OpenAI 开源的免费 AI 语音转文字工具 - Whisper,一步一步本地部署运行
TechAI 2024-06-17 16:01:01 阅读 95

Whisper 是 OpenAI 研发的一个通用的语音识别模型,可以把语音转为文本。它在大量多样化的音频数据集上进行训练,同时还是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
一、使用场景
语音 => 文字 是一个非常实用的功能,例如:
会议、讲座、法庭、医疗等等场景的记录
口述笔记,方便需要频繁记录思路、灵感的人,更快地记录想法
智能助手,例如智能音箱、导航等
文案提取,看到好的视频,可以把视频中的话转为文本文案
ChatGPT 的手机 APP 可以和我们语音对话聊天,就是使用 Whisper 把我们的语音转为的文本。
所以,Whisper 的强大能力不用多说。
现在市面上语音转文字的产品很多都是收费的,例如讯飞语记等等。
Whisper 是开源免费的,而且效果极佳,如果能在自己的电脑中运行,岂不是美事。
下面就以Windows11为例,介绍一下它的安装运行流程。
二、安装步骤
1)安装 ffmpeg
下载地址:
ffmpeg.org/download.html
安装后,打开cmd命令行,确定可以执行 ffmpeg 命令:
ffmpeg -version
如果无法执行,手动配置一下环境变量PATH。
2)安装 rust
下载地址:
rust-lang.org/tools/install
同样的,安装后需要确定命令行可以执行,测试命令:
rustc --version
如果无法执行,手动配置一下环境变量PATH。
rust 的默认安装位置是 ~/.cargo/bin。
3)安装 Whisper
配置python虚拟环境,因为 Whisper 需要特定版本的 python。
conda create --name whisper_env python=3.9.18activate whisper_env
安装依赖库:
pip install setuptools-rustpip install -U openai-whisper
三、运行
命令行运行:
whisper Haul.mp3 --model medium
