
YOLOv11由Ultralytics在2024年9月30日发布,最新的YOLOv11模型在之前的YOLO版本引入了新功能和改进,以进一步提高性能和灵活性。YOLO11在快速、准确且...
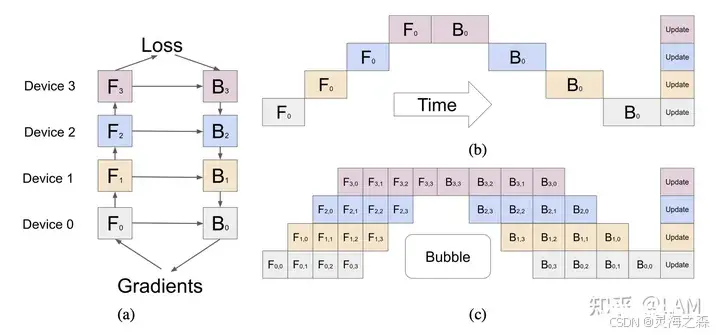
llama3.1论文称使用了:张量并行(TP)、流水线并行(PP)、上下文并行(CP)和数据并行(DP)。并行化可以先粗分为:1.数据并行2.模型并行:张量并行,流水线并行3.上下文并行(llama3.1)4.de...
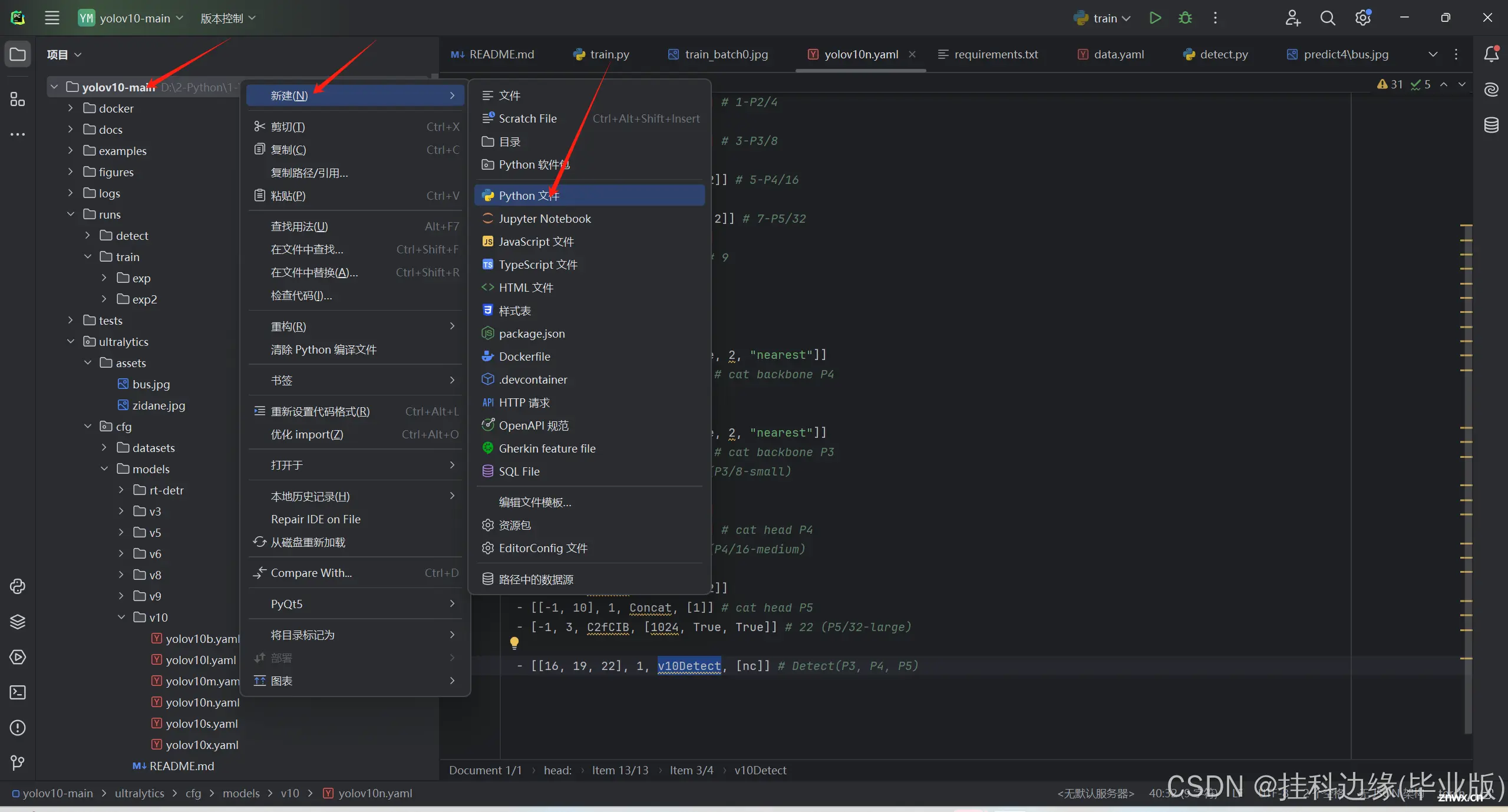
YOLOv10,由清华大学多媒体智能组只开发,是一款亳秒级实时端到端目标检测的开源模型。该模型在保持性能不变的情况下,与YOLOv9相比,延迟减少了46%,参数减少了25%,非常适合需要快速检测物体的应用,如实时...

