在人工智能领域,自然语言处理(NLP)一直是研究的热点之一。随着深度学习技术的不断发展,大型预训练语言模型(如Qwen2-7B-Instruct)在理解与生成自然语言方面取得了显著的进展。然而,这些模型往往需...
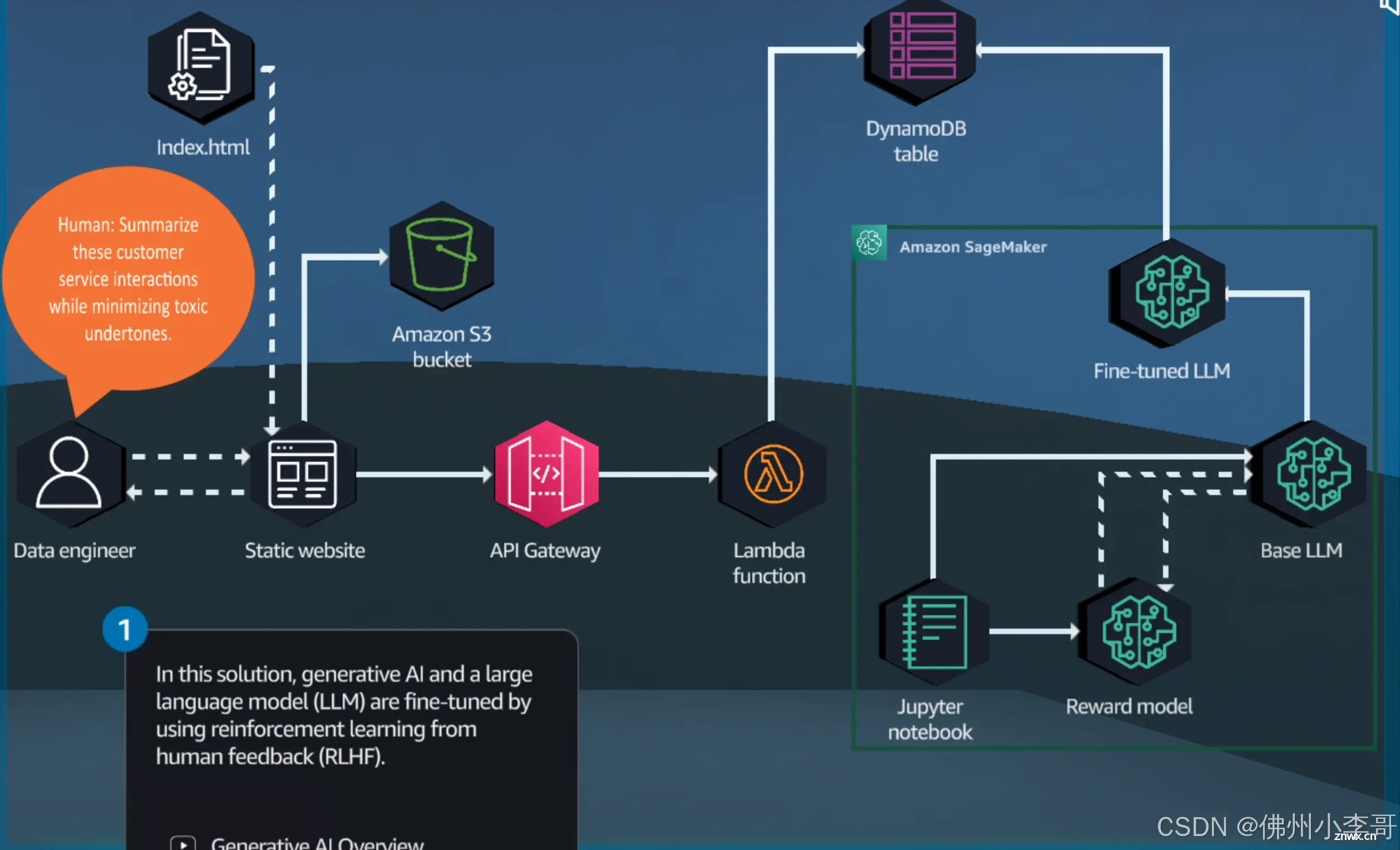
