AI系统的PyTorch:TextGrad框架基于文本梯度实现大语言模型AI系统自优化!
量化交易曾小健(金融号) 2024-08-15 11:01:02 阅读 65
AI系统的PyTorch:TextGrad框架基于文本梯度实现大语言模型AI系统自优化!
原创 旺知识 旺知识 2024年07月07日 16:21 广东
人工智能(AI)正在经历一场范式转变,这一转变是由系统协调多个大型语言模型(LLMs)和其他复杂组件所实现的突破推动的。因此,为复合AI系统开发有原则且自动化的优化方法,是构建这些系统所面临的最重要的新挑战之一。神经网络在其早期也面临类似的挑战,直到反向传播和自动微分的出现,它们通过使优化变得简单,从而改变了这个领域。受此启发,文本介绍了TEXTGRAD,这是一个通过文本执行自动“微分”的强大框架。TEXTGRAD将由LLMs提供的文本反馈反向传播,以改进复合AI系统的各个组件。在此框架中,LLMs以自然语言的形式提供丰富、通用、自然的语言建议,以优化计算图中的变量,这些变量的范围从代码片段到分子结构不等。TEXTGRAD遵循PyTorch的语法和抽象,并且是灵活且易于使用的。它开箱即用,适用于多种任务,用户只需提供目标函数,无需调整框架的组件或提示。本文在从问答到分子优化再到放射治疗计划的多种应用中展示了TEXTGRAD的有效性和通用性。在不修改框架的情况下,TEXTGRAD将Google-Proof问答中GPT-4o的零样本准确率从51%提高到55%,在优化LeetCode-Hard编码问题解决方案中实现了20%的相对性能提升,改进了推理提示,设计了具有理想in silico结合亲和力的新型药物样小分子,并设计了具有高特异性的放射肿瘤治疗计划。TEXTGRAD为加速下一代AI系统的发展奠定了基础。
我们翻译解读最新论文:TextGrad通过文本自动 "微分",文末有论文链接。


作者:张长旺,图源:旺知识
1 引言
由于大型语言模型(LLMs)的突破,AI系统的构建方式正在经历一种新兴的范式转变。新一代的AI应用越来越成为涉及多个复杂组件的复合系统,其中每个组件可能是基于LLM的智能体、模拟器这样的工具,或者是网络搜索。例如,LLMs与符号求解器通信的系统可以解决奥林匹克级别的数学问题;使用搜索引擎和代码解释器工具的LLMs系统表现与人类竞争性程序员相当,并且正在解决现实世界的问题。然而,这些突破中的许多来自于领域专家手工打造的系统,并通过启发式调整。因此,为构建包含LLMs的复合系统,开发有原则和自动化的优化AI系统的方式是至关重要的,这对于解锁AI的力量是必要的。在过去的15年中,许多AI的进步都依赖于人工神经网络和可微优化。神经网络的不同部分(例如,两个人工神经元)通过可微函数(如矩阵乘法)进行通信。因此,使用提供改善模型的每个参数方向的数值梯度和反向传播,已经成为训练AI模型的自然方式。实现反向传播的灵活自动微分框架对于AI模型的发展是不可或缺的。为了优化新一代的AI系统,我们引入了通过文本的自动微分。在这里,我们使用微分和梯度作为来自LLMs的文本反馈的隐喻。在这个框架中,每个AI系统被转换为一个计算图,其中变量是复杂(不一定是可微的)函数调用的输入和输出。对变量的反馈(被称为“文本梯度”)以描述如何改变变量以改善系统的丰富、可解释的自然语言批评的形式提供。梯度通过任意函数传播,例如LLM API调用、模拟器或外部数值求解器。我们在包括问答基准测试到放射治疗计划优化和分子生成的多个领域中展示了我们框架的强大功能。LLMs可以在这些广泛的领域中为变量提供非常丰富、易读和富有表现力的自然语言梯度,例如提出对分子的修改、对其他LLMs的提示和代码片段。我们的框架建立在这样一个假设之上,即当前最先进的LLMs能够推理它试图优化的系统的各个组件和子任务。我们通过以下结果展示了TEXTGRAD的灵活性:
编码:在第3.1节中,我们优化了来自LeetCode的困难编码问题的解决方案,我们通过20%的相关性能提升,提高了gpt-4o和最佳现有方法的性能。
问题解决:在第3.2节中,我们优化了复杂科学问题的解决方案,以提高GPT-4o的零样本性能。例如,在Google-Proof问答基准测试中,我们通过在测试时改进解决方案,将零样本准确率从51%提高到55%。
推理:在第3.3节中,我们优化了提示,以提高LLM性能,我们将GPT-3.5在几个推理任务中的性能提升到接近GPT-4。
化学:在第3.4节中,我们设计了具有理想药物样性和in silico结合亲和力的新型小分子。
医学:在第3.5节中,我们为前列腺癌患者优化了放射治疗方案,以实现理想的目标剂量并减少副作用。我们在广泛的应用中的结果表明,TEXTGRAD通过文本反馈的反向传播自动优化复合AI系统是有希望的。

