
物联网、大数据、云计算、人工智能之间的关系是紧密相连、相互促进的。这四者既有各自独立的技术特征,又能在不同层面上相互融合,共同推动信息技术的发展和应用。物联网(IoT)物联网是指通过互联网连接和共享数据的物理设备网络...
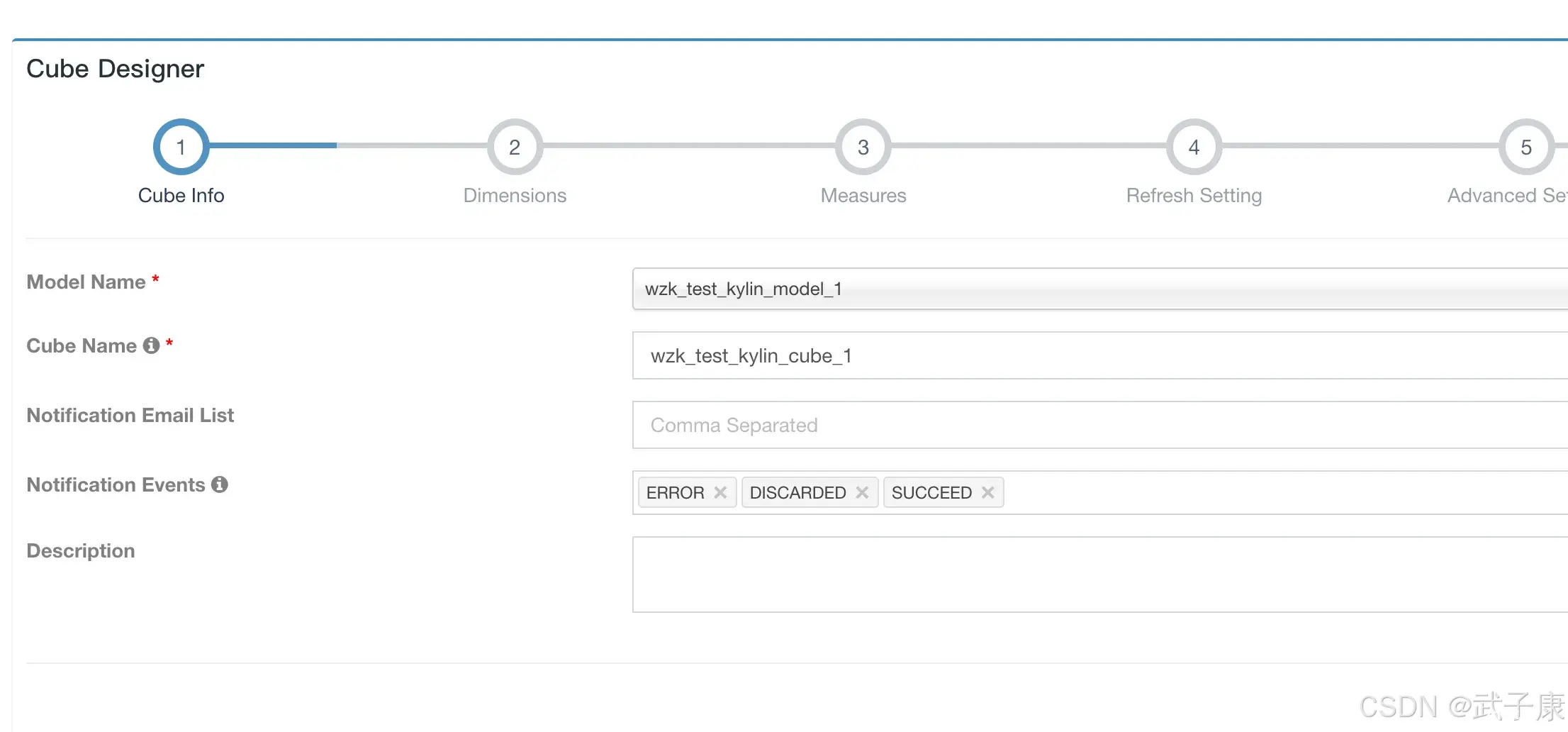
ApacheKylin是一个开源的分布式分析引擎,专注于提供大数据的实时OLAP(在线分析处理)能力。Cube(立方体)是ApacheKylin的核心概念之一,通过预计算大规模数据的多维数据集合,加速复...

