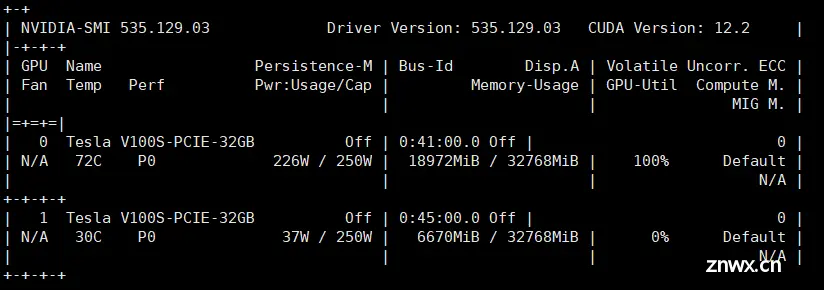
HuggingFace的库支持自动模型(AutoModel)的模型实例化方法,来自动载入并使用GPT、ChatGLM等模型。在方法中的device_map参数,可实现单机多卡推理。_transformer多卡推理...

在本文中,作者引入了MambaVision,这是首个专门为视觉应用设计的Mamba-Transformer混合骨架。作者提出了重新设计Mamba公式的方法,以增强全局上下文表示的学习能力,并进行了混合设计集成模式...

低光照图像增强(LLIE)是计算机视觉(CV)领域的一个重要且具有挑战性的任务。在低光照条件下捕获图像会显著降低其质量,导致细节和对比度的丧失。这种退化不仅会导致主观上不愉快的视觉体验,还会影响许多CV系统的性能。L...

本文对transformers之pipeline的零样本物体检测(zero-shot-object-detection)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以...

本文对transformers之pipeline的零样本图片分类(zero-shot-image-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介...
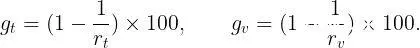
让我们简要回顾一下深度神经网络中BatchNorm的基本概念。这个想法最初是由Ioffe和Szegedy在一篇论文中引入的,作为加速卷积神经网络训练的一种方法。假设zᵃᵢ表示深度神经网络给定层的输入,其中a是从a=...
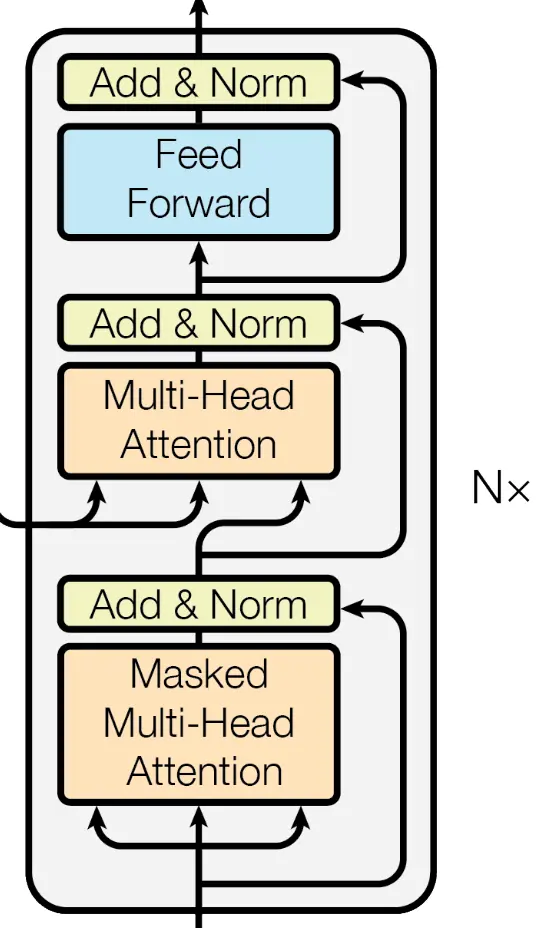
Transformer是一个经典的编码解码结构,编码器decoder负责编码,解码器encoder负责解码。Transformer是基于seq2seq的架构,提出时被用在机器翻译任务上,后面变种SwinTran...

