大数据-163 Apache Kylin 全量增量Cube的构建 手动触发合并 JDBC 操作 Scala
CSDN 2024-10-22 10:37:01 阅读 76
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已更完)Kudu(已更完)Druid(已更完)Kylin(正在更新…)
章节内容
上节我们完成了如下的内容:
全量增量Cube的构建Segment

基本流程
在 Apache Kylin 中,手动触发 Segment 合并的步骤如下:
选择要合并的 Cube 和 Segments: 进入 Kylin Web UI,选择你要操作的 Cube,进入该 Cube 的详情页面。在“Segments”标签页下,可以看到当前 Cube 的所有 Segments。选择你希望合并的 Segments。
合并 Segments: 点击页面上的 “Merge Segment” 按钮。通常情况下,Kylin 会自动计算可以合并的 Segments。如果你想手动控制合并的 Segments,可以在弹出的对话框中手动选择你想合并的 Segments。
配置合并任务: 配置合并任务的参数,如目标时间范围等。Kylin 会根据你选择的 Segments 的范围自动填充一些默认的值。你可以根据需求调整这些参数。
启动合并任务: 完成配置后,点击 “Submit” 按钮。Kylin 将会创建一个新的合并任务(Job),该任务将在后台执行。你可以在 “Job” 页面查看任务的执行状态。
监控任务状态: 在 “Job” 页面,你可以查看合并任务的日志和状态。如果任务执行成功,你会看到新的 Segment 出现在 Segments 列表中,表示合并已经完成。
如果合并成功,新的合并后 Segment 会替代原来的多个 Segments,而旧的 Segments 将被 Kylin 自动清理。
需要注意的是,手动合并的操作可能会占用大量资源,因此在高负载时需要谨慎操作,并在合适的时间段执行合并任务。
手动触发合并Segment
Kylin提供了一种简单的机制用于控制Cube中Segment的数量:合并Segment,在WebGUI中选中需要进行Segments合并的Cube。
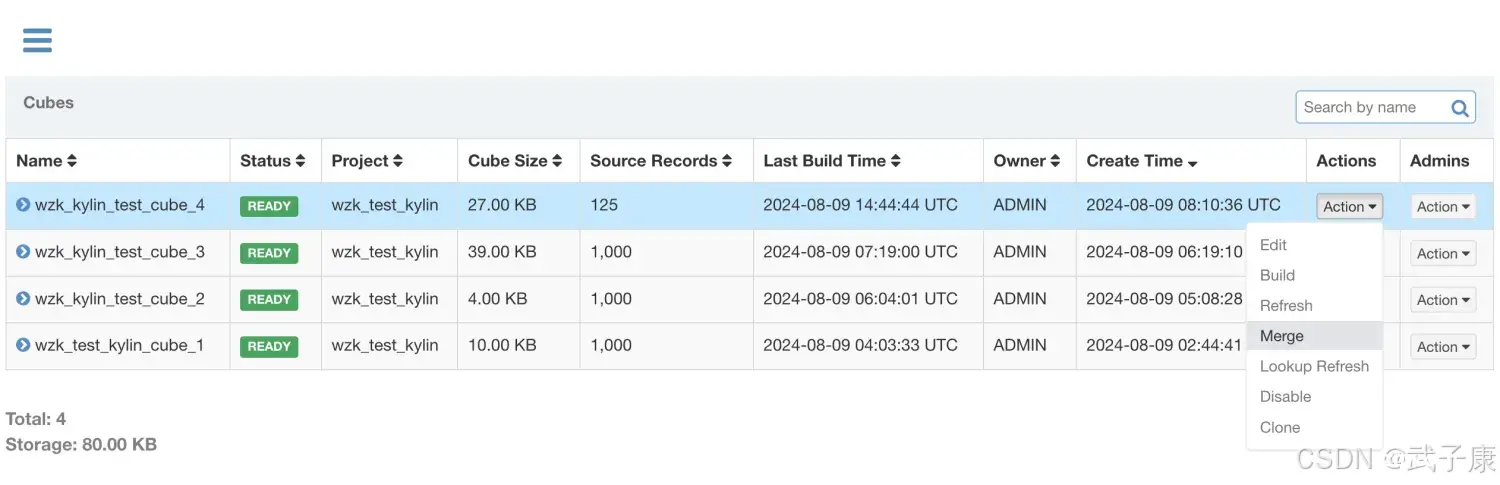
单击Action => Merge
我们刚才分阶段进行了任务的Build操作,
01-01、01-02、01-03、01-04 的任务,我们可以使用 Merge 来进行合并:
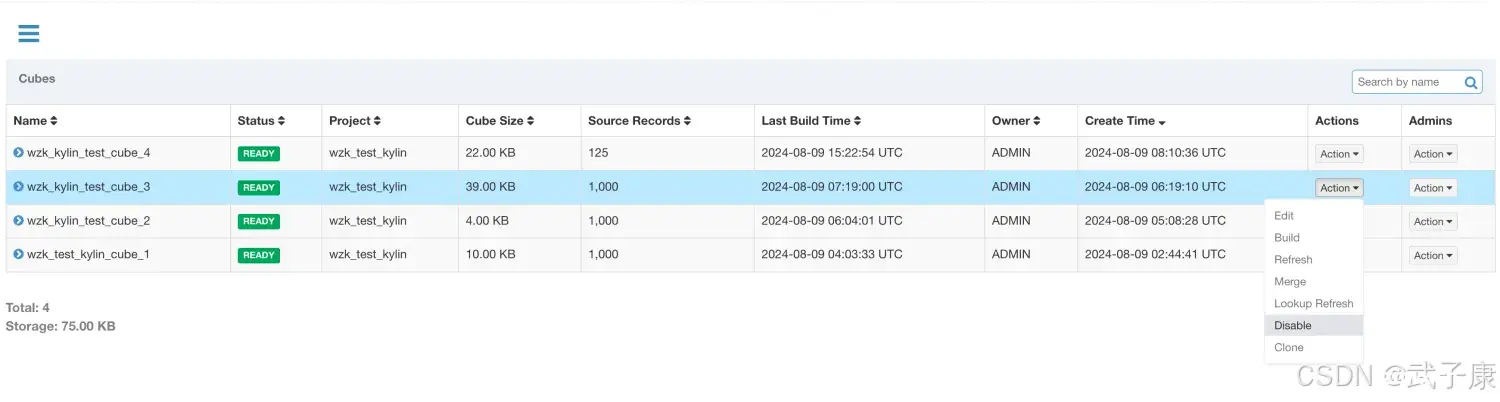
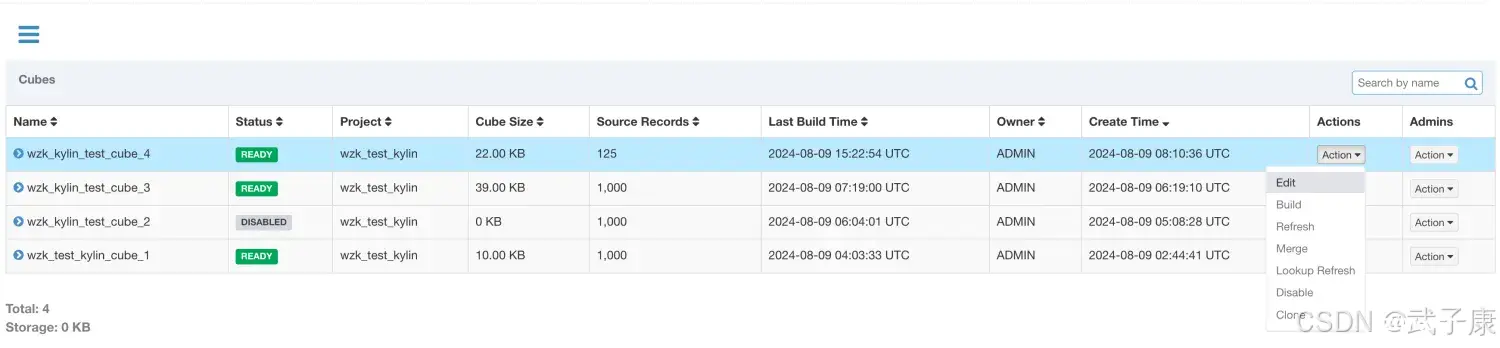
选中需要合并的Segment,可以同时合并多个Segment,但这些Segment必须是连续的,单击提交系统会提交一个类型为 MERGE 的构建任务,这里可以选择时间阶段,我选择的是 01-03到01-04:
