
llama.cpp是一个高性能的CPU/GPU大语言模型推理框架,适用于消费级设备或边缘设备。开发者可以通过工具将各类开源大语言模型转换并量化成gguf格式的文件,然后通过llama.cpp实现本地推理。经过我的调研,相比较其它大模型落地方案,中小型研发企业使...

了解完嵌入模型、向量数据库相关知识后,在此基础上可以实现一个RAG本地问答系统。_springairag...
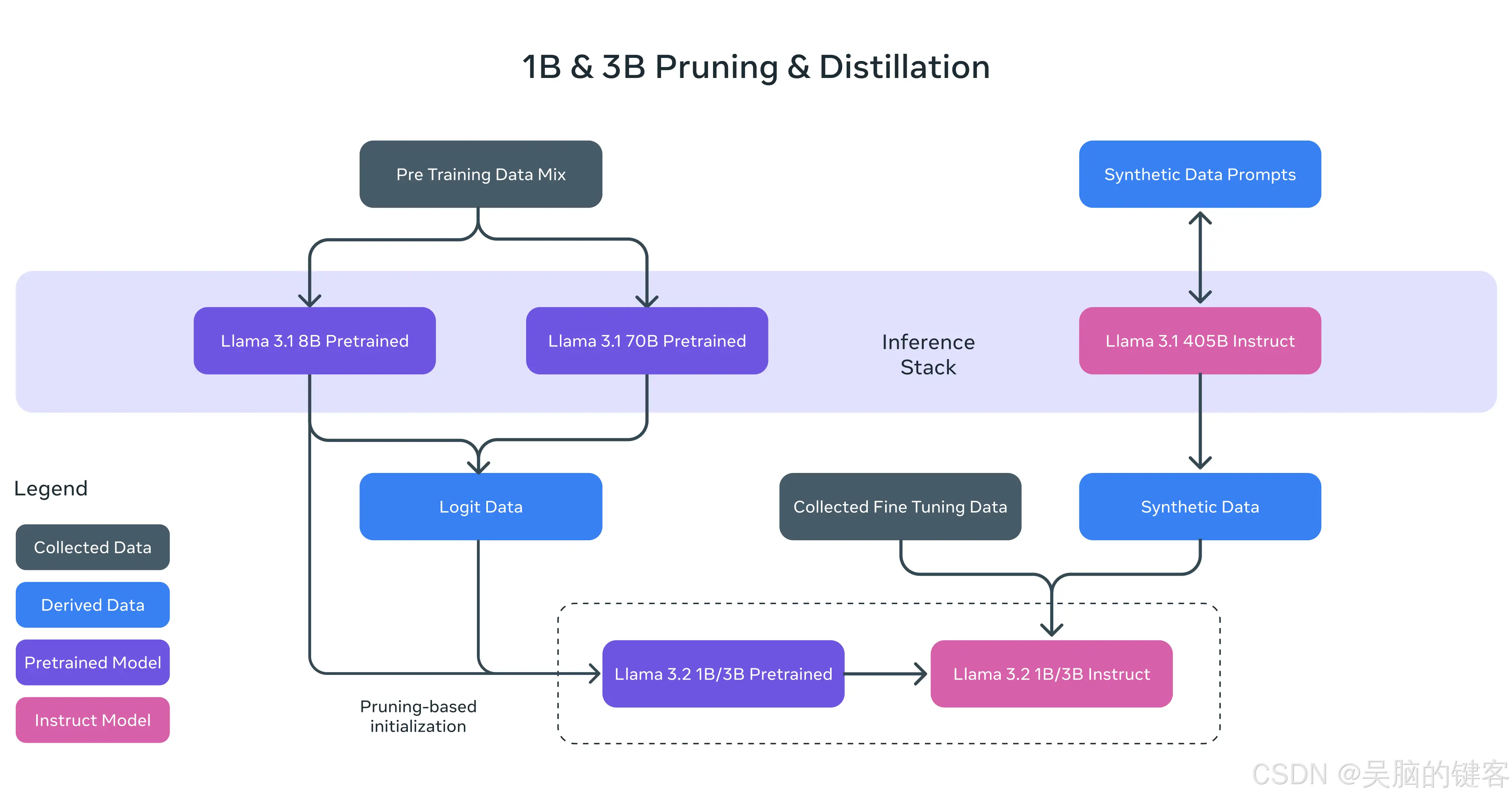
在我们发布Llama3.1模型群后的两个月内,包括405B-第一个开放的前沿级人工智能模型在内,它们所产生的影响令我们兴奋不已。虽然这些模型非常强大,但我们也认识到,使用它们进行构建需要大量的计算资源和...

通过手动下载必要文件并修改安装脚本,你可以有效解决由于网络问题导致的Ollama安装失败。这种方法特别适合在受限网络环境下工作或部署的用户。希望这篇指南能帮助你顺利安装Ollama,并在你的开发环境中开始使用这...

