大数据-165 Apache Kylin Cube优化 案例 2 定义衍生维度及对比 & 聚合组 & RowKeys
CSDN 2024-10-17 13:07:01 阅读 74
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已更完)Kudu(已更完)Druid(已更完)Kylin(正在更新…)
章节内容
上节我们完成了如下的内容:
Cube 剪枝优化检查 Cube 数量、大小案例 1:定义衍生维度及对比(整体详细流程)

定义Cube7
省略Model等操作。
构建前面Cube4类似的Cube7,仅在维度定义有区别。(我这里是Clone Cube4,然后修改的)
wzk_test_kylin_cube_7的字段中,都是Normal:
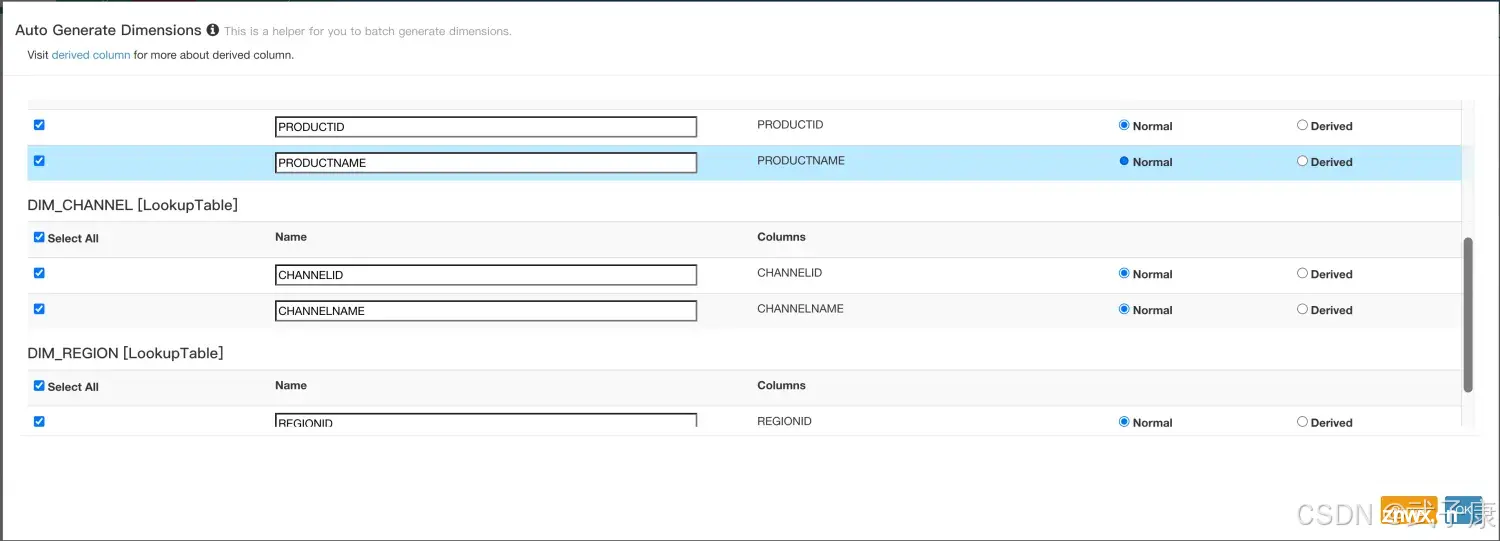
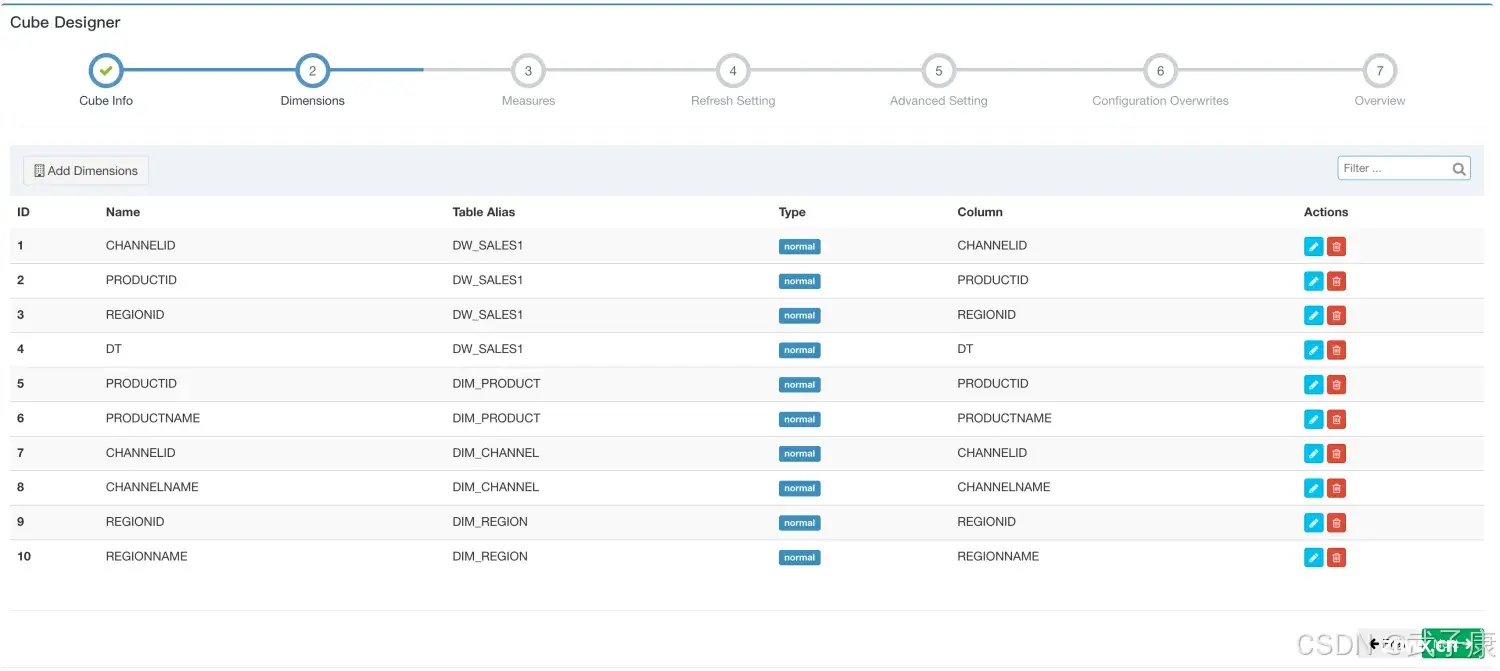
生成的如下图:
构建Cube7
大小对比
查看Size的对比:
由于之前数据太多跑的太慢,我的 cube-4 是125条数据占用22KB,我的cube-7是15条占用9KB。
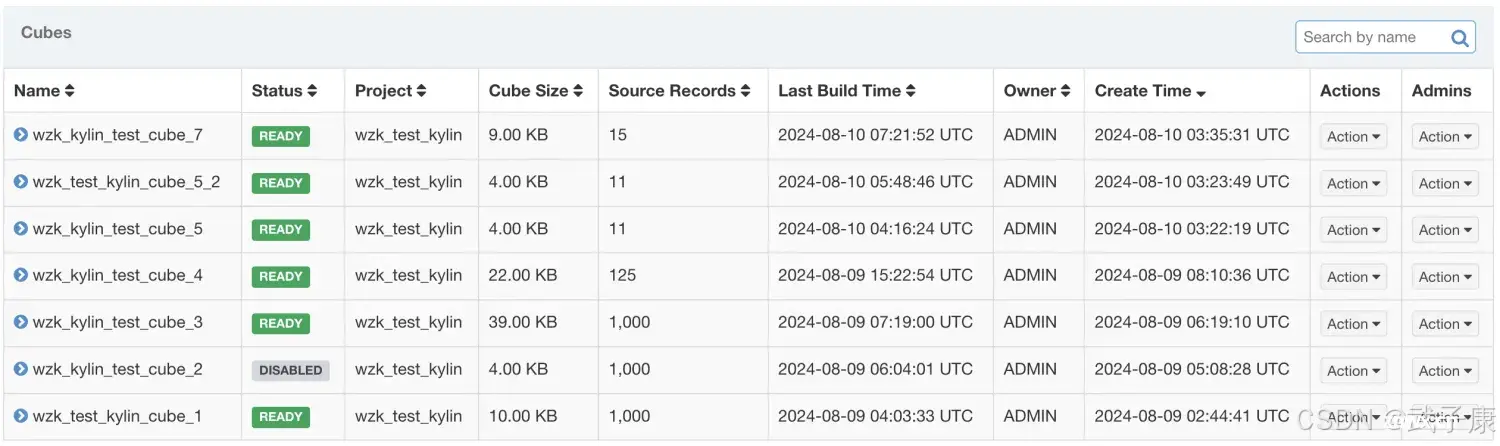
粗略可以估计出来,cube-7的大小要比cube-4的大小大很多(如果同数据量的话)
精度对比
