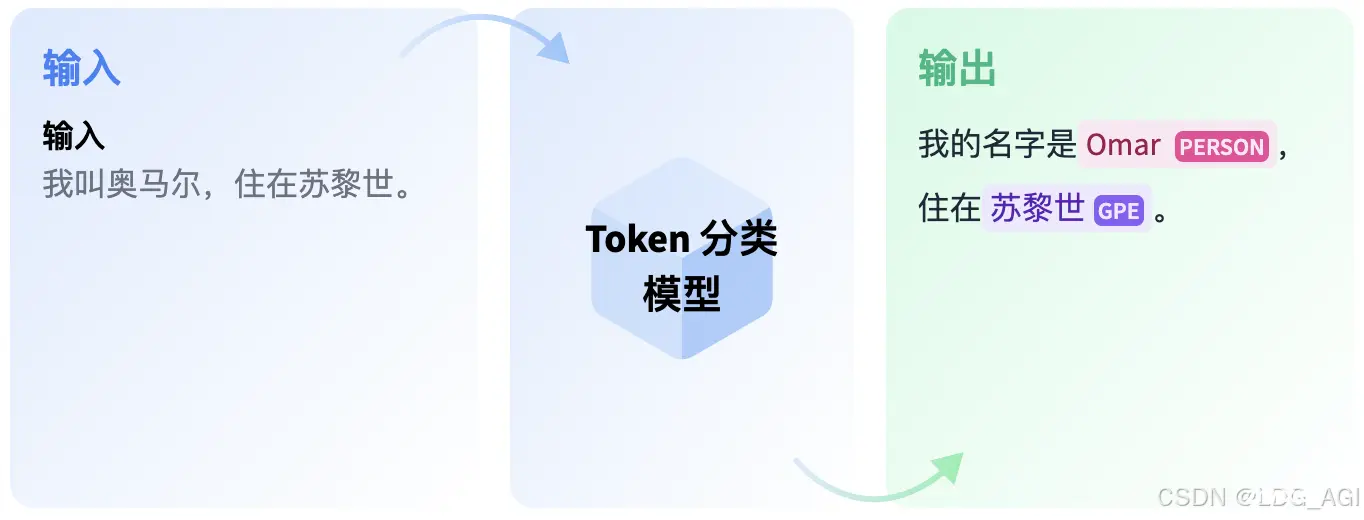
本文对transformers之pipeline的令牌分类(token-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipelin...

因为在Transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失....
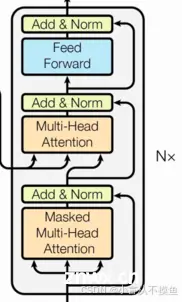
由N个解码器层堆叠而成每个解码器层由三个子层连接结构组成第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接第三个子层连接结构包括一个...
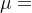
Transformer是一种基于自注意力机制(Self-Attention)的深度学习模型架构,广泛应用于自然语言处理和其他序列到序列的任务。_transformer详解...

本文详细讲解transformers推理大语言模型的初始化过程,包括Python包搜索、LazyModule延迟模块、模块搜索和Python包API设计美学……...
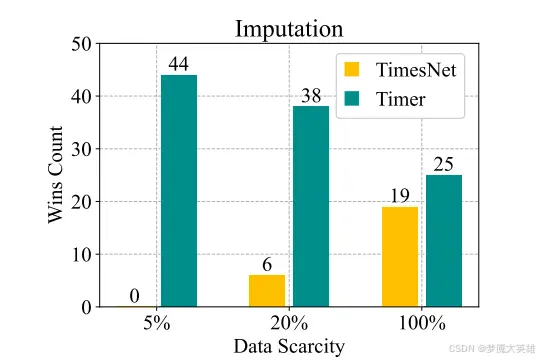
AI论文阅读笔记:Timer:GenerativePre-trainedTransformersAreLargeTimeSeriesModels(ICML2024)这项研究的成果是一个时间序列T...

VisionTransformer(ViTs)是一种在神经网络领域取得了革命性进展的模型,它通过标记混合器(tokenmixer)强大的全局上下文能力,实现了对图像分类、目标检测、实例分割和语义分割等多个视觉...

在Transformer中前馈全连接层就是具有两层线性层的全连接网络。前馈全连接层的作用是考虑注意力机制可能对复杂过程的拟合程度不够,通过增加两层网络来增强模型的能力....

YOLOv8是YOLO(YouOnlyLookOnce)系列的最新版本,继承了YOLO系列的优良传统,致力于实现快速且准确的目标检测。YOLOv8在网络架构、特征提取和检测精度等方面进行了优化,进一步提高了检测性能。然而...
https://www.bilibili.com/video/BV1pL4y1v7jC/?spm_id_from=333.999.0.0&vd_source=7dace3632125a1ef7fd32c285eb...