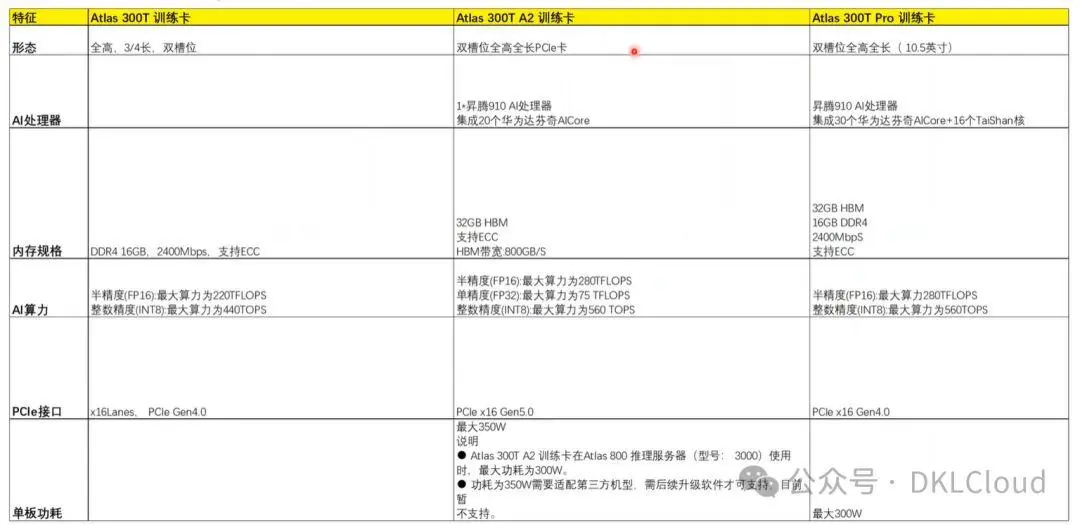
建设人工智能平台,主流GPU卡选型分析_随着技术的进化,nvlink每个版本都提升了带宽能力和链路数。作者:beijingtotokyo...
![解决方案:2024年Pytorch(GPU版本)+ torchvision手动安装教程[万能安装方法] win64、linux、macos、arm、aarch64均适用](/uploads/2024/07/12/1720771626490046184.webp)
对于深度学习新手和入门不久的同学来说,在安装PyTorch和torchvision时经常会遇到各种各样的问题。本文介绍一种手动离线安装Pytorch方法,不用再更改镜像,不用挂代理,。_安装torchvisio...
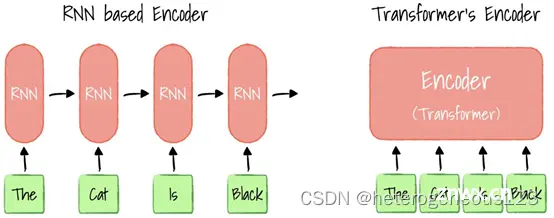
目前,GPGPU在深度学习领域有着成熟的软件生态,如CUDA、DTK等,这些工具和库极大地方便了研究人员和工程师进行模型的开发和优化。它通过self-attention机制,让模型在一次计算中考虑序列中所有词之间的...
YOLOv8项目推理从CPU到GPU;YOLOv8;从CPU到GPU。_yololv8使用gpu...
由于显卡的不同,需要先查看我们显卡及驱动最高支持的cuda。进入cmd输入版本支持向下兼容,为了保证能够和其他开发库版本兼容,这里使用的CUDN版本为11.6._cuda怎么使用...

NVIDIAH100GPU虽然没有提供双精度(FP64)和单精度(FP32)的特定TFLOPS值,但H100旨在显着提高计算吞吐量,这对于科学模拟和高性能计算应用中的数据分析至关重要。因此,...

NVIDIA®TensorRT™是一款用于高性能深度学习推理的SDK,包含深度学习推理优化器和运行时,可为推理应用程序提供低延迟和高吞吐量。YOLOv10是清华大学研究人员近期提出的一种实时目标检测方法...

