【AI大模型应用开发】3. RAG初探 - 动手实现一个最简单的RAG应用
同学小张 2024-07-03 08:01:03 阅读 85
大家好,我是【同学小张】。持续学习,持续干货输出,关注我,跟我一起学AI大模型技能。
文章目录
0. 什么是RAG1. RAG基本流程2. 向量数据库的生成2.1 文档加载与分块2.2 创建向量数据库2.2.1 创建过程2.2.2 运行结果2.2.3 踩坑2.2.3.1 坑一:NoneType object is not iterable2.2.3.2 坑二:Number of embeddings 9 must match number of ids 10
3. Prompt模板4. 使用大模型得到答案4.1 封装OpenAI接口4.2 组装Prompt4.3 使用大模型得到答案
5. 总结5.1 封装RAG5.2 完整代码
6. 思考
0. 什么是RAG
大模型也不是万能的,也有局限性。
LLM 的知识不是实时的LLM 可能不知道你私有的领域/业务知识
RAG(Retrieval Augmented Generation)顾名思义:通过检索的方法来增强生成模型的能力。你可以把这个过程想象成开卷考试。让 LLM 先翻书,再回答问题。
1. RAG基本流程
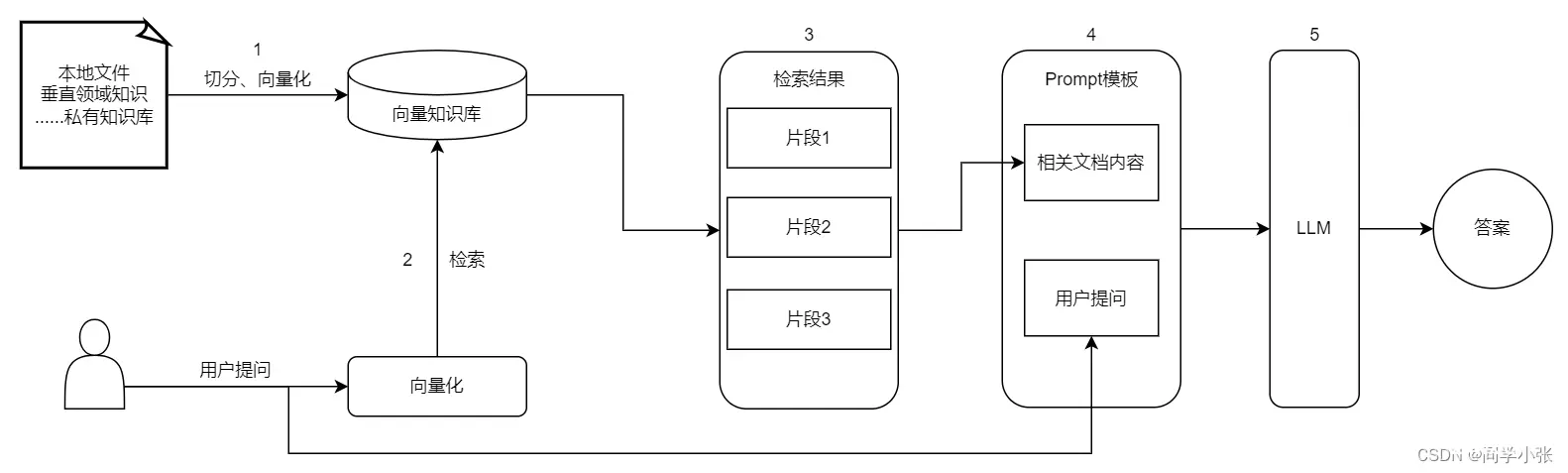
看图就很容易理解RAG的流程了:
(1)私有知识通过切分、向量化保存到向量数据库中,供后续使用
(2)用户提问时,将用户提问用同样的方式向量化,然后去向量数据库中检索
(3)检索出相似度最高的k个切分段落
(4)将检索结果和用户的提问放到Prompt模板中,组装成一个完整的Prompt
(5)组装好的Prompt给大模型,让大模型生成回答
理想状态下,大模型是完全依赖检索出的文档片段进行组织答案的
简化一下,可以看出RAG有两大过程:
加载文档,生成向量数据库查询向量数据库,询问大模型得到答案
下面我们一步步拆解,深入了解下RAG的流程和实现RAG所需的基本模块。
2. 向量数据库的生成
2.1 文档加载与分块
首先加载我们私有的知识库。这里以加载PDF文件为例。Python提供了加载PDF的一些库,这里用 pdfminer。
安装 pdfminer:
pip install pdfminer.six
先看代码:
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
class PDFFileLoader():
def __init__(self, file) -> None:
self.paragraphs = self.extract_text_from_pdf(file, page_numbers=[0,3])
i = 1
for para in self.paragraphs[:3]:
print(f"========= 第{ i}段 ==========")
print(para+"\n")
i += 1
def getParagraphs(self):
################################# 文档的加载与切割 ############################