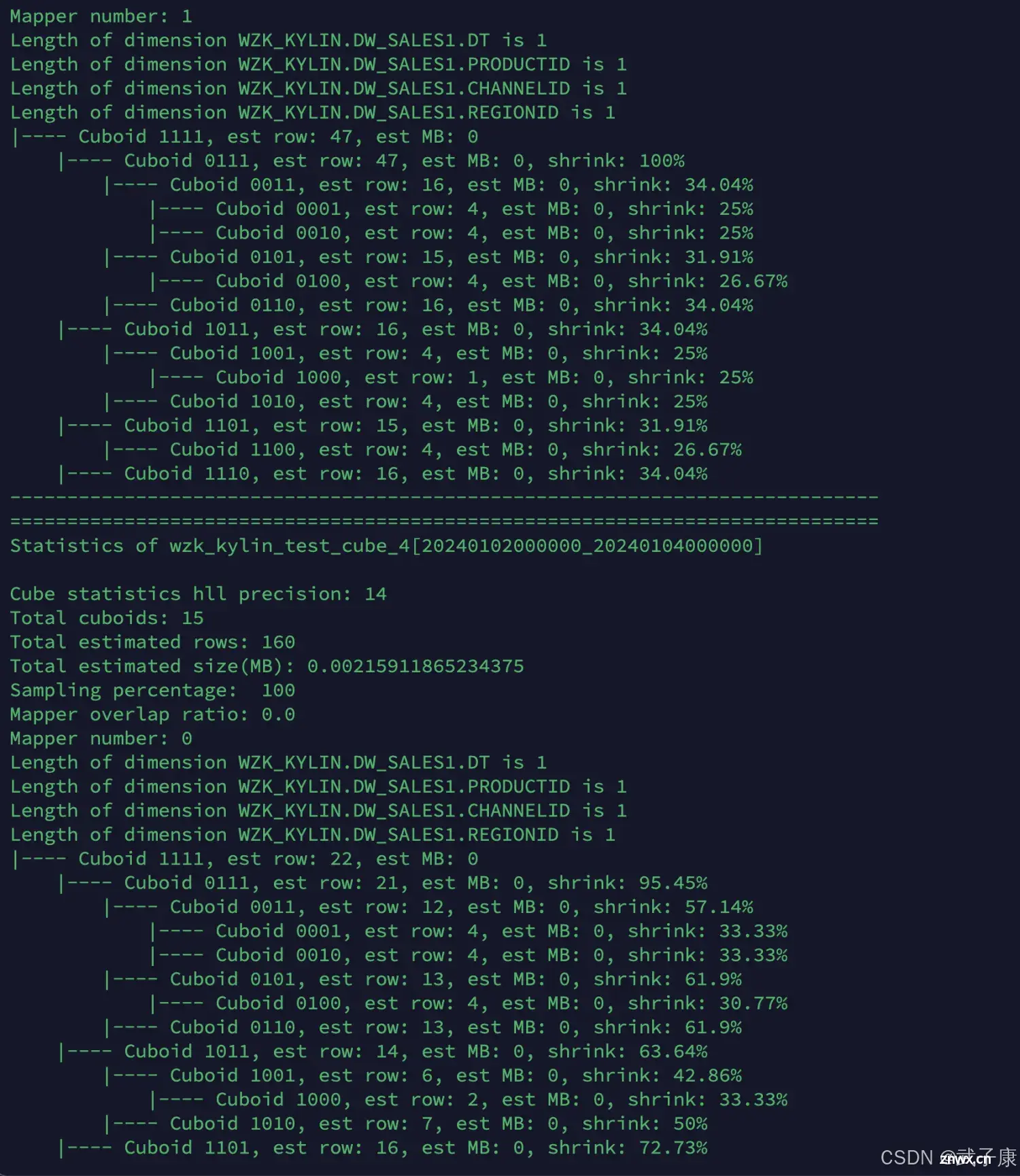
wzk_kylin_test_cube_4
kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader wzk_kylin_test_cube_4
对应的信息如下:
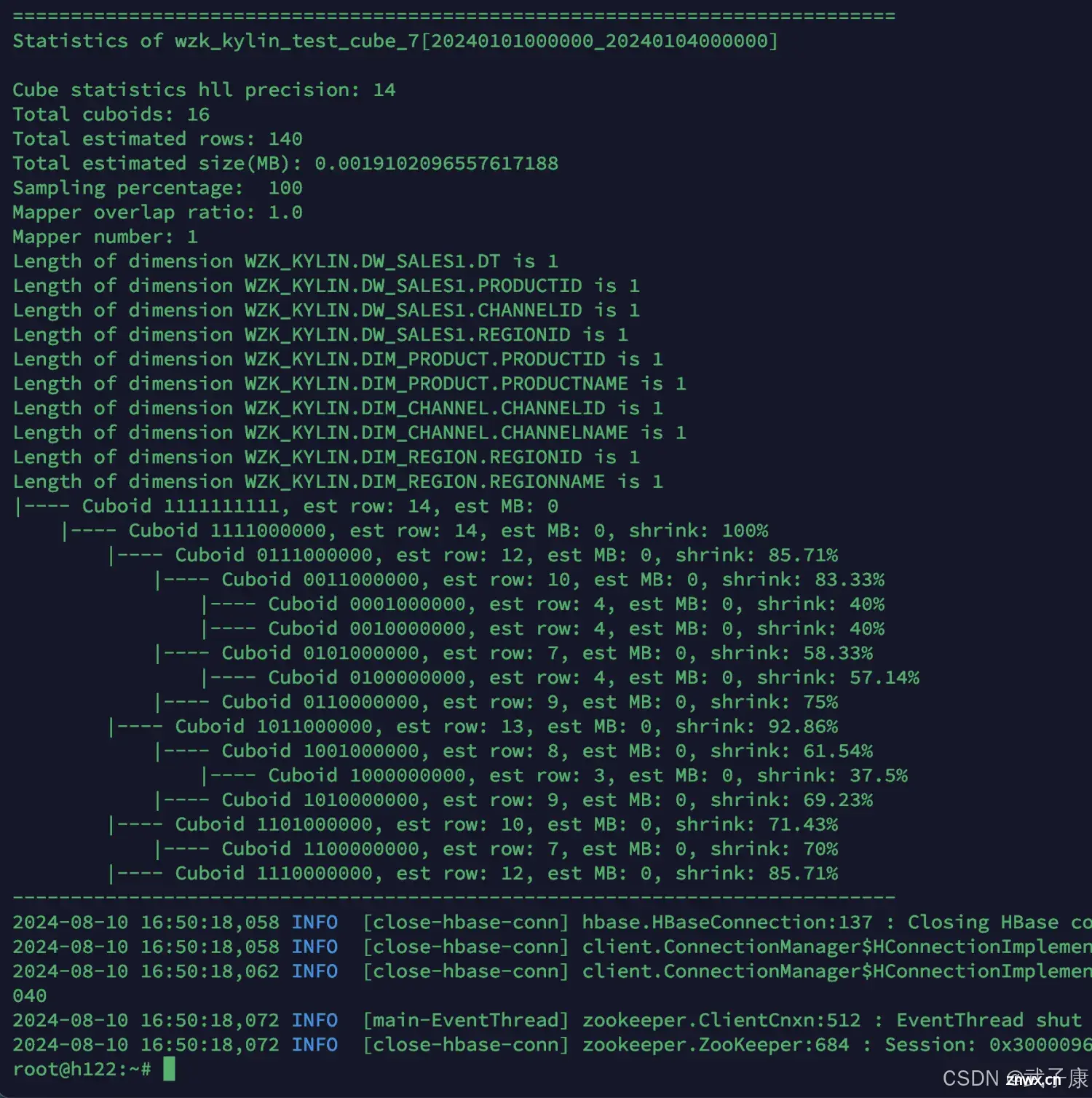
wzk_kylin_test_cube_7
kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader wzk_kylin_test_cube_7
对应的信息如下:
聚合组
随着维度数目的增加,Cuboid的数量会爆炸式的增长,为了缓解Cube的构建压力,Apache Kylin 引入了一系列高级的设置,帮助用户筛选出真正需要的Cuboid(本质是要减少Cube构建过程中的预计算),这些高级设置包括:
聚合组(Aggregation Group)强制维度(Mandatory Dimension)层级维度(Hierachy Dimension)联合维度(Joint Dimension)
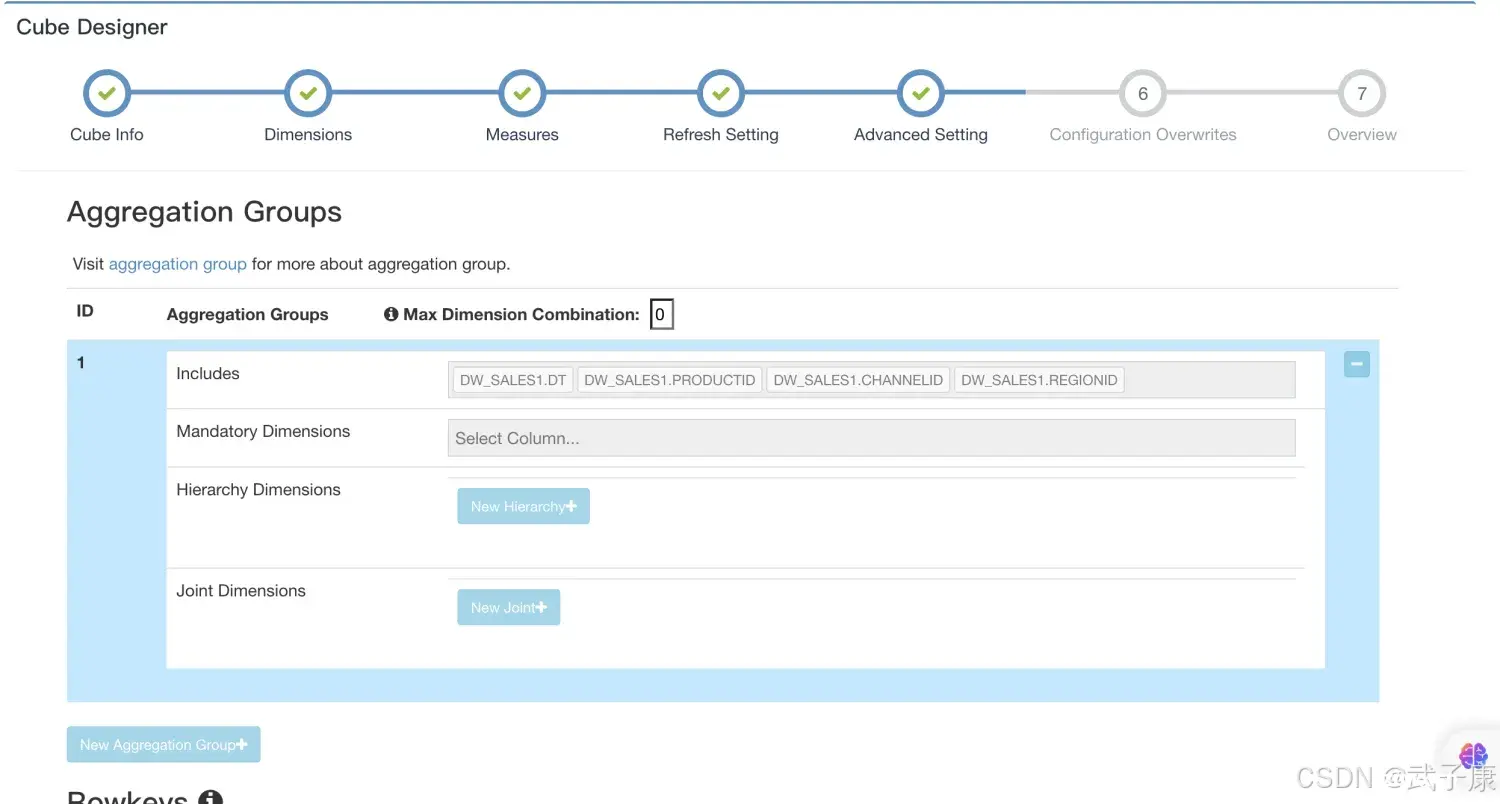
默认Kylin会把所有维度放在同一个聚合组中
如果维度数较多(如维度数>15),建议用户根据查询的习惯和模式,将维度分布到多个聚合组中。通过使用多个聚合组,可以大大降低Cube中的Cuboid数量。