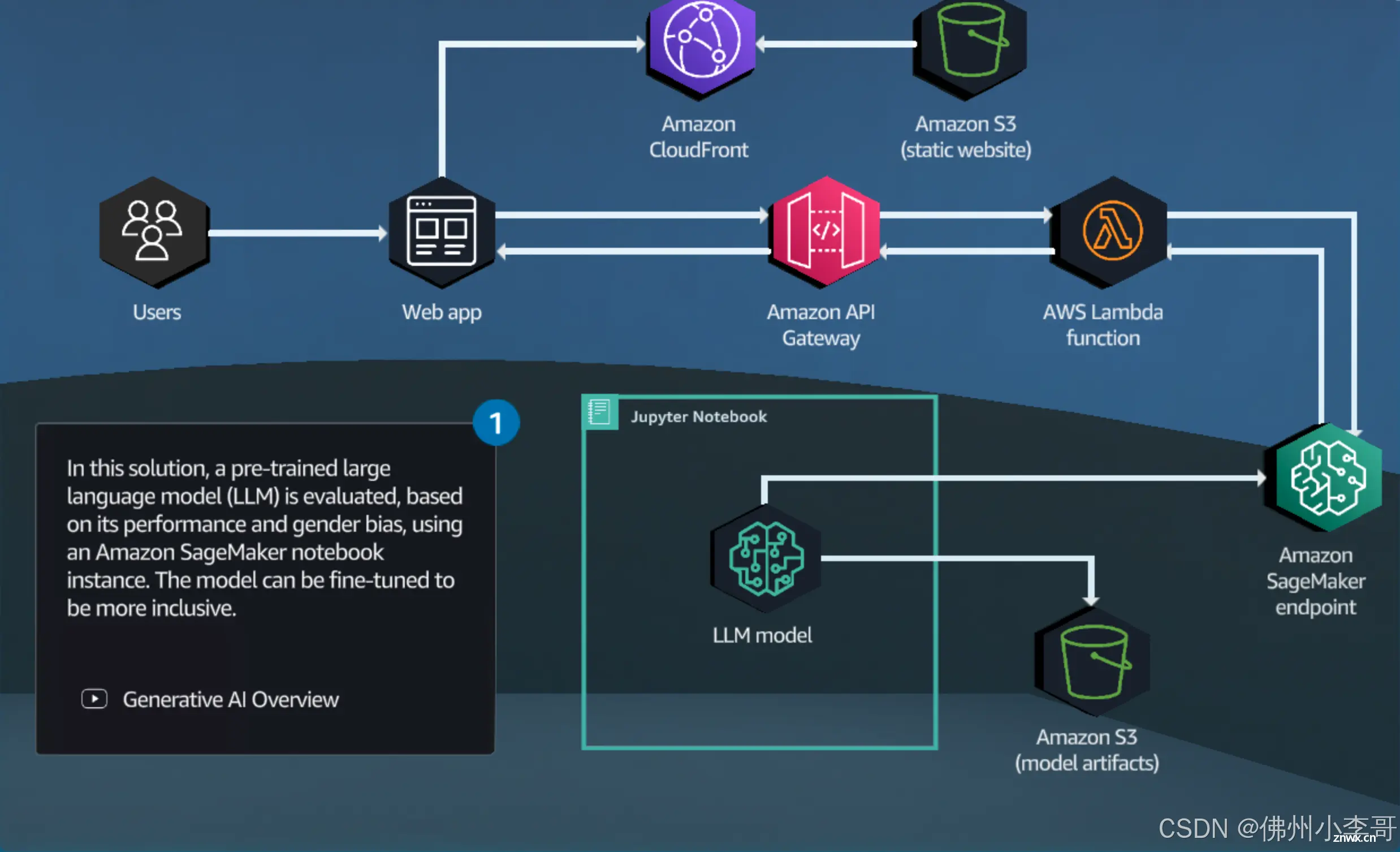
小李哥将继续每天介绍一个基于亚马逊云科技AWS云计算平台的全球前沿AI技术解决方案,帮助大家快速了解国际上最热门的云计算平台亚马逊云科技AWSAI最佳实践,并应用到自己的日常工作里。本次我将介绍如何用亚马逊云科技的...
