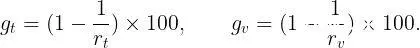
让我们简要回顾一下深度神经网络中BatchNorm的基本概念。这个想法最初是由Ioffe和Szegedy在一篇论文中引入的,作为加速卷积神经网络训练的一种方法。假设zᵃᵢ表示深度神经网络给定层的输入,其中a是从a=...
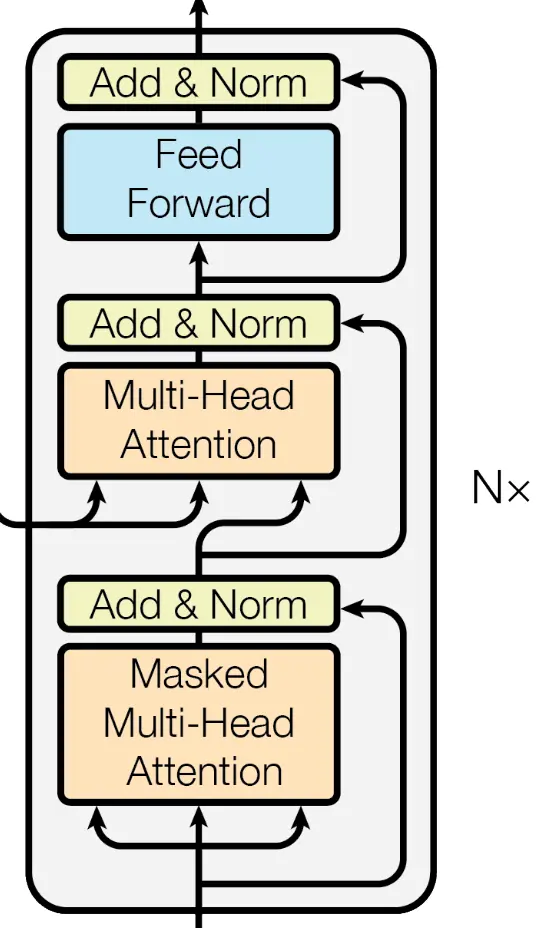
Transformer是一个经典的编码解码结构,编码器decoder负责编码,解码器encoder负责解码。Transformer是基于seq2seq的架构,提出时被用在机器翻译任务上,后面变种SwinTran...

本文介绍了Transformer模型推理性能优化技术KVCache,通过缓存Self-Attention和Cross-Attention中的键值对,减少重复计算,提升解码速度。