本文深入探讨了AI驱动的大数据分析,涵盖了其与大数据的融合、涉及的技术、在不同领域的应用、优势与挑战以及未来发展趋势。通过丰富的案例和详细的代码示例,展示了其在企业决策、金融领域和医疗领域的重要作用。同时,针对...
ApacheDruid是一个高性能的实时分析数据库,专为快速聚合和查询大规模数据集而设计。它的架构由多个组件组成,每个组件在数据的存储、处理和查询中发挥重要作用。每个段通常包含一段时间内的数据,并被优化以支持...
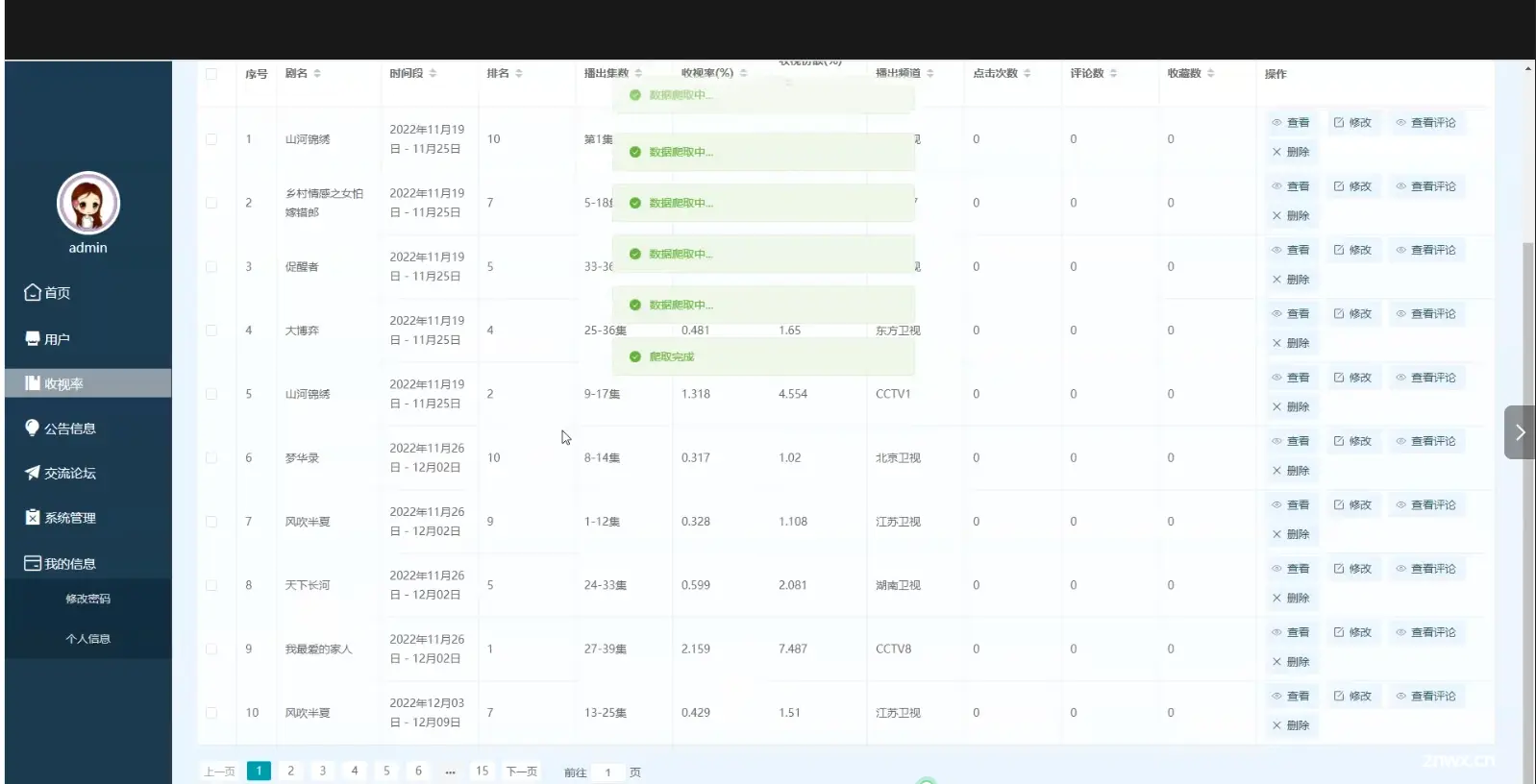
基于Hive的网络电视剧收视率分析系统是一个高效、精确的数据管理与分析平台,旨在为电视传媒机构和观众提供一个全面的收视率数据解决方案。通过利用Hive的大数据处理能力,该系统能够存储和分析海量的收视数据,从而揭示...
