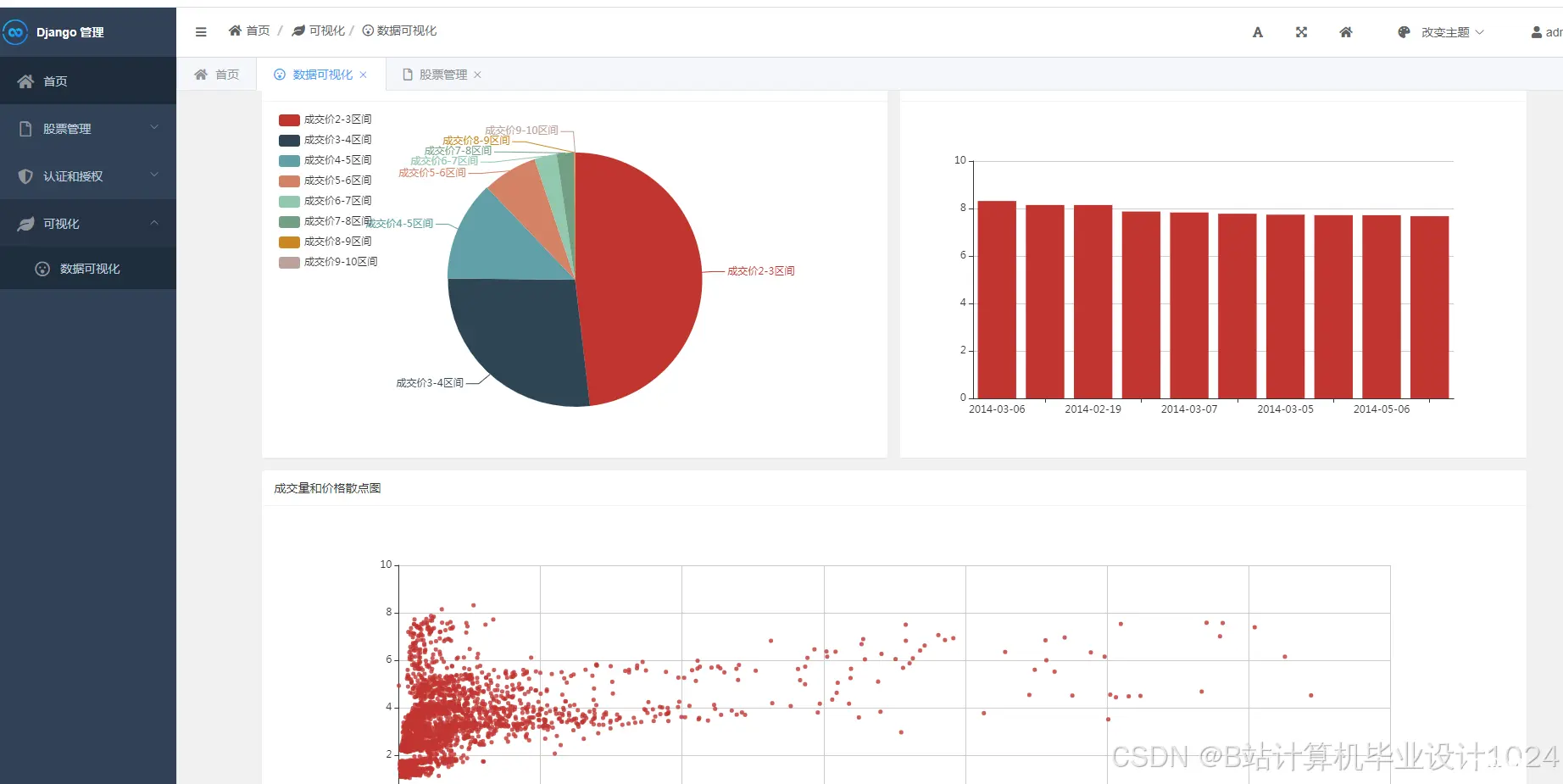
计算机毕业设计Python+Tensorflow股票推荐系统股票预测系统股票可视化股票数据分析量化交易系统股票爬虫股票K线图大数据毕业设计AI_python+tensorflow股票推荐系统...
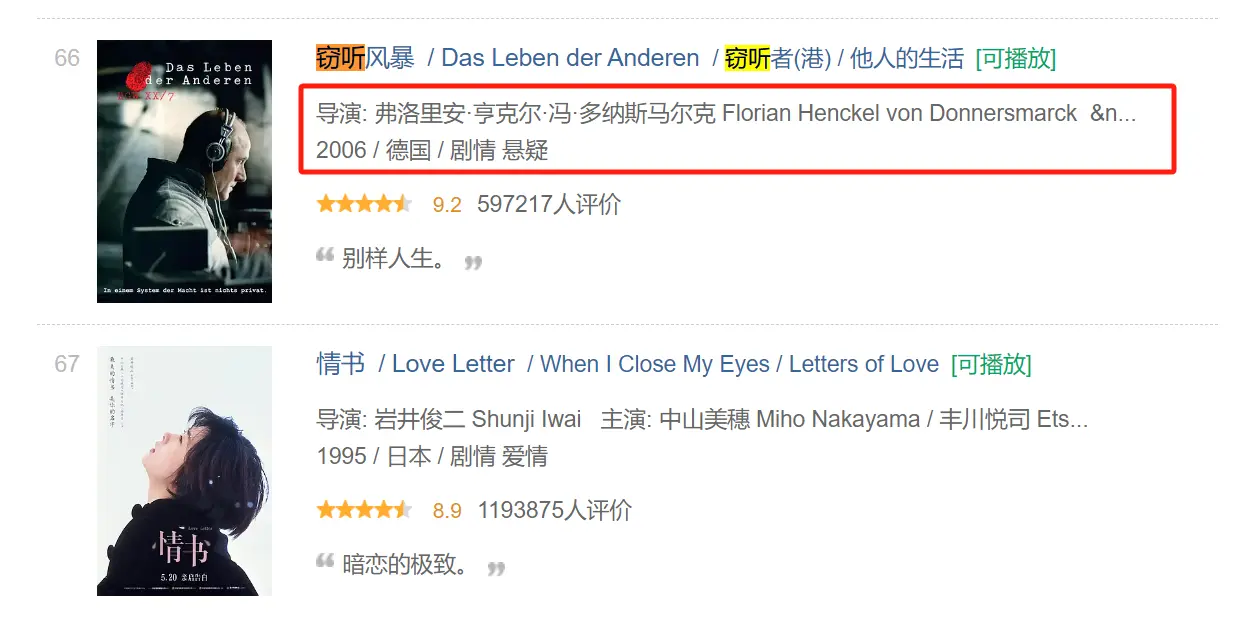
【python爬虫案例】利用python爬取豆瓣电影TOP250评分排行数据,并导出为excel文档...

黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育和辅导。所有项目都配有从入门到精通的基础知识视频课程,学习后应对毕...

爬虫全网抓取是指利用网络爬虫技术,通过自动化的方式遍历互联网上各个网站、论坛、博客等,从这些网页中提取所需的数据。:使用正则表达式、BeautifulSoup、Scrapy等工具对HTML文档进行解析,抽取需要的信息,...
短视频内容理解与推荐系统是针对短视频平台上海量视频内容进行理解、分类、推荐和个性化服务的一种智能化系统。在当今数字娱乐时代,短视频已成为人们日常生活中不可或缺的一部分,而短视频内容理解与推荐系统的研究和应用对于优...

@目录前言selenium简介实战案例共勉博客前言继使用requests库爬取好看视频的文章后,本文分享使用python第三方库selenium库接着来爬取视频网站,后续也会接着分享使用第三方库DrissionPage爬取视频。selenium简介se...

Python爬虫爬取京东商品信息。\t\t作用:导入所有必要的库和模块。:用于自动化浏览器操作。,:用于添加延迟和生成随机数。:用于读写CSV文件。:用于文件系统操作。:用于发送HTTP请求(例如下...
注意:由于user-agent和cookie中保存了部分账户信息,所以一定不要随意泄露给他人!!!1.首先打开某个页面,点击键盘的F12键进入控制台,或者鼠标右键页面选择打开控制台_怎么查看网页请求头...
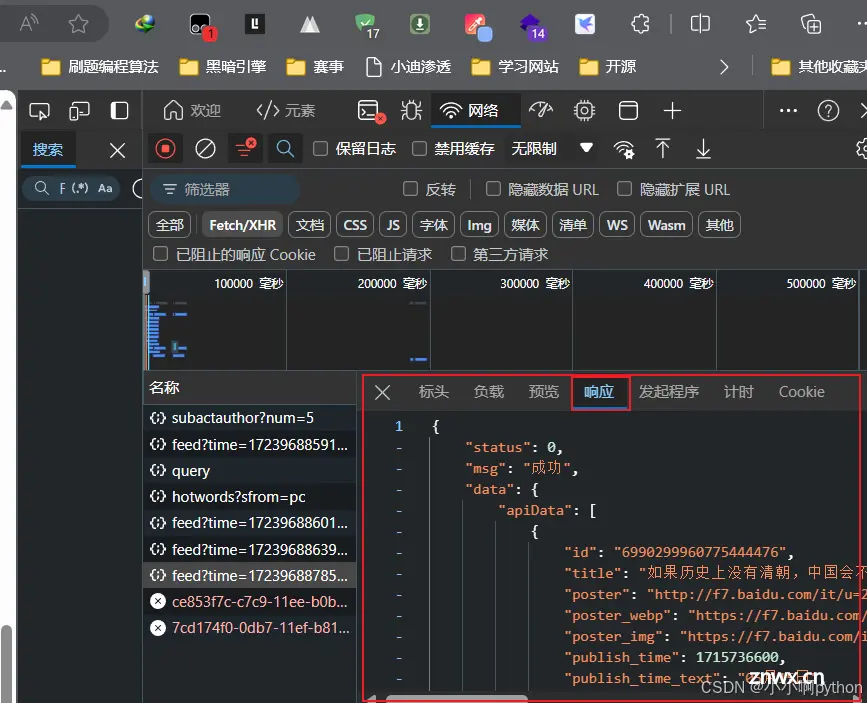
@目录前言爬虫步骤确定网址,发送请求获取响应数据对响应数据进行解析保存数据完整源码共勉博客前言本文写了一个爬取视频的案例,使用requests库爬取了好看视频的视频,并进行保存到本地。后续也会更新selenium篇和DrissionPage篇。当然,爬取图...

指定url发送请求UA伪装:UA、Referer防盗链和Cookie身份信息都放在head中获取你想要的数据在Element获取视频信息数据解析在响应Response中,定位视频的具体位置,请求访问它特别注意:其...