在大模型如GPT中,KVCache能有效减少计算量,尤其...
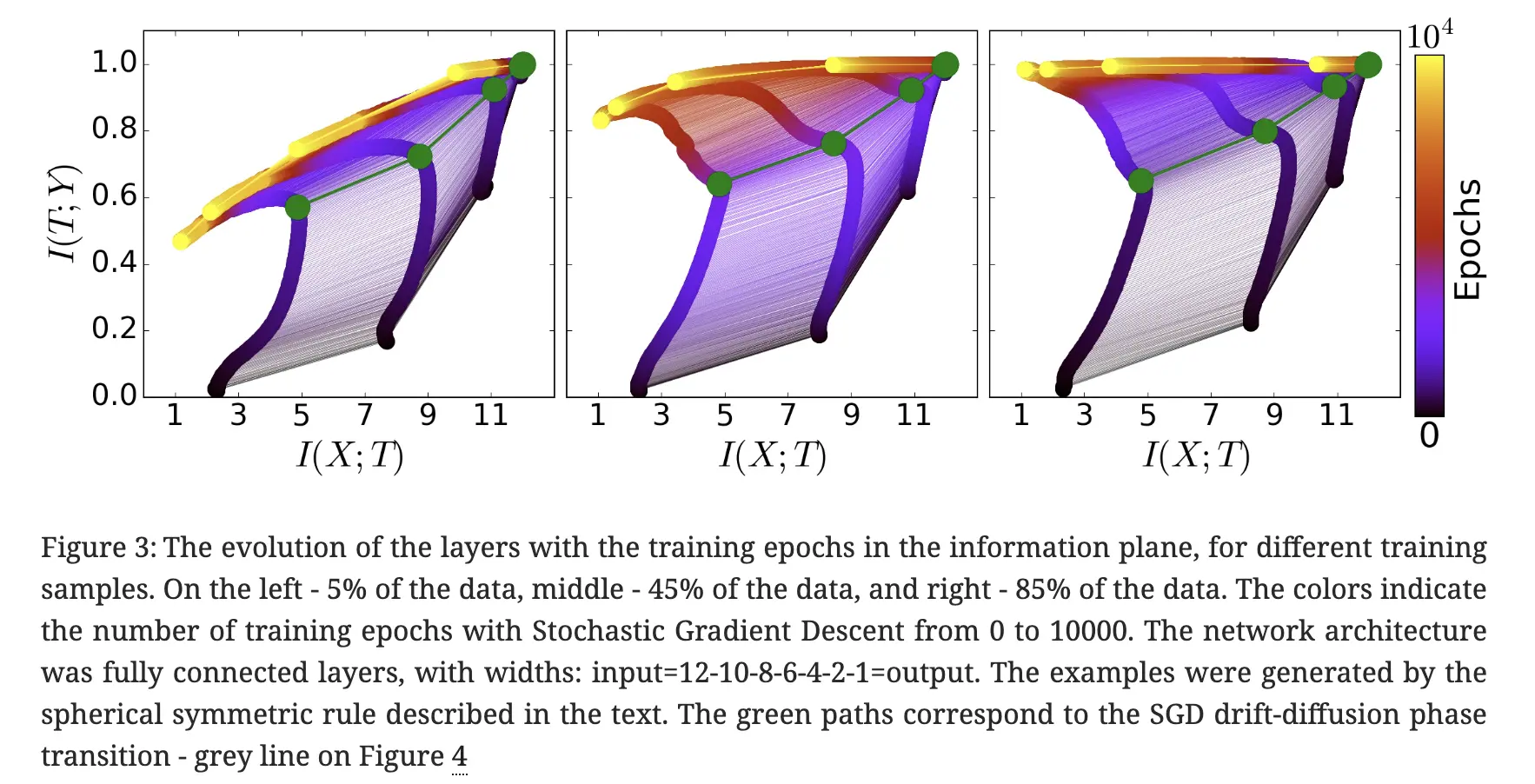
互信息互信息用于表示两个随机变量相互依赖的程度。随机变量\(X\)和\(Y\)的互信息定义为\[\begin{aligned}I(X,Y)&=\mathrm{KL}[p(\boldsymbol{x},\boldsymbol{y}...
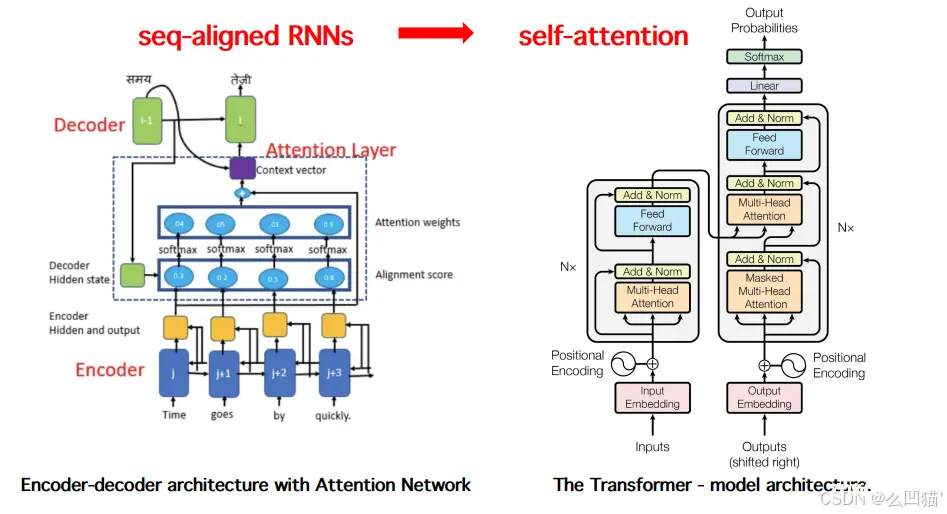
在AI技术的迅猛发展中,注意力机制成为了关键驱动力,赋予机器高效处理复杂信息的能力。本文深入探索注意力机制及其核心应用——Transformer架构,解析其如何通过自注意力机制革新自然语言处理。同时,对比分析GP...
