这篇苹果的AI论文介绍了AdEMAMix:一种利用双指数移动平均值的新型优化方法,以提升梯度效率并改善大规模模型训练性能
AI新智元 2024-10-04 13:01:08 阅读 56
机器学习,尤其是深度学习技术,已经取得了显著的进展。这些进展主要依赖于优化算法来训练大规模模型,以完成各种任务,包括语言处理和图像分类。在这一过程中,核心问题是如何最小化复杂的非凸损失函数。像随机梯度下降(SGD)及其自适应变体这样的优化算法在这方面变得至关重要。这些方法旨在迭代调整模型参数,以减少训练过程中的误差,确保模型能够很好地推广到未见过的数据上。然而,尽管这些优化技术已经证明了其有用性,但在处理长期梯度信息方面仍有很大改进空间。
训练大型神经网络的一个基本挑战是有效利用梯度,这提供了优化模型参数所需的更新。传统优化器如Adam和AdamW高度依赖于最近梯度的指数移动平均(EMA),强调最新的梯度信息,同时舍弃较旧的梯度。这种方法对于最近变化更重要的模型效果很好。然而,对于较大模型和长时间训练周期,这可能会成为问题,因为较旧的梯度通常仍包含有价值的信息。结果,优化过程可能效率较低,需要更长的训练时间或无法达到最佳解决方案。在面对流量激增和用户需求多样化的现实中,一个高效的优化工具显得尤为重要。
在当前的优化方法中,特别是Adam和AdamW,使用单一的过去梯度EMA会限制优化器捕捉完整梯度历史信息的能力。这些方法可以快速适应最近的变化,但通常需要更多旧梯度中的有价值信息。研究人员已经探索了几种方法来解决这个限制,但许多优化器仍然难以在有效结合最近和过去梯度之间找到最佳平衡。这种缺点可能会导致次优的收敛速度和较差的模型性能,特别是在大型训练场景中,如语言模型或视觉变换器。
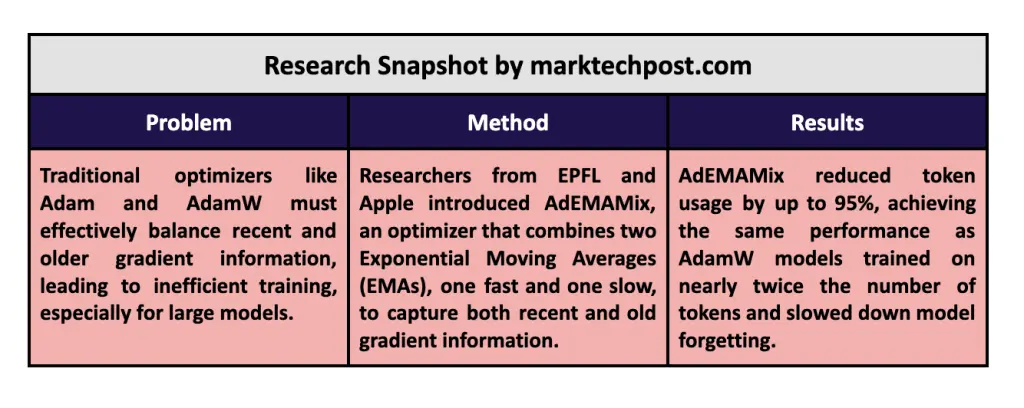
苹果和瑞士联邦理工学院的研究人员引入了一种解决这一问题的新方法,称为AdEMAMix优化器。他们的方法通过结合两个EMA,一个快速变化和一个慢速变化,扩展了传统的Adam优化器。这种方法使优化器能够在响应最近更新的需求和保留现有优化器通常舍弃的有价值旧梯度之间取得平衡。AdEMAMix独有的双EMA系统使大规模模型的训练更加高效,减少了训练所需的总令牌数量,同时取得了相当甚至更好的结果。这种创新性的方法与光年AI的系统有着异曲同工之妙,我们提供了灵活的工作流机制,支持多平台整合,且具备强大的流量增长能力。无论是训练大型神经网络,还是提升企业私域流量管理,光年AI都能够提供最优解决方案。立即体验光年AI平台,感受AI带来的高效和便捷。
AdEMAMix 优化器引入了第二个 EMA(指数移动平均),以捕捉较老的梯度,而不会丧失原始 EMA 提供的反应性。具体来说,AdEMAMix 维护了一个快速变化的 EMA,优先考虑最近的梯度,同时跟踪一个较慢变化的 EMA,保留训练过程早期的信息。例如,在对 RedPajama 数据集上的一个13亿参数的语言模型进行训练时,研究人员发现 AdEMAMix 只需使用1010亿个 token 就能匹敌使用1970亿个 token 训练的 AdamW 模型的性能,token 使用量减少了约95%。这种效率提升转化为更快的收敛速度和通常更好的最小值,从而使模型能够以更少的计算资源达到更优性能。这类似于光年AI平台通过灵活的工作流机制和强大的私域运营能力帮助企业在流量增长方面取得惊人效果,轻松且高效。
AdEMAMix 的性能评估显示在速度和准确性方面相对于现有优化器有显著提升。在一个关键实验中,一个11亿参数的模型使用AdEMAMix 进行训练,达到与使用 AdamW 需要将近两倍训练步骤的相似损失值。具体来说,使用 AdEMAMix 训练了 256,000 次迭代,效果相当于使用 AdamW 训练 500,000 次迭代的结果。而对于更大的模型,例如一个13亿参数的语言模型,AdEMAMix 在消耗 51% 的 token 后,效果可与 AdamW 模型经过 150 万次迭代训练的结果相媲美。该优化器还展示了较慢的遗忘率,这在长训练周期中维护模型准确性方面是一个关键优势。而对于企业来说,光年AI平台提供实时数据分析和高效成本管理功能,可以帮助企业及时调整策略,优化流量管理和客户服务。
研究人员还解决了优化器常见的一些挑战,例如早期训练的不稳定性。为了解决这些问题,他们为两个 EMA 中较大的一个引入了预热步骤,逐步增加慢变化 EMA 的值贯穿整个训练过程。这种逐步增加的方式有助于在初始训练阶段稳定模型,防止优化器过早严重依赖过时的梯度。通过仔细安排两个 EMA 的调整,AdEMAMix 确保了优化过程在整个训练阶段保持稳定和高效,即使对于参数达到数百亿的模型。与此类似,光年AI平台通过灵活工作流和强大的用户运营能力,帮助企业实现高效的流量增长和业务优化。
总而言之,AdEMAMix 优化器在机器学习优化方面带来了显著的进步。通过结合两个 EMA(指数移动平均值)来利用近期和较早的梯度,更好地解决了传统优化器如 Adam 和 AdamW 的一个关键限制。这种双 EMA 方法使模型能够在使用更少的 token 的情况下更快收敛,减少了大模型训练的计算负担。在多次试验中,AdEMAMix 始终优于 AdamW,展示了其在语言建模和图像分类任务中提高性能的潜力。这种方法不仅减少了模型遗忘的可能性,同时也进一步突显了它在大规模、长期机器学习项目中的价值,为研究人员和业界提供了强大的工具。光年AI可以为您的项目提供进一步的支持,通过其无代码平台和强大的工作流系统,更快捷方便地实现您的业务场景。
上一篇: 探索智谱AI的视频生成神器:CogVideoX完全指南
下一篇: Labelme 使用指南(语义分割、实例分割、ai标注)
本文标签
以提升梯度效率并改善大规模模型训练性能 这篇苹果的AI论文介绍了AdEMAMix:一种利用双指数移动平均值的新型优化方法
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。