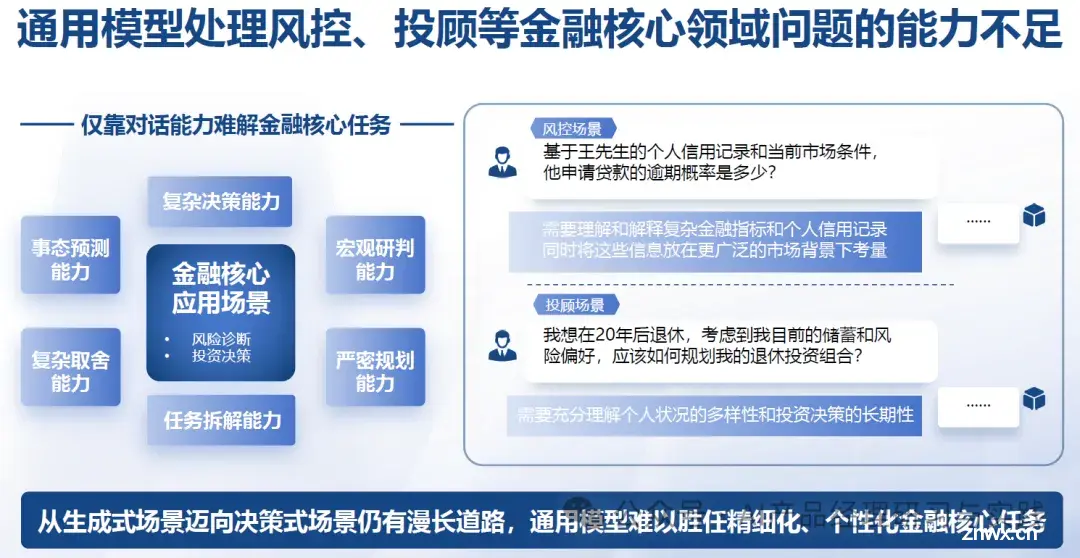
大模型私有化(ModelPrivateDeployment)指的是将预训练的大型人工智能模型(如GPT、BERT等)部署到企业自己的硬件环境或私有云平台上。与公有云服务或模型即服务(Model-as-a-Se...
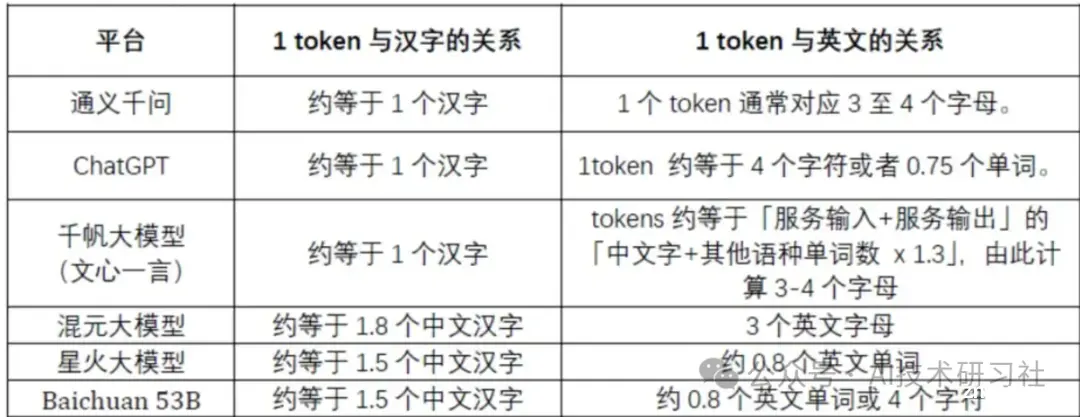
原创SoyogerAI技术研习社2024年07月14日09:00美国先说答案:不同模型可能采用各自的切分方法,因此,一个Token所对应的汉字数量也会有所不同。如腾讯1token≈1.8个汉字,通义...
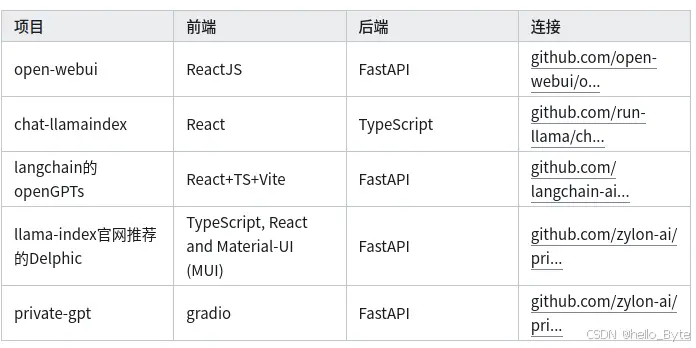
业余兴趣,部署下最近很火的LLM大模型玩玩,现在市面做这种大模型部署的快速应用还是挺多的,比如下面这些。这里介绍采用nvidiagpu,基于ubuntudocker环境下的open-webui+ollam...

在这里,给大家详细介绍下LangChain这个被提及很多次的开发框架,帮助更多的AI爱好者和开发者了解和学习。LangChain是一个开源的基于LLM的上层应用开发框架,LangChain提供了一...

就在上周末,国内大厂快手开源了**可图大模型**文生图模型,这是由快手可图团队开发的基于潜在扩散的大规模文本到图像生成模型。*•Kolors是在**数10亿图文对下进行训练**,*•在...

这个问题引发了一个常见的现象,即大模型(如讯飞星火、Kimi等)在涉及简单的加法运算时,结果经常不准确。_kimi加法不会算...

自从我开始搞大模型应用,就一直有一个头疼的问题困扰着我的团队,那就是避免敏感信息。传统的做法是通过一些匹配算法,过滤掉敏感词,这个后面我们再讲。但大模型的对话中,想要防止他做一些不合法的事情,就比较困难了。_大语言模...
![初识langchain[1]:Langchain实战教学,利用qwen2.1与GLM-4大模型构建智能解决方案[含Agent、tavily面向AI搜索]](/uploads/2024/10/12/1728720069038074048.webp)
初识langchain[1]:Langchain实战教学,利用qwen2.1与GLM-4大模型构建智能解决方案[含Agent]...

在人工智能的快速发展中,Prompt提示词工程作为一种新兴的技术手段,正在逐渐改变我们与大模型的互动方式。本文将深入探讨Prompt提示词的构成、编写原理及其在实际应用中的注意事项,帮助你更好地掌握这一重要...

AI大模型KIMI生成测试用例_kimi自建应用...