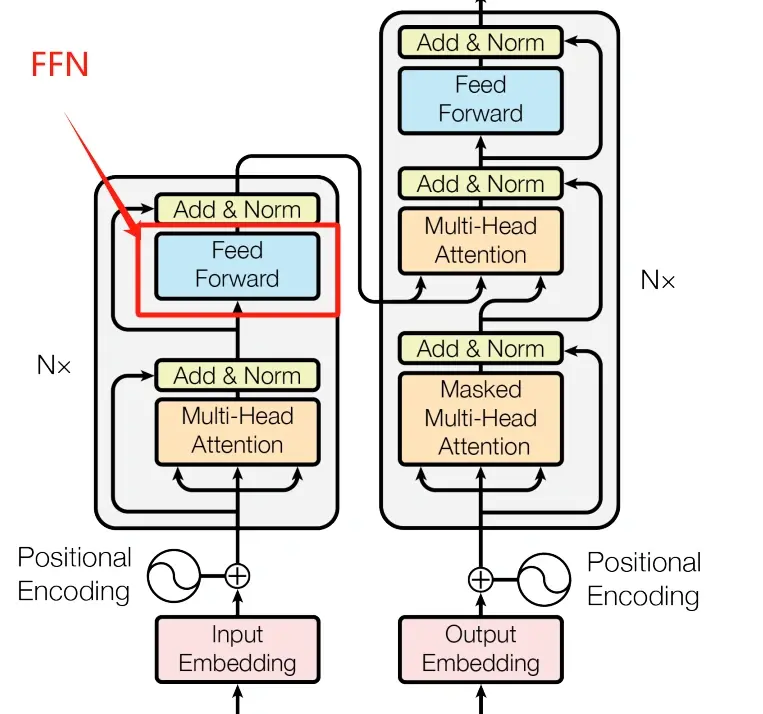
在经过前面3节关于Transformer论文的解读之后,相信你对提出Transformer架构的这篇论文有了一定的了解了,你可以点击下面的链接复习一下前3节的内容。总的来说,这篇论文虽然重要且经典,但很多...
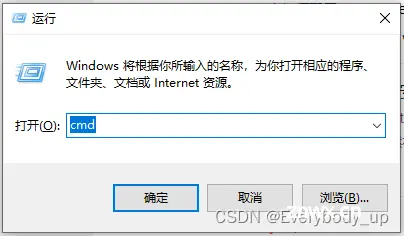
在webstorm配置nodejs之前,需要先下载node.js和webStorm。打开webStorm,File—settings搜索node。会出现相应的版本,如果报错则需要去下载node.js。按下win+r,输入cmd打开命令行...
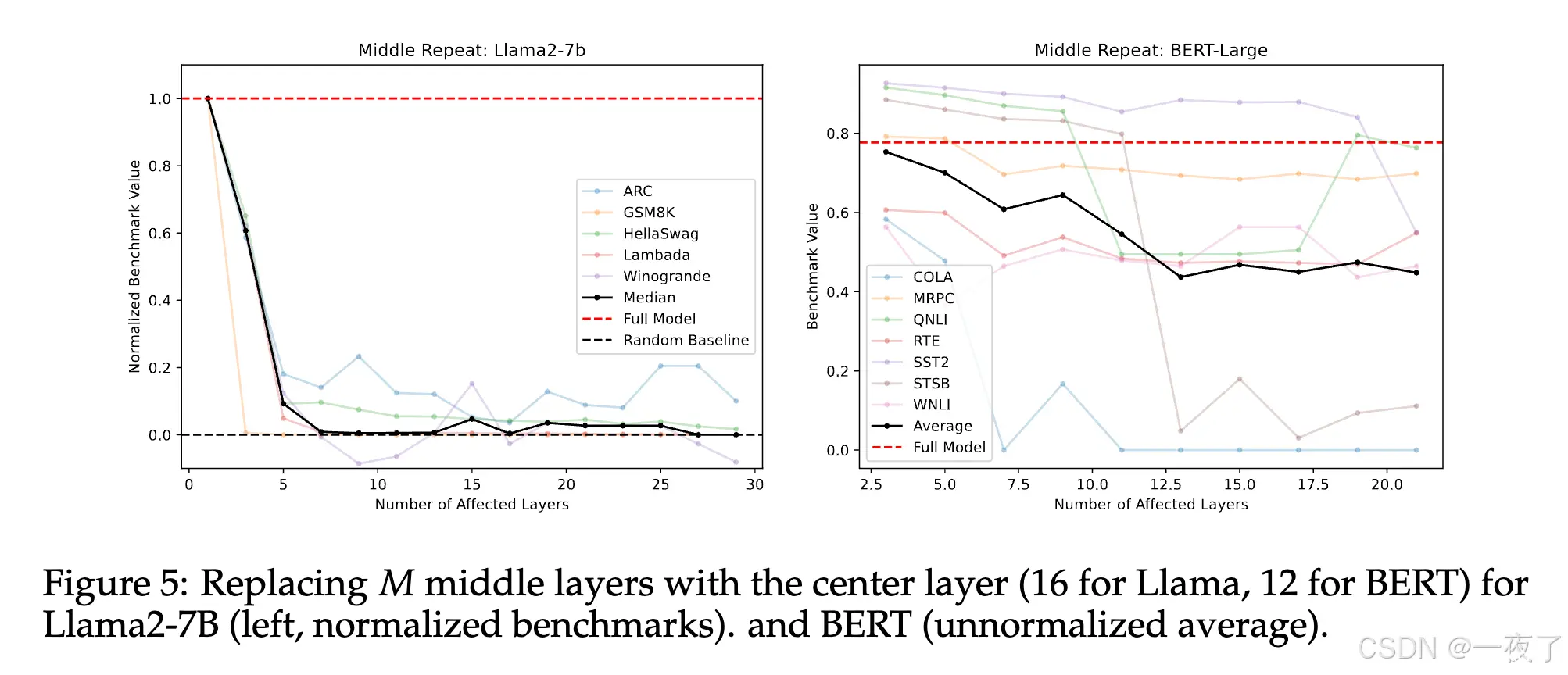
