
Win10WSL2。_开源ai平台部署...
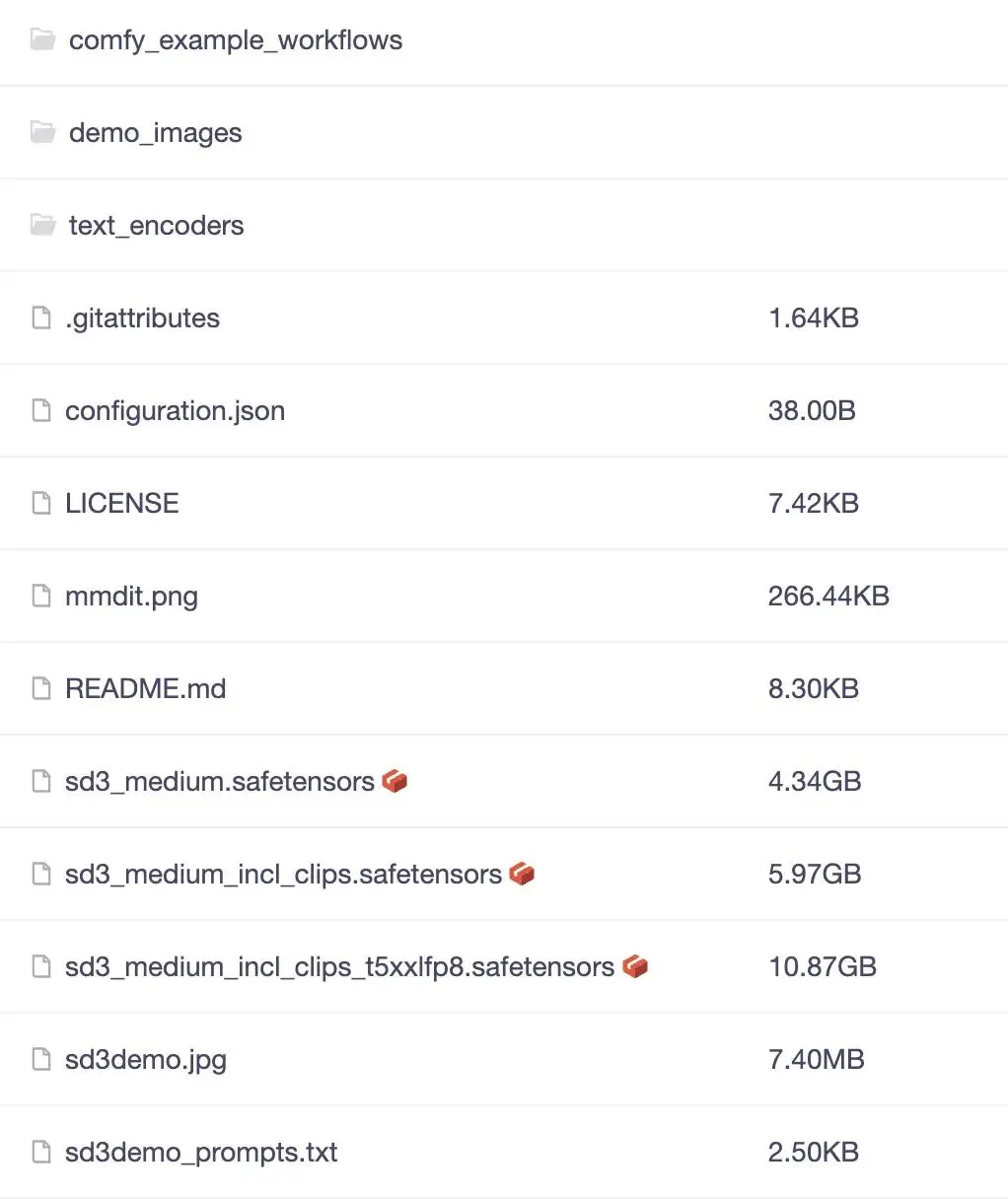
StabilityAI正式开源了StableDiffusion3Medium文生图大模型,它仅20亿参数,就能够生成更高质量和更细腻的图片;因模型尺寸较小,它适合在个人PC、笔记本电脑上运行。老牛同学手把手部署和体验SD3……...