如一个Cube有(M+N)个维度:
这些维度放在一个聚合组中,默认有2^(M+N)个Cuboid将这些维度分为两个不相交的聚合组,第一个组有M个维度,第二个组有N个维度。那么Cuboid的总数为(2^M + 2^N)个维度一个维度可以出现在多个聚合组中
在单个组合组中,可以对维度设置一些高级属性,包括强制思维、层级维度、联合维度。一个维度只能出现在一个属性组中。
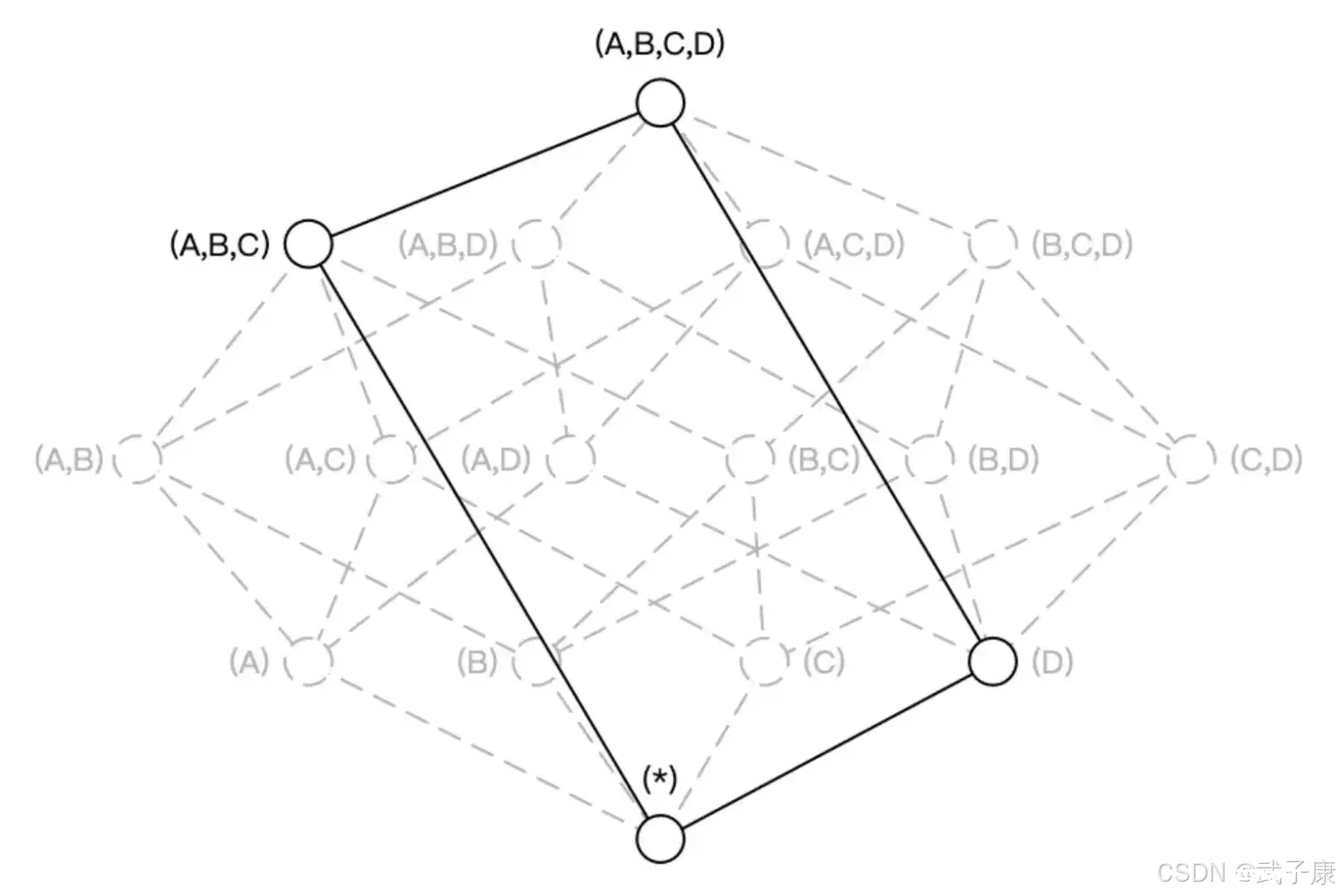
构建N个维度的Cube会生成的2^N个Cuboid,如下图所示,构建一个4个维度(A、B、C、D)的Cube,需要生成16个Cuboid。
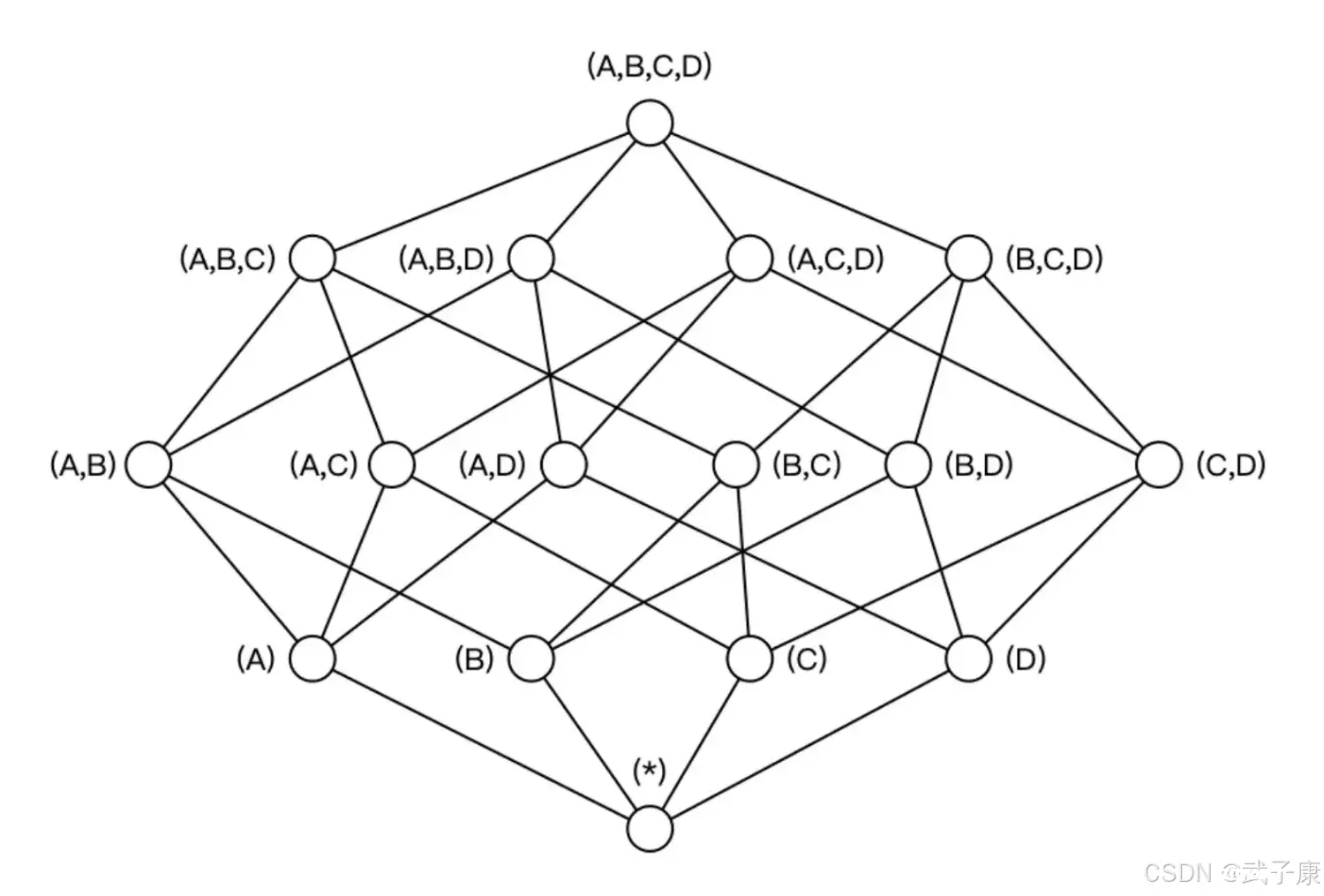
根据用户关注的维度组合,可以维度划分不同的组合类,这些组合类在Kylin中被称为聚合组,如用户仅仅关注维度AB组合和维度CD组合,那么该Cube则可以被分化成两个聚合组,分别是聚合组AB和聚合组CD。生成的Cuboid数目从16个缩减为8个。
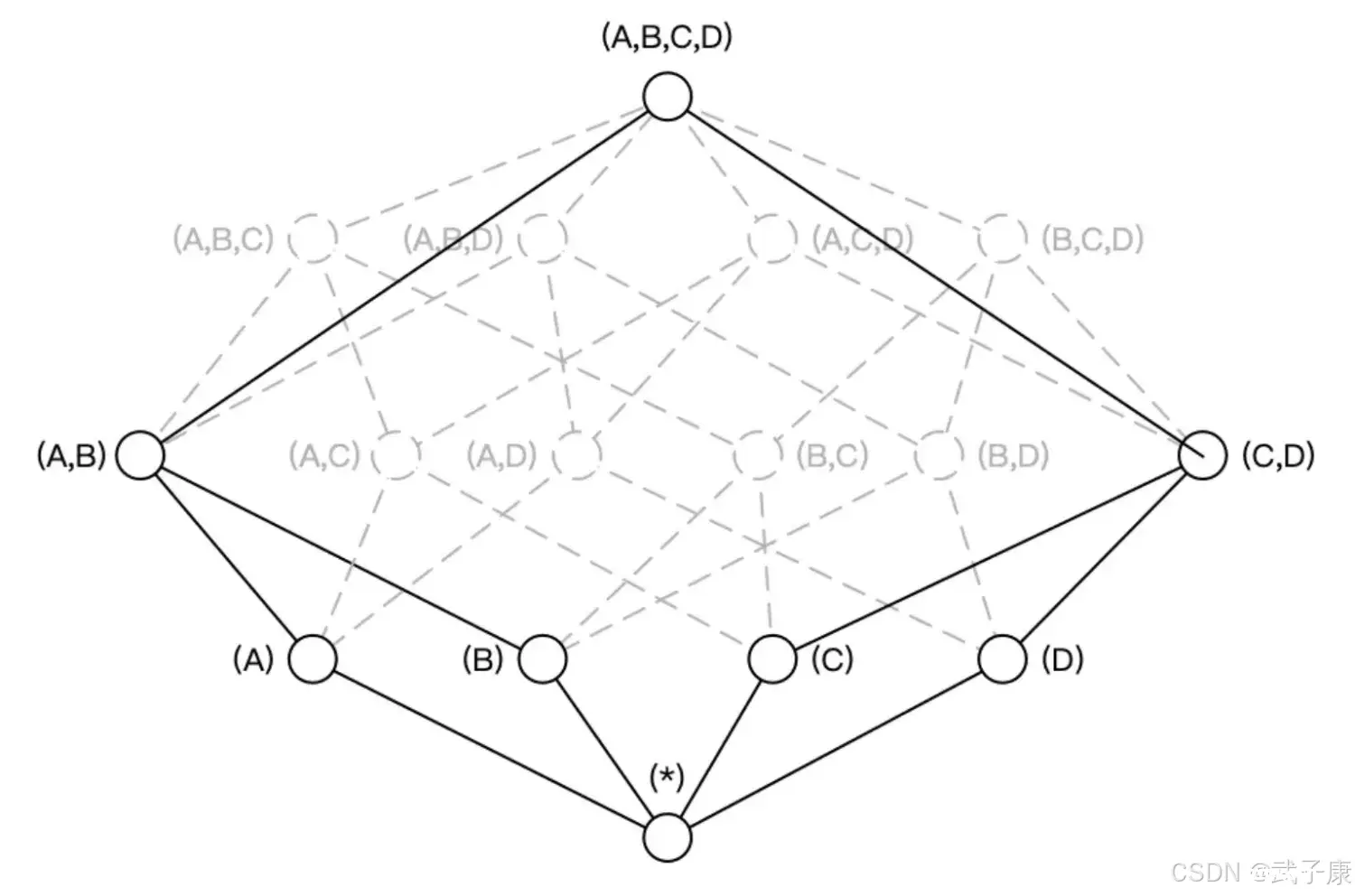
用户关心的聚合组之间可能包含相同的维度,如聚合组ABC和聚合组BCD都包含维度B和维度C,这些聚合组之间会衍生相同的Cuboid。聚合组ABC会产生Cuboid BC,聚合组BCD也会产生Cuboid BC。
