最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答...

本文讲述了高效微调技术QLoRA训练LLaMA大模型并讲述了如何进行推理。_qlora微调...
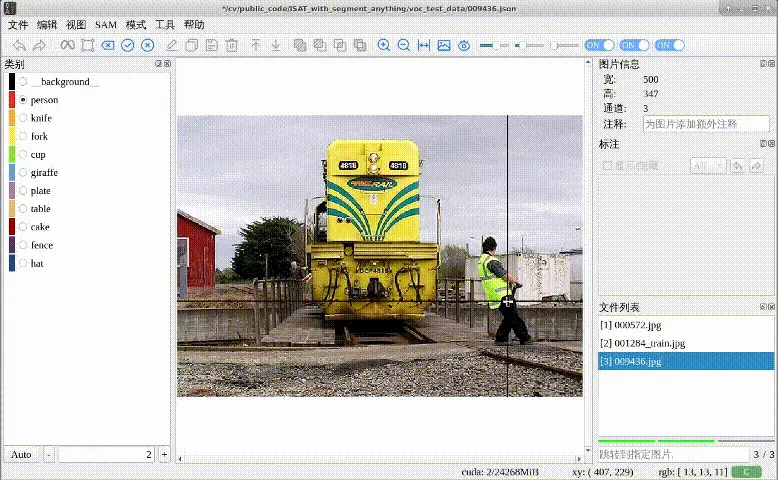
SAM初步理解,简单介绍模型框架,不涉及细节和代码SAM细节理解,对各模块结合代码进一步分析SAM微调实例,原始代码涉及隐私,此部分使用公开的VOC2007数据集,Point和Box作为提示进行maskdeco...
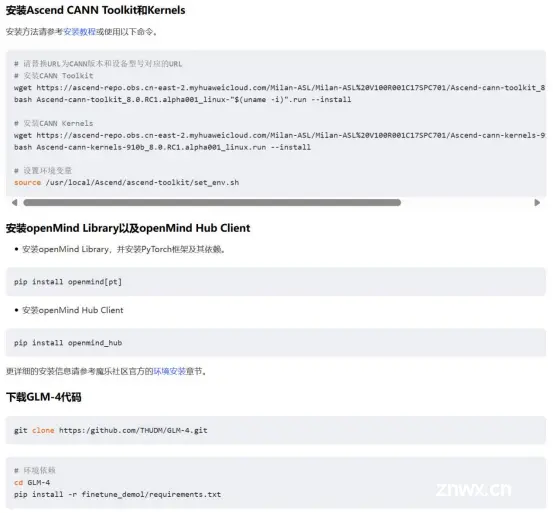
GLM-4V-9B是智谱AI推出的最新一代预训练模型GLM-4系列中的开源多模态版本。。它不仅具备高分辨率(1120*1120)下的中英双语多轮对话能力,更在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,展现出超越GPT-4-turbo-2...
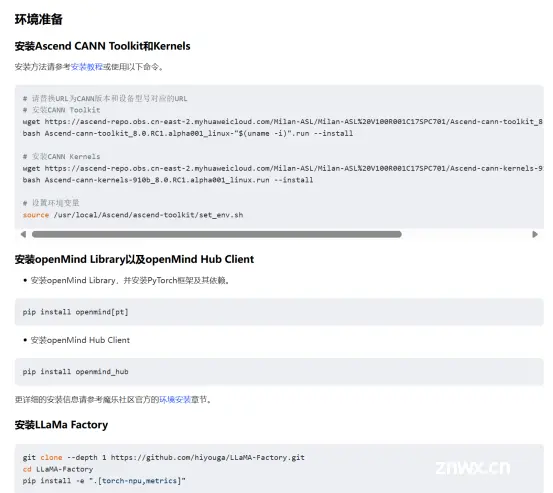
在2024年的AI领域,Meta发布的Llama3.1模型无疑成为了研究者和开发者的新宠。我有幸通过魔乐社区提供的资源,对这一模型进行了深入的学习和实践。在这个过程中,魔乐社区的资源和支持给我留下了深刻的印象。...
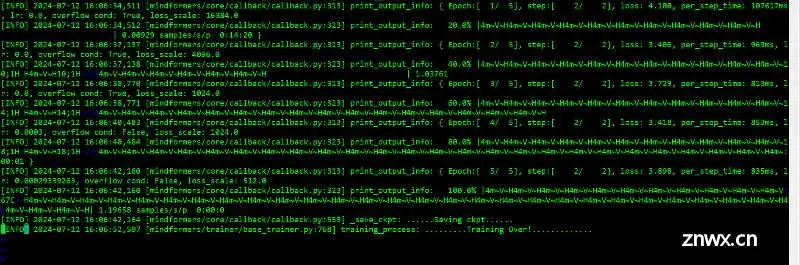
基于Mindformers+mindspore框架在昇腾910上进行qwen-7b-chat的8卡lora微调主要参考文档:https://gitee.com/mindspore/mindformers/tree/r1.0/research/qwe...
