AI 系统全栈架构 什么是 AI 系统 CPU、GPU、FPGA、ASIC PyTorch、MindSpore 系统设计目标 高效编程语言、开发框架和工具链 系统设计、实现和演化
EwenWanW 2024-07-27 10:01:03 阅读 93
AI 系统全栈架构
通过对 AI 的发展、以及模型算法、硬件与数据的趋势介绍,我们已经了解了 AI 系统的重要性。本章将介 AI 系统的设计目标,组成和生态,让读者形成人工智能系统的知识体系,为后续展开每个章节的内容做好铺垫。
AI 系统设计本身需要各个环节通盘考量,无论是系统性能,还是用户体验,亦或是稳定性等指标,甚至在开源如火如荼发展的今天,开源社区运营也成为 AI 系统推广本身不可忽视的环节。接下来将从不同的维度和技术层面展开 AI 系统的全景图。
AI 系统的全栈架构是一个复杂且多维度的概念,它涵盖了从底层硬件、数据预处理、模型训练与部署,到上层应用与交互的整个过程。设计一个高效的 AI 系统需要考虑多个方面,包括性能、稳定性、用户体验以及开源社区运营等。下面将从不同的维度和技术层面来展开 AI 系统的全景图。
一、设计目标
AI 系统的设计目标通常包括以下几个方面:
高效性:系统应能够快速处理大量数据,并实时或准实时地给出结果。
准确性:AI 模型应具有较高的预测或分类精度,以满足实际应用需求。
稳定性:系统应能够稳定运行,避免因硬件故障、数据异常等原因导致的崩溃或性能下降。
易用性:系统应提供友好的用户界面和交互方式,降低用户的使用门槛。
可扩展性:系统应能够支持模型的升级和扩展,以适应不断变化的业务需求。
二、系统组成
AI 系统的全栈架构通常包括以下几个组成部分:
硬件层:包括计算设备(如 CPU、GPU、FPGA)、存储设备(如硬盘、内存)和网络设备等。这些硬件为 AI 系统的运行提供了基础支撑。
数据层:负责数据的收集、存储、预处理和标注等工作。数据的质量和数量对 AI 模型的性能具有重要影响。
算法层:包括各种机器学习算法和深度学习框架,用于构建和训练 AI 模型。
模型层:存储和管理训练好的 AI 模型,以及提供模型推理服务。
应用层:将 AI 模型集成到具体的应用场景中,为用户提供智能化的服务。
三、生态考虑
除了技术层面的考虑外,AI 系统的设计还需要关注生态系统的发展。这包括:
开源社区:积极参与开源项目,贡献代码和文档,与社区成员共享知识和经验。
合作伙伴:与硬件供应商、数据提供商、算法开发者等建立合作关系,共同推动 AI 技术的发展和应用。
用户反馈:关注用户的使用体验和反馈,不断优化系统功能和性能。
四、技术层面
从技术层面来看,AI 系统的全栈架构涉及多个关键技术:
分布式计算:利用多台计算设备协同工作,提高数据处理和模型训练的速度。
自动化运维:通过监控、预警和自动恢复等功能,降低系统的维护成本和风险。
模型压缩与优化:通过剪枝、量化等手段减小模型体积,提高推理速度,降低部署成本。
安全与隐私保护:采用加密、差分隐私等技术保护用户数据的安全和隐私。
五、总结
AI 系统的全栈架构是一个综合性的概念,涉及多个维度和技术层面。设计一个优秀的 AI 系统需要通盘考虑各个环节,确保系统的高效性、准确性、稳定性、易用性和可扩展性。同时,还需要关注生态系统的建设和开源社区的发展,与合作伙伴和用户共同推动 AI 技术的进步和应用。