这些Cuboid不会重复生成,一份Cuboid为这些聚合组所共有。
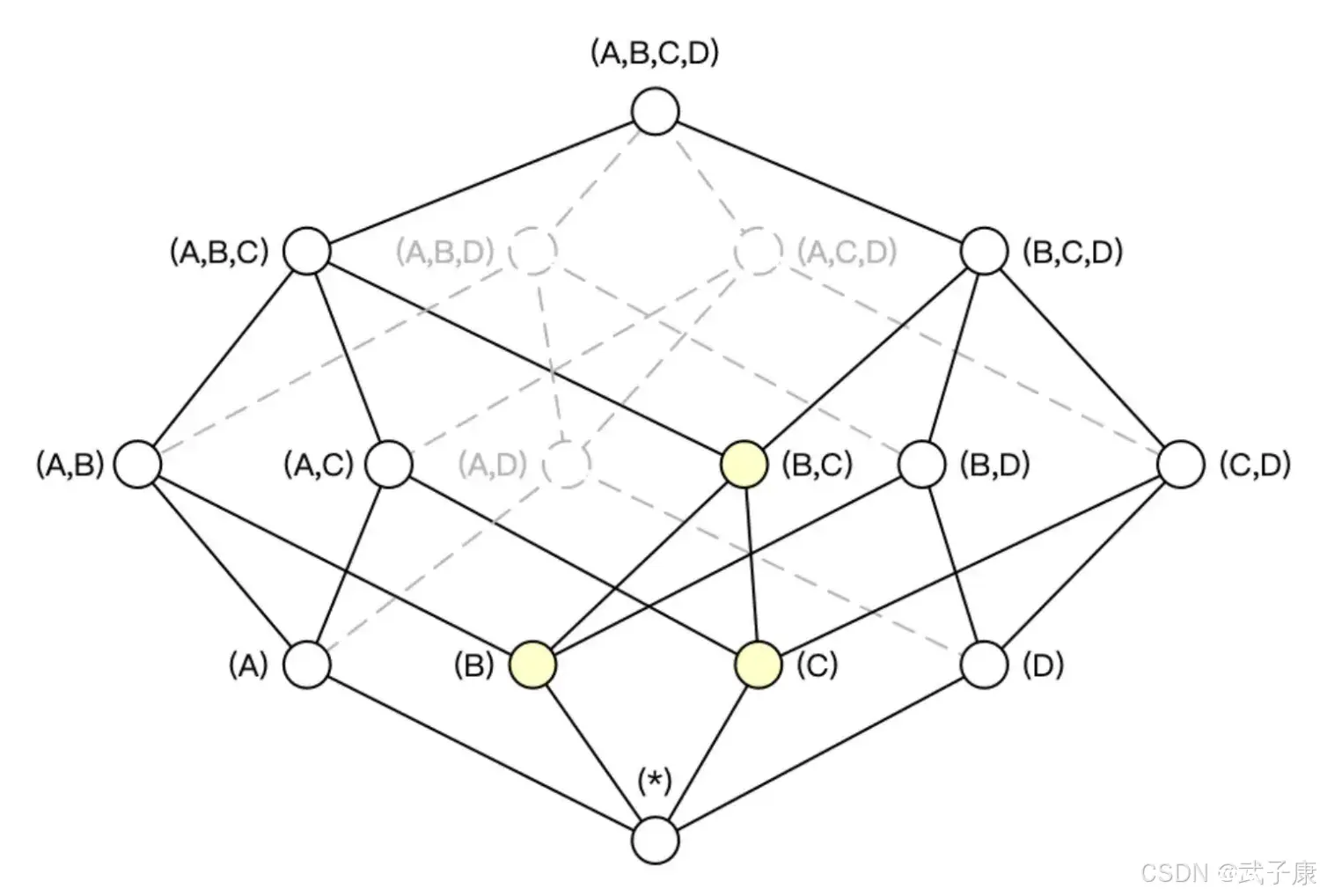
有了聚合组就可以粗粒度的对Cuboid进行筛选,获取自己想要的维度组合。Kylin的建模需要业务专家参数。
强制维度(Mandatory Dimension)
强制/必要 维度:指的是那些总会出现在Where条件或Group By语句中的维度。
通过指定某些维度为强制维度,Kylin不预计算那些不包含此维度的Cuboid,从而减少计算量。
维度A是强制维度,那么生成的Cube如下图所示,维度数从16变成9。
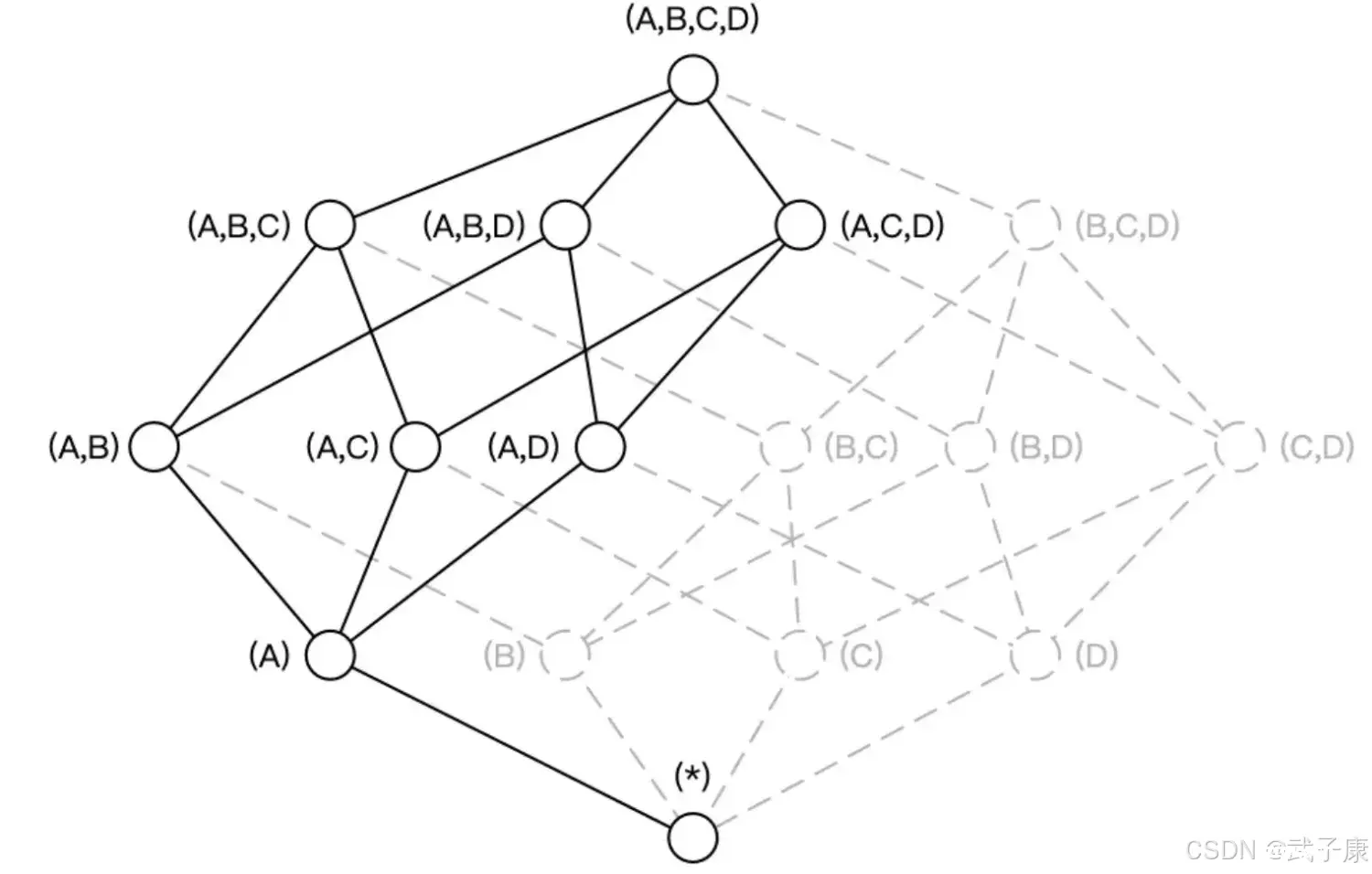
层级维度(Hierachy Dimension)
层级维度:是指一组有层级关系的维度
维度中常常会出现具有层级关系的维度,例如:国家、省份、城市这三个维度,从上而下来说:国家/省份/城市之间分别是一对多的关系。假设维度A代表国家,维度B代表省份,维度C代表城市,ABC三个维度可以被设置为层级维度,生成的Cube如下图所示:
Cuboid[A,C,D] = Cuboid[A,B,C,D], Cuboid[B,D] = Cuboid[A,B,D],因而Cuboid[A,C,D] 和 Cuboid[B,D] 就不必重复存储。
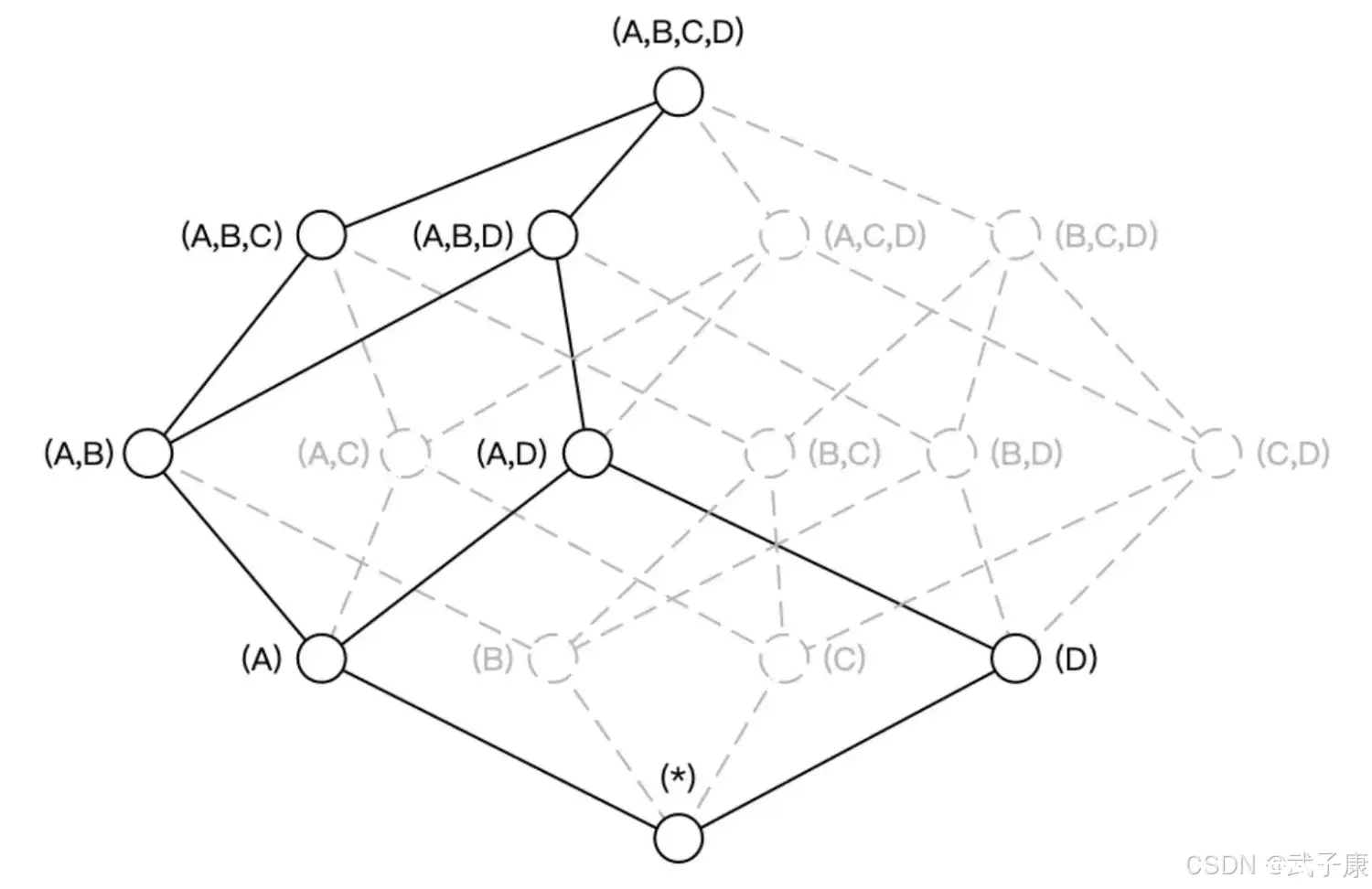