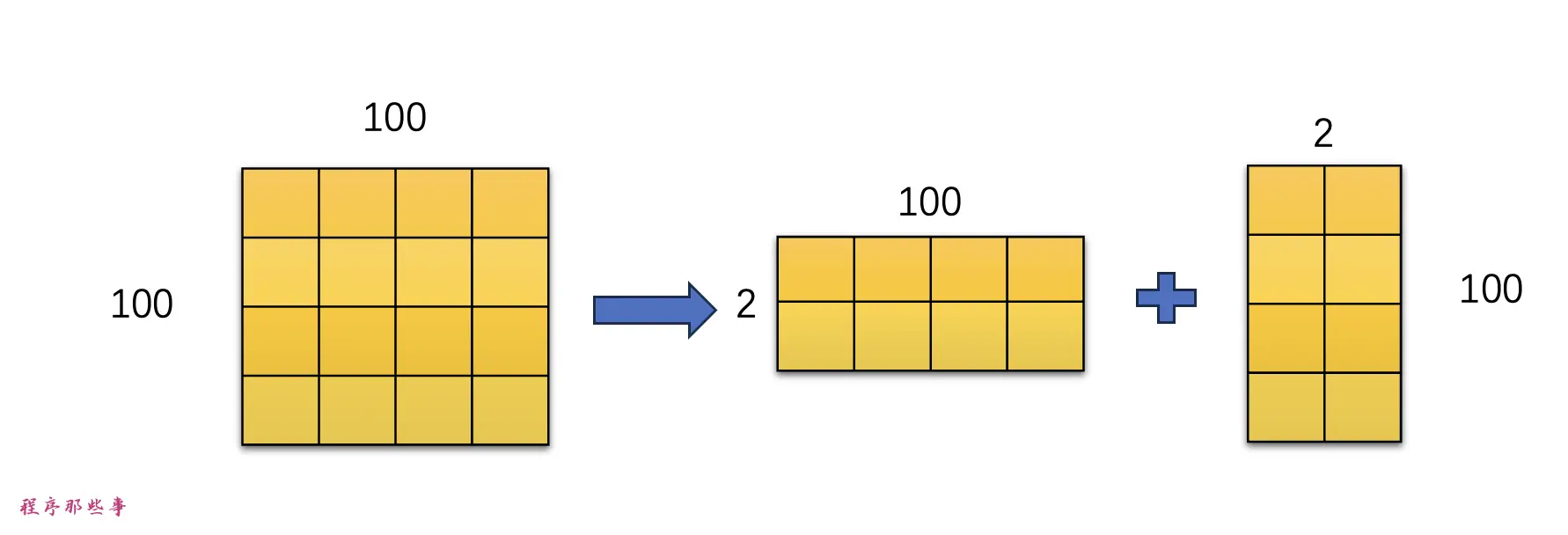
LoRA模型是小型的StableDiffusion模型,它们对checkpoint模型进行微小的调整。它们的体积通常是检查点模型的10到100分之一。因为体积小,效果好,所以lora模型的使用程度比较高。...
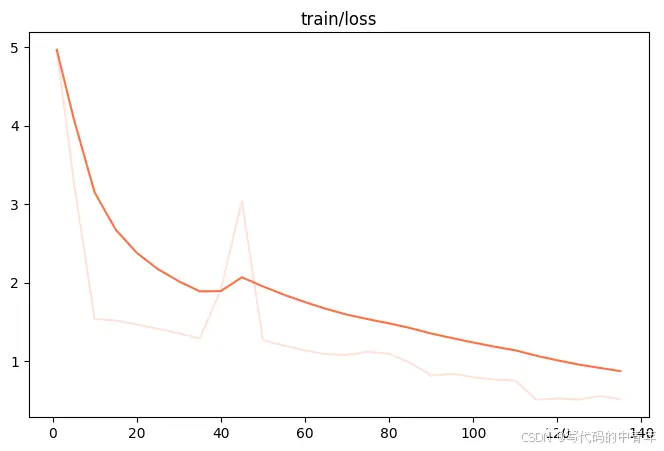
目标检测任务已经不是一个新鲜事了,但是多模态大模型作目标检测任务并不多见,本文详细记录swfit微调interVL2-8B多模态大模型进行目标检测的过程,旨在让更多人了解多模态大模型微调技术、共享微调经验。实际上...