2 TEXTGRAD:通过文本反馈进行AI系统优化
首先,我们通过一个由两次LLM调用组成的系统示例来描述TEXTGRAD的外观,然后给出适用于任意复杂系统的更一般形式。
预热:包含两次LLM调用的系统
示例计算图。在传统的自动微分中,我们计算梯度,这些梯度提供了一个方向,可以在使用链式法则的情况下改善变量相对于下游损失。让我们以一个简单系统为例:

其中,我们用绿色表示要优化的自由参数,即提示,用 + 表示两个字符串的连接,用 LLM(x) 表示将 x 作为提示给语言模型以收集回复。我们将使用链式符号:

作为该系统的另一种表示方法,我们调用一次 LLM,利用提示为一个问题生成一个预测,然后再调用另一次 LLM 来评估这个预测。
示例梯度计算。在这个示例系统中,为了改善提示(Prompt)以适应评估,我们通过以下方式实例化了一个自动微分算法的类比:

其中∇LLM用于表示梯度运算符,当正向函数是LLM调用时。这个函数返回自然语言反馈,例如‘这个预测可以通过...来改进’,其中反馈描述了如何修改变量以改善下游目标,类似于优化中的梯度。我们首先使用评估收集对预测变量的反馈。然后,给定这个反馈和(Prompt LLM → Prediction)调用,我们收集对提示的反馈。
以下是一种灵活的实例化 ∇LLM 的方法,可为 x 这样的简单系统收集反馈信息:
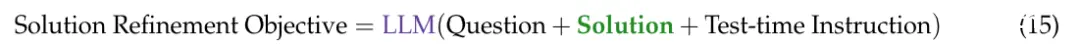
示例优化器。在标准梯度下降法中,变量的当前值通过减法与梯度值相结合,例如:


实例化 TGD 的具体方法如下:
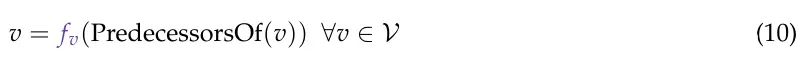
一般情况
这种抽象很容易适用于任意复杂的系统。通过以下方式定义一个计算图:

其中 𝑣是图中的一个变量,𝑉是图中所有变量的集合,SuccessorsOf 返回一个变量的后继和 PredecessorsOf 返回一个变量的前驱。一般来说,𝑣 的值可以是无结构数据,如自然语言文本或图像。在本文的大多数结果和解释中,𝑣v是自然语言文本。此外,让我们有 fv作为转换,它消耗一组变量并产生变量 𝑣。例如,我们可以使用LLM或数值模拟器作为转换。由于不同的函数将有不同的方式计算梯度并收集反馈,我们通常使用∇𝑓表示函数 𝑓的梯度函数。为了解释方便,当函数显而易见时,我们将省略下标。梯度通过以下方式计算:

其中我们从所有后继者那里收集梯度集合。直观地说,我们从每个变量 𝑣被使用的上下文中获得反馈,并进行聚合。公式11递归地计算了下游目标相对于图中所需变量 𝑣的梯度。∇𝑓函数以相对于某个变量 𝑣的后继者的 𝐿的梯度、变量 𝑣的值和后继者本身作为输入。请注意,最终的梯度变量包括了任何地方使用的变量的一组上下文和批评。最后,为了更新图中的任何所需变量 𝑣,我们可以使用优化器:
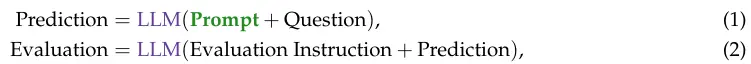
它根据其当前值和梯度更新 𝑣 的值。对于有 𝑛n条边的计算图,每次优化迭代最多执行 𝑛次额外的语言模型调用来计算梯度(在计算图中每条边使用梯度运算符进行1次调用)。
目标函数
在数值优化和自动微分中,目标函数通常是可微分函数,例如均方误差或交叉熵。在TEXTGRAD中,目标可以是复杂且可能是不可微分的函数,其中函数的域和值域可以是无结构数据。这种选择为框架增加了重要通用性和灵活性。例如,我们展示了目标可以以自然语言文本的形式指定,并由提示语言模型计算(§3.3),代码解释器运行单元测试的输出(§3.1),或分子模拟引擎的输出(§3.4)。例如,代码片段的简单损失函数可以是以下形式:
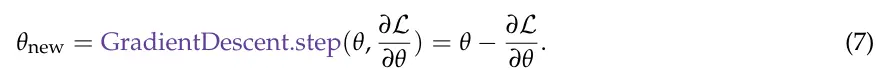
其中,我们可以使用这个评估信号来优化代码片段,这得益于LLMs模拟人类反馈、自我评估和自我改进的充分记录能力。
实例 vs 提示优化
我们探索了两类优化问题。
在实例优化中,我们直接将问题的解决方案——例如代码片段、问题解决方案或分子——视为优化变量。例如,在方程13中,我们有一个我们希望在测试时改进的代码实例。我们的框架生成了梯度,并直接优化了代码变量。
在提示优化中,目标是找到一个提示,以提高LLM在多个查询中对任务的性能。例如,我们可能想要找到一个系统提示给LLM,以提高其在数学推理问题上的性能(见第3.3节中的示例)。特别是,我们希望系统提示能够泛化,与实例优化相反,后者的唯一目标是在测试时改进给定查询的解决方案。关键的是,这两种类型的问题都可以在不手工制作框架的情况下解决。
优化技术
自动微分是TEXTGRAD的一个强有力的类比,并为框架中实现的优化技术提供了概念支持。下面,我们描述了一些示例。批量优化:我们为提示优化实现了随机小批量梯度下降[18, 34]。具体来说,在进行批量中的多个实例的前向传递并评估个别损失项之后,我们使用tg.sum函数来累加损失(类似于torch.sum)。在后向传递中,通过各个损失项的变量梯度被连接起来,类似于通过加法进行反向传播。
约束优化:我们使用自然语言约束,建立在约束优化的类比上[35]。特别是,我们使用自然语言约束(例如,‘你的回答最后一行应该是以下格式:“Answer: $LETTER”,其中LETTER是ABCD之一。’)来指导优化器的行为。我们观察到,由于指令调整[36, 37],语言模型可以遵循这些简单的约束,尽管它们的可靠性可能会因为太多的约束而降低[38, 39]。
动量:我们使用类比于梯度下降中的动量[40, 41]。在优化变量时,TGD优化器可以选择在进行更新时看到变量的早期迭代。
3 结果
我们展示了TEXTGRAD在多种应用中的灵活性。在§ 3.1中,我们优化了LeetCode上的困难编码问题的代码片段。在§ 3.2中,我们优化了科学问题的解决方案。在§ 3.3中,我们优化了提示以提高LLM的推理能力。在§ 3.4中,我们优化了化学结构以改善分子属性。在§ 3.5中,我们为前列腺癌患者优化了治疗计划。
3.1 代码优化
代码优化是实例优化的典型用例。这里的目标是优化一些代码,以提高例如正确性或运行时复杂性。我们通常有一个像以下的计算图:
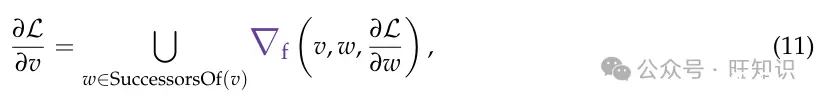
我们优化代码来解决给定的问题,使用有限的局部测试监督和通过测试指令进行自我评估,测试指令要求评估当前代码迭代的正确性和运行时性能。图1e显示了一个示例,问题是这样的:你有一个大小为n的nums数组,由1到n的不同整数组成,还有一个正整数k。返回nums中中位数等于k的非空子数组的数量。gpt-4o提出的第一种解决方案没有通过测试。TEXTGRAD识别了第一种解决方案中的一个边缘情况,并提供了如何改进的建议。优化后的实现通过了所有测试。
任务:我们使用LeetCode Hard数据集[26]来基准测试代码优化。LeetCode是一个在线平台,提供编码练习问题,为技术面试做准备。LeetCode Hard数据集包含对人类和语言模型都具有挑战性的困难编码问题,成功指标是完成率,即通过给定问题的所有测试用例(据报道GPT-4的完成率为7%[26])。LeetCode的测试用例不是公开的,因此,生成后的代码必须提交到LeetCode平台,以便在未见过的测试用例上进行评估。这使得该平台更适合评估语言模型的性能。
基线:Reflexion[26]是LeetCode Hard数据集上的最新技术方法。他们的方法提示一个LLM在测试时使用候选单元测试自省代码片段和生成的错误。给定自省后,LLM再次被提示根据自省和错误提供更新后的代码片段。我们在LeetCodeHard上使用gpt-4o运行Reflexion,使用1个上下文演示来指导行为(一次性)。除了Reflexion,我们还使用gpt-4o运行了一个零样本基线,模仿[26]中描述的零样本基线。相比之下,TEXTGRAD在零样本设置中运行,没有任何演示。
结果:现有结果[26]显示GPT-4零样本的通过率为7%,使用Reflexion的GPT-4为15%。我们展示了这些结果现在已经提高到gpt-4o零样本的23%,使用Reflexion时为31%。使用TEXTGRAD,我们可以优化解决方案,实现36%的性能。

3.2 通过测试时训练改进问题解决的解决方案优化
在这里,我们专注于通过TEXTGRAD进行解决方案优化的任务。在解决方案优化中,目标是改进对复杂问题的解决方案,例如关于量子力学或有机化学的问题。我们通常有一个像以下的计算图:
这里我们优化的是解决方案,损失函数是通过解决方案的评估获得的,例如,通过LLM进行评估。在每次迭代中,LLM被提示问题、当前解决方案和一些测试时指令,要求对当前迭代进行批评或调查。在优化过程中,解决方案通过这种测试时自我评估得到改进。更一般地说,这个想法被称为测试时训练[42, 43],即在测试时对机器学习模型进行训练,通常带有自监督目标。同样,最近的工作表明,自我改进对于推理任务也是有益的[26, 30, 44]。例如,即使LLM在第一次尝试时可能没有正确回答问题或问题的解决方案,它可以通过迭代细化改进响应。例如,细化的客观函数如下所示:

下面是 TEXTGRAD 中解决方案优化的一个代表性实施方案:

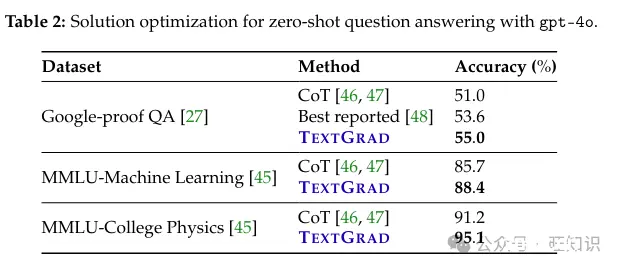
任务:Google-proof问答(GPQA)[27]是一个新的基准,其中由拥有或正在攻读博士学位的领域专家创建并标记了物理、生物学和化学中具有挑战性的多项选择题。在这个基准中,专家和熟练的非专家分别达到81%和22%的准确率,证明了问题的难度。重要的是,这是一个性能尚未饱和的基准,据我们所知,迄今为止报告的最佳结果,由gpt-4o在钻石子集中获得53.6%的准确率。我们还使用了MMLU[45]问答基准的两个具有挑战性的子集(机器学习和大学物理),这是用来跟踪语言建模进展的基准,并确定LLM是否达到了人类水平的表现。在这里,专家人类的平均准确率约为90%。有关问题格式和提示的详细信息,请参阅附录D。
方法:我们报告了两个基线。首先,gpt-4o发布文档中报告的结果为53.6%准确率。然而,他们的官方实现使用了0.5的温度进行生成,因此我们还测试了温度为0的gpt-4o,并提供了官方实现中的Chain-of-Thought(CoT)[46, 47]提示。对于TEXTGRAD,我们进行了3次测试时更新(即更新解决方案三次),并对所有解决方案进行多数投票以获得最终答案。我们使用基于字符串的度量标准来计算每个答案的最终准确率。
结果:通过TEXTGRAD,我们提高了gpt-4o在具有挑战性的问答任务中的性能,并在表2中报告了结果。据我们所知,55%是GPQA数据集中迄今为止已知的最佳结果。同样,我们将MMLU子集的性能从85.7%提高到88.4%(机器学习)和从91.2%提高到95.1%(大学物理)。这些结果表明,通过在测试时通过TEXTGRAD自我改进,我们可以提高甚至最有能力模型的问题回答性能。

3.3 推理的提示优化
尽管大型语言模型(LLMs)在推理任务上表现出令人印象深刻的性能,它们的性能可能对用于引导其行为的提示非常敏感。特别是,通过正确选择提示,它们的性能可以显著提高[49]。在提示优化中,目标是找到一个提示或指令,以指导LLM的行为,使其在给定任务上表现良好。我们通常有一个像以下的计算图:
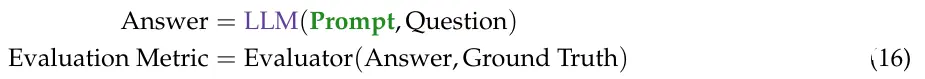
这里我们有一个任务的问题,一个对问题的答案,以及一个指示输出质量的评估指标。目标是最大化LLM在给定任务上的性能。在我们的实验中,我们的目标是使用更强的模型(例如,gpt-4o)在反向传播期间提供的反馈来提高较弱且成本较低的模型(例如,gpt-3.5-turbo-0125)的性能。这在实践中很有用,因为通过支付固定成本来优化一个提示,可以以较低的推理成本使用经过提示优化的较弱模型,而不是使用强大且更昂贵的模型。