首先需要选中一个文件点击添加注释注释添加完成(如果对于注释不满意可以多点几次添加注释)_代码注释ai...
照片说话,数字人,sadtalker源码运行环境搭建,整合包获取_ai数字人声音匹配图片...
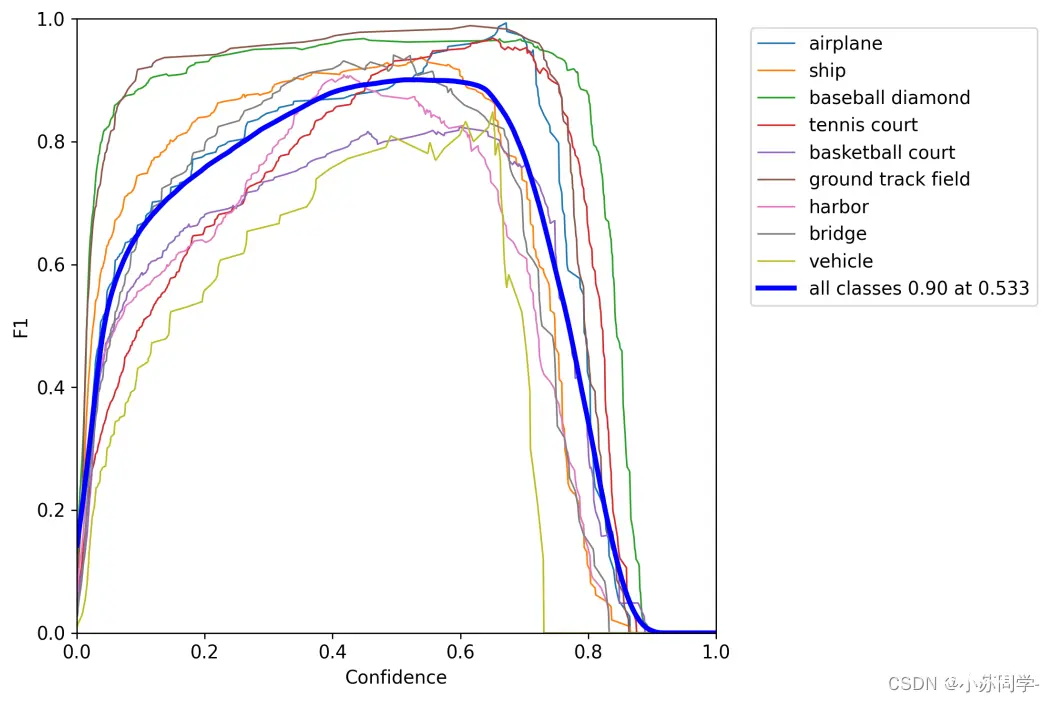
Vitis-AI进行量化编译_yolov5vitisai...
StyleTTS2通过建模风格为潜在随机变量,通过扩散模型生成最适合文本的风格,而无需参考语音,实现了高效的潜在扩散,并从扩散模型提供的多样化语音合成中受益。此外,它还利用大型预先训练的SLM,如WavLM,作...
站得高,才能看得远,学习前沿知识,用于今后职业发展的方向指导...