def extract_text_from_pdf(self, filename, page_numbers=None):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 段落分割
lines = full_text.split('。\n')
for text in lines:
buffer = text.replace('\n', ' ')
if buffer:
paragraphs.append(buffer)
buffer = ''
row_count = 0
if buffer:
paragraphs.append(buffer)
return paragraphs
PDFFileLoader("D:\GitHub\LEARN_LLM\RAG\如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南.pdf")
代码解释
(1)我们首先定义了一个 PDFFileLoader 的类,接收一个PDF文件路径。然后类内部调用extract_text_from_pdf去解析PDF文件并分段。
(2)extract_text_from_pdf中前半部分代码是利用 extract_pages 按页提取出PDF文件中的文字,然后组装成 full_text 。
(3)extract_text_from_pdf中后半部分代码是将 full_text 进行段落划分。
说明:因为每个PDF提取出来的文字格式可能不同,有的每一行后面都带有"\n\n",有的不带有"\n\n",有的每一行中的单词都粘在一起…,各种各样,所以PDF文字划分和段落分割的算法都无法做到完美适应所有PDF。本文重点不再这,所以粗暴地根据"。\n"划分了段落。实际应用中这里你应该按照你的PDF文件去进行调试和分割,段落划分这几行代码不能直接用。
可以简单看下我为什么能如此粗暴的划分段落:通过extract_pages提取出来的文本如下:
'如何向 ChatGPT 提问以获得高质量答案:提示\n技巧工程完全指南\n\n介绍\n\n我很高兴欢迎您阅读我的最新书籍《The Art
of Asking ChatGPT for High-Quality Answers: A complete \n\nGuide to
Prompt Engineering
Techniques》。本书是一本全面指南,介绍了各种提示技术,用于从\n\nChatGPT中生成高质量的答案 。\n\n我们将探讨如何使用不同的提示工程技术来实现不同的目标。ChatGPT是一款最先进的语言模型,能够生成\n\n类似人类的文本。然而,理解如何正确地向ChatGPT提问以获得我们所需的高质量输出非常重要。而这正是\n本书的目的 。\n\n无论您是普通人、研究人员、开发人员,还是只是想在自己的领域中将ChatGPT作为个人助手的人,本书都\n是为您编写的。我使用简单易懂的语言,提供实用的解释,并在每个提示技术中提供了示例和提示公式。通\n\n过本书,您将学习如何使用提示工程技术来控制ChatGPT的输出,并生成符合您特定需求的文本 。\n\n在整本书中,我们还提供了如何结合不同的提示技术以实现更具体结果的示例。我希望您能像我写作时一\n\n样,享受阅读本书并从中获得知识 。\n\n
\n\n