Databricks的dolly-v2-3b是一种基于Databricks机器学习平台训练的指令跟随大型语言模型,可以用于商业用途,专为自然语言处理任务而设计。它能够理解和生成多种语言的文本,支持翻译、摘要...
在人工智能领域,大型预训练语言模型(LargeLanguageModels,LLMs)已经成为推动自然语言处理(NLP)任务发展的重要力量。Llama2作为其中的一个先进代表,通过其庞大的参数规模和深度学习...
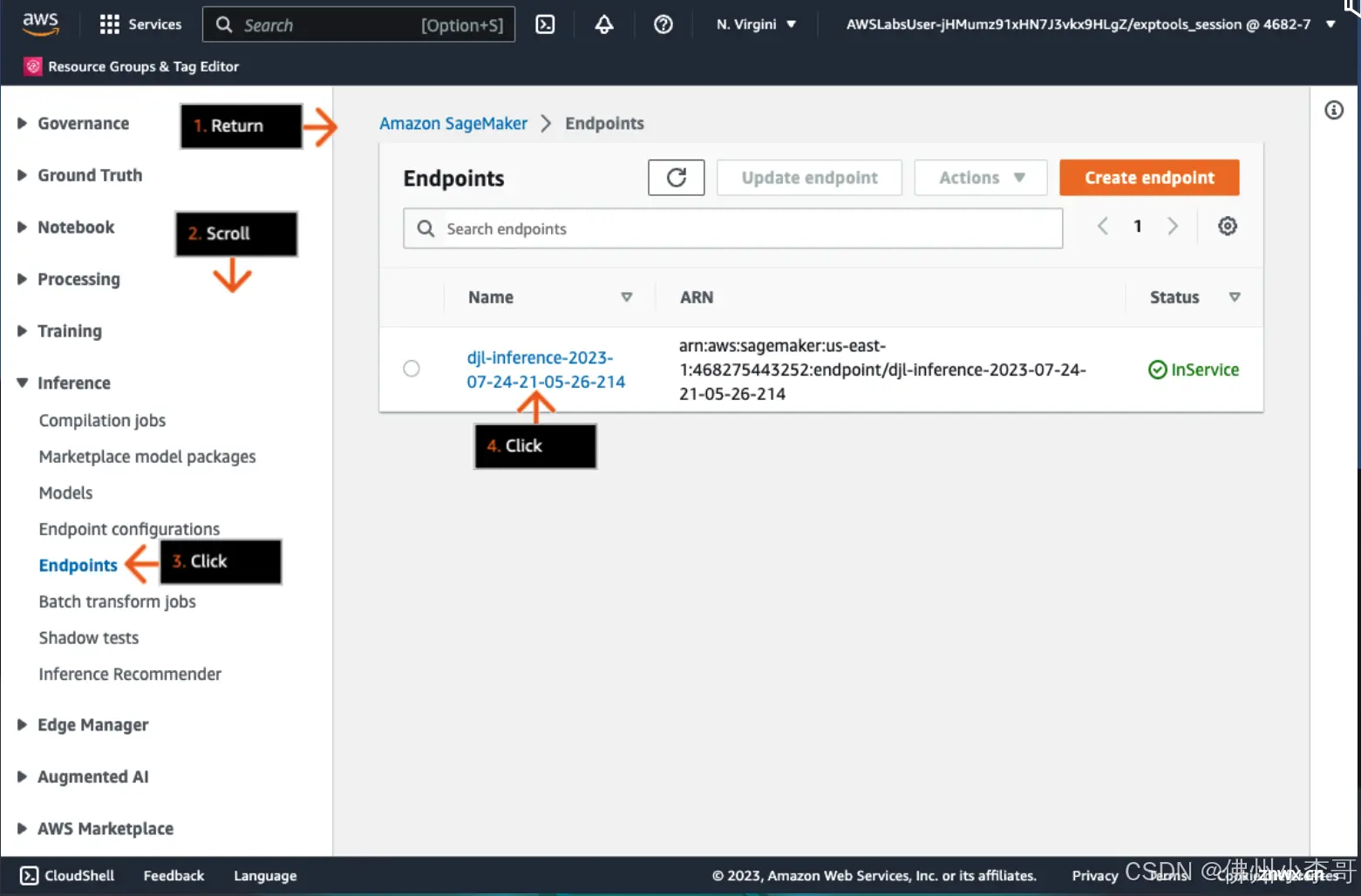
AmazonSageMaker是一个完全托管的机器学习服务(大家可以理解为Serverless的JupyterNotebook),专为应用开发和数据科学家设计,帮助他们快速构建、训练和部署机器学习模型。使用...