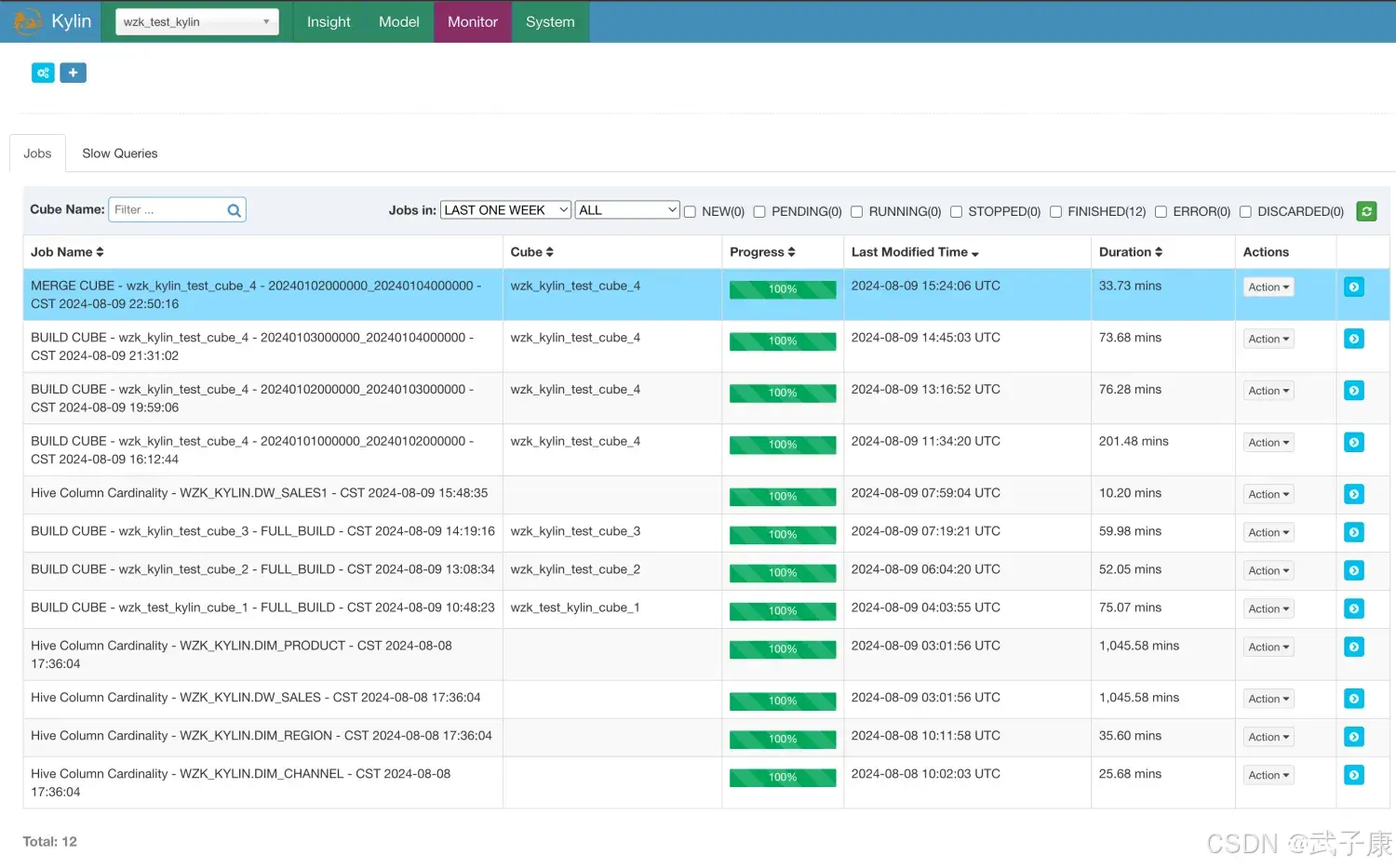
提交任务,可以看到是一个 Merge任务,看名字:【MERGE】,等待合并完毕:
合并完毕的结果如下图:
注意事项
在MERGE构建结束之前,所有选中用来合并的Segment仍然处于可用的状态在MERGE类型的构建完成之前,系统将不允许提交这个Cube上任何类型的其他构建任务当MERGE构建结束的时候,系统将选中合并的Segment替换为新的Segment,而被替换下的Segment等待将被垃圾回收和清理,以节省系统资源
删除Segment
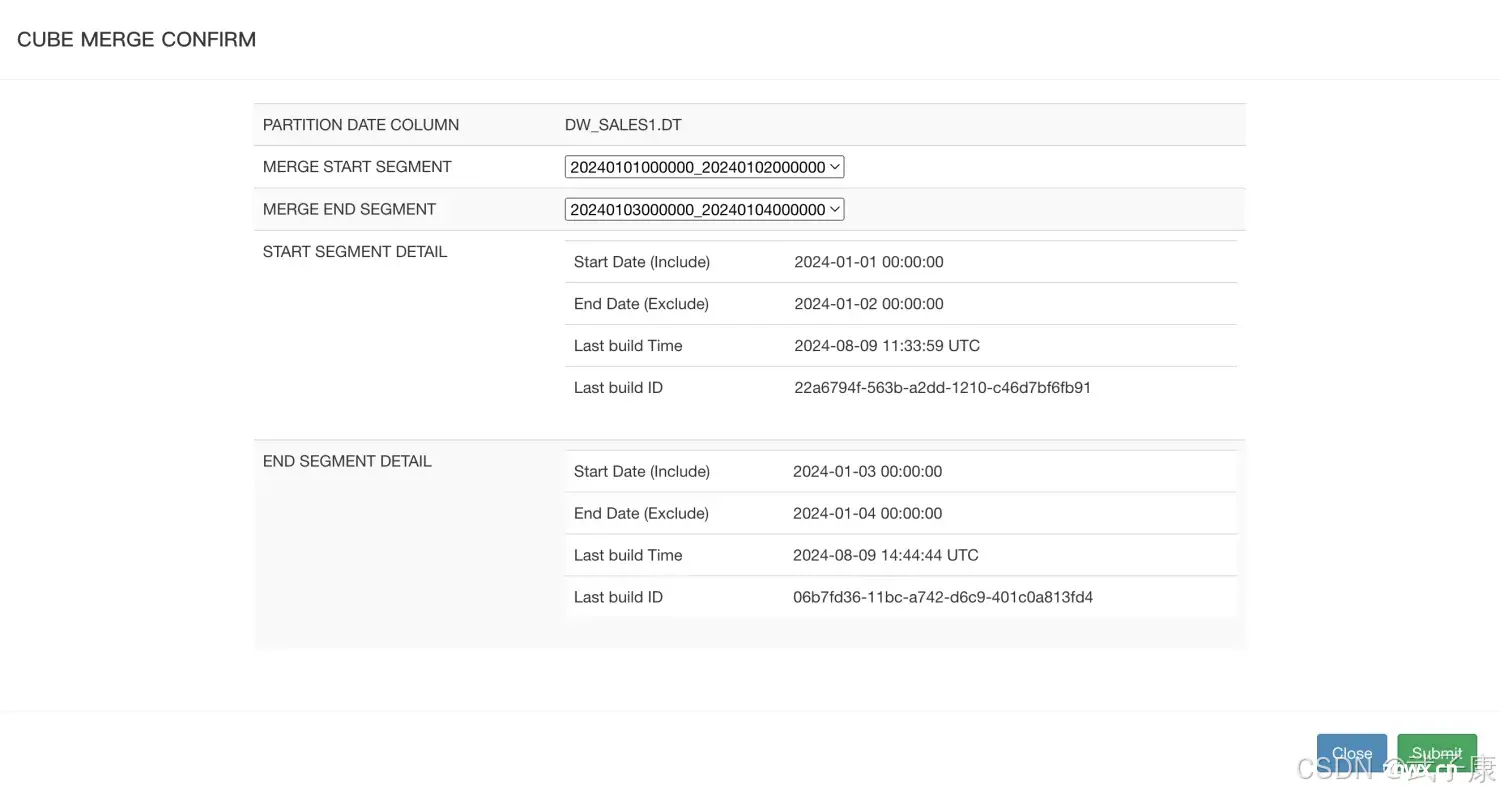
使用WebUI删除Cube的Segment,
这里选择 Disable 就可以删除Segment了:
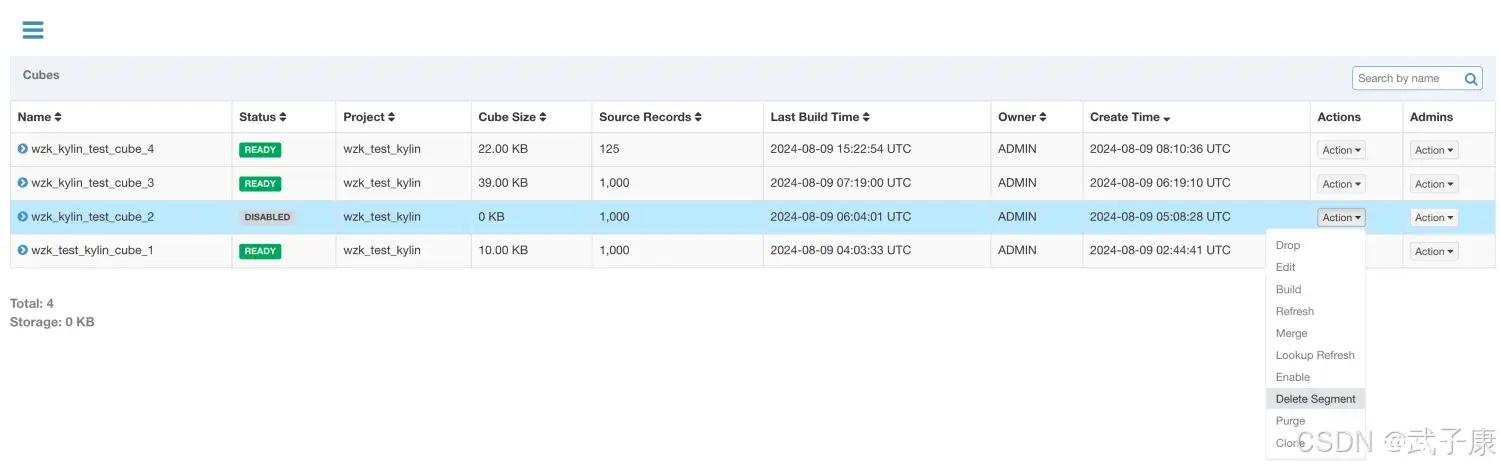
Disable之后,可以看到下面的:DeleteSegment操作,就可以删除指定的Segment了:
自动合并
手动维护Segment很繁琐,人工成本高,Kylin中是可以支持自动合并Segment。
在Cube Designer的 Refresh Settings的页面中有:
Auto Merge ThresholdsRetention Thresholds