大模型领域既是繁星点点的未知宇宙,也是蕴含无数可能的广阔天地,正是这一独特的魅力,令无数的探索者为之倾倒,为之奋斗。随着大模型应用逐渐走入人们的日常生活,支撑它的深度学习技术也开始登上更为广阔和深远的人工智能大...
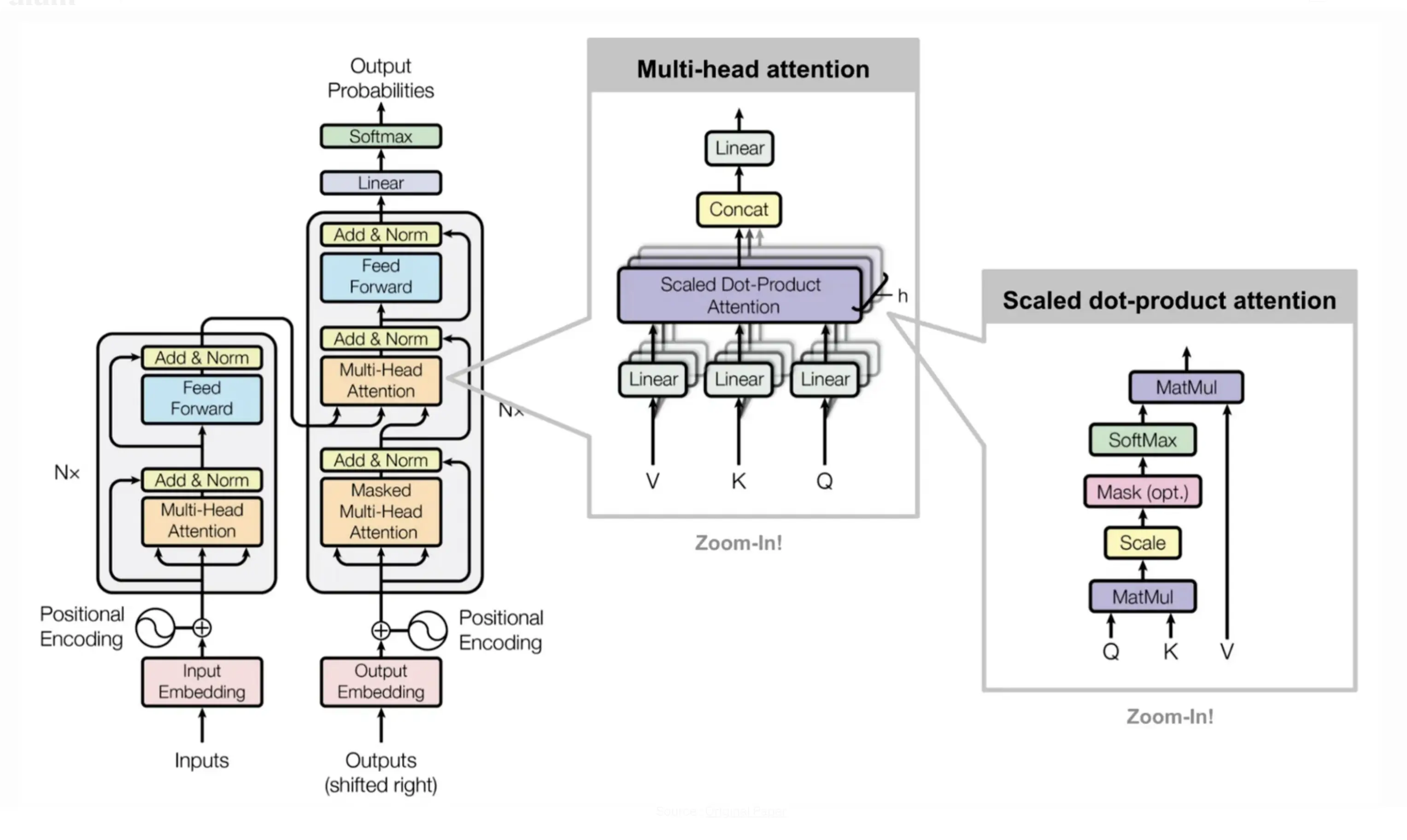
随着人工智能在自然语言处理(NLP)领域的快速发展,对大规模预训练模型的需求日益增长。这些大型模型不仅需要具备广泛的语言理解能力,还需要能适应各种下游任务需求。传统上,针对特定任务训练的较小模型往往无法达到所需的...