OpenWebUI(FormerlyOllamaWebUI)也可以通过docker来安装使用1.详细步骤1.1安装OpenWebUI#官方建议使用python3.11(2024.09.27),conda的使用参考其他文章co...
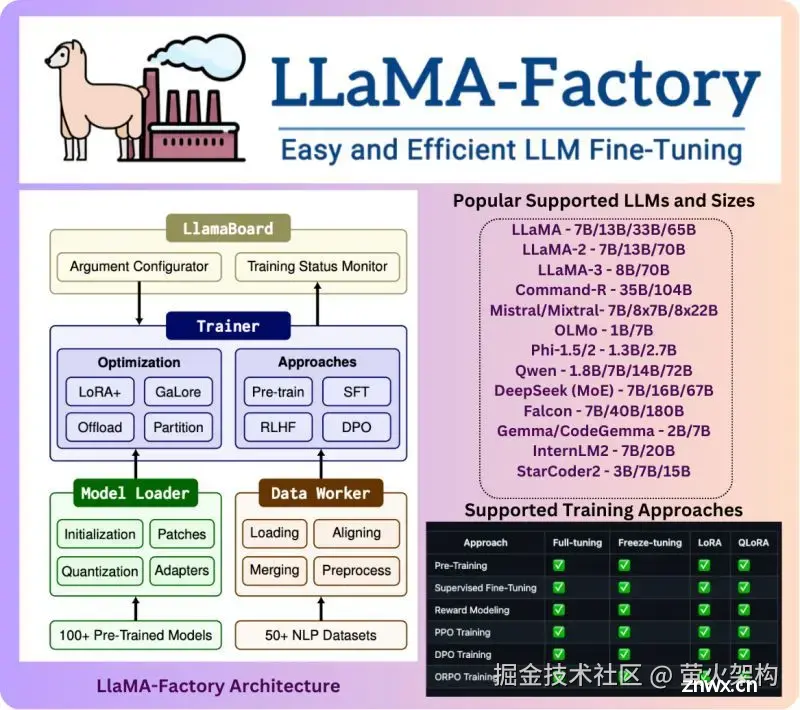
本文聊聊LLama-Factory,它是一个开源框架,这里头可以找到一系列预制的组件和模板,让你不用从零开始,就能训练出自己的语言模型(微调)。不管是聊天机器人,还是文章生成器,甚至是问答系统,都能搞定。而且,...
通过上述步骤,你可以在Java应用程序中无缝集成基于Ollama的本地大型语言模型,为你的项目增添强大的自然语言处理能力。随着Ollama及其支持的模型不断更新,持续探索和优化模型调用策略,将能进一步提升应用性能和...

此处由于挂载目录使用了相对路径,所以本地文件夹位于/var/lib/docker/volumes/ollama而非运行命令的相对路径测试api。_dockerollama...

本文主要介绍如何在Windows系统快速部署Ollama开源大语言模型运行工具,并安装OpenWebUI结合cpolar内网穿透软件,实现在公网环境也能访问你在本地内网搭建的llama2、千文qwen等大语言模...
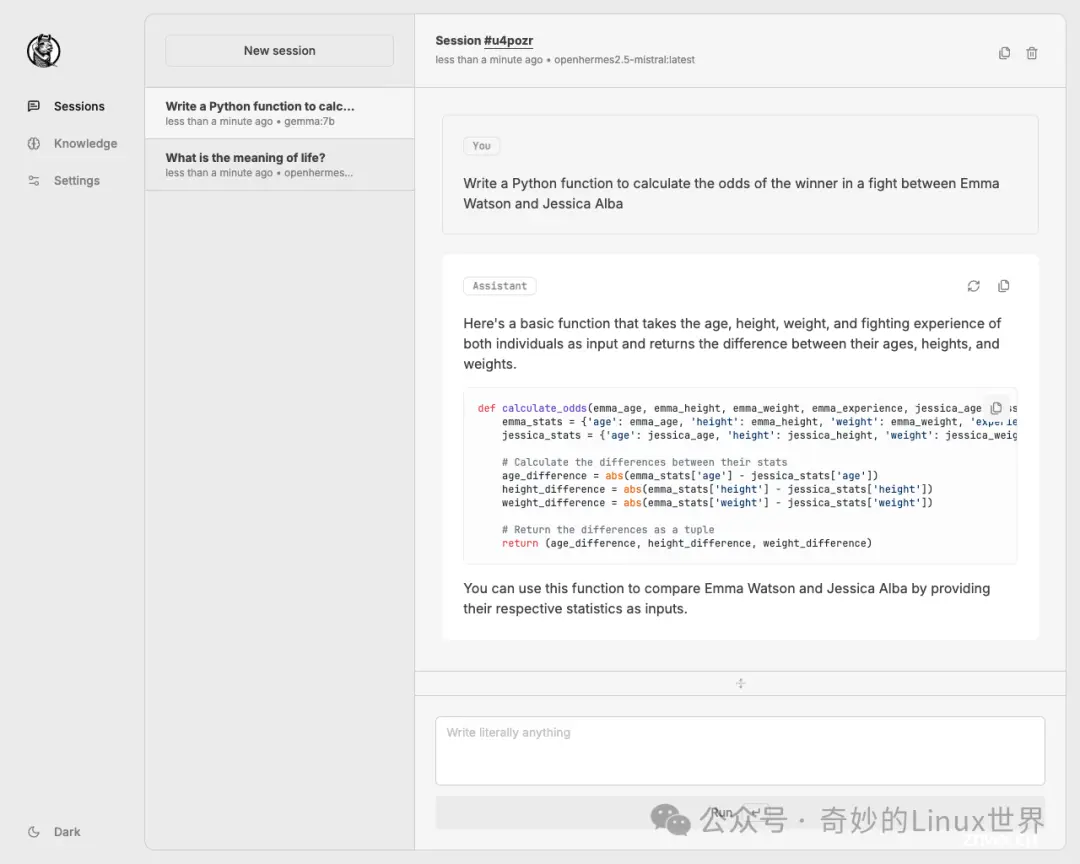
公众号关注「奇妙的Linux世界」设为「星标」,每天带你玩转Linux!????引言在人工智能快速发展的今天,我们越来越依赖各种AI工具来提高工作效率和生活质量。Ollama作为一个强大的本地AI模...