Refresh Settings的页面:

两个设置项可以用来帮助管理Segment碎片,这两项设置搭配使用这两项设置可以大大减少对Segment进行管理的麻烦。
Auto Merge Thresholds
允许用户设置几个层级的时间阈值,层级越靠后,时间阈值越大每当Cube中有新的Segment状态变为READY的时候,就会自动触发一次系统自动合并
合并策略
尝试最大一级的时间阈值,例如:针对(7天、28天)层级的日志,先检查能够将连续的若干个Segment合并成为一个超过28天的大Segment如果有个别的Segment的事件长度本身已经超过28天,系统会跳过Segment如果满足条件的连续Segment还不能够累积超过28天,那么系统会使用下一个层级的时间戳重复寻找
案例1 理解Kylin自动合并策略
假设自动合并阈值设置为7天、28天如果现在有A-H 8个连续的Segment,它们的时间长度为28天(A)、7天(B)、1天(C)、一天(D)、一天(E)、一天(F)、一天(G)、一天(H)此时,第9个Segment加入,时间长度为1天
自动合并的策略为:
Kylin判断时能够将连续的Segment合并到28天这个阈值,由于Segment A已经超过28天,会被排除。剩下的连续Segment,所有时间加一起 B+C+D+E+F+G+H+I < 28天,无法满足28天的阈值,则开始尝试7天的阈值跳过 A(28)、B(7)均超过7天,排除剩下的连续Segment,所有时间加在一起 C+D+E+F+G+H+I 达到7天的阈值,触发合并,提交Merge任务,并构建一个SegmentX(7天)合并后,Segment为:A(28天)、B(7天)、X(7天)连续触发检查,A(28天)跳过,B+X(7+7=14)< 28天,不满足第一阈值,重新使用第二阈值触发跳过B、X尝试终止
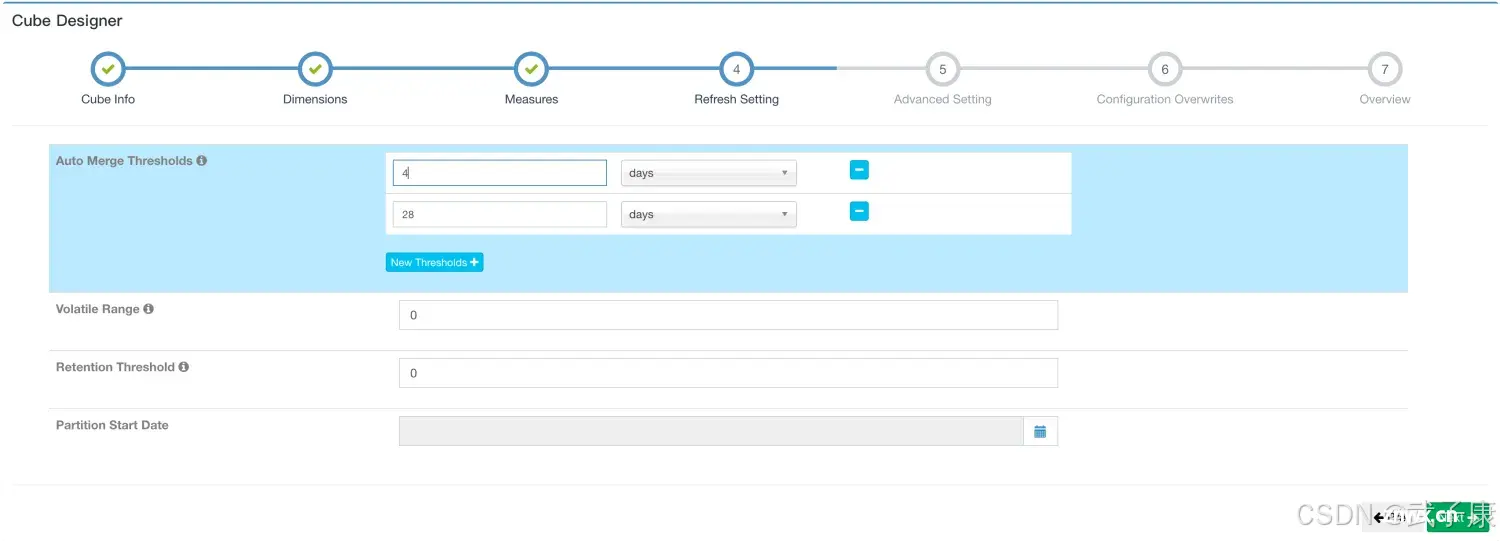
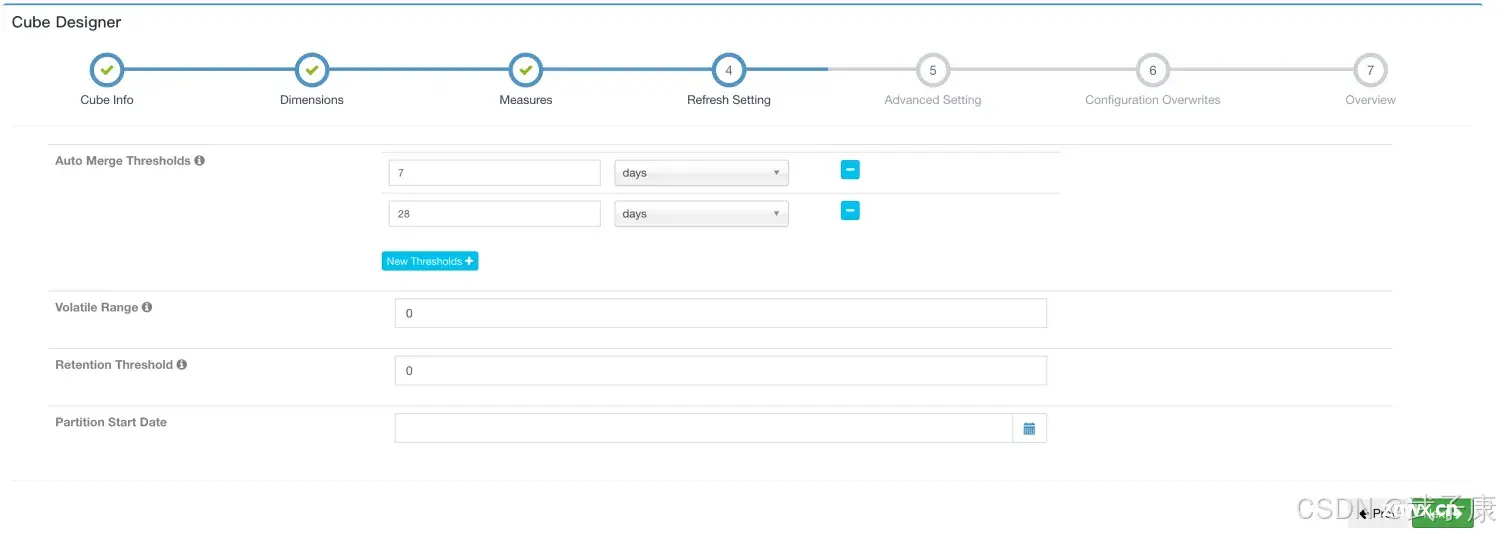
案例2 配置自动合并4天的Segment
选中Model,选择Edit进行编辑:

直接到Refresh Setting选项卡,将选项修改为,4天:
后续将自动进行Segment的构建。
配置保留的Segment
自动合并是将多个Segment合并为一个Segment,以达到清理碎片的目的,保留Segment则是及时清理不再使用的Segment。
在很多场景中,只会对过去一段时间内的数据进行查询,例如:
对于某个只显示过去1年数据的报表支持它的Cube其实只需要保留过去一年类的Segment即可由于数据在Hive中已经存在备份,则不需在Kylin中备份超过一年的类似数据
