与发展契机
高性能服务器 2024-10-01 14:31:01 阅读 66
在当今科技飞速发展的时代,大模型作为人工智能领域的关键技术,正引发着深刻的变革。它们在自然语言处理、计算机视觉、语音识别等众多领域展现出了惊人的潜力,为各行各业带来了前所未有的机遇和挑战。本文将深入剖析大模型的技术原理、市场态势以及算力需求等方面,全面展现其发展的现状与未来前景。
一、大模型的基石与演进
1. “规模定律” 与大模型的发展
大语言模型(Large Language Models,LLM)通常指具有超大规模参数或经过超大规模数据训练的语言模型。与传统语言模型相比,大模型在自然语言理解和复杂任务处理方面具有显著优势,其发展呈现出 “规模定律”(Scaling Law)的特征,即模型的性能与模型的规模、数据集大小以及训练所用的计算量之间存在幂律关系。这意味着随着模型规模的扩大、数据集的丰富以及计算量的增加,模型的性能将呈现出线性提升的趋势。
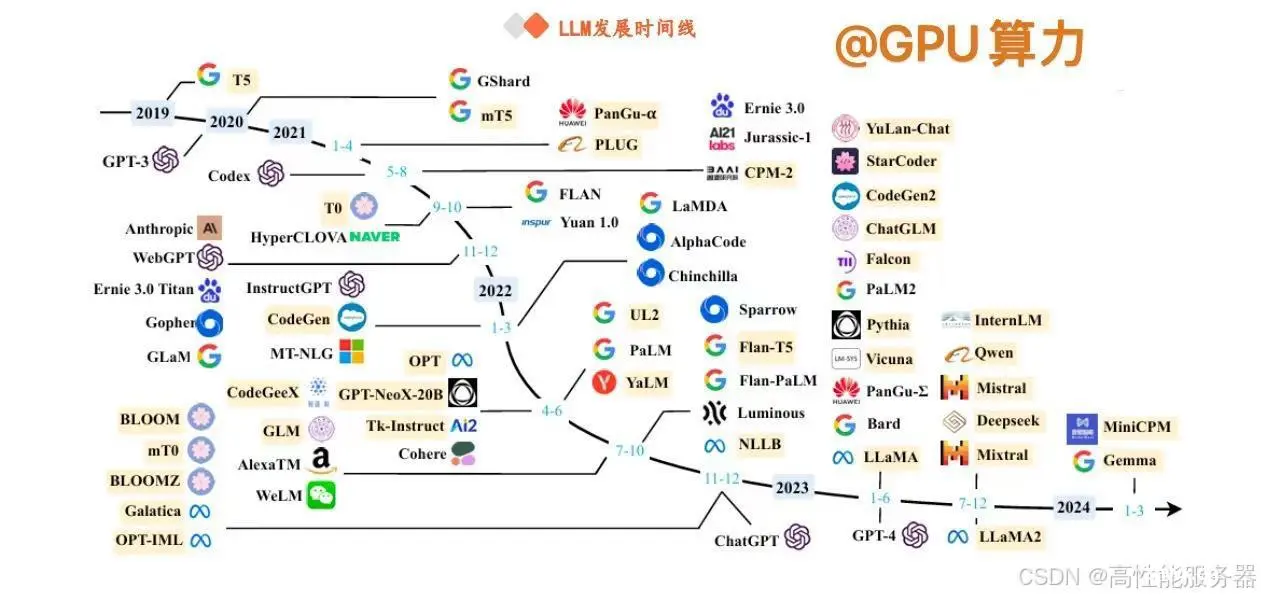
2.Transformer模型的独特优势
当前主流大模型大多基于Transformer模型构建,Transformer模型于2017年在Google团队的论文《Attention Is All You Need》中首次被提出,其核心优势在于独特的自注意力(Self - attention)机制。这一机制能够直接建模任意距离的词元之间的交互关系,有效地解决循环神经网络(RNN)、卷积神经网络(CNN)等传统神经网络在处理长序列数据时存在的依赖问题。与RNN相比,Transformer具有以下显著优势:
-卓越的长序列数据处理能力:RNN受其循环结构的限制,在处理长序列数据时面临挑战。而Transformer的Self - attention 机制能够同时处理序列中的所有位置,精准地捕捉全局依赖关系,从而更准确地理解和表示文本含义。
-高效的并行计算实现:RNN作为时序结构,需要依次处理序列中的每个元素,计算速度受到较大限制。而Transformer则可以一次性处理整个序列,大大提高了计算效率,为大规模数据的快速处理提供了可能。
3.Transformer的组件与网络架构演变
Transformer由Encoder(编码器)和Decoder(解码器)两类组件构成。Encoder擅长从文本中提取信息,以执行分类、回归等任务;Decoder则主要用于生成文本。在实际应用中,这两类组件可以独立使用,并且衍生出了多种架构的大规模预训练语言模型,如以BERT为代表的Encoder - only 架构、以T5为代表的Encoder - decoder 架构以及以GPT为代表的Decoder - only 架构。
4. GPT 系列模型的发展历程
从GPT - 1 到GPT - 3 的演进:
GPT - 1:2018 年,OpenAI 推出的第一个 GPT 模型,基于生成式、Decoder - only 的 Transformer 架构开发。由于参数规模相对较小,其通用任务求解能力有限,采用了 Pre - training(预训练)+ Fine - tuning(微调)的两阶段范式,通过单向 Transformer 预训练通用模型,再在特定子任务上进行微调。