本文介绍了Transformer模型推理性能优化技术KVCache,通过缓存Self-Attention和Cross-Attention中的键值对,减少重复计算,提升解码速度。在大模型如GPT中,KVCache能有效减少计算量,尤其...
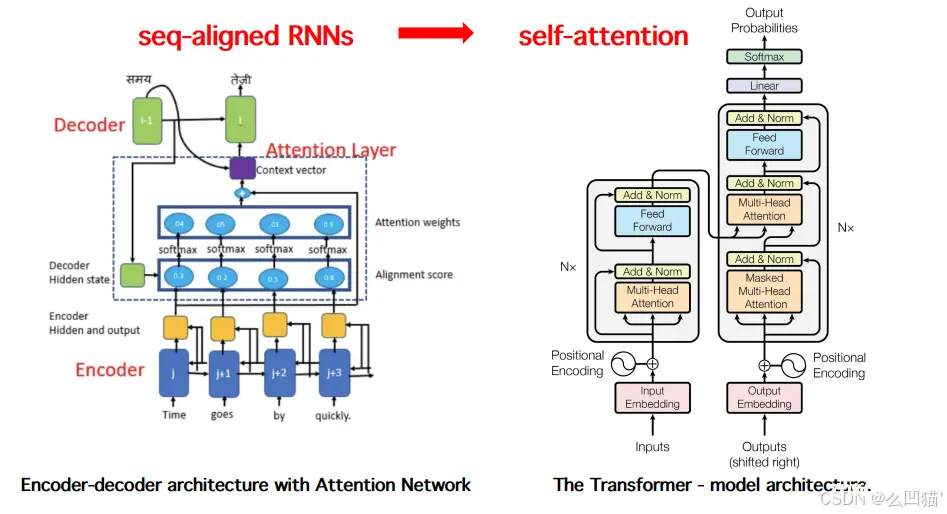
在AI技术的迅猛发展中,注意力机制成为了关键驱动力,赋予机器高效处理复杂信息的能力。本文深入探索注意力机制及其核心应用——Transformer架构,解析其如何通过自注意力机制革新自然语言处理。同时,对比分析GP...
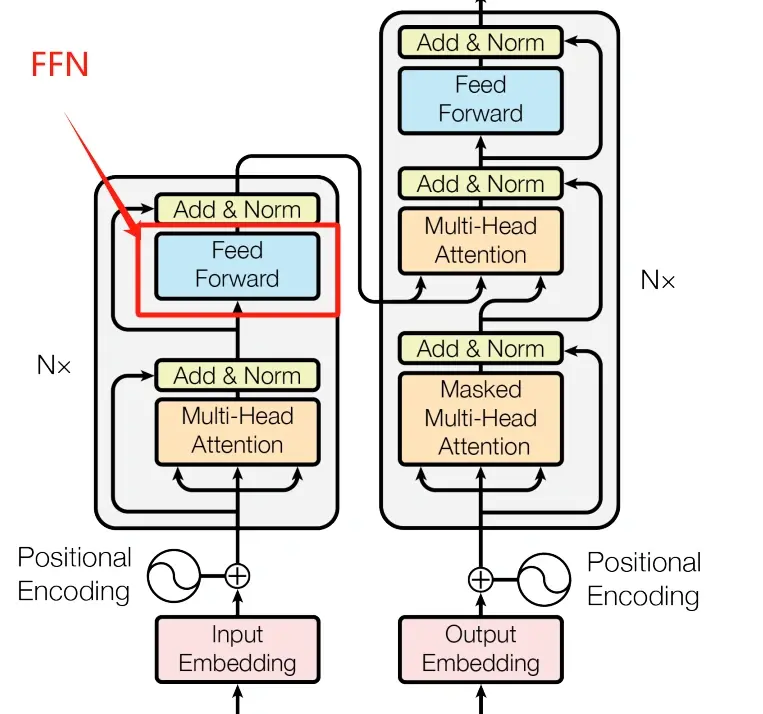
在经过前面3节关于Transformer论文的解读之后,相信你对提出Transformer架构的这篇论文有了一定的了解了,你可以点击下面的链接复习一下前3节的内容。总的来说,这篇论文虽然重要且经典,但很多...