近年来,科技飞速发展,在经济全球化的背景之下,大数据将进一步提高社会综合发展的效率和速度,大数据技术也会涉及到各个领域,而爬虫实现网站数据可视化在网站数据可视化背景下有着无法忽视的作用。管理信息系统的开发是一个...
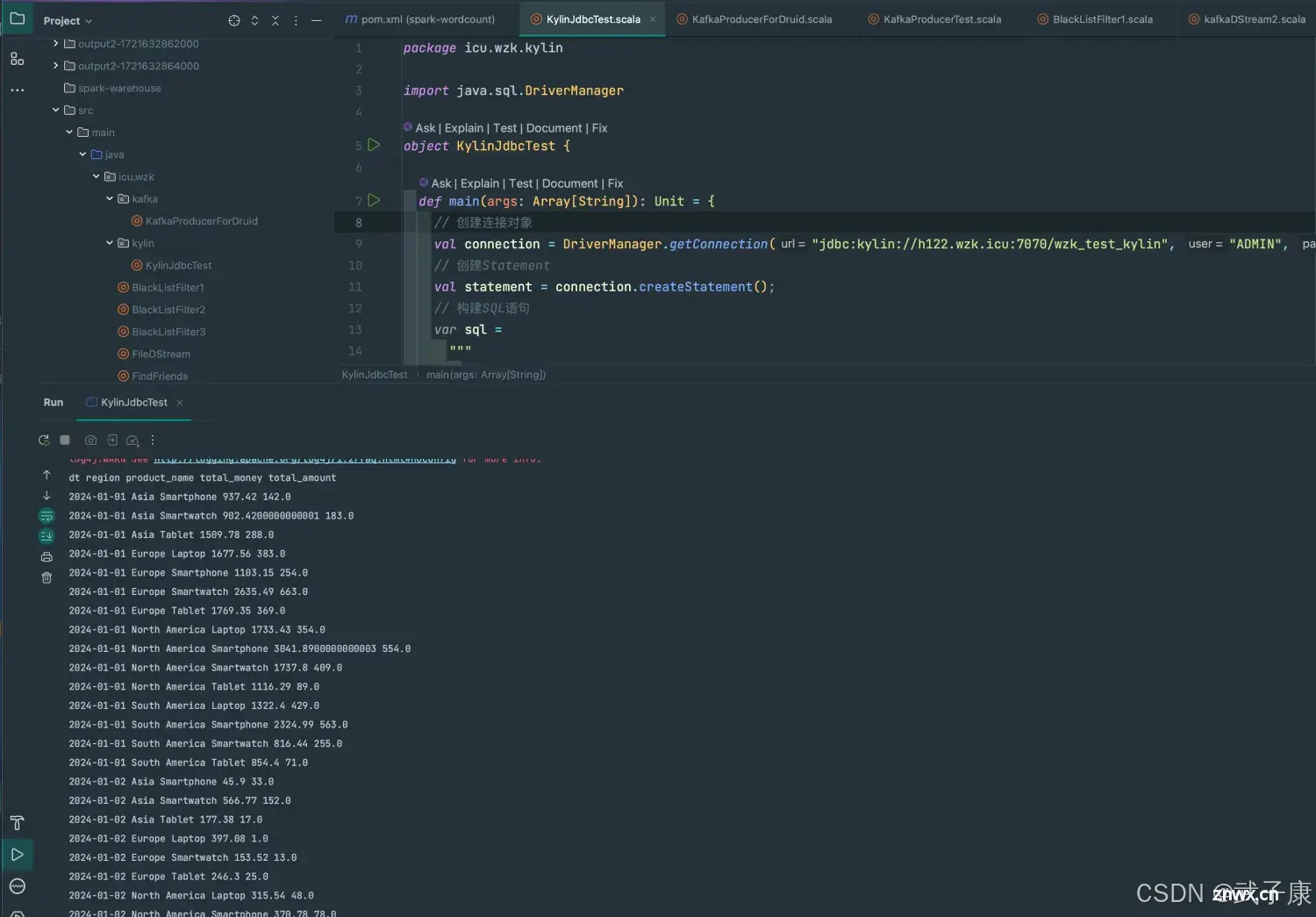
要将数据以可视化方式展示出来,需要使用Kylin的JDBC方式连接执行SQL,获取Kylin的执行结果使用Kylin的JDBC与JDBC操作MySQL一致。选择要合并的Cube和Segments:进入K...
