【科普】【国产AI大模型与ChatGPT的差距到底有多大?】【转载】
旅之灵夫 2024-07-30 14:01:02 阅读 90
据不完全统计,截止今年10月,中国已经发布了238个大模型。IDC预测,2026年中国人工智能软件及应用市场规模将达到211亿美元,人工智能将进入大规模落地应用关键期。
有报告分析发现,中国自2020年进入大模型加速发展期,目前与美国保持同步增长态势。在自然语言处理、机器视觉和多模态等各技术分支上均在同步跟进、快速发展,涌现出盘古、悟道、文心一言、通义千问、星火认知等一批具有行业影响力的预训练大模型,形成了紧跟世界前沿的大模型技术群。
这些国产AI大模型的能力如何?如何测试一款大模型的能力?与ChatGPT的差距到底有多大?ChatGPT的优势在哪里?国产大模型能否实现超越?这是我的一些疑问,也是本文试图回答的问题。
评测榜单
虽然评测榜单本身的权威性还有待验证,但这也是一个观察判断的角度。
国际上用的较多的大模型评测集是MMLU。全称Massive Multitask Language Understanding,由UC Berkeley大学的研究人员在2020年9月推出。该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。被直接用于GPT-3.5、GPT-4和PaLM系列大模型的研发过程,国内科技大厂大多数情况也都基于这个框架进行评测。

中文自然语言理解测评基准SuperCLUE,成立于2019年,作为国内最早的评测社区,其专业性逐渐被大家所认可。不断推进中文语言模型测评体系、数据集、基准等基础工作,陆续推出CLUE、FewCLUE、ZeroCLUE等广为应用的语言模型测评基准。