尽管大语言模型现在已经被广泛的应用于各种任务,但是目前对其并没有一个很好的认知。为了弄清楚删除和重组预训练模型不同层的影响,本文设计了一系列的实验。通过实验表明,预训练语言模型中的lower和finallayer...
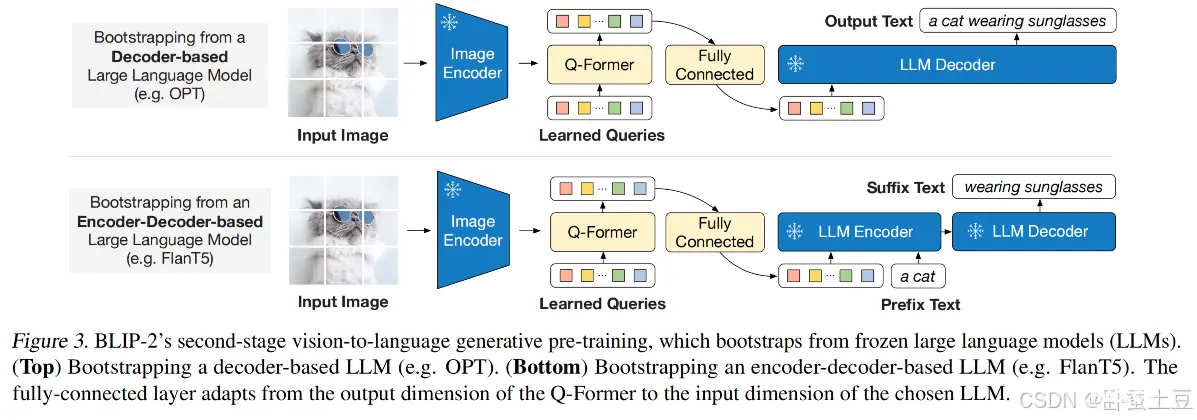
在这篇博客中,我们将详细探讨Q-Former的工作原理、应用场景,并在必要时通过公式进行解释,帮助你全面理解这一前沿技术。通过本文的介绍,希望你对Q-Former的工作原理、应用场景以及在BLIP2中的具体应用有了更...

深度学习的前沿技术包括生成对抗网络(GANs)、自监督学习和Transformer模型。GANs通过生成器和判别器的对抗训练生成高质量数据,自监督学习利用数据的内在结构在无标签数据上学习有效特征,Transfor...