GPT - 2:沿用了类似架构,但将参数规模扩大至 1.5B,并使用大规模网页数据集 WebText 进行预训练。与 GPT - 1 不同的是,GPT - 2 旨在通过扩大模型参数规模来提升性能,并尝试使用无监督预训练的语言模型来解决各种下游任务。
GPT - 3:经过充分的实验探索,OpenAI 于 2020 年将模型参数扩展到了 175B,较 GPT - 2 提升了 100 余倍,验证了神经网络超大规模扩展对模型性能的大幅提升作用。同时,GPT - 3 正式提出了 “上下文学习” 的概念,建立了以提示学习方法为基础的任务求解范式。
ChatGPT 的突破与创新:
在 GPT - 3 的基础上,OpenAI 通过代码训练、人类对齐、工具使用等技术不断升级模型性能,推出了 GPT - 3.5 系列模型。
2022 年 11 月,ChatGPT 正式上线,以对话形式解决多种任务,用户可通过网络 API 体验其强大功能。ChatGPT仅用 5 天时间注册用户便达到 100 万,约 2 个月注册用户达到 1 亿,成为 AIGC 领域的现象级应用。
ChatGPT 主要沿用了 2022 年 1 月推出的 InstructGPT,其核心技术是基于人类反馈的强化学习算法(RLHF 算法,Reinforcement Learning from Human Feedback),旨在改进模型与人类的对齐能力。具体实现过程中,人类标注人员扮演用户和代理进行对话,产生对话样本并对回复进行排名打分,将更好的结果反馈给模型,让模型从人类评价奖励和环境奖励两种反馈模式中学习策略,实现持续迭代式微调。
GPT - 4 系列的进阶与发展:
GPT - 4:2023 年 3 月,OpenAI 发布的 GPT - 4 首次将输入由单一文本模态扩展到了图文双模态,在解决复杂任务方面的能力显著强于 GPT - 3.5,在一系列面向人类的考试中取得了优异成绩。
GPT - 4V:基于 GPT - 4,OpenAI 于 2023 年 9 月进一步发布了 GPT - 4V,重点关注 GPT - 4 视觉能力的安全部署,在多种应用场景中展现出强大的视觉能力与综合任务解决能力。
GPT - 4 Turbo:2023 年 11 月,OpenAI 在开发者大会上发布了 GPT - 4 Turbo,引入了一系列技术升级,包括将模型内部知识库更新至 2023 年 4 月、将上下文长度提升至 128K、降低价格以及引入若干新功能(如函数调用、可重复输出等)。
GPT - 4o:今年 5 月 14 日,OpenAI 在春季发布会上推出了新版旗舰模型 GPT - 4o,将文本、音频和视觉集成到一个模型中,提供更快的响应时间、更好的推理能力以及在非英语语言中的更佳表现。不仅在传统文本能力上与GPT - 4 Turbo 性能相当,在 API 方面也更快速且价格便宜 50%。与 GPT - 4 Turbo 相比,GPT - 4o 速度提高了 2倍,限制速率提高了 5 倍,目前的上下文窗口为 128k,模型知识截止日期为 2023 年 10 月。

二、全球大模型竞争格局与国产大模型的崛起
1.全球大模型竞争态势
在全球大模型竞争中,OpenAI、Anthropic、谷歌三大厂商处于第一梯队。OpenAI率先推出GPT - 4,在2023年基本占据行业龙头地位,而Anthropic凭借Claude、谷歌凭借Gemini奋起直追,2024年以来,三家大模型能力呈现相互追赶的态势。