可以将Retention Threshold设置为365,每当有新的Segment状态变为READY的时候,系统会检查每一个Segment。如果它的结束时间距离最晚的一个Segment的结束时间已经大于等于RetentionThreshold,那么这个Segment将视为无需保留,系统会自动从Cube中删除这个Segment。
保留策略示意图如下所示:
使用JDBC连接操作Kylin
简单介绍
要将数据以可视化方式展示出来,需要使用Kylin的JDBC方式连接执行SQL,获取Kylin的执行结果使用Kylin的JDBC与JDBC操作MySQL一致
业务需求
通过JDBC的方式,查询按照日期、区域、产品维度统计订单总额/总数量结果
开发步骤
添加依赖
<code><dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>3.1.1</version>
</dependency>
实现规划
创建Connection连接对象构建SQL语句创建Statement对象,并执行executeQuery打印结果
编写代码
我这里用Scala实现了,Java也差不多
package icu.wzk.kylin
import java.sql.DriverManager
object KylinJdbcTest {
def main(args: Array[String]): Unit = {
// 创建连接对象
val connection = DriverManager.getConnection("jdbc:kylin://h122.wzk.icu:7070/wzk_test_kylin", "ADMIN", "KYLIN")
// 创建Statement
val statement = connection.createStatement();
// 构建SQL语句
var sql =
"""
|select
| t1.dt,
| t2.regionid,
| t2.regionname,
| t3.productid,
| t3.productname,
| sum(t1.price) as total_money,
| sum(t1.amount) as total_amount
|from
| dw_sales1 t1
|inner join dim_region t2
|on t1.regionid = t2.regionid
|inner join dim_product t3
|on t1.productid = t3.productid
|group by
| t1.dt,
| t2.regionid,
| t2.regionname,
| t3.productid,
| t3.productname
|order by
| t1.dt,
| t2.regionname,
| t3.productname
|""".stripMargin