paddle的GPU版本的正常使用方式_paddlepaddle-gpu识别结果为空...
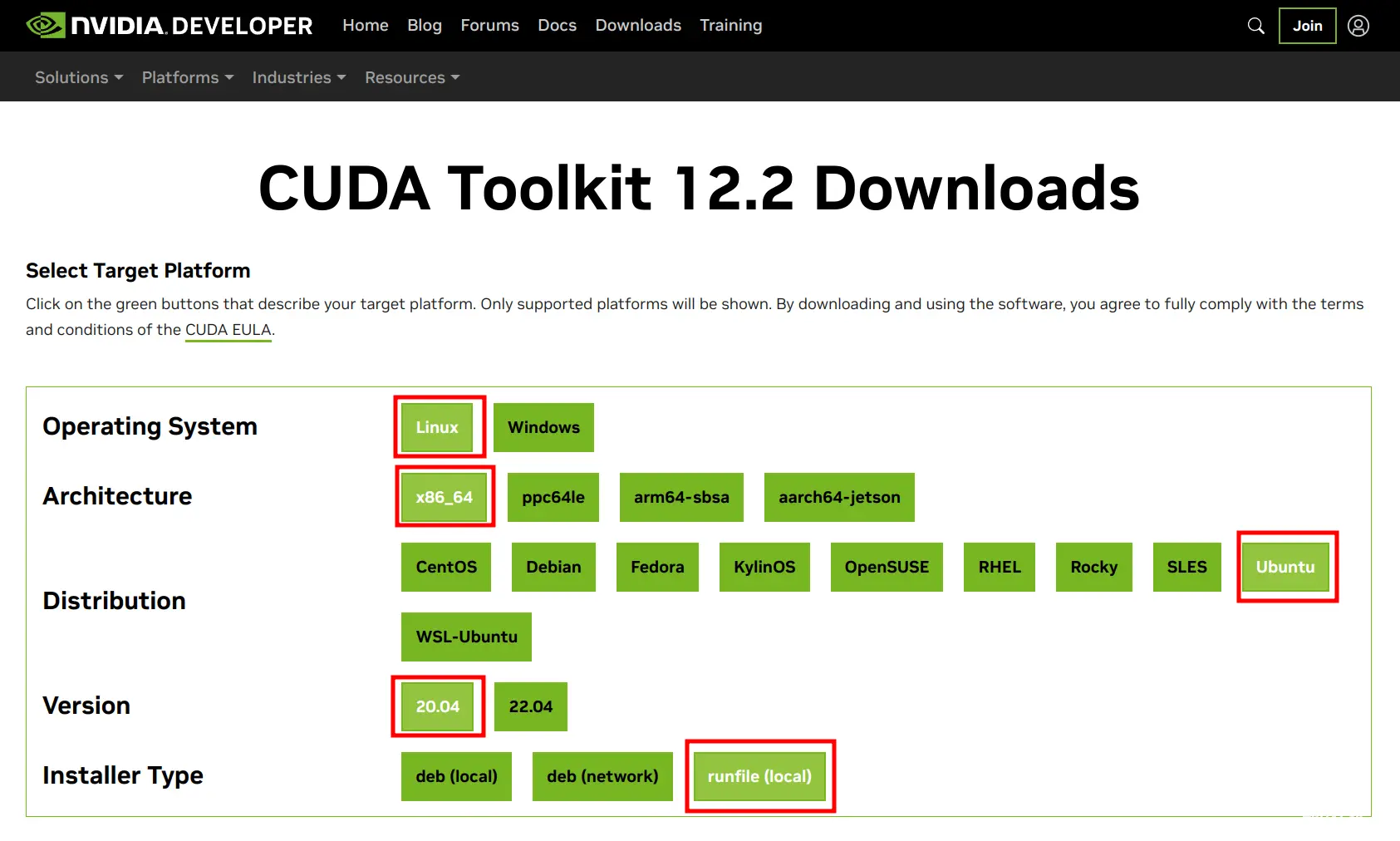
在Ubuntu20.04系统中,安装CUDA,cuDNN和Pytorch,配置深度学习开发环境_ubuntu20.04pytorch...
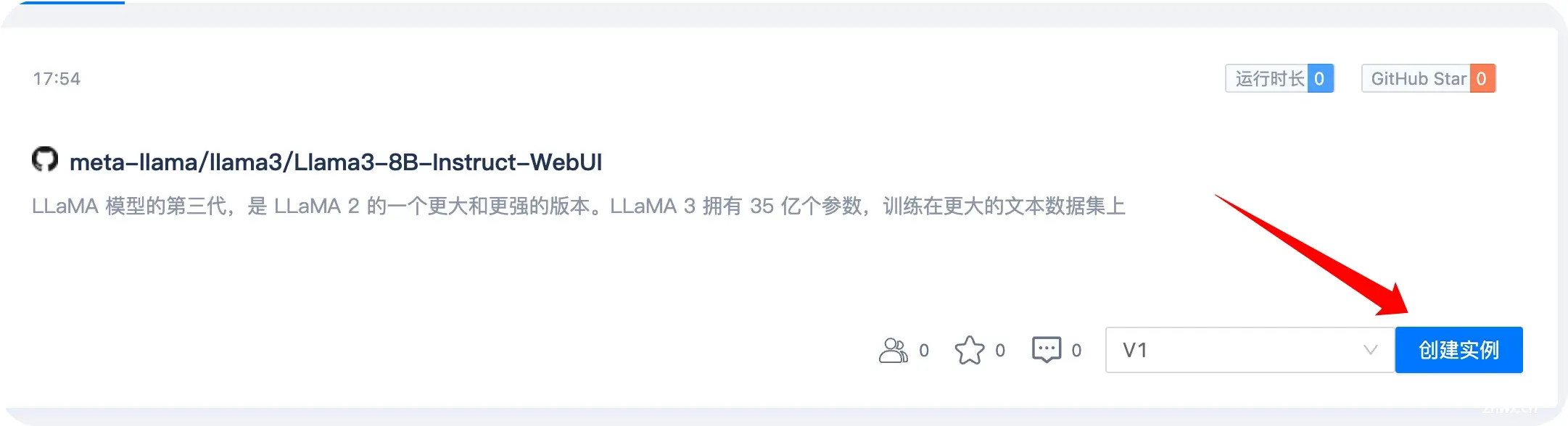
实例创建成功后,点击更多-创建自定义端口输入7860端口(该端口为实例中监听的端口)端口重置成功后点击自定义端口7860,然后跳转到Llama3模型的web控制台。_metallama38b...