大模型应用中一个 Token 占多少汉字?答案超乎想象!
CSDN 2024-10-14 12:31:01 阅读 75
【科普】大模型应用中一个 Token 占多少汉字?答案超乎想象!
原创 Soyoger AI技术研习社 2024年07月14日 09:00 美国
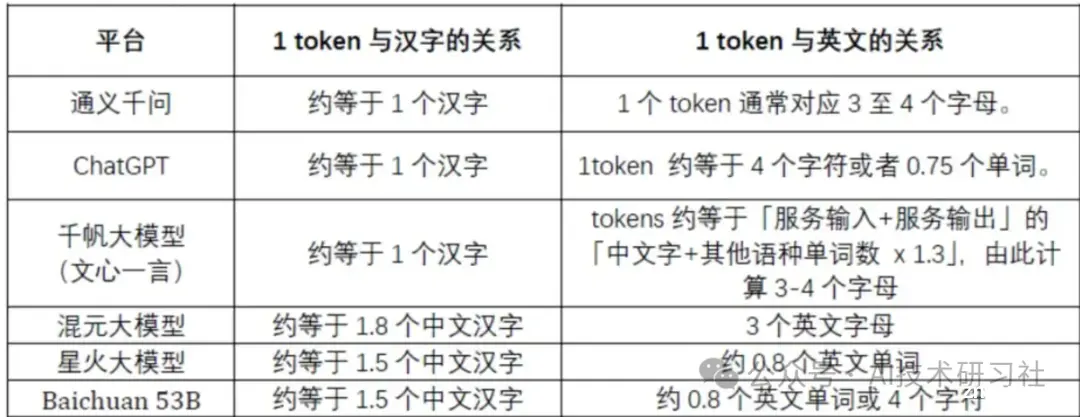
先说答案:不同模型可能采用各自的切分方法,因此,一个 Token 所对应的汉字数量也会有所不同。如腾讯1token≈1.8个汉字,通义千问、千帆大模型等1token=1个汉字,对于英文文本来说,1个token通常对应3至4个字母, 不同的模型对相同的输入分词, 分词结果是不一样的。
同样可以说,一个汉字占约0.5个Token。

Token 是大模型中最基础、最常见的概念,它既可以是一个完整的单词,也可以是一个单词的一部分,甚至是标点符号或空格。其翻译方式尚无定论,包括“标记”、“词”、“令牌”等多种说法。复旦大学计算机学院的邱锡鹏教授将其翻译为“词元”,我个人认为这种翻译比较恰当。

众所周知,大语言模型的训练语料数量、上下文的限制、生成速度等都以 Token 作为基本单位进行衡量。在训练过程中,Token 的数量直接影响模型的表现和泛化能力;在推理过程中,上下文中的 Token 数量会限制模型的记忆和理解范围;生成速度则通常通过每秒生成的 Token 数量来衡量。这些指标对于评估和优化大语言模型的性能至关重要。
以下是关于 Token 的一些详细信息:
定义与组成:
Token:在自然语言处理中,一个 Token 通常指一个有意义的文本片段。大模型在处理文本时,会将输入的句子拆分成一个个 Token。
词汇表(Vocabulary):模型预训练时使用的词汇表包含了所有可能的 Token。这个词汇表是有限的,但通常包含了数万到数十万个 Token。
Token化过程:
分词(Tokenization):将输入文本拆分成 Token 的过程称为分词。分词器根据预定义的词汇表和算法,将文本拆解成模型可以理解和处理的最小单元。
子词分词(Subword Tokenization):许多现代大模型使用子词分词技术,如BPE(Byte-Pair Encoding)或WordPiece,这些方法可以将未知的或不常见的单词拆分成更小的子词,从而更有效地处理语言中的多样性。
处理与生成:
输入处理:当模型接收到输入文本时,会将其转换成 Token 序列,然后再输入模型进行处理。
输出生成:模型生成文本时,会逐步预测下一个 Token,直到生成完所需的完整文本。
Token 的作用:
理解上下文:通过 Token 化,模型可以更好地理解和生成连贯的文本,因为它能够在单词级别甚至更细粒度的子词级别上进行处理。
处理复杂语言结构:Token 允许模型处理复杂的语言结构,包括复合词、多词表达式、缩写等。
举个简单的例子,假设输入文本是 “你好,世界!”,经过 Token 化后,可能会变成类似 ['你', '好', ',', '世', '界', '!'] 这样的序列。模型会在这个 Token 序列的基础上进行计算和生成新的 Token。
OpenAI官方文档中介绍:“1000个token通常代表750个英文单词或500个汉字。1 个token大约为 4 个字符或 0.75 个单词。”
OpenAI官方的token计算工具 : https://platform.openai.com/tokenizer
国内也有一些工具:
百度文心一言也提供了token计算器来在线计算文心大模型的字符转token数。网址:https://console.bce.baidu.com/support/#/tokenizer
阿里通义千问也有:https://dashscope.console.aliyun.com/tokenizer
所以,一个汉字所占的 Token 数量具体取决于分词器的设计。通常情况下,一个Token平均会占用约 1.5 至 2 个 汉字。这是因为分词器在处理文本时,会根据预定义的规则和算法,将文本拆分成模型可以理解的最小单元。不同的分词器在处理汉字时可能会有不同的策略,从而影响每个汉字对应的 Token 数量。
目前的各种tokenization技术,涉及到将文本分割成有意义的单元,以捕捉其语义和句法结构,如字级、子字级(例如,使用字节对编码或 WordPiece)或字符级。
根据特定语言和需求场景,每种技术都有自己的优势和权衡。比如Qwen-7B采用UTF-8字节级别的BPE tokenization方式,并依赖OpenAI开源的tiktoken软件包执行分词。
字节对编码(BPE):为AI模型构建子词词汇,用于合并出现频繁的字符/子字对。
子词级tokenization:为复杂语言和词汇划分单词。将单词拆分成更小的单元,这对于复杂的语言很重要。
单词级tokenization:用于语言处理的基本文本tokenization。每个单词都被用作一个不同的token,它很简单,但受到限制。
句子片段:用习得的子词片段分割文本,基于所学子单词片段的分段。
分词tokenization:采用不同合并方法的子词单元。
字节级tokenization:使用字节级token处理文本多样性,将每个字节视为令牌,这对于多语言任务非常重要。
混合tokenization:平衡精细细节和可解释性,结合词级和子词级tokenization。
对于普通用户很难理解Token这个概念, 这个概念是隐藏在模型内部的, 对于普通使用者来说,这种计价方式无疑是致命的, 所以对于大部分普通使用者,还是采用包月方式偏多, Token计价方式针对的是开发者,希望通过API方式进行调用,封装自己的应用。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。