chatgpt说:模型微调(ModelFine-tuning)是指在已经训练好的模型基础上,针对特定任务或数据集进行调整,以获得更好的性能。通常情况下,模型微调是在预训练模型的基础上完成的,它可以提高模型在新任务...

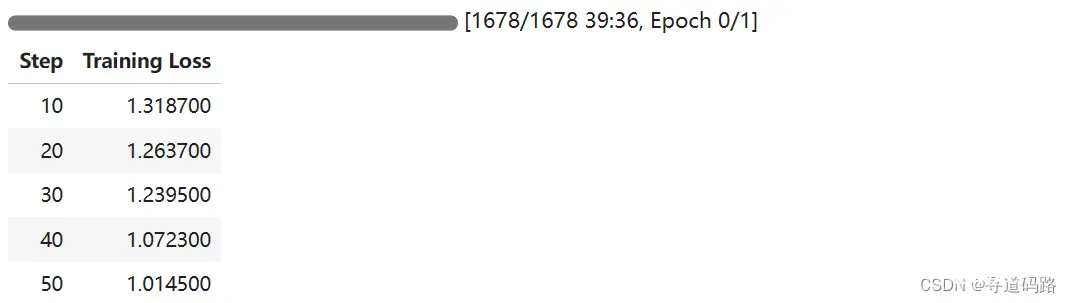
本教程详细介绍了LoRA参数高效微调技术,包括数据集准备和处理、模型加载、参数设置等,然后以Qwen2-0.5B预训练模型实践,进行了文本分类能力微调,微调过程通过SwanLab可视化界面查看,最终微调模型进行测试数据评估……...

选择预训练模型:选择一个在类似任务上已经训练好的模型作为起点。数据准备:准备并预处理你的数据集,使其适合模型的输入格式。微调:在你的特定数据集上继续训练模型,调整模型的权重。评估:评估微调后模型的性能。应用:将微...
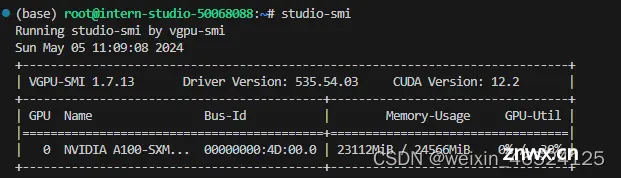
本文详细介绍了如何在不同的环境中部署Llama3WebDemo,包括配置VSCode、创建虚拟环境、安装所需库,以及进行XTuner微调、模型量化和LMDeploy部署。重点展示了如何优化内存使用和模型部署流程。...
