大数据-153 Apache Druid 案例 从 Kafka 中加载数据并分析
CSDN 2024-10-09 08:37:01 阅读 55
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已更完)Kudu(已更完)Druid(正在更新…)
章节内容
上节我们完成了如下的内容:
通过两篇来完成 集群模式配置、集群模式启动

基本介绍
Apache Druid 从 Kafka 中获取数据并进行分析的流程通常分为以下几个步骤:
Kafka 数据流的接入: Druid 通过 Kafka Indexing Service 直接从 Kafka 中摄取实时流数据。Kafka 是一个高吞吐量的消息队列,适合处理大量实时数据。Druid 会订阅 Kafka 的 topic,每当新数据到达时,它会自动从 Kafka 中读取数据。
数据解析与转换: 数据从 Kafka 进入 Druid 后,首先会进行数据解析,通常采用 JSON、Avro 或 CSV 格式。解析的过程中,Druid 可以根据预定义的 schema 进行字段映射、过滤和数据转换,比如将字符串转为数值类型、提取时间戳等。这一步允许对数据进行初步处理,比如数据清洗或格式化。
实时数据摄取与索引: Druid 将解析后的数据放入一个实时索引中,同时也将数据存储在内存中。Druid 的一个核心特点是,它会为每条记录生成倒排索引和 bitmap 索引,这样可以大大加快查询速度。实时摄取的数据在内存中保存一段时间,直到满足一定条件(比如时间或数据量),然后会以段的形式写入深度存储(如 HDFS 或 S3)。
批处理与历史数据合并: Druid 支持实时和批处理的混合模式。当实时摄取的数据段被持久化到深度存储后,Druid 可以自动将这些段与批处理数据合并。这种设计确保了在数据分析时,既能查询到最新的实时数据,也能访问历史数据。批处理数据可以通过 Hadoop 或 Spark 等框架预先批量加载到 Druid 中。
数据分片与副本管理: Druid 支持水平扩展,通过分片将数据分布在多个节点上。每个分片可以有多个副本,这样可以保证系统的高可用性和容错性。通过负载均衡,Druid 可以有效处理大规模查询请求,尤其是在数据量非常大的情况下。