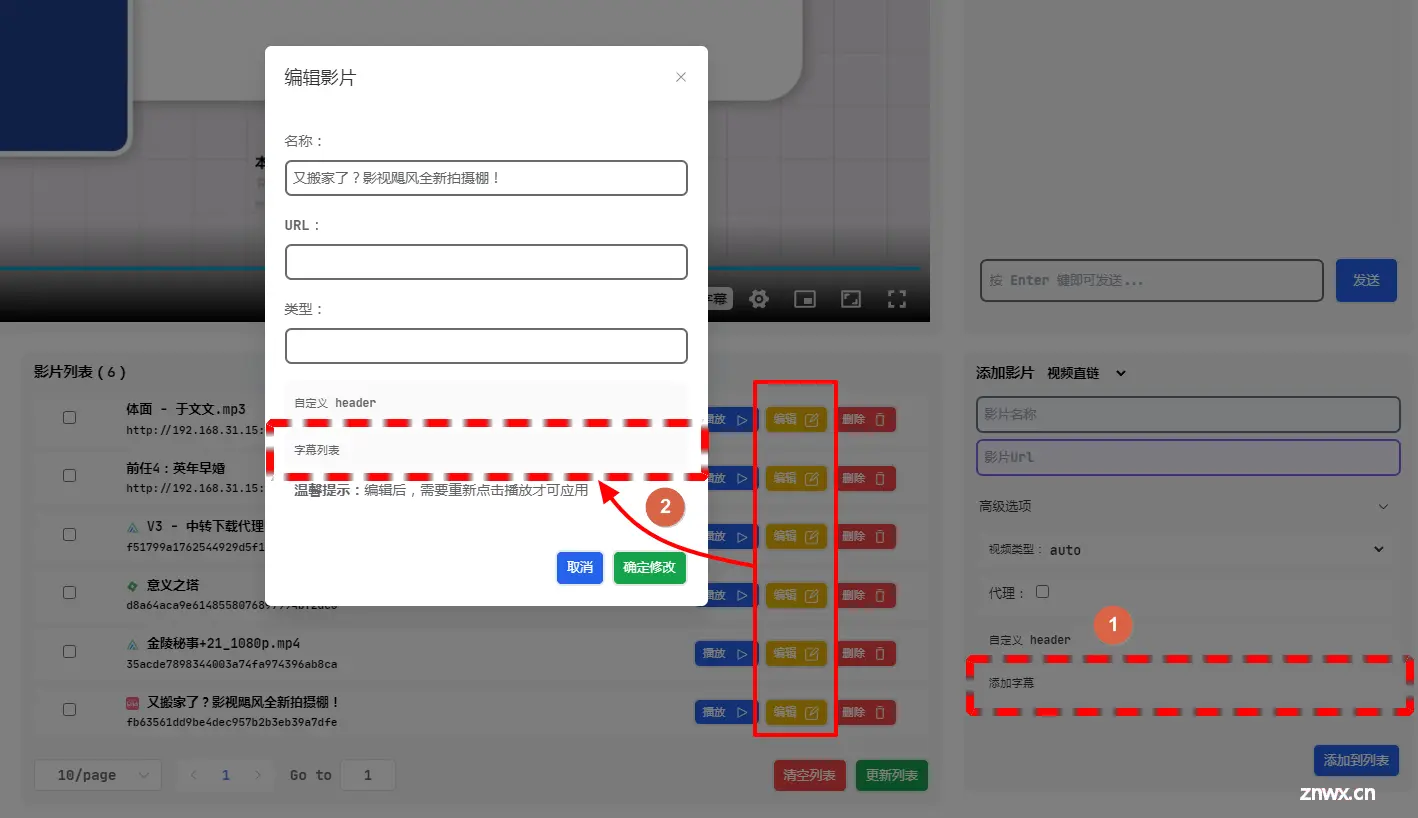
SyncTV是一个允许您远程一起观看电影和直播的程序。它提供了同步观看、剧院和代{过}{滤}理功能。使用SyncTV,您可以与朋友和家人一起观看视频和直播,无论他们在哪里。SyncTV的同步观看功能确保所有观看视...