与原文对比,大体上按"。\n"来分割能与实际段落比较接近,所以本例我就先这样干了。这实际是不能用于实际项目的:
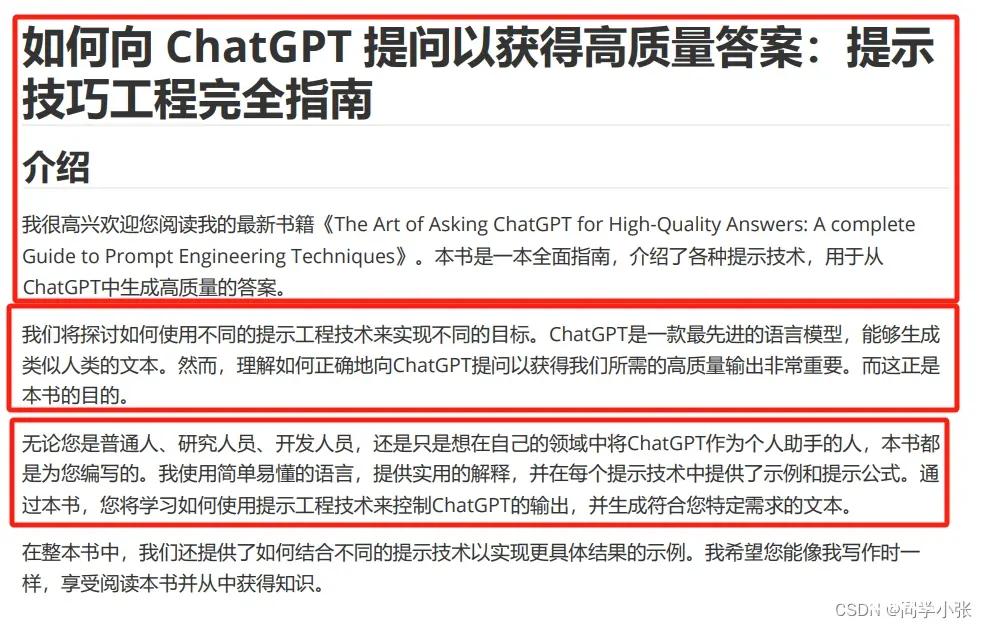
分割结果(打印前三段):
2.2 创建向量数据库
本文以 chromadb 向量数据库为例进行实操。
安装向量数据库chromadb
pip install chromadb
2.2.1 创建过程
(1)创建一个向量数据库类。该类add_documents函数用来添加数据,它需要三个参数:
文档的向量文档的原文文档的id
import chromadb
from chromadb.config import Settings
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 为了演示,实际不需要每次 reset()
chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{ i}" for i in range(len(documents))] # 每个文档的 id
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return results
(2)文档的向量怎么来?可以通过OpenAI的embeddings接口计算得到:
from openai import OpenAI
import os
# 加载环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI()
def get_embeddings(texts, model="text-embedding-3-small"):
'''封装 OpenAI 的 Embedding 模型接口'''
print(texts)
print(model)
data = client.embeddings.create(input=texts, model=model).data
print(data)
return [x.embedding for x in data]
(3)调用接口,创建向量数据库
# 创建一个向量数据库对象
vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档
vector_db.add_documents(pdf_loader.getParagraphs())
(4)测试查询
user_query = "什么是角色提示?"
results = vector_db.search(user_query, 3) # 3是指查询出最相近的3块文本
for para in results['documents'][0]:
print(para+"\n\n")
2.2.2 运行结果
(1)通过OpenAI的embeddings接口计算得到的文本向量

(2)查询结果,查找出最相近的3块文本
2.2.3 踩坑
2.2.3.1 坑一:NoneType object is not iterable
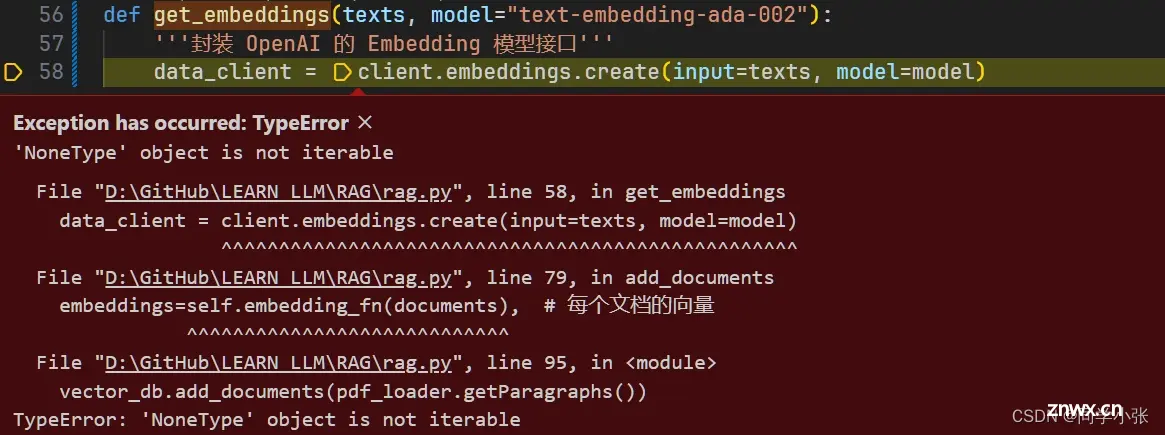
原因:传入的分块有空字符的情况。
不知道这种情况为什么会导致NoneType的错误,可能是OpenAI向量化时对特殊字符进行了去除?