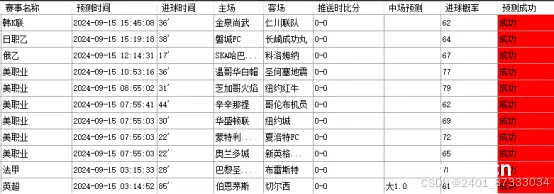
对足球预测系统而言,以下功能模块是必须的:数据采集模块:收集全球范围内的足球赛事数据,包括球队信息、球员数据、比赛结果等。数据处理模块:对采集到的数据进行清洗、整理和预处理,为后续分析提供高质量数据。特征提取模块...

本文深入探讨ApacheBeam在大数据处理中的应用。介绍了其批流处理统一模型,通过高度抽象管道操作融合批处理和流处理,窗口机制依据时间或数据量划分窗口。阐述编程模型与API优势,如JavaAPI的...
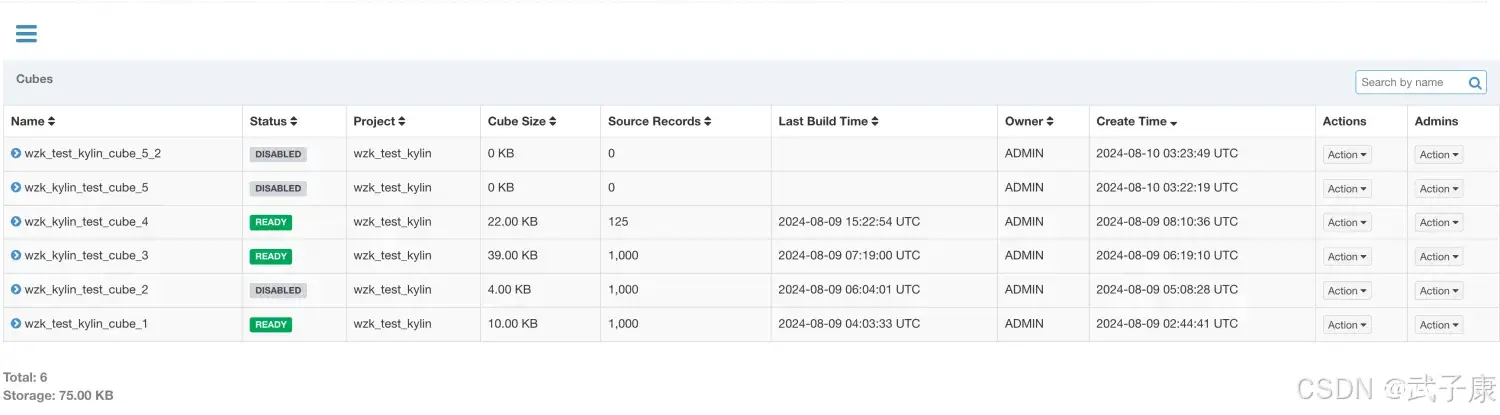
上节我们完成了如下的内容:Cuboid特指Kylin中在某一种维度组合下所计算的所有数据,以减少Cuboid数量为目的的优化统称为Cuboid剪枝。在没有采取任何优化措施的情况下,Kylin会对每一种维度的...