什么是 AI 系统
AI系统是一个集成了硬件、软件和数据,用于执行人工智能任务的复杂系统。它涵盖了从数据收集、预处理、模型训练、推理到最终应用部署的整个过程。AI系统的核心在于通过机器学习算法和深度学习模型,使计算机能够模拟人类的智能行为,从而实现自主决策、推理和识别等任务。
AI系统通常包含以下几个关键组成部分:
硬件层
包括高性能计算设备(如CPU、GPU、FPGA、ASIC等)、存储设备(如硬盘、内存)和网络设备等。这些硬件为AI系统的运行提供了必要的计算能力和数据存储能力。
数据层
涉及数据的收集、清洗、标注和存储。数据是AI模型训练的基础,其质量和数量对模型的性能具有重要影响。
算法层
包括各种机器学习算法和深度学习框架。这些算法和框架用于构建和训练AI模型,使其能够学习数据的特征和规律。
模型层
存储和管理训练好的AI模型。模型是AI系统的核心,它根据输入数据进行推理和预测。
应用层
将AI模型集成到实际的应用场景中,如自动驾驶、语音识别、图像识别、自然语言处理等。
AI系统的设计和开发是一个复杂的过程,需要综合考虑多个因素,如性能、稳定性、易用性、安全性等。同时,随着AI技术的不断发展,AI系统也在不断演进和优化,以适应更广泛的应用场景和更复杂的任务需求。
目前,开源社区中涌现出了许多针对特定应用领域而设计的框架和工具,这些工具和框架为开发者提供了更简化的接口和应用体验,加速了AI技术的研发和应用。同时,硬件厂商也在围绕AI技术设计专用的AI芯片和加速模块,以提供更强大的计算能力和更高的能效比。
开发者一般通过编程语言 Python 和 AI 开发框架(例如 PyTorch、MindSpore 等)API 编码和描述以上 AI 模型,声明训练作业和部署模型流程。由最开始 AlexNet 是作者直接通过 CUDA 实现网络模型,到目前有通过 Python 语言灵活和轻松调用的框架,到大家习惯使用 HuggingFace 进行神经网络语言模型训练,背后是系统工程师贴合实际需求不断研发新的工具,并推动深度学习生产力提升的结果。
但是这些 AI 编程语言和 AI 开发框架应对自动化机器学习、强化学习等多样执行方式,以及细分的应用场景显得越来越开发低效,不够灵活,需要用户自定义一些特殊优化,没有好的工具和系统的支撑,这些问题一定程度上会拖慢和阻碍算法工程师研发效率,影响算法本身的发展。因此,目前开源社区中也不断涌现针对特定应用领域而设计的框架和工具,例如 Hugging Face 语言预训练模型动物园和社区,FairSeq 自然语言处理中的序列到序列模型套机,MMDetection 物体检测套件,针对自动化机器学习设计的 NNI 加速库等,进而针对特定领域模型应用负载进行定制化设计和性能优化,并提供更简化的接口和应用体验。
由于不同领域的输入数据格式不同,预测输出结果不同,数据获取方式不同,造成模型结构和训练方式产生非常多样的需求,各家公司和组织不断研发新的针对特定领域的 AI 开发框架或上层应用接口封装,以支持特定领域数据科学家快速验证和实现新的 AI 想法,工程化部署和批量训练成熟的模型。如 Facebook 推出的 Caffe 与 Torch 演化到 PyTorch,Google TensorFlow 及新推出的 JAX,基于 PyTorch 构建的 HuggingFace 等。AI 开发工具与 AI 开发框架本身也是随着用户的模型构建与程序编写与部署需求不断演进。