在这里,我们在小批量随机梯度下降设置中使用 TEXTGRAD [18, 34]。具体来说,在每次迭代时,我们使用少量训练实例来运行公式 16 中的前向传递。在上面的代码段中可以找到伪代码和简短的实现过程。提示优化的全部细节见附录 E。与 TEXTGRAD 尝试优化每个单独解决方案的实例优化不同,这里的目标是优化一个在基准测试的所有问题中都能良好运行的单个提示。
方法:我们探索使用gpt-4o在反向传播期间提供反馈来提高gpt-3.5-turbo-0125的性能。特别是,虽然执行推理的前向模型是gpt-3.5-turbo-0125,但我们使用gpt-4o来提供反馈并改进提示。我们使用3的批量大小和12次迭代,即模型总共看到36个训练示例,随机替换采样。每次迭代后,我们使用数据集的验证集运行验证循环,如果性能优于上一次迭代,我们将更新提示。
基线:我们有两个主要的基线:
零样本链式思维(CoT)[46, 47]:我们初始化所有提示为零样本CoT提示,其中模型被指示“逐步思考”以解释其推理过程,然后再给出答案。这种策略是众所周知的强基线,用于提示。
DSPy是最新的语言模型编程和提示优化框架[10],因此我们将其作为参考基线。我们使用DSPy的BootstrappedFewShotRandomSearch(BFSR)优化器,它有10个候选程序和8个少数示例。这个优化器通过生成LLM输入和输出的跟踪来确定要在提示中包含的示例,这些示例单独通过度量标准(在这种情况下,是准确性)并包括CoT推理。然后,它在最多8个镜头的这些示例的子集上应用随机搜索。
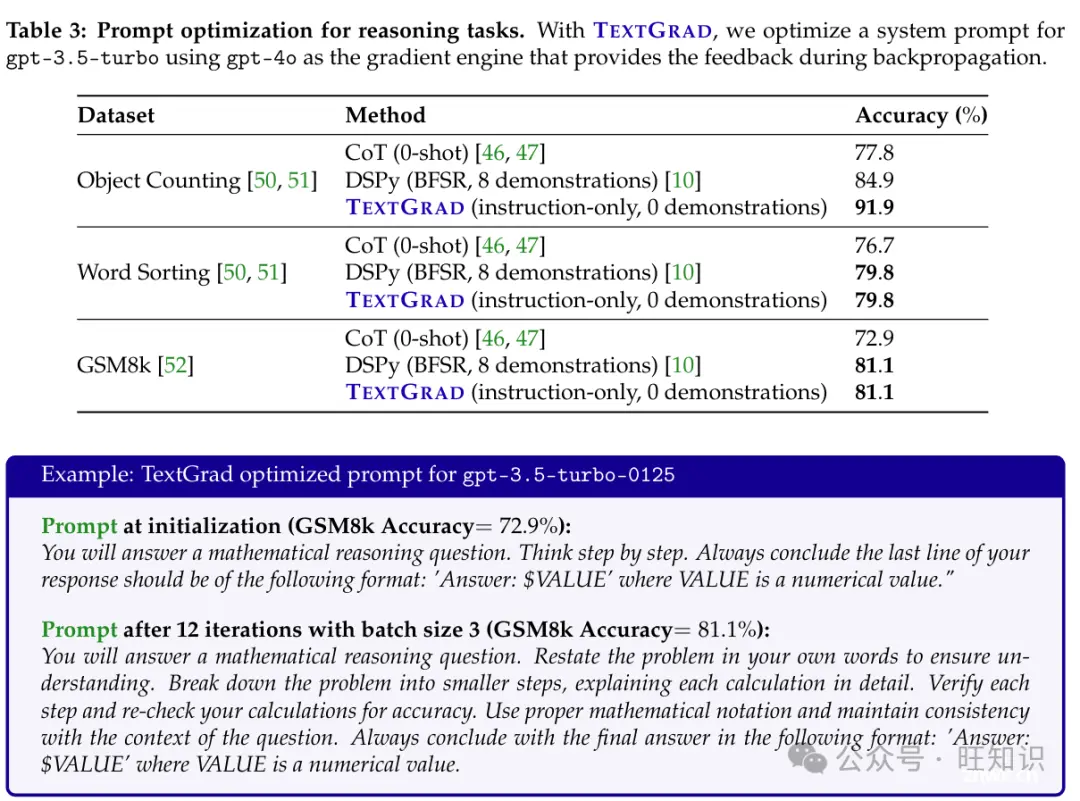
结果:在所有三个任务中,TEXTGRAD显著提高了零样本提示的性能。它在Word Sorting和GSM8k上的表现与DSPy[10]相似,在Object Counting上比DSPy提高了7%。虽然上下文中的8个示例可以帮助引导LLM的行为,但可能会增加推理成本。有趣的是,DSPy优化器和TEXTGRAD进行了互补的调整——前者增加了上下文中的示例,后者优化了系统提示。将DSPy选择的示例添加到TEXTGRAD的优化提示中,可以进一步提高性能(对于GSM8k,直接将DSPy的示例与TextGrad的指令结合起来,可以将准确率提高到82.1%),这表明将这两种方法结合起来是一个有益的方向。
3.4 分子优化
TEXTGRAD支持各种优化问题,包括科学和工程应用中常见的多目标优化任务。例如,在药物发现中,研究人员寻求发现或设计分子,以最大化与合成性、功效和安全性相关的多种目标[53, 54]。为了展示TEXTGRAD在多目标优化中的应用,我们将TEXTGRAD应用于药物分子优化,并展示我们的框架如何与计算工具接口,优化化学结构,同时提高其结合亲和力和药物样性。