联合维度(Joint Dimension)
联合维度:是将多个维度视作一个维度,在进行组合计算的时候,它们要么一起出现,要么均不出现。
通常适用于以下几种情形:
总是在一起查询的维度彼此之间有一定映射关系,如USER_ID和EMAIL基数很低的维度,如性别、布尔类型的属性
维度的基数:维度有多少个不同的值。
联合维度并不关心维度之间各种细节的组合方式,如用户查询语句中仅仅会出现GROUP BY A,B,C,而不会出现GROUP BY A、B或者GROUP BY C等等这细化的维度组合。这一类问题就是联合维度所解决的问题。
例如将A、B、C定义为联合维度,Apache Kylin就仅仅构建Cuboid ABC,而Cuboid AB、BC、A等等Cuboid都不会被生成,最终Cube结果如下图所示的,Cuboid数目从16减少到4:
总结内容
在单个聚合组中,可以对维度进行设置,包括强制维度、层级维度、联合维度。强制维度:指的是那些总会出现在Where条件或者GROUP BY子句中的维度层级维度:一组具有层级关系的维度(如:国家、省、市)联合维度:将多个维度看成一个角度,要么一起出现,要么都不出现
RowKeys
简单的说Cuboid的维度会映射为HBase的Rowkey,Cuboid的指标会映射为HBase的Value。
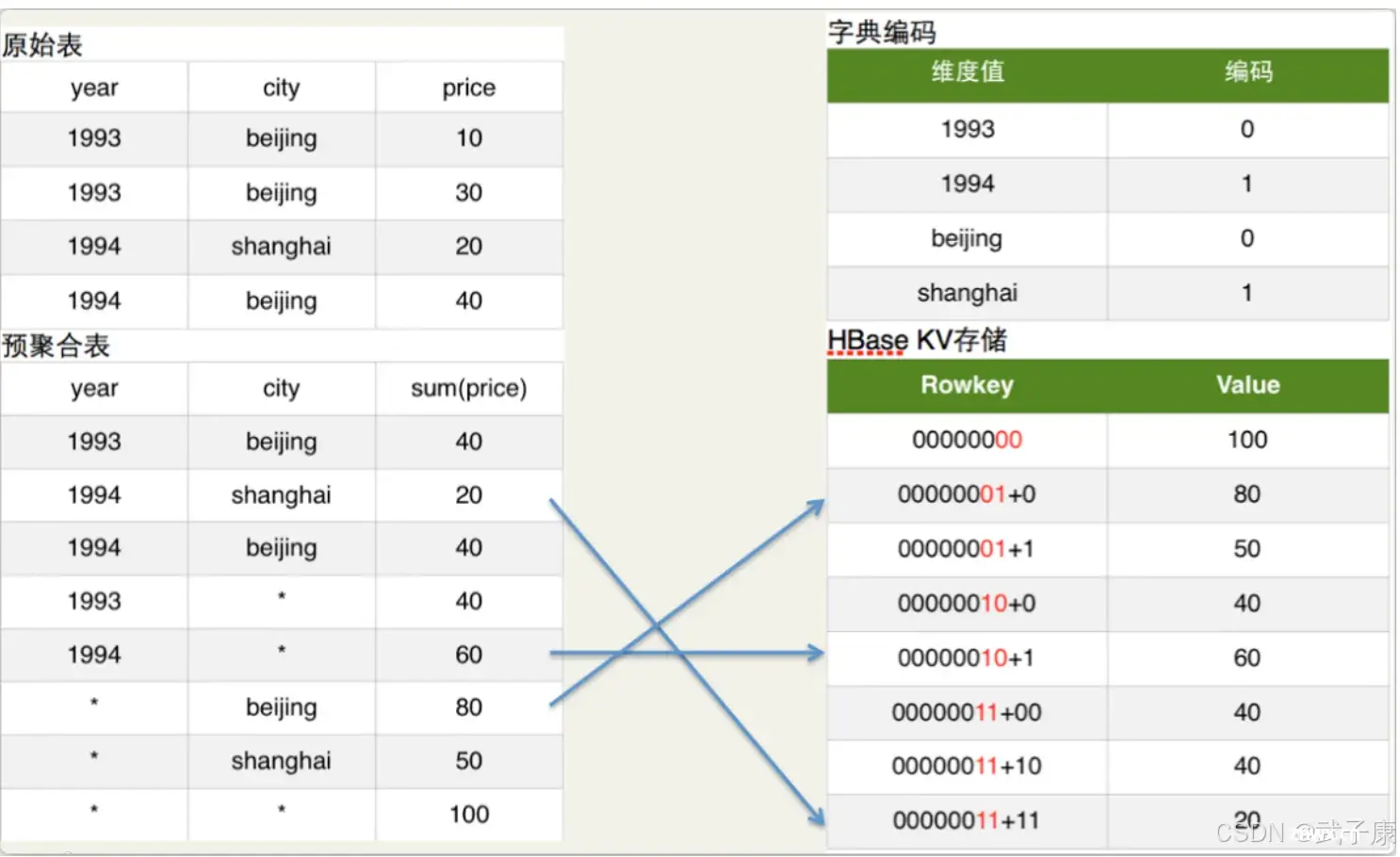