SuperCLUE每月都会发布榜单,11月30日,SuperCLUE发布了中文大模型基准11月榜单。
SuperCLUE是中文通用大模型多层次的综合性测评基准,包括多轮开放问题测评SuperCLUE-OPEN和三大能力客观题测评SuperCLUE-OPT。主要考察模型在中文能力上的表现,包括专业知识技能、语言理解与生成、AI智能体和安全四大能力维度的上百个任务。


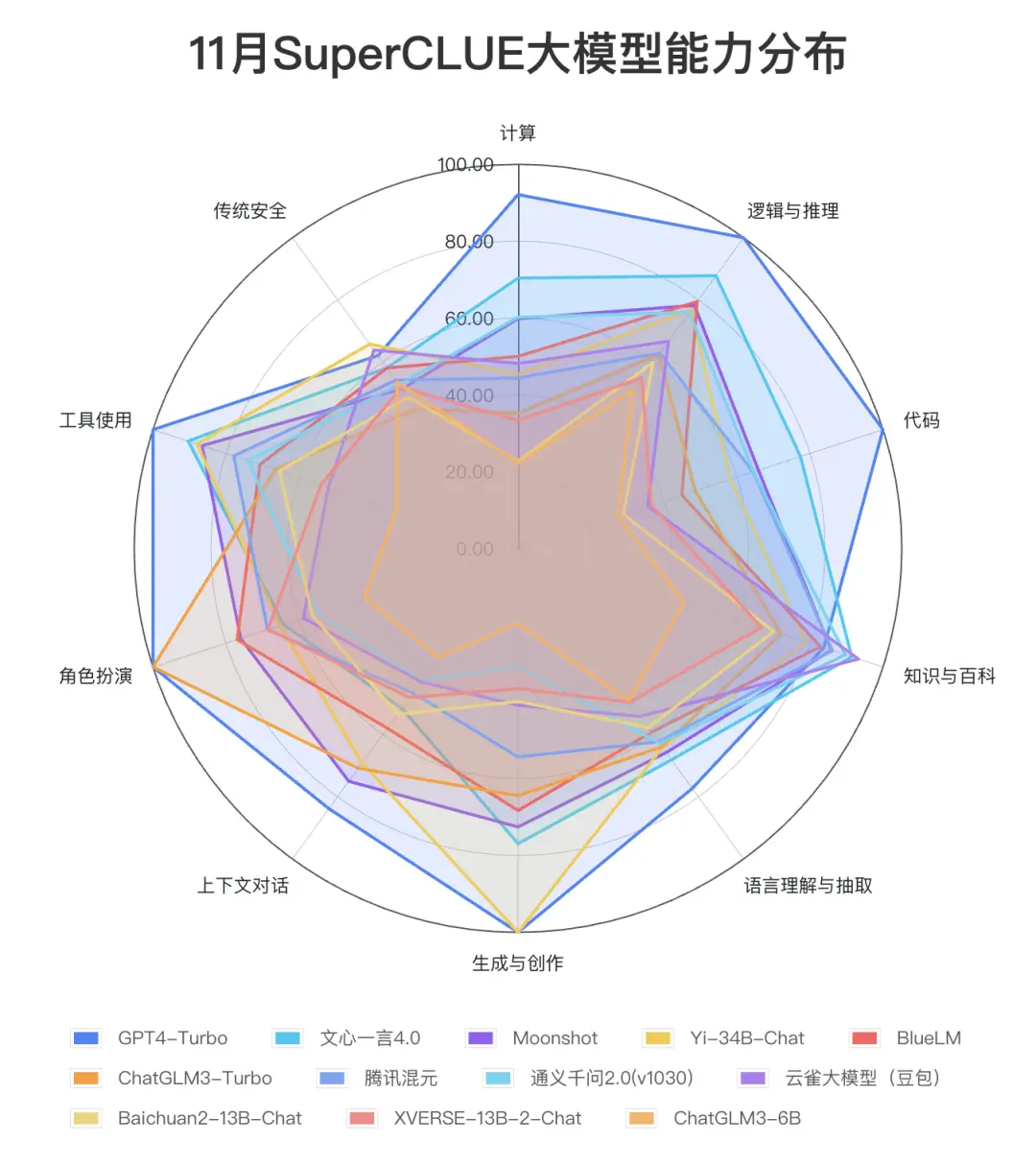

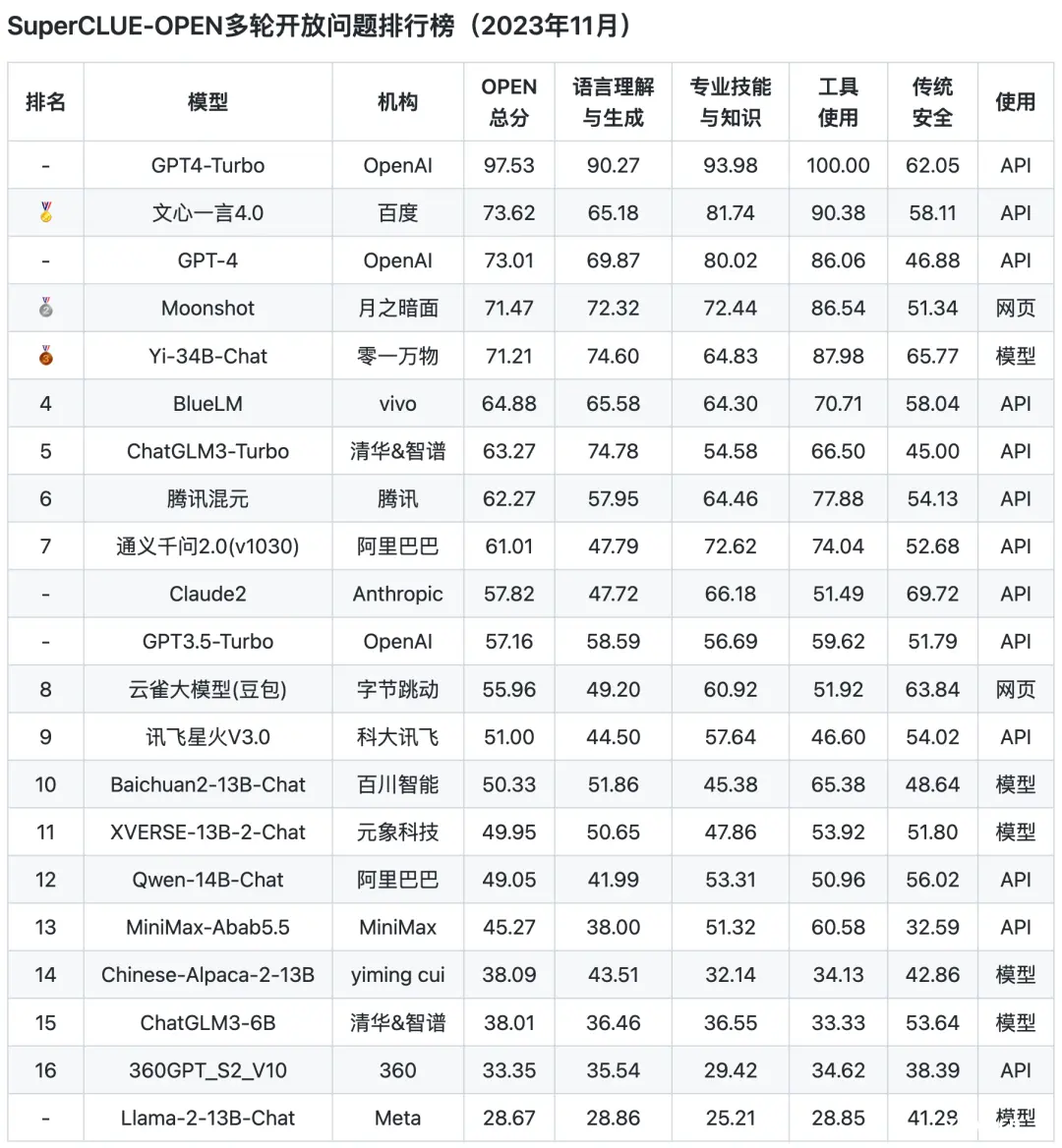

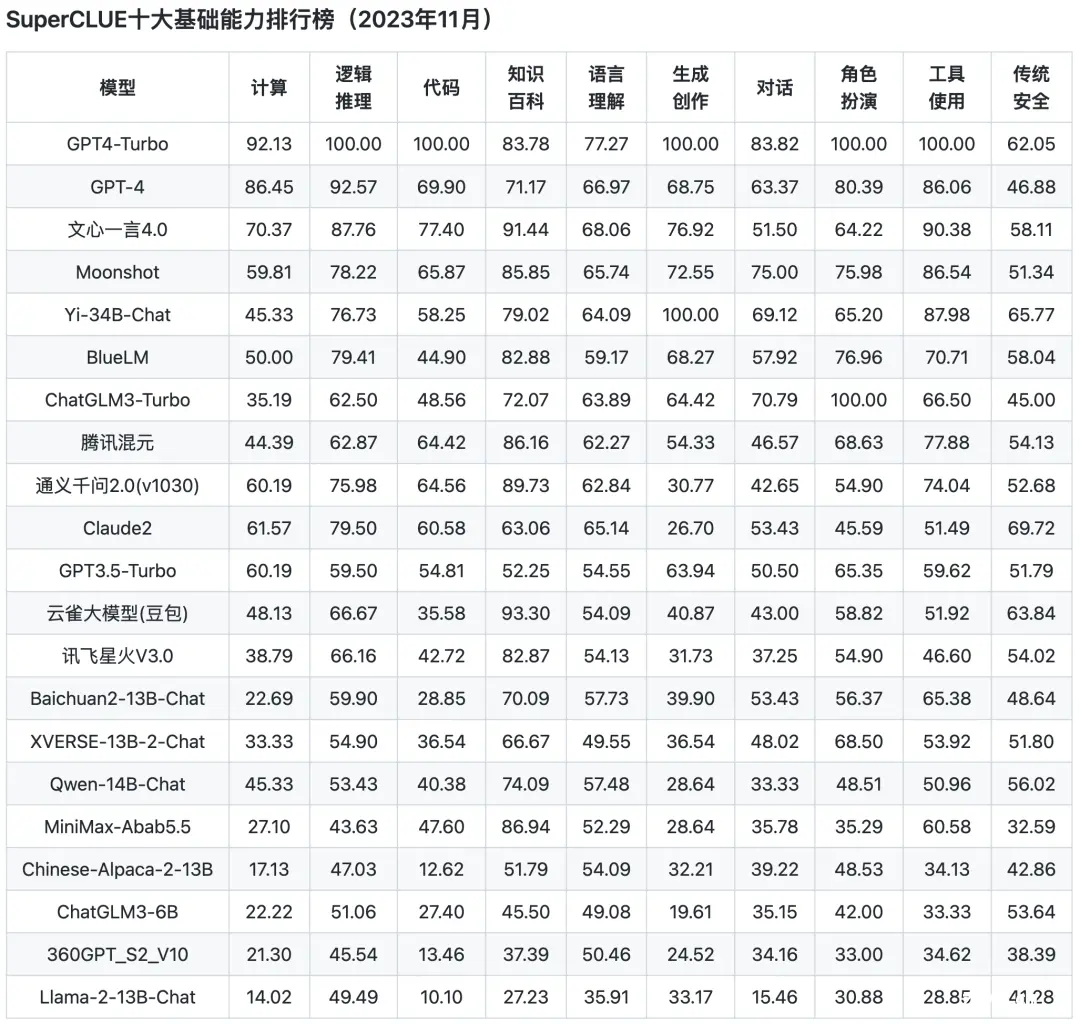
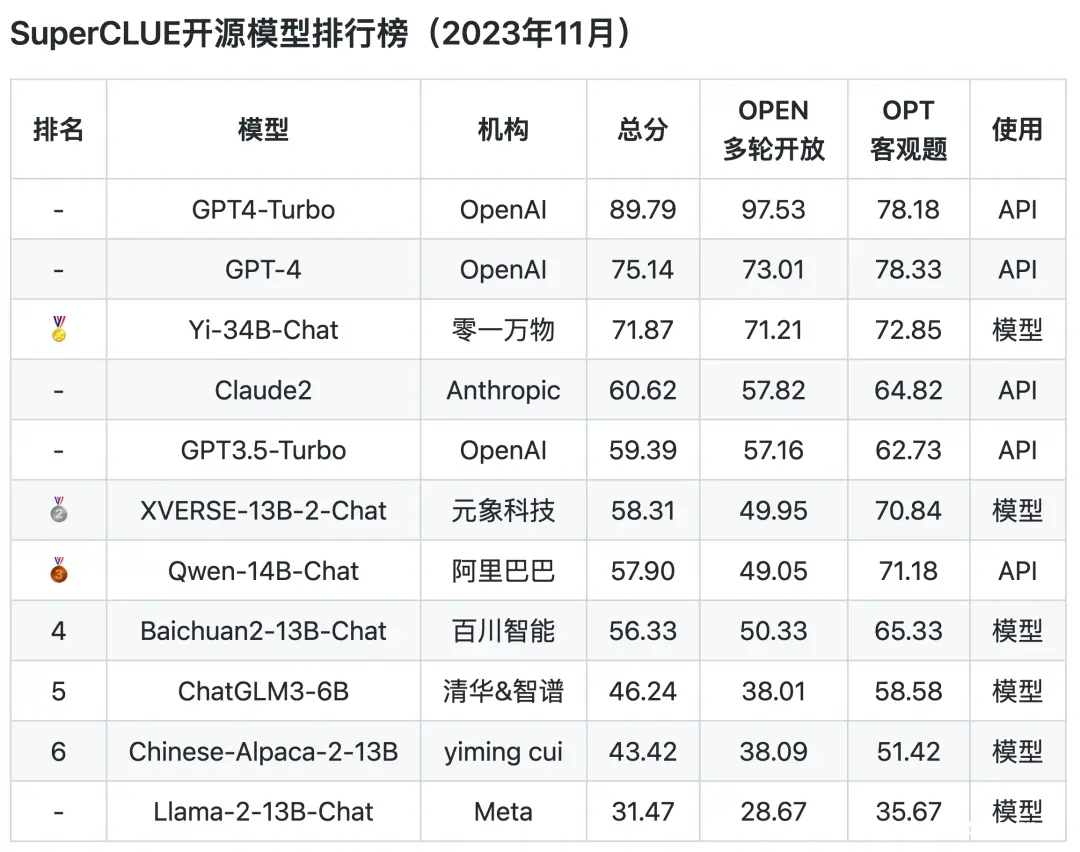
从榜单上的测评结果来看,GPT的综合能力和单项能力都表现非常出色,各榜单中都是遥遥领先。
国内的几个大模型的表现只能说是有待加强,与GPT的差距还是相当明显的,在AI大模型的竞赛中,国内模型的追赶步伐还得再快些,按360创始人周鸿祎话说,目前中国AI模型与GPT之间的差距在2到3年左右。
开源AI社区Hugging Face发布最受欢迎开源大模型机构TOP15榜单,在大名鼎鼎的Stability AI、Meta AI、Runway、OpenAI、谷歌、微软等海外机构外,只有一家机构来自中国:KEG实验室(全称为清华大学知识工程实验室,成立于1996年),其凭借今年开源的模型ChatGLM-6B上榜。
