
环境搭建系统环境需要Nvidia显卡,至少8G显存,且专用显存与共享显存之和大于20G建议将非安装版的环境文件都放到非系统盘,方便重装或移植以Windows11为例,非安装环境文件都放在E盘下设置自定义Path文件夹创建E:\mypath文...

在实际应用中,结合不同的向量存储和自定义节点处理,可以实现更复杂和精细的检索需求。向量存储(VectorStores)是检索增强生成(RAG)的关键组件,因此你几乎会在使用LlamaIndex构建的每个应用程序中直...
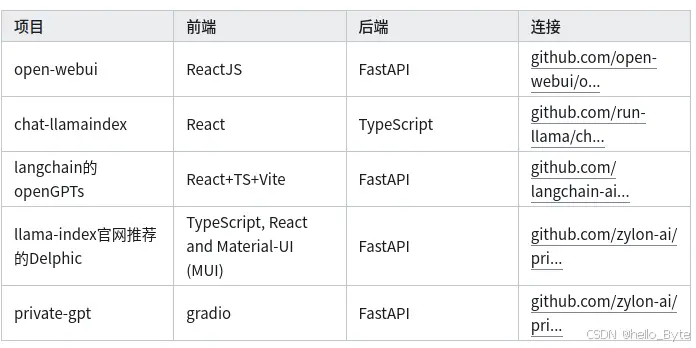
业余兴趣,部署下最近很火的LLM大模型玩玩,现在市面做这种大模型部署的快速应用还是挺多的,比如下面这些。这里介绍采用nvidiagpu,基于ubuntudocker环境下的open-webui+ollam...

Ollama是一款用于本地运行大语言模型的工具,支持对LLM模型进行管理、训练和推理。通过Ollama,用户可以在本地机器上运行GPT-4、BERT等模型,并利用Ollama提供的Web界面或...

等,进一步支撑你的行动,以提升本文的帮助力。_crewai...

简介如何用ollama在linux部署大模型_linux离线安装ollama...

本文主要分享如何在群晖NAS本地部署并运行一个基于大语言模型Llama2的个人本地聊天机器人并结合内网穿透工具发布到公网远程访问。本地部署对设备配置要求高一些,如果想要拥有比较好的体验,可以使用高配置的服务器设...
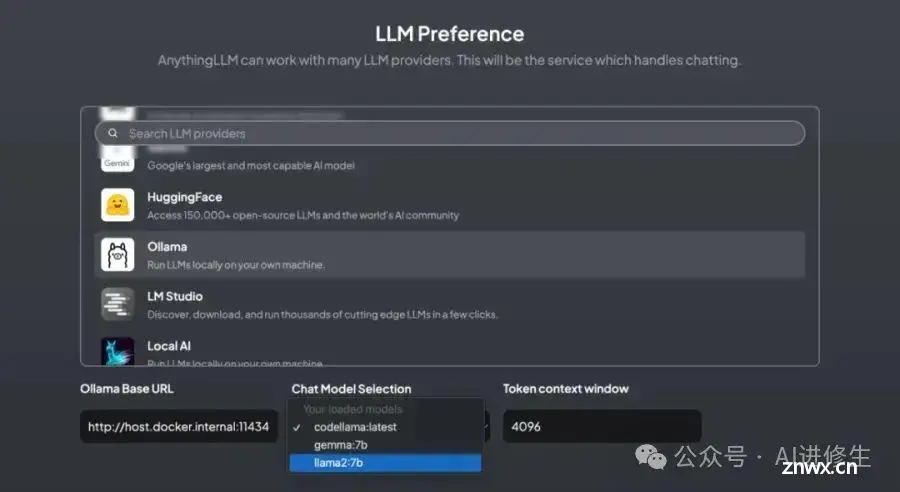
本地运行大模型耗资源,需要选择较小的模型作为基础模型。在终端中运行时可能会出现CUDA错误,表示显存不足,导致提供的端口失效。中文支持不够完善。\\3.文中提到的技术软件工具有:Ollama、Chatbox...

python调用ollama库详解,包含:准备Ollama软件、准备ollama库ollama库的基本使用ollama库的进阶使用:options参数设置、返回的json对象处理_pythonollama...

Ollama是一个基于Python的工具,专为本地调用大型语言模型而设计。它提供了用户友好的接口,使开发者能够在本地环境中快速加载和管理模型,简化了大模型的集成与使用流程。Ollama适用于各种应用场景,...