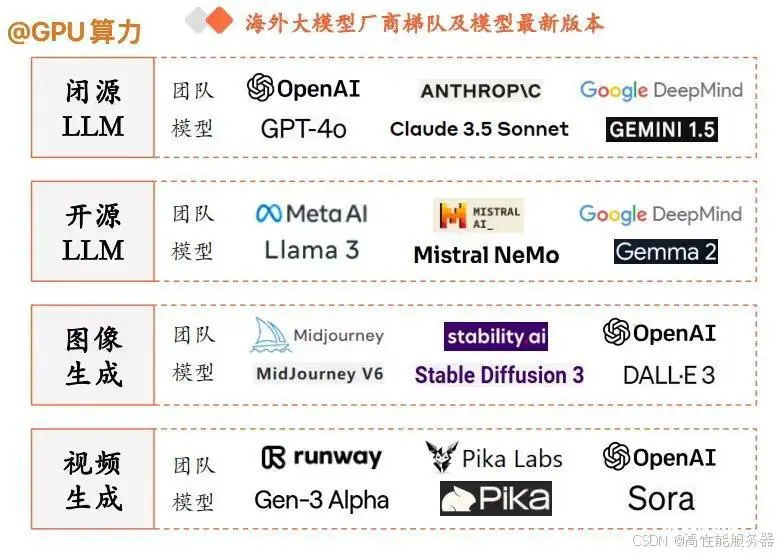
在开源大模型厂商中,Meta AI(Llama)、欧洲Mistral AI(Mistral)、Google(Gemma)等厂商的大模型性能表现优异。此外,随着Sora的推出以及Pika的崭露头角,图像、视频生成领域取得了超预期的进展,备受关注。全球图像生成大模型以Midjourney、Stable Diffusion、OpenAI的DALL・E为代表,视频生成则以Runway的Gen、Pika和OpenAI的Sora为代表。
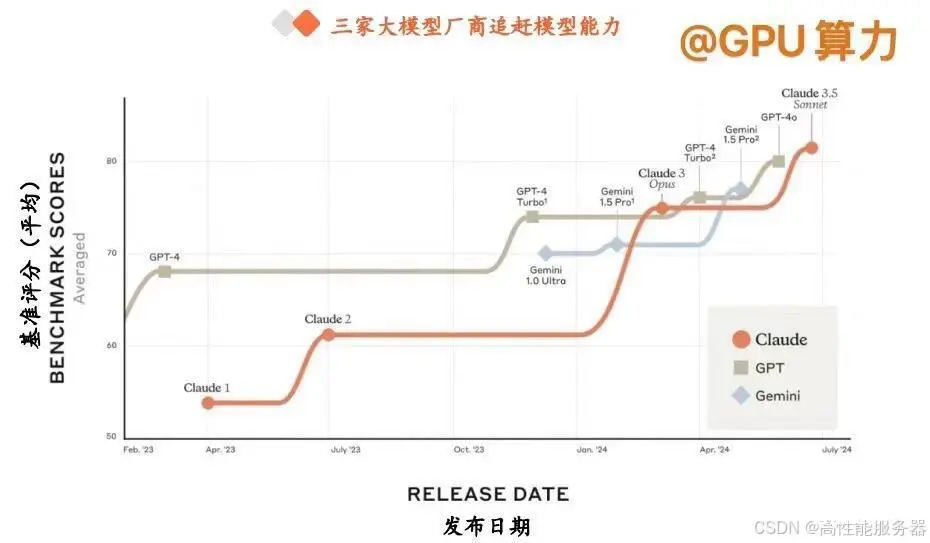
1).OpenAI的进展与突破:
文生视频大模型 Sora 的发布:今年 2 月 15 日,OpenAI 正式发布 Sora,能够在保持视觉质量和遵循用户文本提示的情况下,生成长达 1 分钟的视频,远超以往的视频生成时长。
GPT - 4o 的性能与实用性提升:5 月 14 日,OpenAI 在春季发布会上推出 GPT - 4o,可接受文本、音频和图像的任意组合作为输入和输出,在英语文本和代码方面的性能可与 GPT - 4 Turbo 媲美,同时在 API 方面更快且便宜50%。在 GPT - 4o 之前,使用语音模式与 ChatGPT 对话时,GPT - 3.5/GPT - 4 的平均延迟分别为 2.8/5.4 秒,而GPT - 4o 可以在短至 232 毫秒的时间内响应音频输入,平均时长为 320 毫秒,与人类在一次谈话中的响应时间相当。
GPT - 4o mini 的推出:7 月 18 日,OpenAI 正式推出 GPT - 4o mini,将取代 ChatGPT 中的旧模型 GPT - 3.5 Turbo,向 ChatGPT 的免费用户、ChatGPT Plus 和团队订阅用户开放。GPT - 4o mini 的成本为每百万输入标记(token)15 美分和每百万输出标记 60 美分,比 GPT - 3.5 Turbo 便宜超过 60%。
2). Anthropic 的创新与发展:
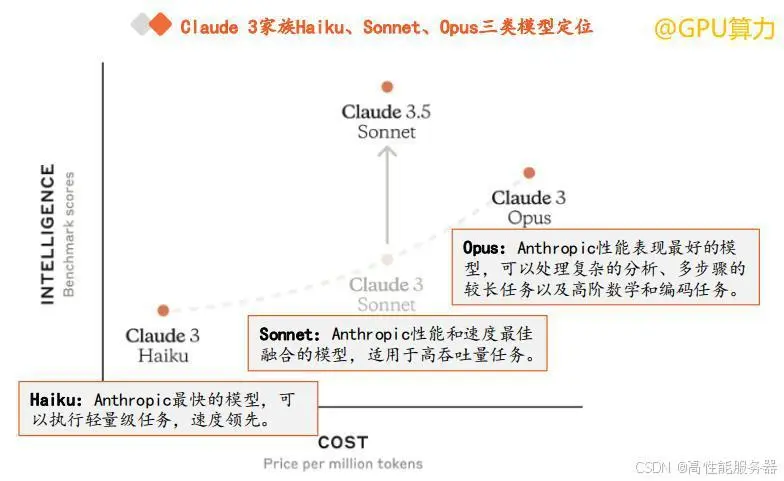
Claude 3 家族的推出:今年 3 月 4 日,Anthropic 发布了 Claude 3 系列模型,包括 Opus、Sonnet 和 Haiku。Opus代表 Anthropic 最高级、最智能的模型,Sonnet 代表中等级别的模型,在性能和成本效益之间取得平衡,Haiku代表入门级别或最基础的快速模型。其中,Claude 3 Opu 被官方认为是性能全面超过 GPT - 4 的最强版本。
Claude 3.5 Sonnet 的优势:6 月 21 日,Anthropic 发布了全新大模型 Claude 3.5 Sonnet,被称为 “迄今为止最智能的模型”。据 Anthropic 介绍,Claude 3.5 Sonnet 在绝大多数基准评估中都超越了竞品大模型和自家前代最强Claude 3 Opus,同时在运行速度和成本方面与自家前代 Claude 3 Sonnet 相当。
3).谷歌的全面升级与创新:
Gemini 系列的升级:继 2023 年 12 月推出规模最大、功能最强的多模态大模型 Gemini 系列之后,今年 2 月 15日,谷歌发布 Gemini 1.5,其中首个登场的多模态通用模型 Gemini 1.5 Pro 将稳定处理上下文的上限扩大至 100万 tokens。
在谷歌 IO 开发者大会上的升级:5 月 14 日,谷歌大模型在开发者大会上迎来多项升级。基础大模型方面,Gemini 1.5 Pro 将上下文窗口长度从之前的 100 万 tokens 进一步扩展至 200 万 tokens,谷歌首席执行官 Pichai 称这是目前市场上处理上下文长度规模最大的基础大模型。
视频生成模型 Veo 和文生图模型 Imagen 3 的发布:谷歌发布了视频生成模型 Veo 以及文生图模型 Imagen 3,Veo 模型对标 Sora,能够根据文字、图片和视频的提示生成长度超过 1 分钟、分辨率最高 1080p 的视频;Imagen 3 文生图模型是 Imagen 系列的升级版,从细节拟真度来看对标 Midjourney v6。
4).Meta的突破与进展:
Llama 3 的推出:今年 4 月 18 日,Meta 推出强大的开源人工智能模型 Llama 3,发布了包括 8B 和 70B 参数的两个版本,作为 Llama 2 的重大升级。Meta 表示,正在开发的最大模型是 400B 参数的版本,将在未来几个月内推出。英伟达科学家 Jim Fan 认为,Llama 3 400B 将成为一个分水岭,意味着社区将获得开源的重量级 GPT - 4 模型,这将改变许多研究工作和草根创业公司的计算方式。
Llama 3.1 的发布:7 月 23 日,Llama 3.1 正式发布,其 405B 版本在 150 多个基准测试集上的表现追平或超越现有领先的基础模型,包括 GPT - 4、GPT - 4o 和 Claude 3.5 Sonnet。除了与闭源模型相比具有显著更好的成本 /性能比之外,405B 模型的开放性使其成为微调和蒸馏更小模型的优质选择。此外,Meta 也推出了 8B 和 70B 模型的升级版本,能力与同等参数下的顶尖模型基本持平,与具有相似参数数量的开闭源模型构成强大竞争力。
2.国产大模型的发展态势
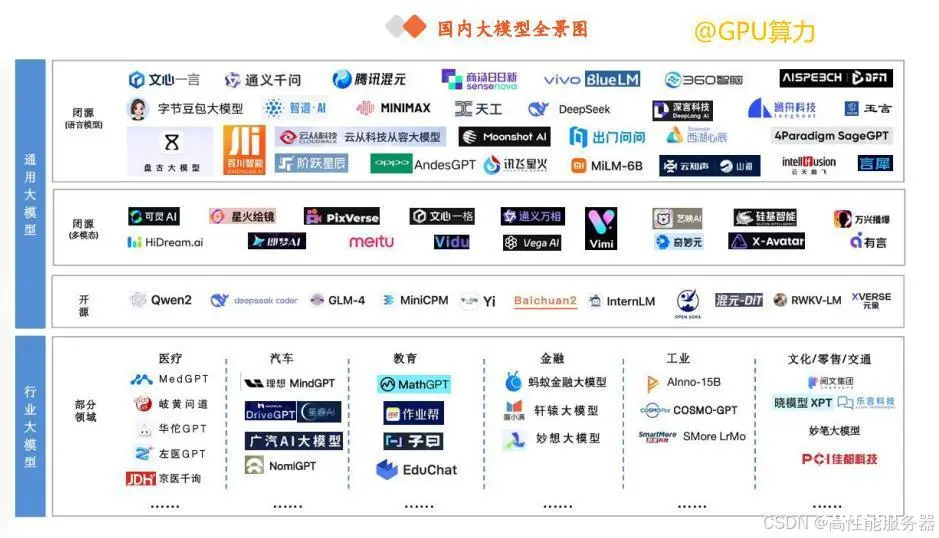
自2022年11月底ChatGPT发布以来,AI大模型在全球范围内掀起了巨大的浪潮,国内学术和产业界也积极响应,加紧追赶突破。
国内大模型的发展大致分为三个阶段:
1).准备期:2022年11月ChatGPT发布后,国内产学研界迅速形成对大模型的共识。
2).成长期:2023年初,国内大模型的数量和质量开始逐渐增长。
3).爆发期:2023年底至今,各行各业开源闭源大模型层出不穷,形成了百模大战的竞争态势。
从参与者的角度来看,我国AI大模型厂商大致可以分为四类:
1).互联网/科技公司:以百度、阿里、腾讯、字节、快手、华为等为代表。
2).AI公司:以智谱AI、昆仑万维、科大讯飞、商汤科技等专注于AI研发与应用的科技公司为代表。
3).学术、科研机构:包括清华、北大、复旦、中科院等国内一流高校,以及智源研究院、IDEA研究院等科研机构。
4).行业专家品牌:以月之暗面(Moonshot AI)、百川智能、MiniMax等由AI专家创业成立的公司为代表。
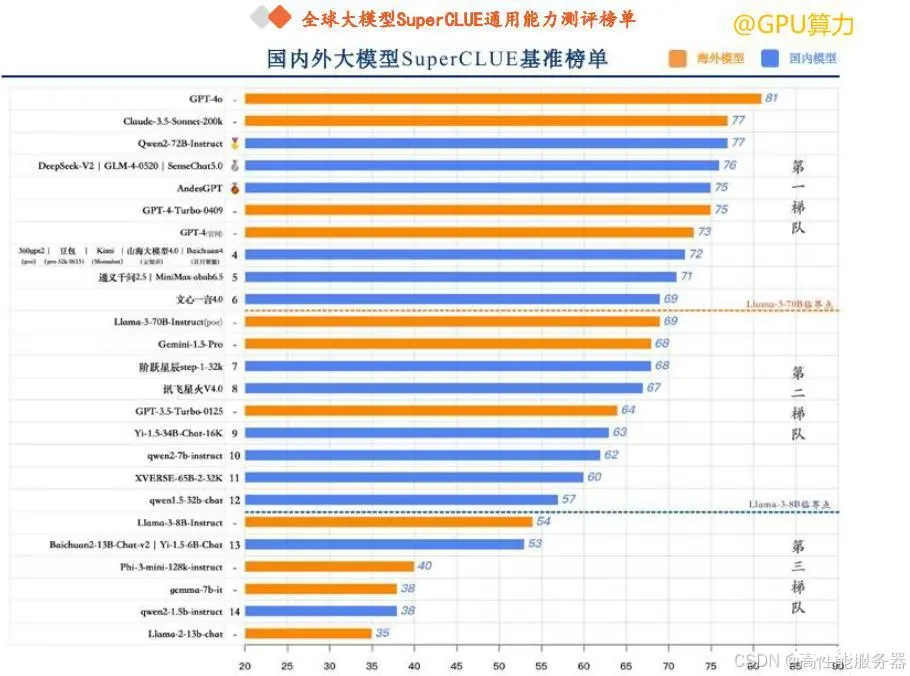