三驾马车
数据、算法、算力被称为人工智能的“三驾马车”。要训练一个新的ChatGPT,核心并不在算法有多先进,而是超量的数据、还有训练时用的算力。算力是指数据处理和计算的能力,它可以用每秒浮点运算次数(Flops)来衡量。
国内目前大模型主要是算力层面和国外差距比较大,这也是制约国内大模型发展的客观因素,没有算力基础,后面算法等发展都无法进行。
算力需求主要分为两部分,包括训练算力和推理算力。据ChatGPT的公开数据显示,它的整个训练算力消耗非常 大,达到了3640PF-days(即假如每秒计算一千万亿次,需要计算3640天),换算成英伟达A100芯片,它单卡算力相当于0.6P的算力,理想情况 下总共需要大概6000张,在考虑互联损失的情况下,需要一万张A100作为算力基础。
在A100芯片10万人民币/张的情况下,算力的硬件投资规 模达到10亿人民币。而整个的数据中心还需要推理算力以及服务器等,规模应该在100亿人民币以上。
根据2020年全球计算力指数评估报告,美国以75分位列国家计算力指数排名第一,知名企业包括Google、Facebook、Amazon、Microsoft、Apple等互联网巨头,中国获得66分位列第二。这两个国家在AI算力支出占总算力支出最高的两个国家,占比均超过10%。根据工业和信息化部的数据,截至2021年底,我国在用数据中心服务器规模1900万台,存储容量达到800EB(1EB=1024PB)。算力总规模超过140 EFlops(每秒浮点运算次数), 近五年年均增速超过30%, 算力规模排名全球第二 。