任务:潜在药物分子的一个关键考虑因素是其结合亲和力,这代表分子与其蛋白质靶标的相互作用强度。药物设计者寻求具有高结合亲和力的分子,因为它们需要较低和较少的剂量就能达到疗效。这种亲和力可以通过自由能量ΔG来量化,它描述了结合配体-受体对的概率比。ΔG可以通过蛋白质-配体结合的“对接”模拟来估计[55, 56]。在我们的实验中,我们采用了Autodock Vina工具的Vina分数,这是一种广泛使用的基于物理的对接模拟器[57]。Vina分数越负,药物与其预期靶标结合的可能性越大。潜在的药物分子还通过其药物样性来评估,这估计了分子在体内的行为,包括溶解度、渗透性、代谢稳定性和转运体效应。具有高药物样性的分子更有可能被身体吸收并到达其靶标[58]。“药物样性”的一个流行度量是定量估计药物样性(QED)分数,这是一个重要化学特性的加权复合度量,如分子量、亲脂性、极性表面积等。QED分数范围从0到1,其中1表示高药物样性[59]。尽管成功分子还有更多的考虑因素,在我们的实验中,由于这两个度量的相对成熟度,我们限制我们的目标是最小化Vina分数和最大化QED。
方法:我们通过将分子编码为SMILES字符串,并从Vina和QED分数构建多目标损失,将TEXTGRAD应用于药物分子优化。即我们对SMILES字符串进行实例优化,使用TEXTGRAD生成的梯度相对于多目标损失来更新表示分子的文本。
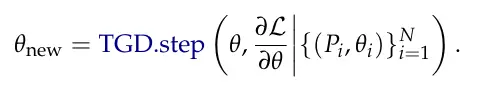
我们使用gpt-4o作为我们的LLM,并使用附录F.2中找到的提示文本。在每次迭代中,通过使用Autodock Vina的Vina分数评估当前分子与目标蛋白的结合亲和力,并使用RDKit的QED分数评估药物样性(附录F.1)。每个分子都从一个官能团的小化学片段初始化。我们对DOCKSTRING分子评估基准[61]中的所有58个目标应用TEXTGRAD进行优化。这些58个目标包括来自各种结构类别的临床相关蛋白,其中29个有临床批准的药物。对于每个目标,我们使用TEXTGRAD优化了3个独特的初始片段,每个片段进行10次迭代。为了评估我们的表现,我们将TEXTGRAD生成的分子与各自蛋白的临床批准药物的特性进行比较(附录F.3)。
结果:对于所有58个目标,TEXTGRAD始终生成具有改善的结合亲和力和药物样性的分子,无论初始片段如何(附录F.4)。对于有临床批准药物的29个蛋白靶标,我们观察到TEXTGRAD生成的分子与使用相同损失函数评估的临床分子相比,具有高度竞争的亲和力和药物样性(图2(b))。生成的分子与其临床批准的对应物和现有化合物相比,展现出独特的结构(附录F.5),同时保持相似的in silico安全概况(附录F.6)。虽然存在替代的机器学习方法用于de novo分子生成,但TEXTGRAD提供了两个关键优势:
通过结合传统化学信息学工具和LLMs的一般知识和推理能力,TEXTGRAD即使没有预先训练的数据集也能产生竞争性的结果。
TEXTGRAD的自然语言梯度框架产生可解释的决策,使研究人员能够准确理解分子结构是如何以及为什么构建的。
这些特性共同预示着AI智能体在科学发现中的作用有一个充满希望的未来。
3.5 放射治疗计划优化
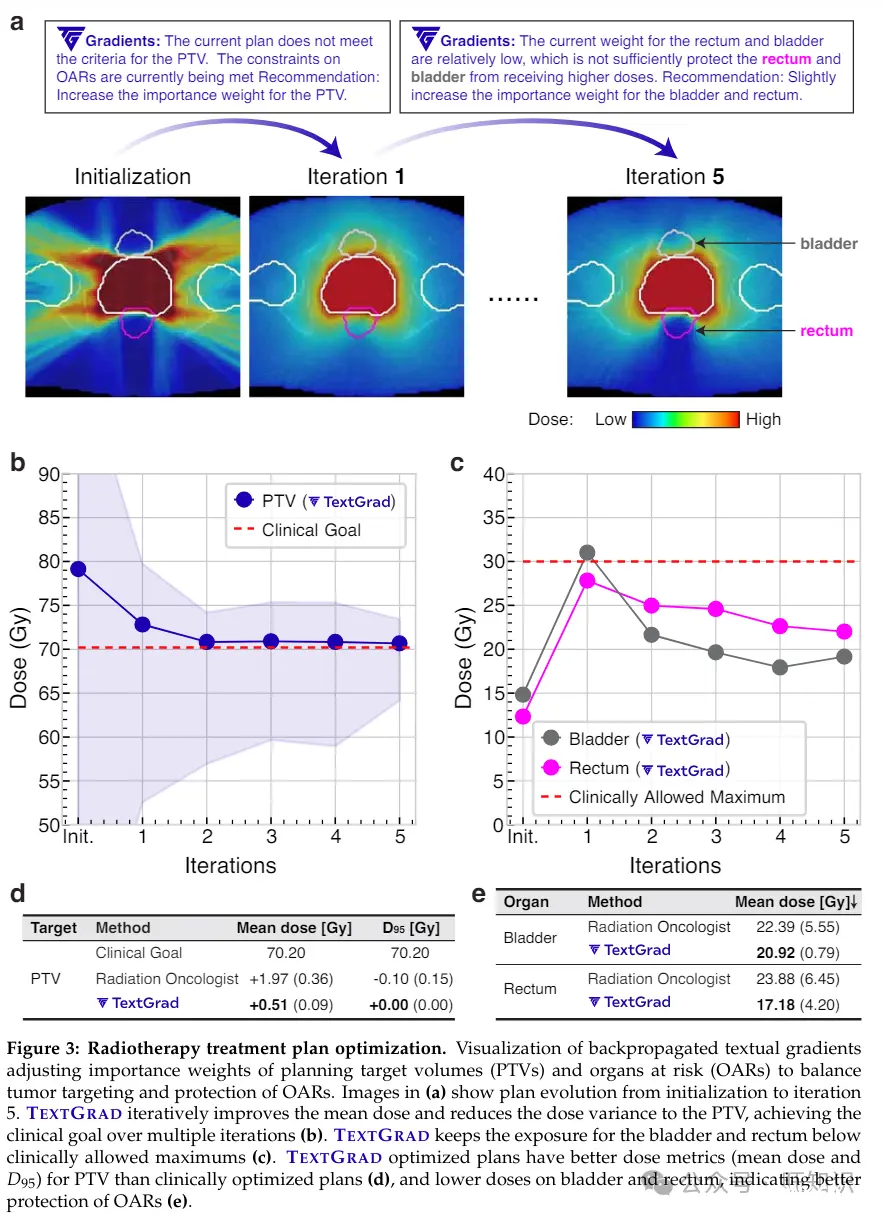
放射治疗,也称为放疗,是一种使用强烈能量束(如X射线)来杀死癌细胞的癌症治疗方法。在治疗开始之前,包括放射肿瘤学家和规划者在内的放射治疗团队会合作设计一个有效的治疗计划。这涉及到确定必要的放射剂量,并准确找出需要治疗的确切位置。放射治疗计划可以被制定为一个双层优化问题。内层,称为逆向计划,包括诸如影响图优化和直接孔径优化等过程[62]。这个优化问题通常是一个受约束的问题,通过数值优化器解决,目标是最小化加权成本函数,平衡多个相互冲突的目标[63]。这些目标包括向计划目标体积(PTV)输送规定的剂量,PTV包括肿瘤和额外的边界,以考虑计划或治疗交付中的不确定性,同时保护关键的正常组织,即风险器官(OARs),避免接受不安全的剂量。治疗计划中的主要挑战是将总体临床目标转化为加权目标函数和剂量约束,以产生一个可接受的计划[62]。人类规划者通常使用试错方法,根据优化过程的结果迭代调整优化超参数,直到计划满足临床要求[62]。这些超参数包括目标函数中分配给PTV、器官和其他组织的权重。这个过程可能是主观的,受规划者经验和可用时间的影响,并且涉及多次使用计算成本高昂的优化算法进行迭代。这使得过程效率低下、耗时且成本高昂[64]。
方法:我们应用TEXTGRAD执行外层优化,即内层数值优化器的超参数优化。实例优化是通过gpt-4o对表示为字符串的超参数进行的:θ = "PTV的权重:[PTV WEIGHT],膀胱的权重:[BLADDER WEIGHT],直肠的权重:[RECTUM WEIGHT],股骨头的权重:[FH WEIGHT],身体的权重:[BODY WEIGHT]"。当提供超参数时,我们通过采用数值优化器并构建损失函数作为当前计划与临床目标之间的不匹配来获得治疗计划。具体来说,为了计算梯度,我们首先使用数值优化器matRad[65]解决内优化循环,以获得相应的治疗计划P(θ) = matRad(θ)。损失是使用LLM计算的。

