
高通的AIHub是一个全新的AI模型库,专为搭载骁龙和高通平台的终端设备提供优化的AI模型。这些模型经过验证,可在不同执行环境中部署,实现卓越的终端侧AI性能、降低内存占用并提高能效。本文将介绍如何...
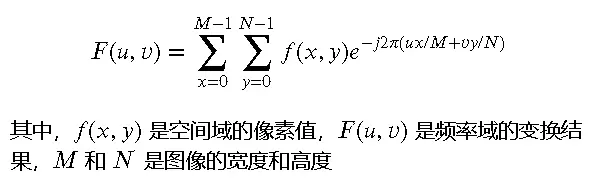
图像增强方法在数字图像处理中占有重要地位,它能够有效提高图像的视觉效果,增强图像的细节信息,从而在医学、遥感、工业检测等多个领域发挥重要作用1.空间域增强方法空间域增强方法是通过直接对图像像素进行操作来实现图像增强的技术。以下是几种常见的空间域增强方法:...

在本文中,我们深入探讨了图像分类技术的发展历程、核心技术、实际代码实现以及通过MNIST和CIFAR-10数据集的案例实战。文章不仅提供了技术细节和实际操作的指南,还展望了图像分类技术未来的发展趋势和挑战。_人工...

StableDiffusion3的强大性能其实并不仅限于DiffusionTransformer在架构上所带来的增益,其在提示词、图像质量、文字拼写方面的能力都得到了极大的提升。...
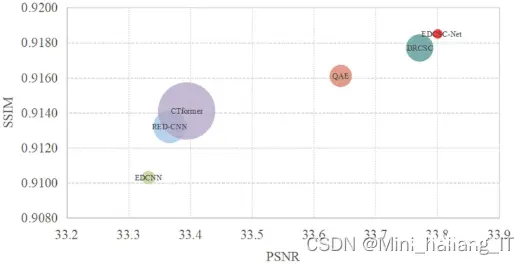
毕业设计:基于深度学习的图像去噪算法通过深度学习模型的训练和优化,能够准确还原图像的真实信息,并有效去除图像中的噪声。本研究为计算机毕业设计提供了一个创新的方向,结合了深度学习和计算机视觉技术,为毕业生提供了一个...
通过本教程,我们学习了如何使用JavaScript和Transformers库来实现图像对象检测的功能。我们使用了一个预训练的对象检测模型,并将其集成到网页中,通过简单的上传图片操作就能实现对象检测,并在图...
本文介绍了基于深度学习的全景图像拼接系统,涉及神经网络特别是卷积神经网络的应用,包括特征提取、图像配准、特征匹配模型,以及实验环境搭建和模型训练。通过SIFT和深度可分离卷积等技术提升拼接精度和效率。...

从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。每一个案例都附带关键代码,详细讲解供大家学习,希望可以帮到大家。正在不断更新中~_aigc图像生成通常采用以下哪...
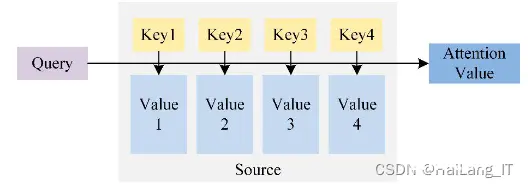
模态编码器(ModalityEncoder,ME):负责将不同模态的输入编码成特征。常见的编码器包括图像的NFNet-F6、ViT、CLIPViT等,音频的Whisper、CLAP等,视频编码器等。输入投影...

labelme是使用python写的基于QT的跨平台图像标注工具,可用来标注分类、检测、分割、关键点等常见的视觉任务,支持VOC格式和COCO等的导出,代码简单易读,是非常利用上手的良心工具。(2)在labelme...