欧盟内部排名较高的有德国、英国、法国等,它们的计算力指数分别为54分、53分和51分,在全球排名第三、第四和第五。欧洲的SAP、ASML、ARM等软硬件企业也是比较出名的。
算力的发展是离不开算力芯片的。算力芯片的种类有很多,比如GPU、DPU、NPU等,它们各有不同的特点和优势。人工智能大模型所需的芯片需要更高的处理信息的精度和计算速度。在超级计算领域,双精度浮点计算能力FP64是高计算能力计算的硬指标。英伟达的H100、A100是目前唯一具备这些能力的芯片。

2022年10月,美国限制英伟达和AMD向国内出售高性能计算芯片,国内互联网大厂意识到风险,去找英伟达购买。但因为从下单到拿货的周期较长,国内互联网厂商的优先级较低,国内互联网大厂买到的A100以及H100芯片数量是比较有限的。
国内AI芯片已经批量生产的产品,大多都是A100的上一代。各公司正在研发的相关产品,如昆仑芯三代、思远590、燧思3.0 等,都是对标A100,但由于“实体清单”的限制以及研发水平的原因,都还没有推到市场。

目前国内,已经发布的大模型产品只有百度文心一言,占据了先机。但是从试用结果看,和ChatGPT、GPT4的相差还是很大。百度的算力、硬件、算法模型层面都没有做到ChatGPT的水平。在美国制裁的背景下,国产化替代方案需要积累,在很长一段时间内,芯片与算力会是国产大模型与ChatGPT之间一道巨大的鸿沟。
技术之外的烦恼
除了技术本身之外,经济、政治、文化、人才、价值观等也是影响中美AI发展的重要因素。
举几个例子:
2022年9月,美国芯片禁令变本加厉,限制英伟达与英特尔相中国出售高端芯片,壁仞、摩尔线程等被列入“实体清单”
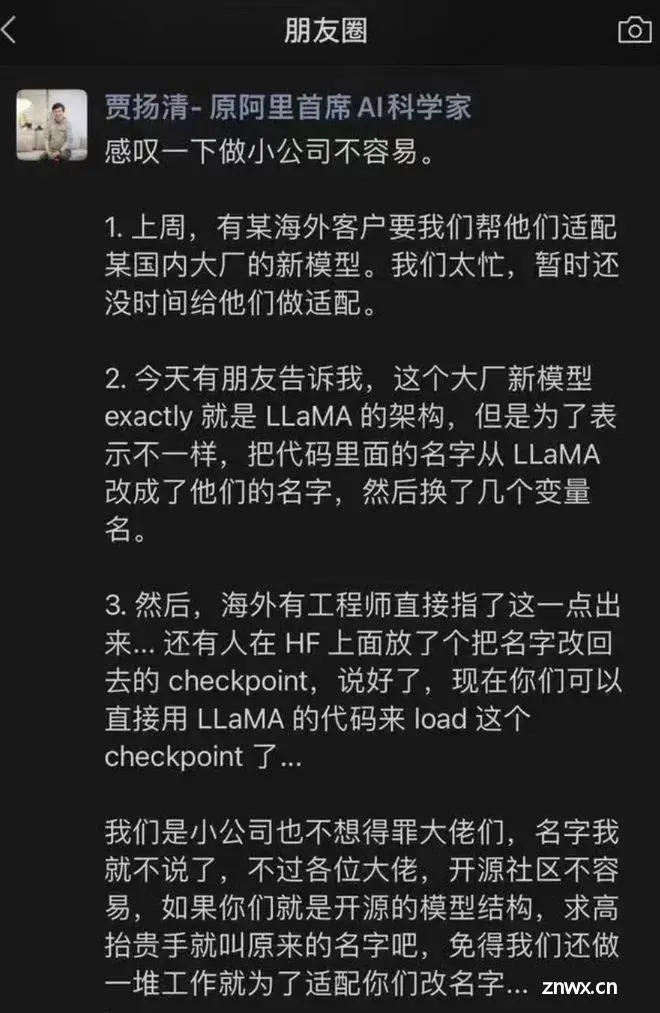
11月14日上午,一位国外开发者在Hugging Face开源主页上评论称,李开复旗下 AI 公司“零一万物”开源大模型Yi-34B,完全使用Meta研发的LIama开源模型架构,而只对两个张量(Tensor)名称进行修改。
11月15日,在深圳举行的西丽湖论坛上,李彦宏表示,自从8月31日开放以来,文心大模型的API调用量呈现了指数级的增长,“国内有200多个大模型,上了这个榜单、进了那个排名,但其实调用量是很小的。文心大模型一家的调用量比这200多家大模型的调用量加起来还要多。”
国外的AI圈也没闲着,Open AI开发者大会仅仅过去11天,一场惊爆了整个科技圈的“宫斗”大戏却悄悄上演了。
11月17日,ChatGPT之父山姆·奥特曼(Sam Altman)被突然宣布遭遇董事会罢免,即刻离开公司。紧接着,微软邀请奥特曼加入,OpenAI高层相机离职,OpenAI大约770名员工中的近500名(包括苏茨克维)签署联名信,称除非董事会辞职并重新任命奥特曼,否则他们可能会辞职。在经历一段时间的谈判后,OpenAI宣布山姆·奥特曼重返公司担任CEO。
最后的话
国内AI圈持续火热的一个问题是,为什么ChatGPT这样的产品没有诞生在中国,答案各一。