如上图原始表所示:Hive表有两个维度列year、city,有一个指标列 price。如上图预聚合表所示:我们具体要计算的是year和city这两个维度所有维度组合(即4个cuboid)下的sum(prices)指标,这个指标的具体计算过程就由MapReduce完成的。如上图的字典编码所示:为了节省存储资源,Kylin对维度值进行了字典编码,图中将beijing和shanghai依次编码0和1。如上图HBase KV存储所示:在计算Cuboid过程中,会将Hive表的数据转换为HBase的KV形式。Rowkey的具体格式是 Cuboid id + 具体的维度值(最新的Rowkey中为了并发查询还加入了Shard Key),以预聚合表内容的第2行为列,其维度组合是(year,city),所以Cuboid id就是00000011,Cuboid是8位,具体维度值是1994和shanghai,所以编码后的维度值对应上图的字典编码也是11,所以HBase的Rowkey就是00000011,对应HBase Value就是sum(price)的具体值。所有的Cuboid计算完成后,会将Cuboid转换为HBase的KeyValue格式生成HBase的HFile,最后将HFile Load进Cube对应的HBase表中。
编码
Kyelin以Key-Value的方式将Cube存储到HBase中,HBase的Key就是Rowkey,是由各维度的值拼接而成的,为了更高效的的存储这些值,Kylin会对它们进行编码和压缩,每个维度均可以选择合适的编码方式,为了更搞笑存储这些值,Kylin会对它们进行编码和压缩,每个维度均可以选择合适的编码方式,默认采用的是字典(Dictionary)编码技术。字段支持的基本编码类型如下:
Dictionary 字典编码将所有此维度下的值构成一张映射表,从而大大节约存储空间,适用于大部分字段,默认推荐使用。Dictionary产生的编码非常紧凑,尤其在维度的值基数小且长度大的情况下,但在超高基情况下,可能引起内存不足的问题,在Kylin中字典编码允许的基数上限默认是500万(由参数kylin.dictionay.max.cardinality配置)boolean:适用于字段为:ture、false、TURE、FALSE、t、f、T、F、yes、no、YES、NO、y、n、Y、N、1、0date:适用于字段为日期字符,支持的格式包括yyyyMMdd、yyyy-MM-dd、yyyy-MM-dd HH:mm:ss.SSStime:适用于字段为时间戳字符,支持范围为[1970-01-01 00:00:00],[2038-01-09 03:14:07],毫秒部分会被忽略,time编码适用于time、datetime、timestamp等类型fix_length:使用超高基环境,将选取字段的前N个字节为编码值,当N小于字段长度,会造成字段阶段,当N较大时,造成RowKey过长,查询性能下降,只适用于varchar、nvarchar类型fixed_length_hex:适用于字段为十六进制字符,比如1A2BFF或者FF00FF,每两个字符需要一个字节,只适用于varchar或nvarchar类型