其中 “Haul.mp3” 是我测试用的音频文件。
“--model medium” 是指定使用 medium 版本的模型(Whisper 有多种模型:tiny、base、small、medium、large,模型大小依次变大)。
第一次运行时,会先下载指定的模型,需要耐心等待一会儿。
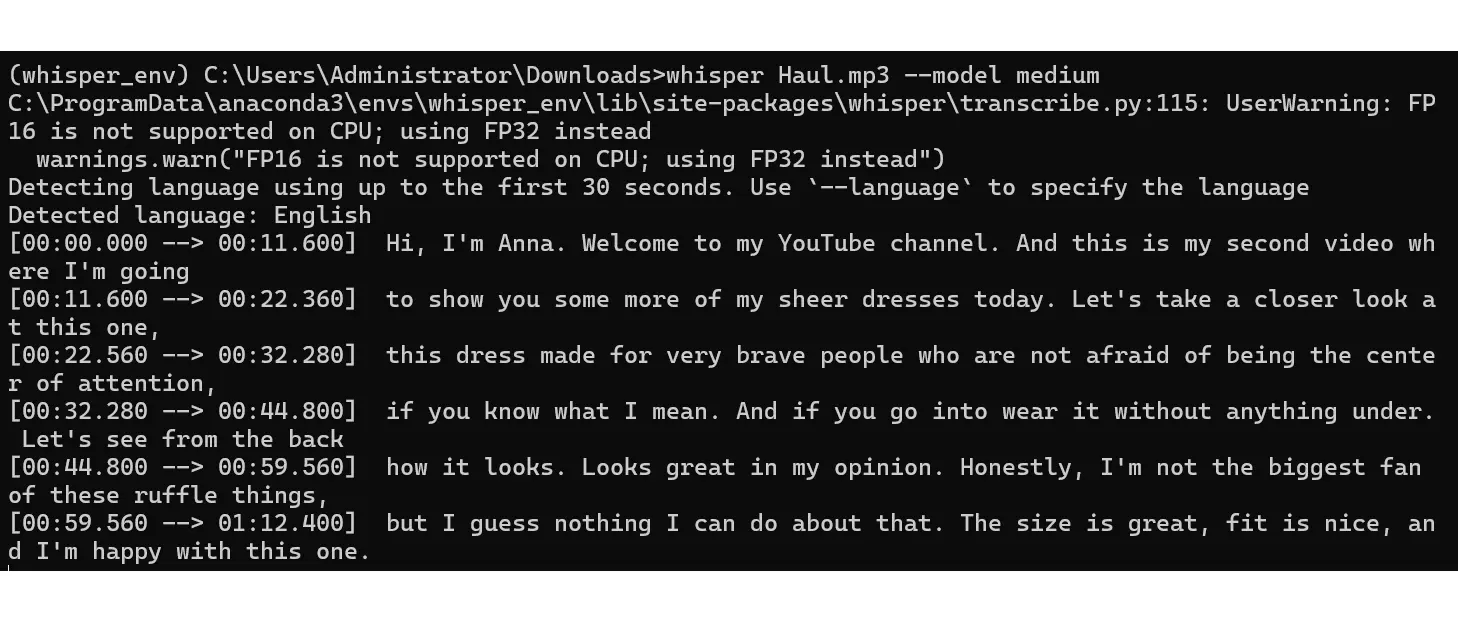
模型下载之后,就会开始执行语音识别,输出识别结果。
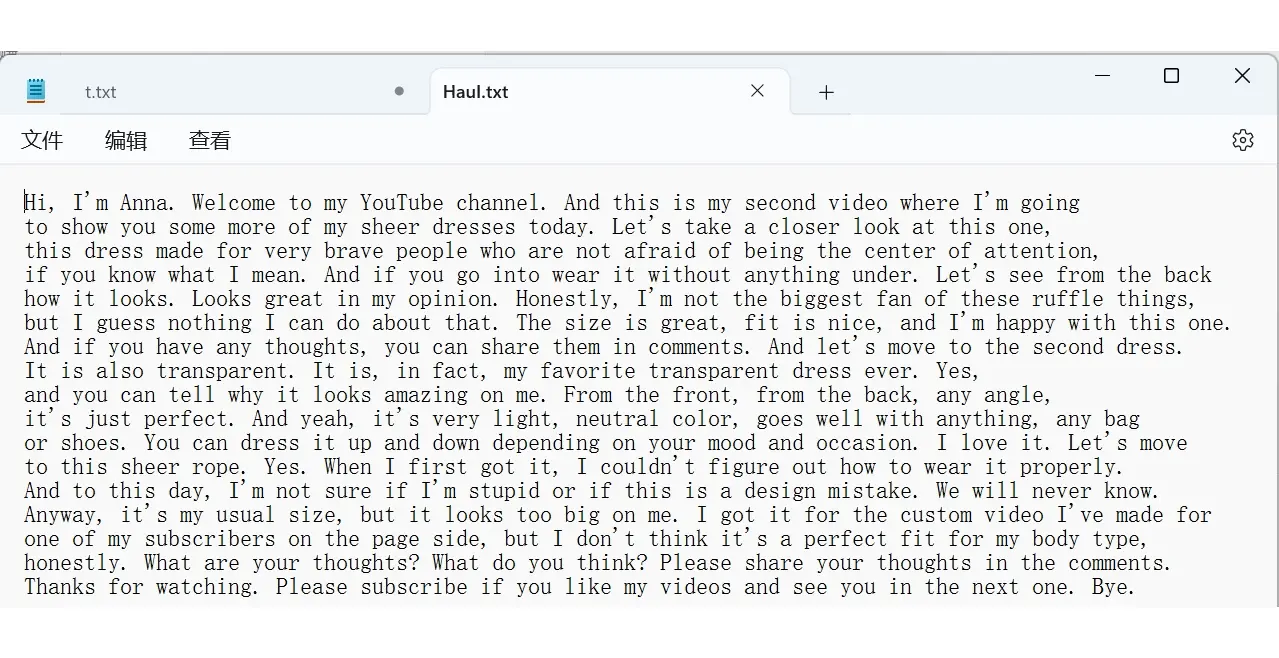
并且会自动写入文件。
Python代码中运行:
import whisper# 加载模型model = whisper.load_model("medium")# 加载音频文件audio = whisper.load_audio("Haul.mp3")audio = whisper.pad_or_trim(audio)# make log-Mel spectrogram and move to the same device as the modelmel = whisper.log_mel_spectrogram(audio).to(model.device)# detect the spoken language_, probs = model.detect_language(mel)print(f"Detected language: {max(probs, key=probs.get)}")# decode the audiooptions = whisper.DecodingOptions()result = whisper.decode(model, mel, options)# print the recognized textprint(result.text)
怎么样,感觉不错吧,有兴趣的话,快试试吧。
项目地址:
github.com/openai/whisper
#AI 人工智能,#OpenAI,#whisper, #ChatGPT,#语音转文字,#gpt890
信息来源 gpt890.com/article/34
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。