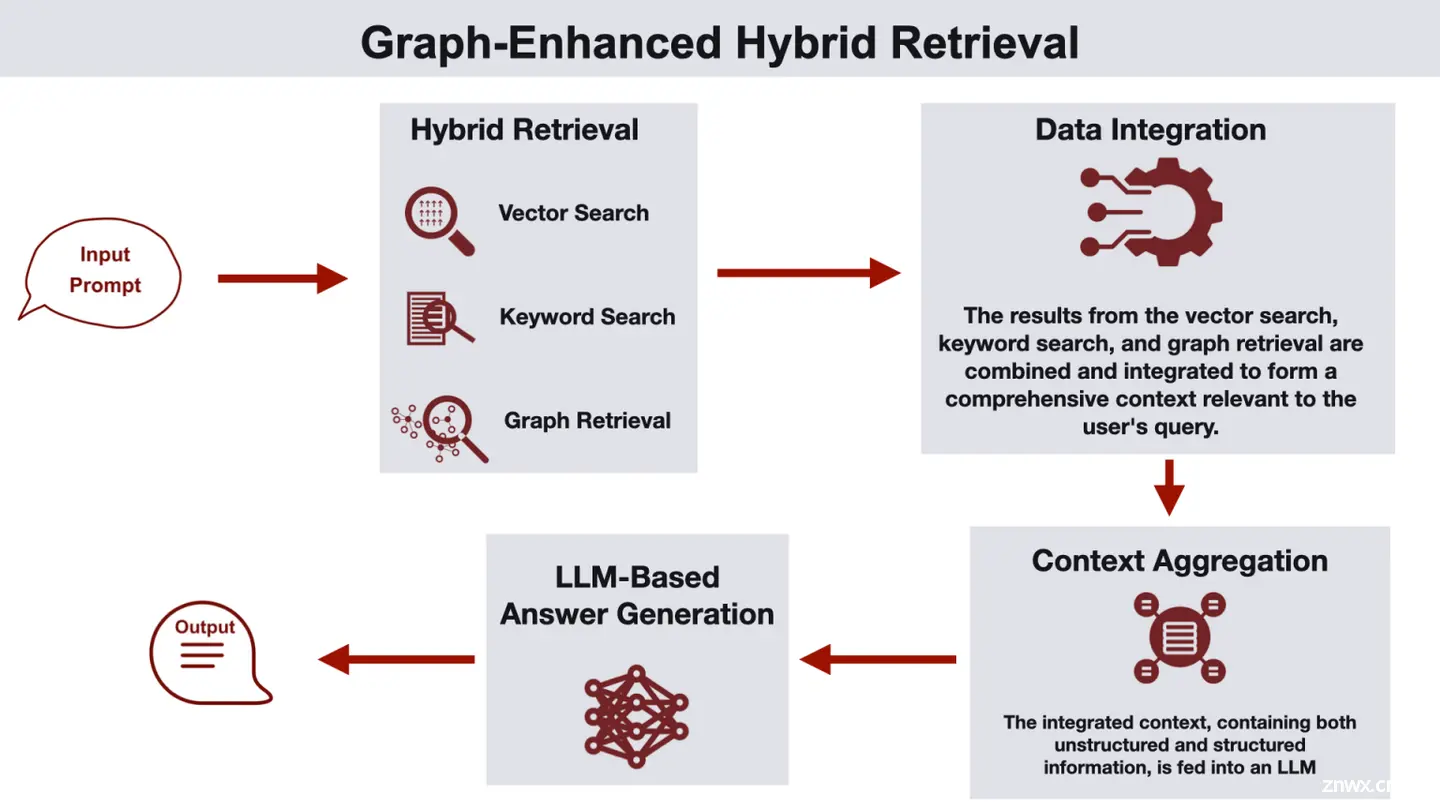
引入知识图谱技术后,传统RAG链路到GraphRAG链路会有什么样的变化,如何兼容RAG中的向量数据库(VectorDatabase)和图数据库(GraphDatabase)基座,以及蚂蚁的GraphRAG开源技术方案和未来优化方向。...

Whisper是OpenAI研发的一个通用的语音识别模型,可以把语音转为文本。它在大量多样化的音频数据集上进行训练,同时还是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别_rustttssp...