有网友这样说,其实从原理和方法看,他们所做的东西业界都是了解的,倒没有说什么是美国做得了、我们做不了的。”但像OpenAI和DeepMind,他们可能是业界唯二的两家机构,无论在创新性、投入、决心,还是在顶尖人才储备上,都是一如既往坚持的。我们看到的是成功,但里面可能已经有很多失败的尝试。
在看不到前景和没有明显效果的阶段,OpenAI非常坚定地做了投入,相反国内倾向于在技术出现突破后,快速追随。国内大家第一步想的是,我们现在怎么用起来,但在不能用的时候,人家就在长期投入。
其实这才是值得我们学习的,我们真的需要有足够多的钱,有这么一帮热血的人才,能够在一个方向上这样持续积累发力。
参考资料:
1、国内外AI芯片、算力、大模型综合对比(2023)-电子发烧友网
2、https://chat.lmsys.org/
3、MMLU: Better Benchmarking for LLM Language Understanding | Deepgram
4、大模型综合评测对比 | 当前主流大模型在各评测数据集上的表现总榜单 | 数据学习 (DataLearner)
5、MMLU Benchmark (Multi-task Language Understanding) | Papers With Code
6、Foundation Model Transparency Index
7、https://huggingface.co/models
原文链接:
国产AI大模型与ChatGPT的差距到底有多大?
下一篇: 两位软件工程师创业,开发出一款软件质量保证自主AI代理,融资总额超3000万美元
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。