查询与分析: Druid 的查询系统基于 HTTP/JSON API,支持多种类型的查询,如时间序列查询、分组聚合查询、过滤查询等。Druid 的查询引擎设计非常高效,可以处理大规模的 OLAP(在线分析处理)查询。由于 Kafka 中的数据是实时流式的,Druid 的查询结果通常可以反映出最新的业务指标和分析结果。
可视化与监控: Druid 的数据可以与 BI 工具(如 Superset、Tableau)集成,生成实时的报表和仪表盘。用户可以通过这些可视化工具,实时监控业务指标,做出数据驱动的决策。
整个流程中,Druid 负责将 Kafka 中的数据转化为高效的、可查询的 OLAP 格式,并且通过索引和分布式架构实现高效查询。这个系统可以被广泛应用于实时监控、用户行为分析、金融交易分析等场景。
从Kafka中加载数据
典型架构
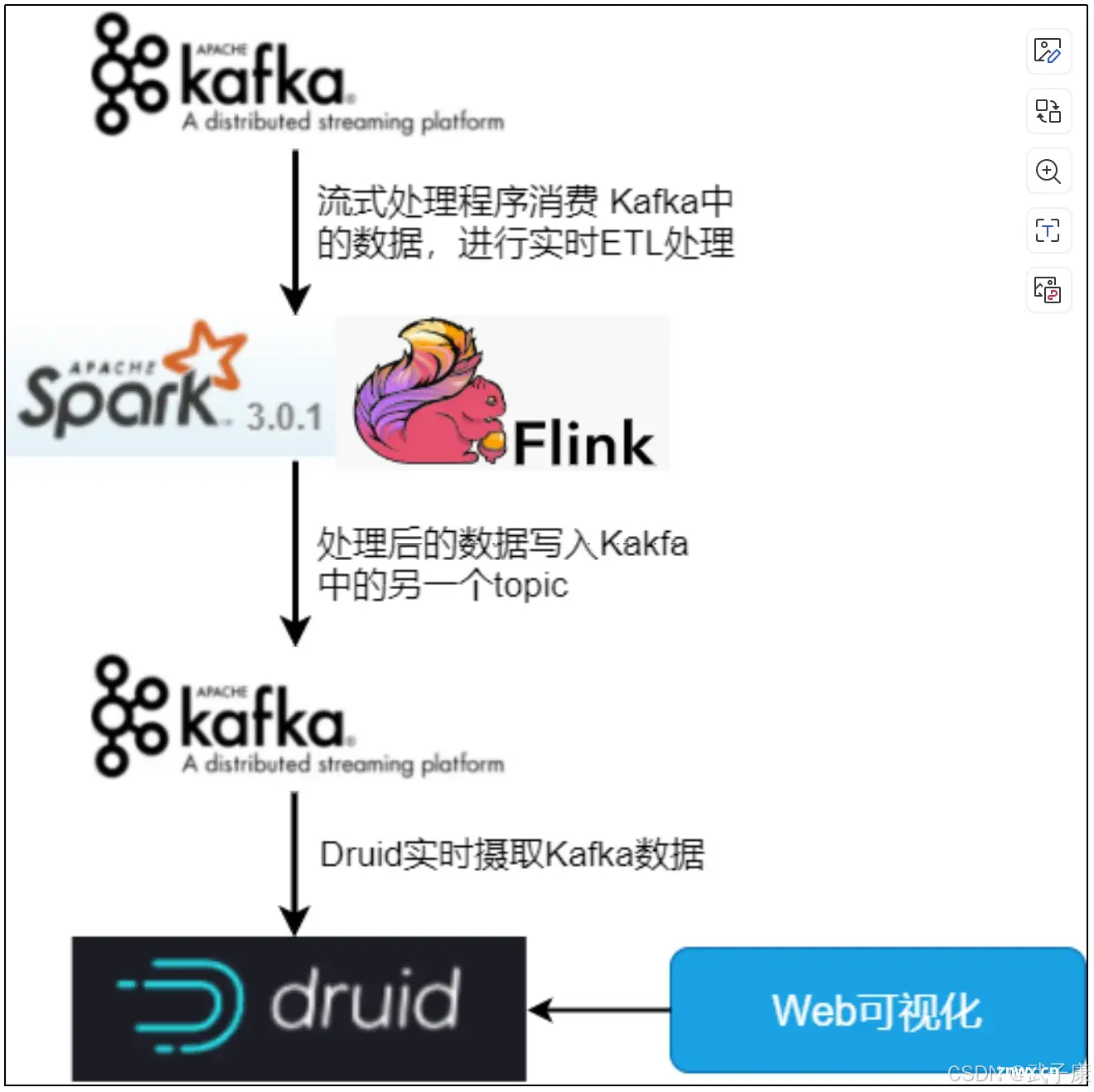
日志业务中,我们不会在Druid中处理复杂的数据转换清晰工作
案例测试
假设有以下网络流量数据:
ts:时间戳srcip:发送端IP地址srcport:发送端端口号dstip:接收端IP地址dstport:接收端端口号protocol:协议packets:传输包bytes:传输的字节数cost: 传输耗费的时间
数据是JSON格式,通过Kafka传输
每行数据包含:
时间戳维度列指标列
需要计算的指标:
记录的条数:countpackets:maxbytes:mincost:sum
数据汇总粒度:分钟
测试数据
<code>{ "ts":"2020-10-01T00:01:35Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666,"dstPort":8888, "protocol": "tcp", "packets":1, "bytes":1000, "cost": 0.1}