解决方法:保证分块中没有全是特殊字符的分块即可。
2.2.3.2 坑二:Number of embeddings 9 must match number of ids 10
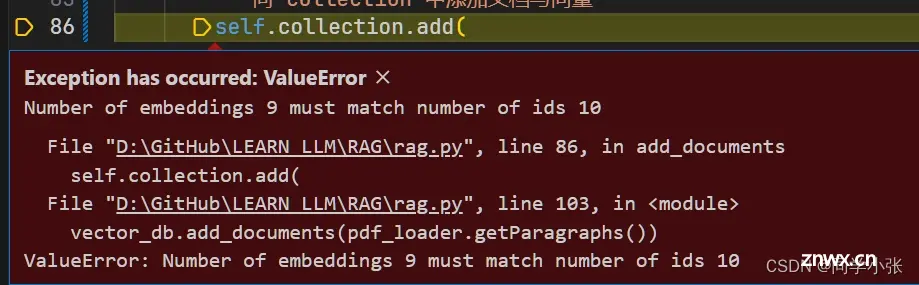
原因:可以看下下面的代码,上面的错误指的是embeddings是9个值,而ids有10个值。这是因为在解决坑一时,将里面最后那个空的文档分块去掉了,没去生成embeddings。
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{ i}" for i in range(len(documents))] # 每个文档的 id
)
解决方法:保证documents和embeddings的数组大小长度一致。
以上两个坑总体的解决方案代码,看下里面修改的部分(注释部分),在段落分割部分就把异常的分块去掉,从源头上保证documents的正常以及后面documents和embeddings数组大小一致:
# 段落分割
lines = full_text.split('。\n')
for text in lines:
buffer = text.strip(' ').replace('\n', ' ').replace('[', '').replace(']', '') ## 1. 去掉特殊字符
if len(buffer) < 10: ## 2. 过滤掉长度小于 10 的段落,这可能会导致一些信息丢失,慎重使用,实际生产中不能用
continue
if buffer:
paragraphs.append(buffer)
buffer = ''
row_count = 0
if buffer and len(buffer) > 10: ## 3. 过滤掉长度小于 10 的段落,这可能会导致一些信息丢失,慎重使用,实际生产中不能用
paragraphs.append(buffer)
return paragraphs
注意:文档分块不一定是按段落分。
3. Prompt模板
上面我们已经拿到了检索回来的相关文档。下面我们写一个Prompt模板用来组装这些文档以及用户的提问。
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
prompt = prompt_template
for k, v in kwargs.items():
if isinstance(v,str):
val = v
elif isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n'.join(v)
else:
val = str(v)
prompt = prompt.replace(f"__{ k.upper()}__",val)
return prompt
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
__INFO__
用户问:
__QUERY__
请用中文回答用户问题。
"""
注意以上最重要的提示词,要求大模型完全按照给定的文本回答问题:
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
4. 使用大模型得到答案
4.1 封装OpenAI接口
def get_completion(prompt, model="gpt-3.5-turbo-1106"):
'''封装 openai 接口'''
messages = [{ "role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
4.2 组装Prompt
prompt = build_prompt(prompt_template, info=results['documents'][0], query=user_query)
print(prompt)
运行结果

4.3 使用大模型得到答案
response = get_completion(prompt)
print(response)
运行结果

5. 总结
至此,我们已经实现了RAG的基本流程。总结下流程:
离线部分,可提前生成好
(1)文档加载与分块
(2)分块数据灌入向量数据库
在线部分
(3)解析用户提问,用户提问向量化
(4)查询向量数据库,得到最相似的k个文本块
(5)使用得到的k个文本块和用户提问组装Prompt模板
(6)询问大模型得到最终答案
5.1 封装RAG
我们将RAG流程封装一下,createVectorDB完成离线部分,创建出向量数据库和灌入数据。chat完成在线部分。
class RAG_Bot:
def __init__(self, n_results=2):
self.llm_api = get_completion
self.n_results = n_results
def createVectorDB(self, file):
print(file)
pdf_loader = PDFFileLoader(file)
# 创建一个向量数据库对象
self.vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档,灌入数据
self.vector_db.add_documents(pdf_loader.getParagraphs())
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query,self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(prompt_template, info=search_results['documents'][0], query=user_query)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
使用
rag_bot = RAG_Bot()
rag_bot.createVectorDB("D:\GitHub\LEARN_LLM\RAG\如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南.pdf")
response = rag_bot.chat("什么是角色提示?")