大家好,我是默语,擅长全栈开发、运维和人工智能技术。今天我将和大家分享在大模型训练时如何解决CUDAOutofMemory错误的解决方案。这个问题在深度学习领域非常常见,尤其是在处理大型数据集和复杂模型时。...

本书内容系统、全面,实例丰富,共有10章,包括51个实操案例解析和80个行业案例分析。通过学习本书,读者可以从零开始,逐步掌握人工智能的核心技术,成为合格的AI训练师。本书附赠了同步教学视频+PPT教学课件+素...

Qwen2-57B-A14B作为一个强大的MoE模型,在保持较小激活参数规模的同时,实现了优秀的性能表现,为大规模语言模型的应用提供了新的可能性。任务中表现优异,超越了当前主流的MoE开源模型。SwiGLU激活函数...
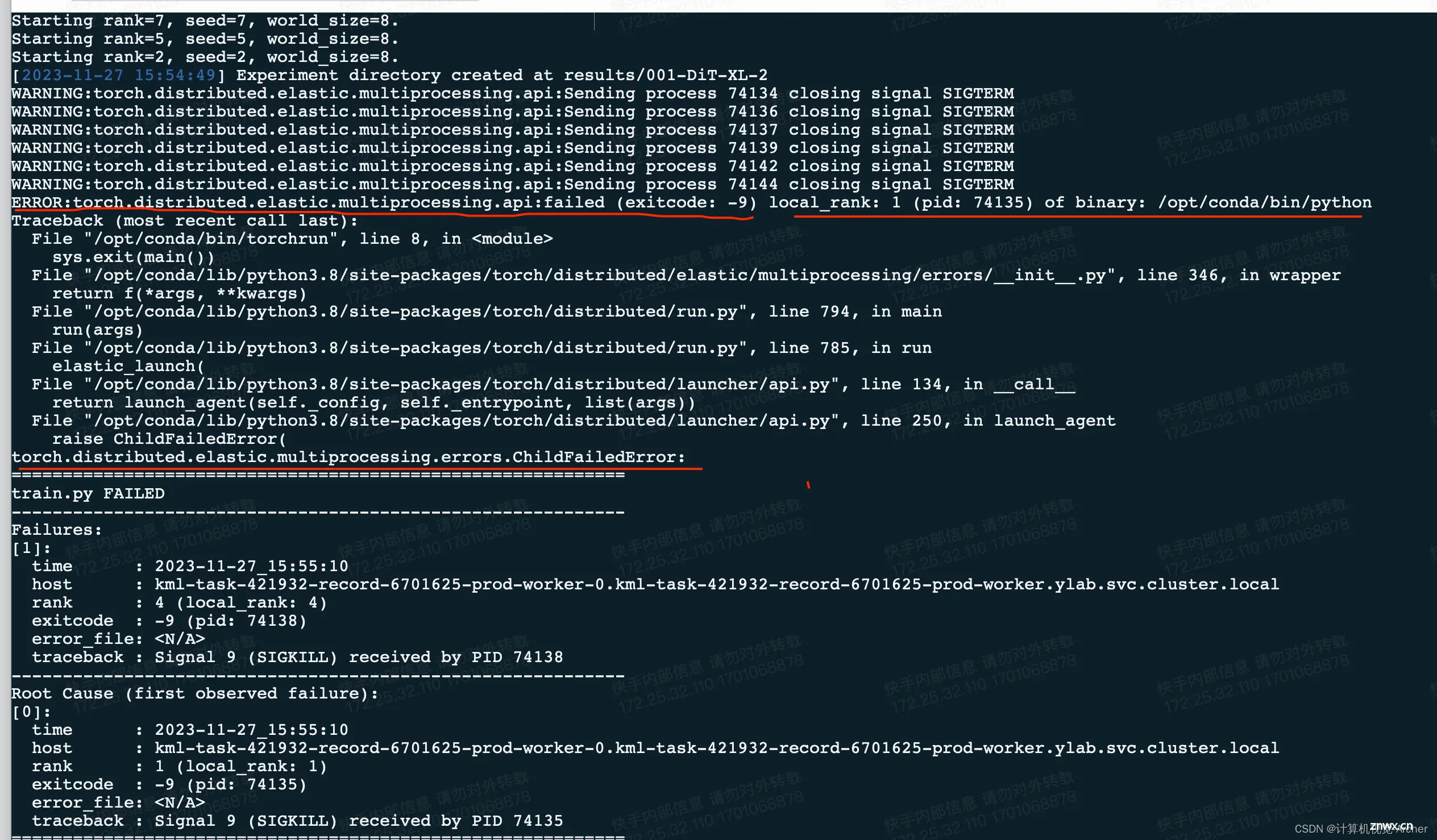
运行Dit时,torchrun--nnodes=1--nproc_per_node=8train.py--modelDiT-XL/2--data-path/home/pansiyuan/jupyter/...