从模型能力的角度来看,以开源Llama - 3 - 70B、Llama - 3 - 8B 的模型能力为分界线,国内大模型形成三大梯队:
1).开源模型Qwen2 - 72B 在SuperCLUE基准中表现出色,超过众多国内外闭源模型,与Claude - 3.5 持平,与GPT - 4o 仅差4分。
2).4个国内大模型(深度求索DeepSeek - V2、智谱GLM - 4、商汤SenseChat5.0、OPPO的AndesGPT)超过GPT - 4 - Turbo - 0409。
3).专家创业团队如Baichuan4、Kimi、MiniMax - abab6.5 均有超过70分的表现,位列国内大模型第一梯队。
4).国内绝大部分闭源模型已超过GPT3.5 Turbo – 0125。
三、大模型商业的挑战与机遇
1.大模型商业形态的多元化
大模型的收费模式可以概括为API、订阅、广告、定制化四种。大模型最常见的商业模式遵循软件行业的SaaS(Software as a Service)模式,通用大模型通常采用API模式,根据tokens / 调用次数/产出内容量等进行计价。当大模型形成AI产品后,可以采用订阅制,按月/季/年向用户收取使用费。如果AI产品具有一定的流量价值,能够吸引商家投放广告,从而实现广告收费。此外,对于付费能力强的企业客户,部分厂商会提供软硬件一体的定制化解决方案,即MaaS(Model as a Service)。
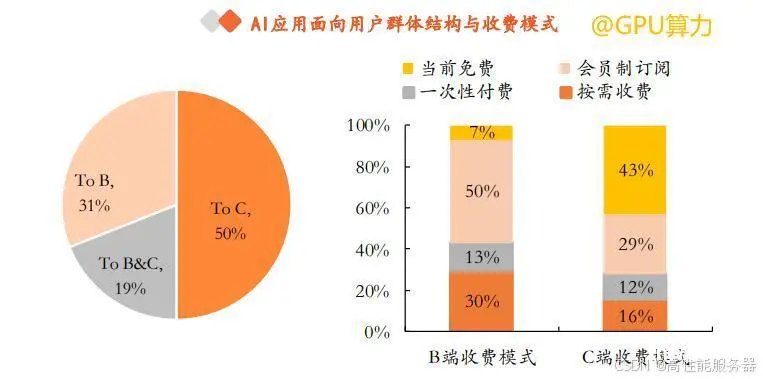
从AI产品的商业化程度来看,B端的变现模式更为清晰,而C端的大多数产品仍以免费为主。面向B端的AI产品在通用场景到垂直赛道的分布较为均匀,收入模式以会员订阅和按需付费为主,商业模式相对清晰。尽管纯B端市场占比仅为31%,但80%以上的B端产品都能够实现营收。C端AI产品主要以智能助手以及图像生成类的生产力工具为主,虽然用户量较大(纯C端占比50%以上),但近50%的C端产品目前仍没有明确的收入模式,主要以免费形式提供。
2.OpenAI的商业模式
OpenAI确立了一种较为经典的大模型商业模式,主要包括ChatGPT订阅、API调用和战略合作三种营收方式:
- ChatGPT 订阅:OpenAI向C端用户提供ChatGPT这一生产力解放工具,并通过付费订阅的方式实现变现,针对ChatGPT Plus 会员收取每月20美元的订阅费。
- API 调用:对于模型使用灵活性要求较高的用户,OpenAI提供API服务,根据模型的调用量(tokens)或产出内容量(如图片张数、时长)进行收费。
-战略合作:OpenAI与微软建立了密切的合作关系。在To C 方面,OpenAI的模型能力嵌入到微软的生成式AI工具中,如GitHub、Office、Bing等;在To B 方面,微软Azure是OpenAI的独家云服务提供商,Azure全球版企业客户可以在平台上直接调用OpenAI模型。

3.全球API定价的趋势
1). API作为大模型厂商普遍采用的营收模式,由于大模型性能逐渐趋向同质化,全球API价格呈现出下降的趋势。今年5月,作为行业风向标的OpenAI发布了GP - 4o,面向ChatGPT所有付费和免费用户发布,并支持免费试用,其API价格比GPT - 4 - turbo降低了50%,输入价格低至5美元/百万tokens。同时,谷歌发布的Gemini 1.5 Flash也将输入价格定为0.35美元/百万tokens。