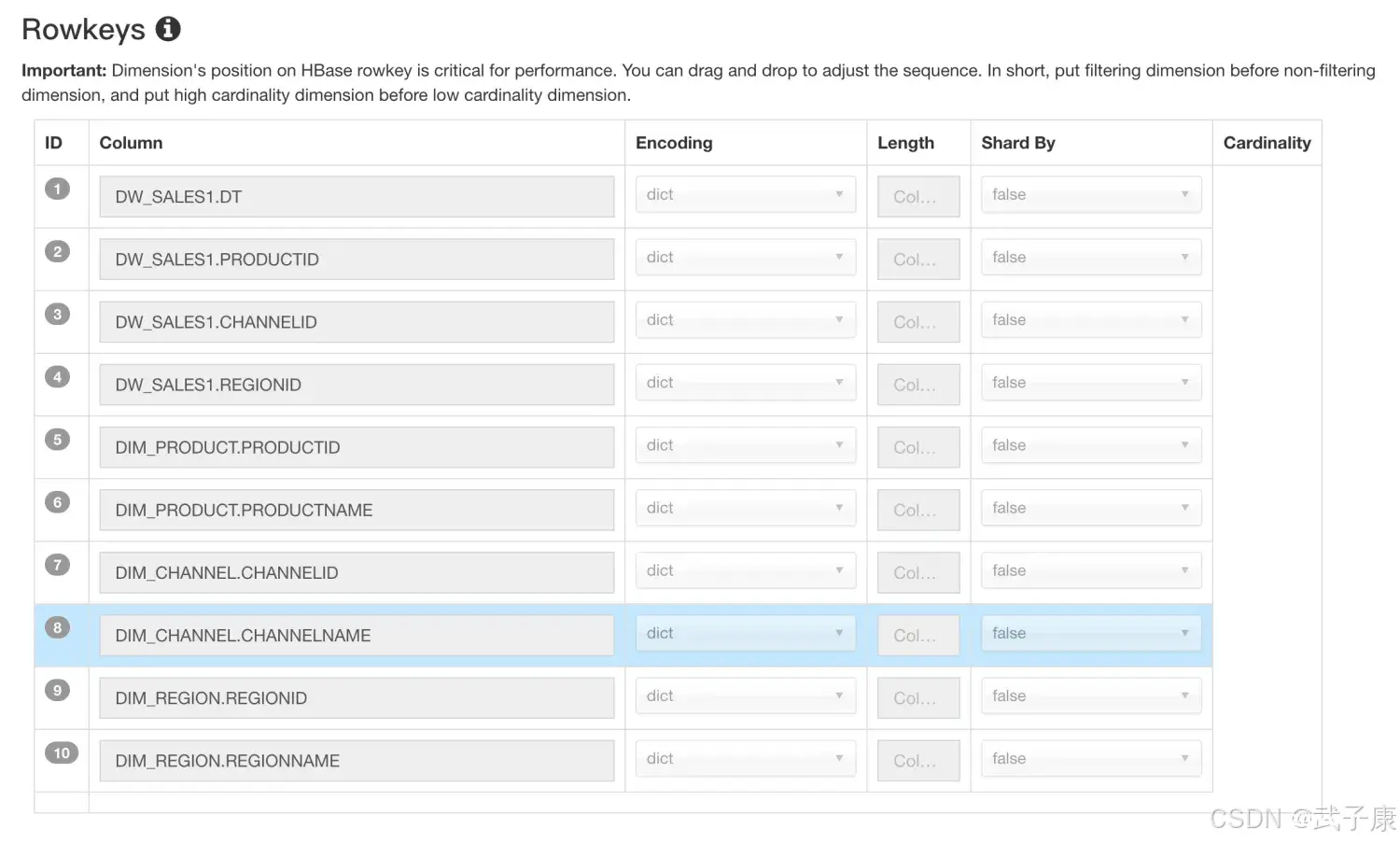
顺序
各维度在RowKeys中的顺序,对于查询的性能会产生较明显的影响,在这里用户可以根据查询的模式和习惯,通过拖拽的方式调整各个维度在RowKeys上的顺序,推荐的顺序为:
Mandatory 维度where 过滤条件中出现频率较多的维度高基数维度低基数维度放后面不常用的维度放在后面
这样做的好处是,充分利用过滤条件来缩小在HBase中扫描的范围,从而提高查询的效率。
分片
指定ShardBy的列,明细数据将按照该列的值分片,没有指定的ShardBy的列,则默认根据所有列中的数据进行分片,选择适当的ShardBy列,可以使明细数据较为均匀的分散在多个数据片上,提高并行性,进而获得更理想的查询。
建议选择基数较大的列作为ShardBy列,以避免数据分散不均匀。
上一篇: 关于使用v2rayn开启服务时报Failed to start的错误解决方法
下一篇: 2024全网最为详细的红帽系列【RHCSA-(13)】初级及进阶Linux保姆级别骚操作教程;[就怕你日后学成黑客了]
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。