这其中快速获取用户的原因,有一些是其提供了针对应用场景非常简化的模型操作,并提供模型中心快速微调相应的模型,有一些是因为其能支持大规模模型训练或者有特定领域模型结构的系统优化。
AI 系统自身设计挑战较高(如更大的规模、更大的超参数搜索空间、更复杂的模型结构设计),人工智能的代表性开发框架 PyTorch 是 Facebook 开发,后续贡献给 Linux 开源基金会;TensorFlow 是谷歌(Google)从 2016 年开源;华为(HUAWEI)为了避免美国全面封锁 AI 领域推出自研的 AI 框架 MindSpore。
硬件厂商围绕其设计了大量的专有 AI 芯片(如 GPU、TPU、NPU 等)来加速 AI 算法的训练微调和部署推理,微软(Microsoft)、亚马逊(Amazon)、特斯拉(Tesla)等公司早已部署数以万计的 GPU 用于 AI 模型的训练,OpenAI 等公司不断挑战更大规模的分布式模型训练。
英伟达(NVIDIA)、华为(HUAWEI)、英特尔(Intel)、谷歌(Google)等公司不断根据 AI 模型特点设计新的 AI 加速器芯片和对应的 AI 加速模块,如张量核 Tensor Core、脉动阵列等提供更大算力 AI 加速器。
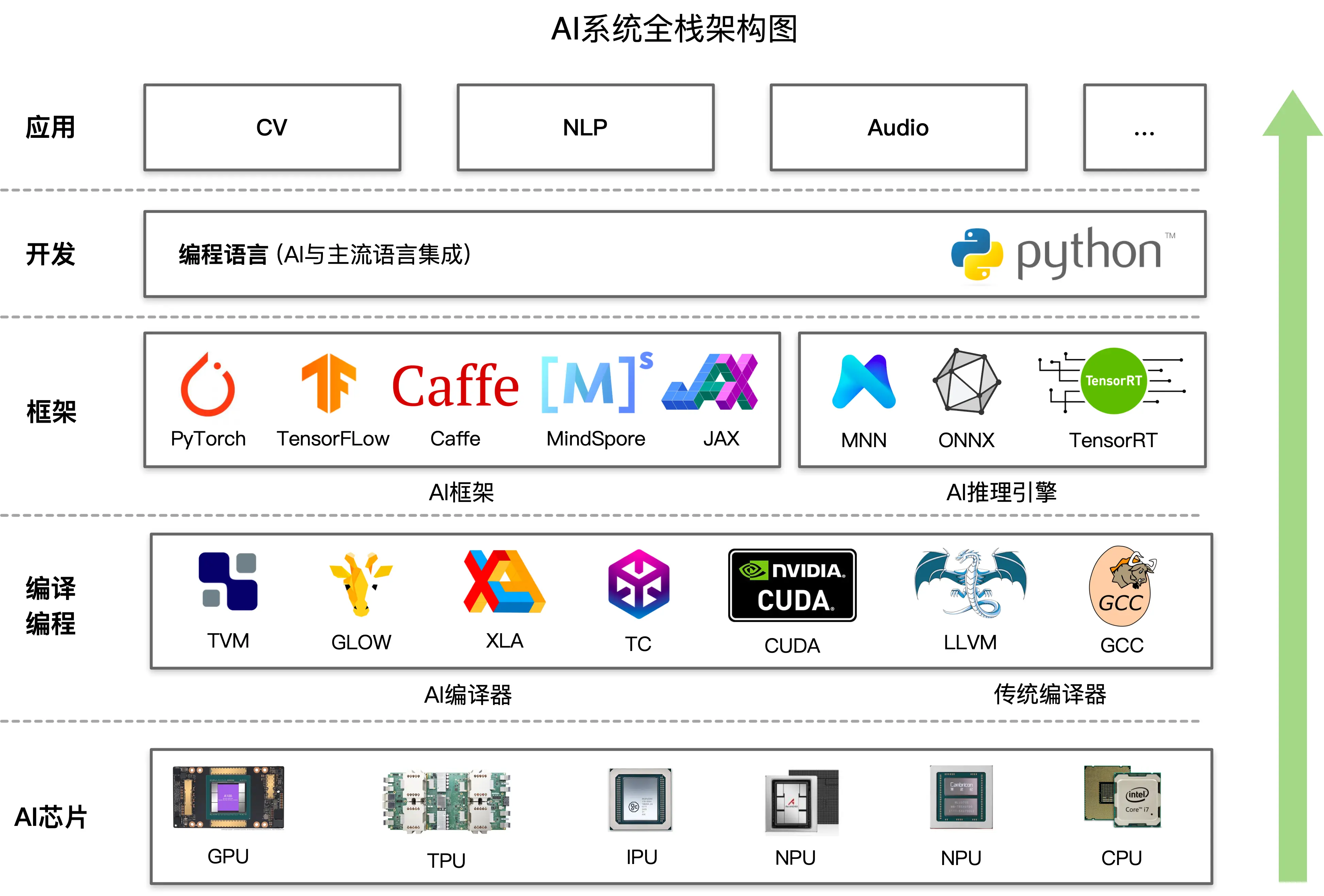
上述从上层应用、开发框架到底层应用所介绍的 AI 全栈相关内容中则是指 人工智能系统(AI System),是围绕深度学习而衍生和设计的系统,因此也叫做深度学习系统(Deep Learning System)。
但是 AI 系统很多也可以应用于机器学习算法或使用机器学习算法,例如,自动化机器学习,集群管理系统等。同时这些系统设计方法具有一定的通用性,有些继承自机器学习系统或者可以借鉴用于机器学习系统。即使作为系统工程师,也需要密切关注算法和应用的演进,才能紧跟潮流设计出贴合应用实际的工具与系统。
AI系统的设计和实现需要考虑多个层面,从底层硬件到上层应用,每个部分都需要精心设计和优化。系统工程师需要紧密关注算法和应用的发展,以确保他们的设计能够跟上时代的步伐,满足不断变化的需求。
此外,AI系统在设计上具有一定的通用性。尽管深度学习系统可能具有一些特定的优化和特性,但许多设计原则和方法也可以应用于更广泛的机器学习系统。这种通用性使得系统工程师能够借鉴和利用不同领域的经验和技术&#
上一篇: AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
下一篇: 手把手YOLOv5输出热力图
本文标签
AI 系统全栈架构 什么是 AI 系统 CPU、GPU、FPGA、ASIC PyTorch、MindSpore 系统设计目标 高效编程语言、开发框架和工具链 系统设计、实现和演化
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。