2).国内方面,5月6日,AI公司深度求索(DeepSeek)率先宣布降价,其发布的第二代MoE大模型DeepSeek - V2的输入价格定为0.001元/千tokens,输出价格为0.002元/千tokens。随后,智谱AI、火山引擎、阿里云、百度、科大讯飞、腾讯云等国内主要大模型厂商也迅速跟进降价。
4.订阅制的挑战与AI Agent的机遇
1).订阅制实现难度较高:尽管有ChatGPT的成功案例,但许多大模型厂商在尝试通过构建AI应用来推行付费订阅制时,面临着用户留存度和粘性不足的问题。即使是ChatGPT、runway等具有代表性的大模型产品,其用户留存度和粘性尚未达到现有领先C端应用的水平。
2).AI Agent:AGI(Artificial General Intelligence,通用人工智能)能力的实现是一个渐进的过程,而具有专业能力、可定制的AI Agent(智能体)被认为是打开AGI之门的关键。2023年6月,OpenAI应用研究主管Lilian Weng提出:Agent = LLM + 记忆+规划技能+能+工具使用。在2024年红杉资本的人工智能峰会上,吴恩达认为Agent应该具备反思(Reflection)、使用工具(Tool use)、规划(Planning)以及多智能体协同(Multi - agent collaboration)四种主要能力。
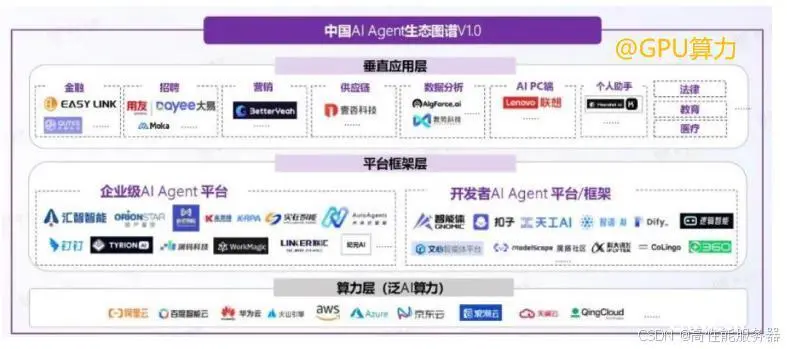
3).国内AI Agent市场的发展:以互联网大厂、大模型厂商、企业服务SaaS类厂商为代表的众多企业纷纷参与到AI Agent市场中,产品形态既包括面向企业和开发者的Agent构建平台/框架,也包括服务于各个垂直行业的专业Agent。2024年上半年,国内多个AI Agent平台相继发布,这将进一步提升AI Agent的开发便利性,加速国内大模型应用的发展。
4).2月,字节跳动的新一代一站式AI Bot开发平台扣子Coze在国内上线,用户可以快速、低门槛地构建专属聊天机器人;4月,百度AI开发者大会发布了文心智能体平台AgentBuilder;随后,钉钉正式上线AI Agent Store,首批上架了包括通义千问在内的超过200个AI Agents。
5.MaaS助力企业降低模型使用门槛
1).B端对大模型的需求增长:
根据a16z的调研,2023年平均每家受访企业在API、自托管和微调模型上的支出达到700万美元,并且几乎所有企业计划将2024年LLM预算增加2 - 5倍。企业的AI模型采购决策主要受云服务提供商(CSP)的影响。2023年,大多数企业出于安全考虑通过现有的CSP购买模型,2024年这一情况仍在延续。在使用API访问模型的受访企业中,有超过50%的企业通过其CSP(如Azure、Amazon等)访问,例如Azure用户更常用OpenAI,而Amazon用户更倾向于使用Anthropic或Cohere。剩下28%的受访企业选择了自托管,可能是出于运行开源模型的需要,采用私有化部署或者CSP提供的GPU服务。
2).Maas的作用:
根据中国信通院的定义,MaaS围绕低技术门槛、模型可共享、应用易适配三大特性,提供包括算力服务、平台服务、模型服务、数据集服务、AI应用开发服务在内的全栈服务,使企业能够快速高效地构建、部署、监控和调用模型,无需开发和维护底层基础能力。