新的超参数是通过TextGrad下降步骤获得的:

为了进一步提高LLM理解超参数θ与由matRad产生的计划P之间关系的能力,一组配对计划及其相应的超参数{(Pi, θi)}Ni=1在TGD.step期间作为上下文提供给LLMs。因此,


评估指标:由于无法使用单一指标评估治疗计划,我们采用了几种常用的剂量指标来评估治疗计划。我们考虑了送达目标/器官体积的平均剂量,以及Dq,它表示目标/器官体积的q%接收到的最小剂量。
结果:TEXTGRAD生成的梯度为改善超参数提供了有意义的指导。如图3所示,当剂量溢出到计划目标体积(PTV)外面时,梯度建议增加PTV的重要性权重。这种调整导致PTV的剂量更均匀、更局限。然而,这可能导致膀胱和直肠的保护不足,因为它们的相对权重降低了。因此,在接下来的步骤中,梯度建议稍微增加膀胱和直肠的权重,从而更好地保护这些器官。我们比较了TEXTGRAD优化的计划与用于治疗五名前列腺癌患者的临床计划。在图3(c)中,我们评估了TextGrad实现PTV区域临床目标的能力。TextGrad在所有指标上都优于临床计划,实现了更高的平均剂量,并且D95完全符合规定剂量。在图3(d)中,我们专注于保护健康器官。TextGrad优化的计划在这些健康器官上实现了更低的平均剂量,表明比人类优化的计划更好地保护了器官。我们报告了五个计划的平均值,并在括号中包含了标准差。
4 相关工作
有一条相关工作线索研究了提示优化问题。实践者证明,如智能选择少数样本例子和上下文学习、CoT、集成等提示工程策略可以显著提高LLMs的性能[66]。为了自动化这个过程,开发了一些利用数值梯度的白盒方法来优化提示[67-70],然而,这些方法不能用于封闭源模型,因为它们需要访问模型参数。有各种工作研究了使用LLMs作为提示优化器[12, 25, 71]。在提示优化下,有两项工作最接近我们的理念,它们启发了我们。首先,DSPy[10, 72, 73]开创了将复杂的基于LLM的系统视为具有可能许多层的程序的观点,并提出了以编程方式构建和优化它们的方法。该框架是广泛的,结果在各种问答、推理和提示优化任务中提高了LLM的性能。我们的工作采取了不同的视角,即反向传播及其扩展可以是一个通用且强大的框架,用于优化新一代AI系统,并在提示优化任务之外执行多项任务。特别是,我们不仅将指令或示例作为要优化的变量,还包括我们关心的实例本身——如分子、治疗计划、代码片段等。其次,非常启发我们的是,使用文本梯度的提示优化(ProTeGi)[25]在提示优化的背景下定义了文本梯度,其中梯度是LLM在任务期间犯错误时给出的自然语言反馈。虽然ProTeGi建立在文本梯度类比上,我们更广泛地扩展了这个类比到自动微分,并大大超出了提示优化任务。特别是,DSPy和ProTeGi专注于提示优化,而TEXTGRAD的一个显著进步,正如我们通过多样化的应用所展示的,是在实例优化中。更一般地说,有一条新兴的工作线建立在将LLMs作为评论家或优化器的高级理念上[10, 12, 25, 26, 30, 71, 74-80]。虽然许多早期框架证明了LLMs作为优化器的效用,我们提出了一个单一且通用的框架,已在各种应用中成功测试。在这个框架内,我们可以将优化链或堆栈的LLMs视为一个整体[81-83]:我们传播自然语言反馈。同样,一旦被视为通用优化引擎,我们可以将许多相关问题表述为框架中的几行代码,例如测试时训练[42, 43]或解决方案的自我改进和自我提升[26, 30, 44, 84-91]。建立在优化类比上,我们已经转移了传统优化文献中的几个类比,如通过使用早期迭代在上下文中使用动量[40],使用批量优化[92],使用自然语言约束的约束优化[35]等。我们的工作为设计新一代优化算法开辟了广阔的空间,所有这些都在同一个框架内。
5 讨论
TextGrad 建立在三个关键原则之上:i) 它是一个通用且高性能的框架,不是为特定应用领域手工制作的;ii) 它易于使用,反映了 PyTorch 抽象,从而允许知识转移;iii) 它是完全开源的。通过 TEXTGRAD,我们在代码优化和博士级问答中取得了最先进的结果,优化了提示,并在科学应用中提供了概念验证结果,例如开发分子和优化治疗计划。虽然我们已经迈出了第一步,但存在各种限制,激发了未来的工作,以实现由 LLMs 驱动的自动微分框架的潜力。首先,虽然我们展示了通过文本反馈进行反向传播的潜力,但我们的框架可以扩展到许多应用。我们希望 TEXTGRAD 可以用来加速科学发现中的迭代过程,并提高工程努力的生产力。例如,为了实现这一点,我们希望能够扩展我们的计算图中的操作,以包括在实际 LLM 应用中使用的更多组件,如工具使用[83]或检索增强型生成系统[93]。第二,自动微分类比为算法设计提供了巨大的空间。我们相信,在数值优化、自动微分和 TEXTGRAD 之间有许多有益的联系。特别是,使用方差减少技术[94]、自适应梯度[95]或使用 LLMs 进行自我验证[96]来增加优化的稳定性是有趣的联系。使用方法如 TEXTGRAD 本身来优化 TextGrad 框架的元学习方法[97-99]也是未来工作的一个有趣方向。最后,虽然我们对 TEXTGRAD 进行了概念验证应用,以设计新分子和治疗计划,并进行了 in silico 验证,但最终的测试需要实验和临床评估,这超出了本文的范围。随着 AI 的范式从训练单个模型转变为优化涉及多个交互 LLM 组件和工具的复合系统,我们需要新一代的自动化优化器。TEXTGRAD 结合了 LLMs 的推理能力以及反向传播的可分解效率,创建了一个通用框架来优化 AI 系统。

作者:张长旺,图源:旺知识
参考资料
标题:Automatic “Differentiation” via Text
作者:Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, James Zou
单位:Stanford University, Chan Zuckerberg Biohub
链接:https://arxiv.org/pdf/2406.07496v1
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。