print("response=====================>")
print(response)
5.2 完整代码
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
class PDFFileLoader():
def __init__(self, file) -> None:
self.paragraphs = self.extract_text_from_pdf(file, page_numbers=[0,3])
i = 1
for para in self.paragraphs:
print(f"========= 第{ i}段 ==========")
print(para+"\n")
i += 1
def getParagraphs(self):
return self.paragraphs
################################# 文档的加载与切割 ############################
def extract_text_from_pdf(self, filename, page_numbers=None):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 段落分割
lines = full_text.split('。\n')
for text in lines:
buffer = text.strip(' ').replace('\n', ' ').replace('[', '').replace(']', '') ## 1. 去掉特殊字符
if len(buffer) < 10: ## 2. 过滤掉长度小于 10 的段落,这可能会导致一些信息丢失,慎重使用,实际生产中不能用
continue
if buffer:
paragraphs.append(buffer)
buffer = ''
row_count = 0
if buffer and len(buffer) > 10: ## 3. 过滤掉长度小于 10 的段落,这可能会导致一些信息丢失,慎重使用,实际生产中不能用
paragraphs.append(buffer)
return paragraphs
# pdf_loader = PDFFileLoader("D:\GitHub\LEARN_LLM\RAG\如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南.pdf")
from openai import OpenAI
import os
# 加载环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI()
def get_embeddings(texts, model="text-embedding-3-small"):
'''封装 OpenAI 的 Embedding 模型接口'''
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
import chromadb
from chromadb.config import Settings
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 为了演示,实际不需要每次 reset()
chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{ i}" for i in range(len(documents))] # 每个文档的 id
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return results
# # 创建一个向量数据库对象
# vector_db = MyVectorDBConnector("demo", get_embeddings)
# # 向向量数据库中添加文档
# vector_db.add_documents(pdf_loader.getParagraphs())
# user_query = "什么是角色提示?"
# results = vector_db.search(user_query, 3)
# for para in results['documents'][0]:
# print(para+"\n\n")
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
prompt = prompt_template
for k, v in kwargs.items():
if isinstance(v,str):
val = v
elif isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n'.join(v)
else:
val = str(v)
prompt = prompt.replace(f"__{ k.upper()}__",val)
return prompt
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
__INFO__
用户问:
__QUERY__
请用中文回答用户问题。
"""
########################### 大模型接口封装 #############################
def get_completion(prompt, model="gpt-3.5-turbo-1106"):
'''封装 openai 接口'''
messages = [{ "role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
# prompt = build_prompt(prompt_template, info=results['documents'][0], query=user_query)
# print(prompt)
# response = get_completion(prompt)
# print(response)
################################## 基于向量检索的 RAG ##################
class RAG_Bot:
def __init__(self, n_results=2):
self.llm_api = get_completion
self.n_results = n_results
def createVectorDB(self, file):
print(file)
pdf_loader = PDFFileLoader(file)
# 创建一个向量数据库对象
self.vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档,灌入数据
self.vector_db.add_documents(pdf_loader.getParagraphs())
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query,self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(prompt_template, info=search_results['documents'][0], query=user_query)
print("prompt===================>")
print(prompt)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
rag_bot = RAG_Bot()
rag_bot.createVectorDB("D:\GitHub\LEARN_LLM\RAG\如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南.pdf")
response = rag_bot.chat("什么是角色提示?")
print("response=====================>")
print(response)
6. 思考
RAG 是一个增强大模型垂直领域能力和减少幻觉的通用方法论,所以了解其原理和流程对实现出效果较好的大模型应用非常有用。
但是上面也可以看到,它也限制了大模型使用其自身的知识库去回答问题,只能够用给定的文本回复问题。这就导致这个RAG应用的通用性大大降低。
另外,从RAG流程中也可以看到要想实现的效果好,也是困难重重:
(1)预处理: 首先文本分割的块要恰到好处
文本分割的粒度太小,查找到的参考文本较少文本颗粒度太大,参考文本太多,消耗token,同时也会带入更多的干扰信息,导致大模型出现幻觉的概率增加
(2)有些问题的回答是需要依赖上下文的,怎样将上下文所在的文本块都找出来也不容易
(3)召回正确性:召回文档的相关性也对结果比较重要。查找出的文档虽然与用户提问的向量值比较相似,但某些时候,最相似的并不一定是与问题答案相关的
(4)大模型本身的能力对结果也比较重要
目前针对以上各个困难都有非常多的研究,还在快速发展阶段,未形成一套通用、效果好的方法论。
后面可以针对这部分进行深入探索和学习,关注和整理当下最新的RAG调优方法。敬请期待。
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
大家好,我是同学小张欢迎 点赞 + 关注 👏,促使我持续学习,持续干货输出。+v: jasper_8017 一起交流💬,一起进步💪。
上一篇: 《DNK210使用指南 -CanMV版 V1.0》第七章 基于CanMV的MicroPython语法开发环境搭建
下一篇: stable diffusion ControlNet使用介绍与进阶技巧
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。