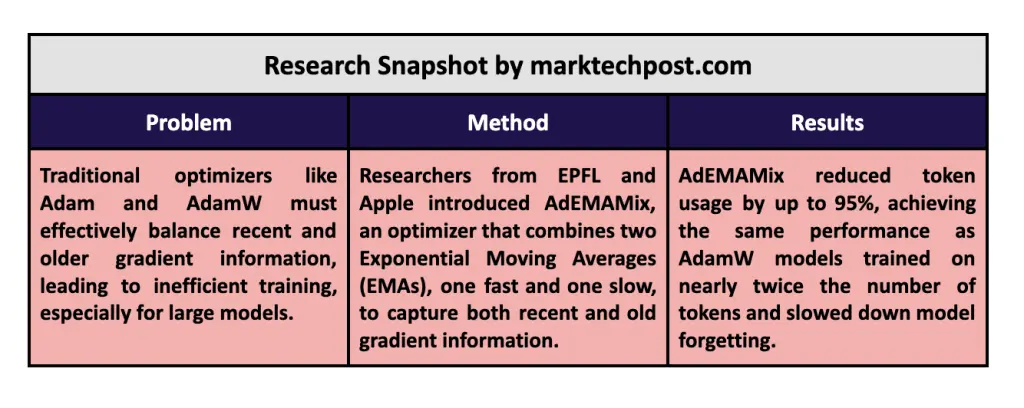
具体来说,AdEMAMix维护了一个快速变化的EMA,优先考虑最近的梯度,同时跟踪一个较慢变化的EMA,保留训练过程早期的信息。例如,在对RedPajama数据集上的一个13亿参数的语言模型进行训练时,研究...
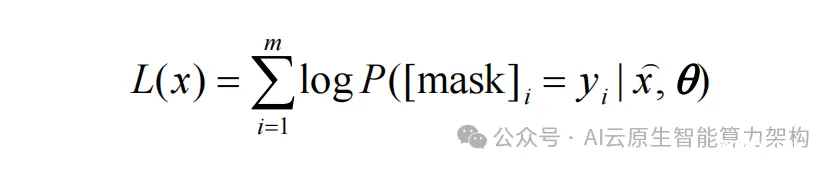
多模态预训练大模型架构与GPT和BERT类似,也是基于自注意力机制Transformer深度学习模型,其最大特点是模型的输入由单一模态的文本拓展到文本、语音、图像、视频等多个模态数据同时作为输入。多模态...
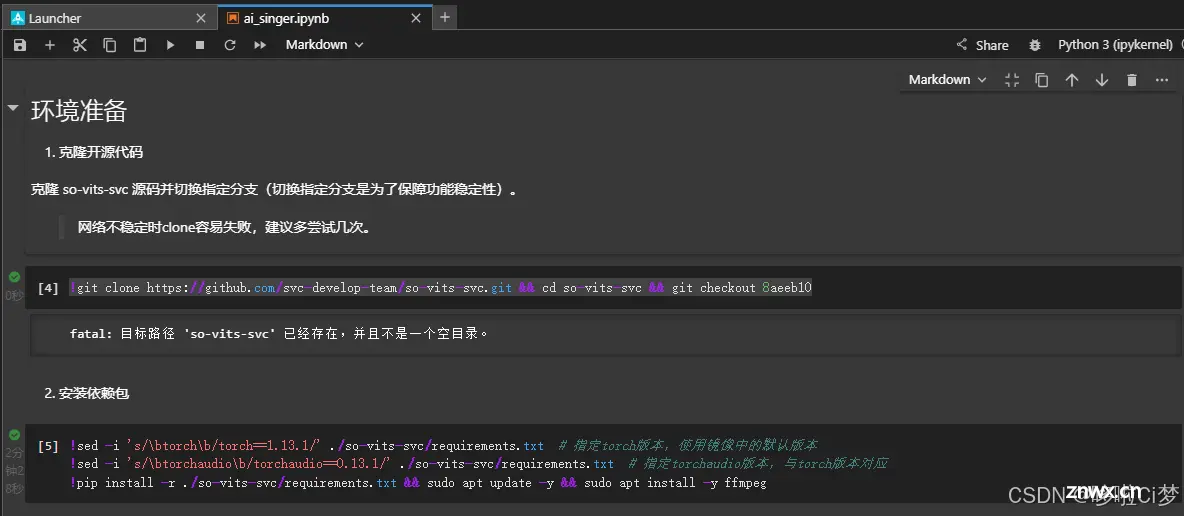
好久没更新了,但是按耐不住对人工智能大模型的好奇,这个项目很简单很微小,但也是一次尝试。留下一点笔记,做个纪念。最后吐槽一下,Ai唱的好像还没有我自己唱的好。_训练自己的语音模型...