val resultSet = statement.executeQuery(sql)
println("dt region product_name total_money total_amount")
while (resultSet.next()) {
// 获取时间
val dt = resultSet.getString("dt")
// 获取区域名称
val regionName = resultSet.getString("regionname")
// 获取产品名称
val productName = resultSet.getString("productname")
// 获取累计金额
val totalMoney = resultSet.getDouble("total_money")
// 获取累计数量
val totalAmount = resultSet.getDouble("total_amount")
println(f"$dt $regionName $productName $totalMoney $totalAmount")
}
connection.close()
}
}
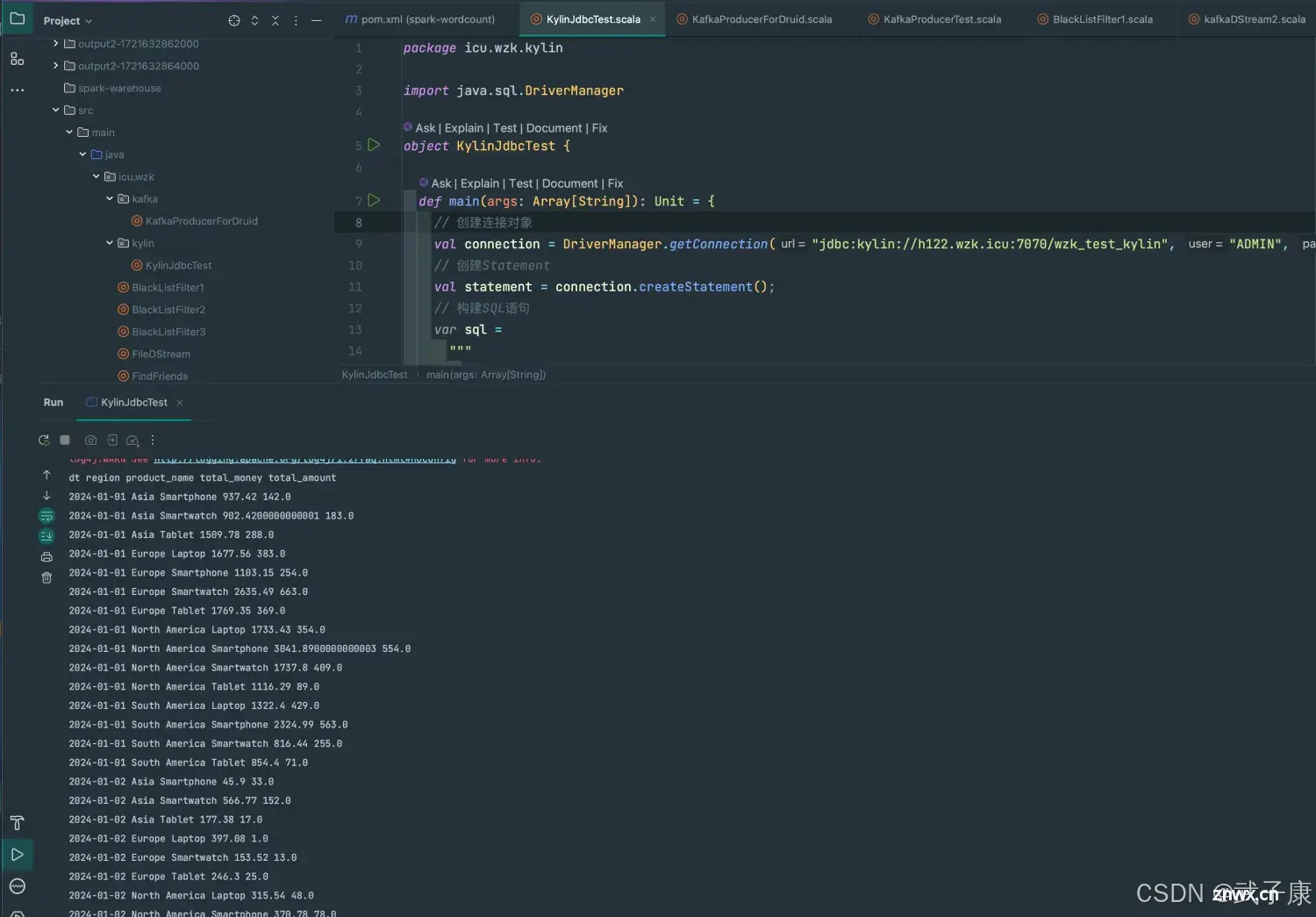
测试运行
我们运行代码,可以看到如下的运行结果:
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。