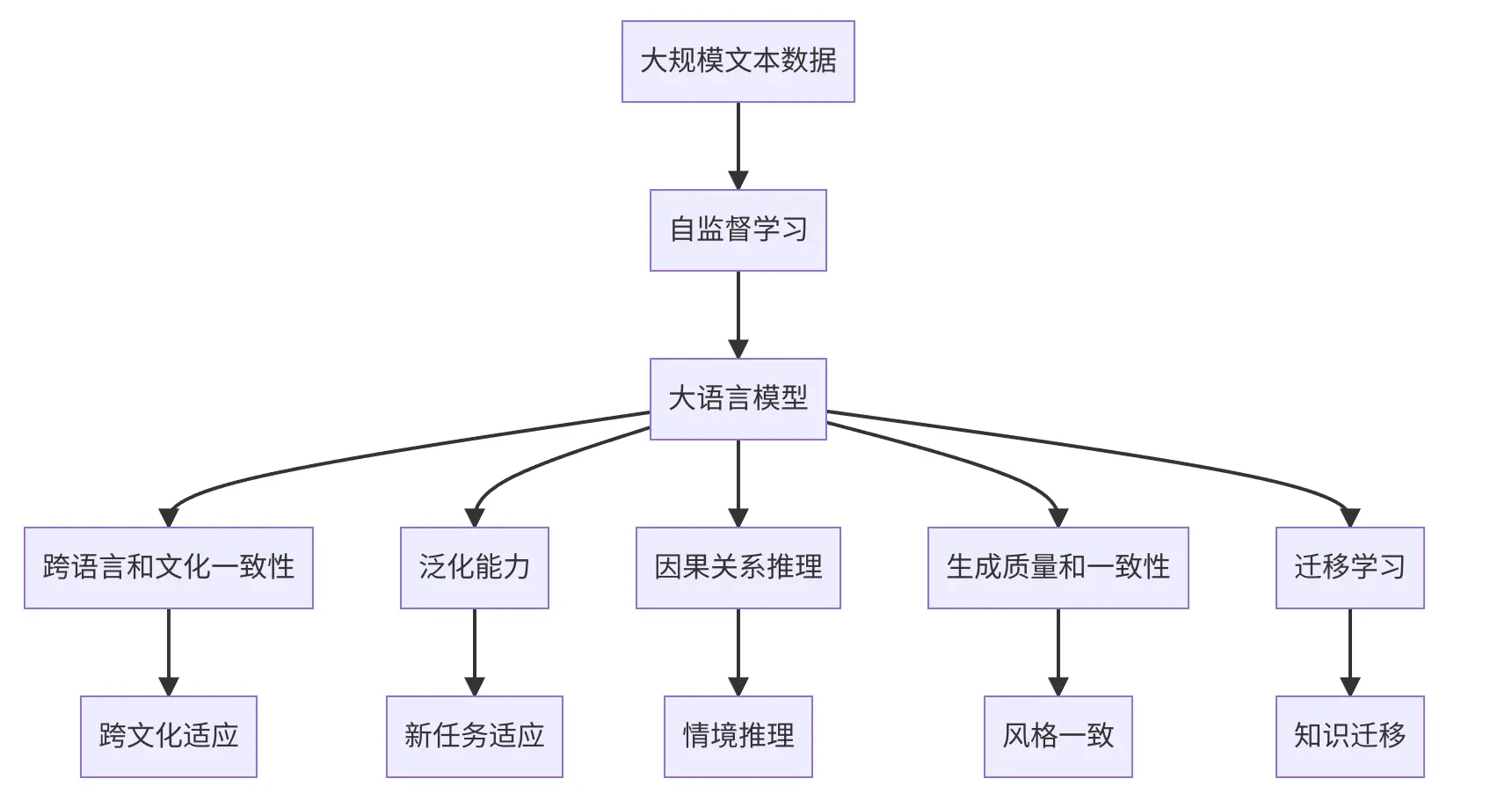
在人工智能领域,大语言模型(LargeLanguageModels,LLMs)已经取得了令人瞩目的成就。这些模型基于深度学习,通过在大量文本数据上预训练学习语言知识,被广泛应用于各种自然语言处理(NLP)任务,...