3).云厂商的布局:
目前,微软云Azure、阿里云、华为云、腾讯云、百度云、京东云等CSP都已经推出了MaaS服务。以阿里云的魔搭ModelScope为例,它支持用户使用来自达摩院大模型平台和SOTA模型矩阵的超过300个优质大模型,提供包括模型管理和下载、模型调优、训练、推理、部署、应用在内的一站式模型服务。
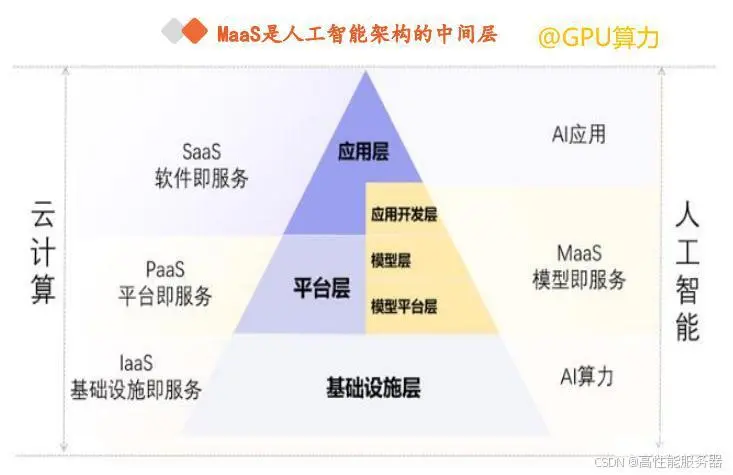
四、大模型发展对算力的需求与挑战
1.大模型发展与算力需求
大模型的发展受到多种资源的制约,包括能源、算力、显存、通信等。在训练端,大模型延续Scaling Law的主流技术路线,通过扩大参数规模和数据集的大小来提升模型性能,导致对算力的持续需求。
在推理端,以ChatGPT为代表的AI应用的广泛使用也驱动着算力需求呈指数级增长。根据Jaime Sevilla等人的研究,2010 - 2022年在深度学习兴起的背景下,机器学习训练算力增长了100亿倍。2016 - 2022年,常规模型算力每5至6个月翻一倍,而大规模模型算力每10至11个月翻一倍。
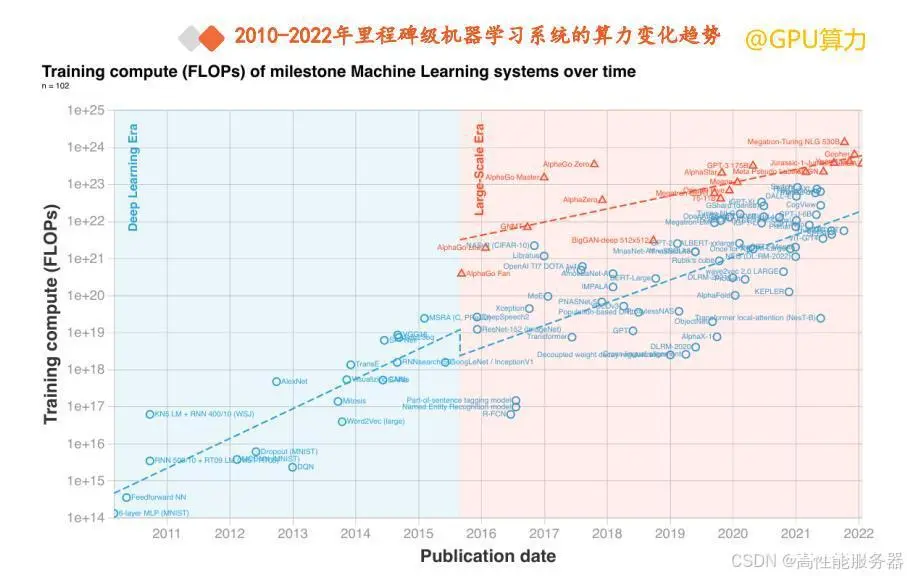
2.算力需求测算逻辑
1). Transformer模型的训练和推理过程都是通过多次迭代完成。一次训练迭代包含前向传播和反向传播两个步骤,而一次推理迭代相当于一个前向传播过程。前向传播是将数据输入模型并计算输出,反向传播则是计算模型的梯度并存储梯度,以进行模型参数的更新。
2).反向传播的计算量大约是前向传播的2倍。因此一次训练迭代(包含一次前向 + 一次反向)的计算量大约为一次推理迭代(包含一次前向)的3倍。
3).训练Transformer模型的理论计算量约为C≈6N*D,其中N为模型参数量大小,D为训练数据量大小;推理所需计算量约为2N*D。

3.算力需求测算——训练端
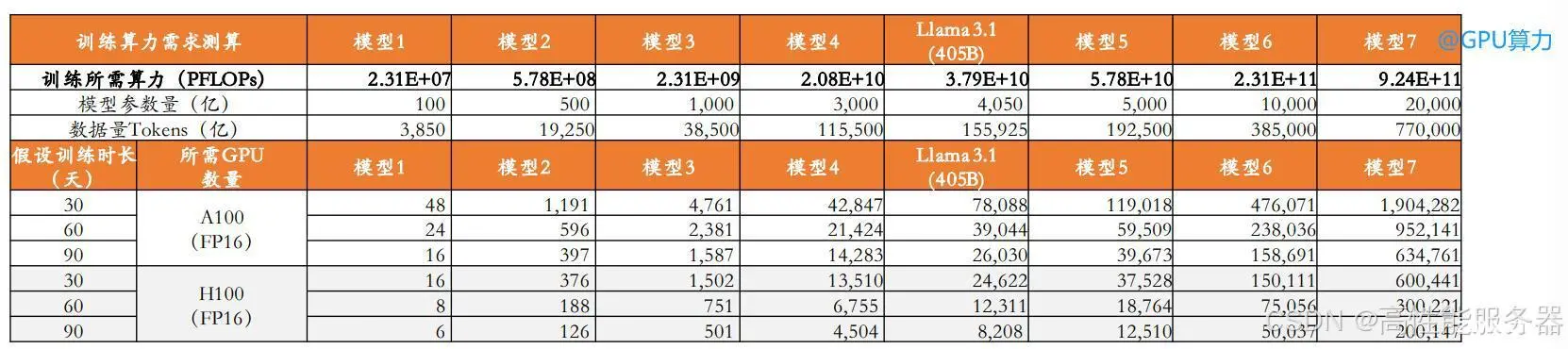
参考7月23日Meta公布的最新开源模型——Llama 3.1 405B,该模型基于15.6T tokens的数据量进行预训练以达到最优性能,训练数据量约为模型参数规模的38.5倍。假设最优大模型参数量(N)与Tokens数(D)的近似线性关系为D = 38.5*N,并设置了参数量分别为100亿、500亿、1000亿、3000亿、5000亿、1万亿、2万亿的共七档模型进行算力需求的测算。
根据前述公式计算得出训练一次Llama 3.1的计算量大致为3.79*10^25FLOPs,与实际情况接近(Llama 3.1 405B的training budget为3.8*10^25FLOPs)。A100 80G SXM、H100 SXM在16位精度下(FP16)的算力峰值分别为624TFLOPs、1979TFLOPs,假设集群算力利用率MFU为30%,模型训练时长分别为30天、60天、90天的背景下,则训练一次Llama 3.1 405B模型分别需要7.8万张、3.9万张、2.6万张A100,或者等同于分别需要2.5万张、1.2万张、8208张H100。
4.算力需求测算——推理端
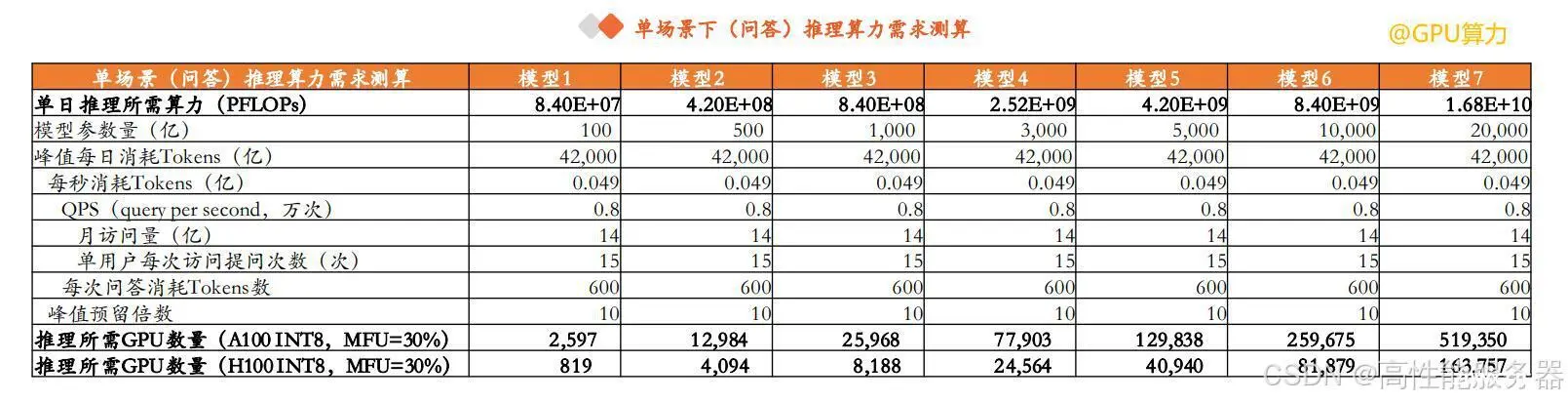
根据Similarweb的统计,ChatGPT网站在过去12个月平均月访问量为14.1亿次。假设在问答场景下,月访问量为14亿、单用户平均每次访问提问次数为15次,即模型每秒处理请求数8000次,假设单次问答消耗600Tokens,计算得出该场景下每秒消耗0.049亿Tokens。
考虑并发峰值和显存预留等问题,假设峰值预留倍数为10,得出每日峰值消耗4.2万亿Tokens。根据C≈2N*D,对应推理所需算力及所需GPU数量(假设采用INT8精度、MFU = 30%),千亿参数模型单问答场景推理大约需要2.6万张A100或者8188张H100。
5.大模型AI服务器成本测算
将前述训练(假设训练时长60天)和推理(单场景)两个阶段所需GPU数量加和,并统一假设1台服务器集成8张A100,计算得出千亿参数规模模型训练+推理大约需要3544台服务器,万亿参数规模模型需要6.2万台服务器。

五、大模型的进展与趋势

1.技术创新不断涌现
随着大模型技术的不断发展,新的架构和算法不断涌现。一些研究团队正在探索如何进一步提高Transformer模型的效率和性能,通过改进自注意力机制、引入新的训练方法等,以减少计算量和内存消耗。同时,多模态大模型的发展也备受关注,如何更好地融合文本、图像、音频等多种模态的信息,以实现更全面的理解和生成能力。
2.应用场景持续拓展
大模型在各个领域的应用场景不断拓展和深化。
在医疗领域,大模型可以用于疾病诊断、药物研发等方面,通过分析大量的医疗数据,提供更准确的诊断建议和个性化的治疗方案;
在教育领域,大模型可以为学生提供个性化的学习辅导,根据学生的学习情况和特点,定制合适的学习计划和内容;
在金融领域,大模型可以用于风险评估、市场预测等,帮助金融机构做出更明智的决策。
3.行业合作日益紧密
大模型的发展需要跨学科、跨领域的合作,包括学术界、产业界以及政府部门等。各方面力量加强合作共同推动大模型技术的发展和应用。例如,企业与高校、科研机构合作开展研究项目,共享数据和资源,加速技术创新的进程。政府出台相关政策,支持大模型的研发和应用。
4.伦理和社会问题受到关注
随着大模型的广泛应用,伦理和社会问题也日益受到关注。如大模型可能存在的偏见、隐私泄露等需要引起重视并加以解决。大模型的发展可能会对就业结构产生影响,需要提前做好应对措施。因此,制定相关的伦理准则和法律法规,引导大模型的健康发展是当前的重要任务之一。
大模型的发展正处于快速演进的阶段,其技术不断创新,市场竞争日益激烈,变现模式仍在探索和优化中,对算力的需求也持续增长。未来,大模型将在各个领域发挥更加关键的作用,需要密切关注其发展动态,积极应对其带来的机遇和挑战,以充分发挥其潜力,推动人工智能技术的发展和应用。
#大模型#LLM#算力#ChatGPT#Meta#MaaS#算力#高性能计算#GPU#GPT#国内大模型
上一篇: CVPR|《URetinex-Net: Retinex-based Deep Unfolding Network for Low-light Image Enhance》论文超详细解读(翻译+精读)
下一篇: AI训练语音(以游戏角色“白露”为示例)—>So-VITS-SVC 4.1—>新手使用教程
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。