{ "ts":"2020-10-01T00:01:36Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666,"dstPort":8888, "protocol": "tcp", "packets":2, "bytes":2000, "cost": 0.1}
{ "ts":"2020-10-01T00:01:37Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666,"dstPort":8888, "protocol": "tcp", "packets":3, "bytes":3000, "cost": 0.1}
{ "ts":"2020-10-01T00:01:38Z","srcip":"6.6.6.6", "dstip":"8.8.8.8", "srcport":6666,"dstPort":8888, "protocol": "tcp", "packets":4, "bytes":4000, "cost": 0.1}
{ "ts":"2020-10-01T00:02:08Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666,"dstPort":8888, "protocol": "udp", "packets":5, "bytes":5000, "cost": 0.2}
{ "ts":"2020-10-01T00:02:09Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666,"dstPort":8888, "protocol": "udp", "packets":6, "bytes":6000, "cost": 0.2}
{ "ts":"2020-10-01T00:02:10Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666,"dstPort":8888, "protocol": "udp", "packets":7, "bytes":7000, "cost": 0.2}
{ "ts":"2020-10-01T00:02:11Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666,"dstPort":8888, "protocol": "udp", "packets":8, "bytes":8000, "cost": 0.2}
{ "ts":"2020-10-01T00:02:12Z","srcip":"1.1.1.1", "dstip":"2.2.2.2", "srcport":6666,"dstPort":8888, "protocol": "udp", "packets":9, "bytes":9000, "cost": 0.2}
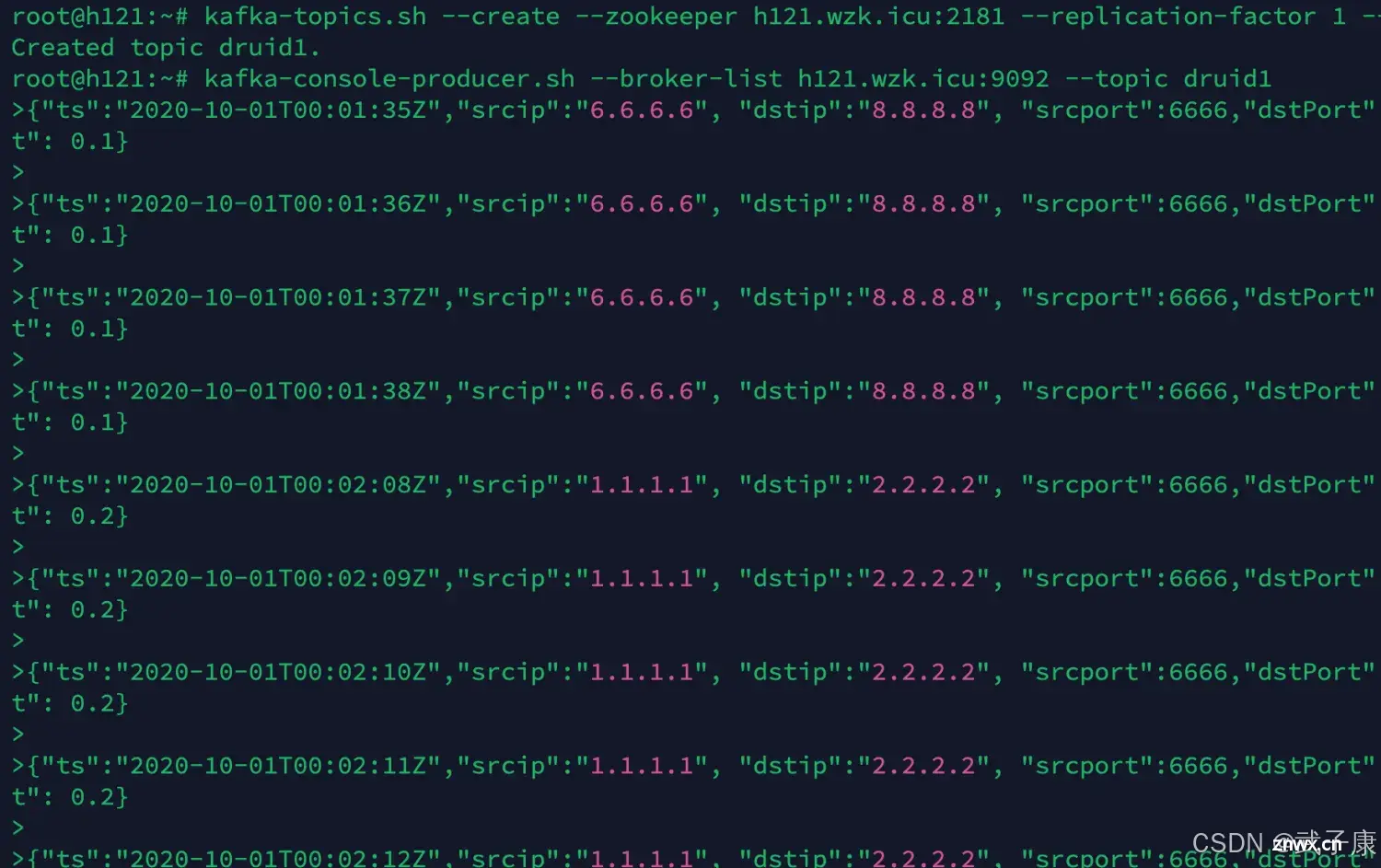
写入的数据如下所示:
启动Kafka
这里由于资源比较紧张,我就只启动一台Kafka了:
我在 h121 节点上启动
<code>kafka-server-start.sh /opt/servers/kafka_2.12-2.7.2/config/server.properties
创建 Topic
kafka-topics.sh --create --zookeeper h121.wzk.icu:2181 --replication-factor 1 --partitions 1 --topic druid1
推送消息
kafka-console-producer.sh --broker-list h121.wzk.icu:9092 --topic druid1
输出我们刚才的数据,一行一行的写入输入进行(后续要用)。
提取数据
浏览器打开我们之前启动的Druid服务
<code>http://h121.wzk.icu:8888/
LoadData
点击控制台中的 LoadData 模块:
Streaming
选择 Streaming:
Kafka
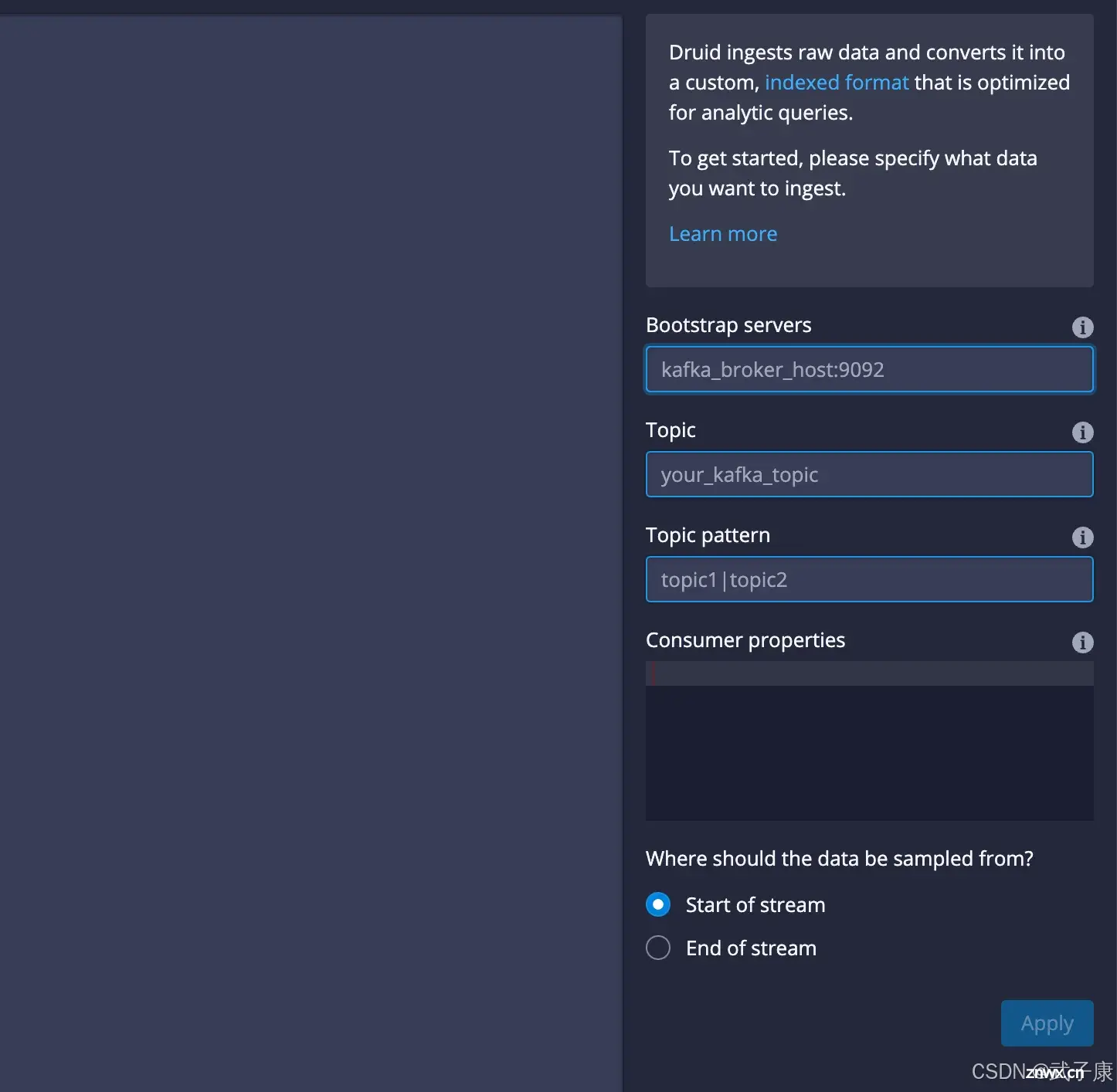
继续选择Kafka,点击 ConnectData,在右侧输入对应的信息,点级Apply:
h121.wzk.icu:9092druid1
ParserData
此时可以看到右下角有:Next: Parse Data:
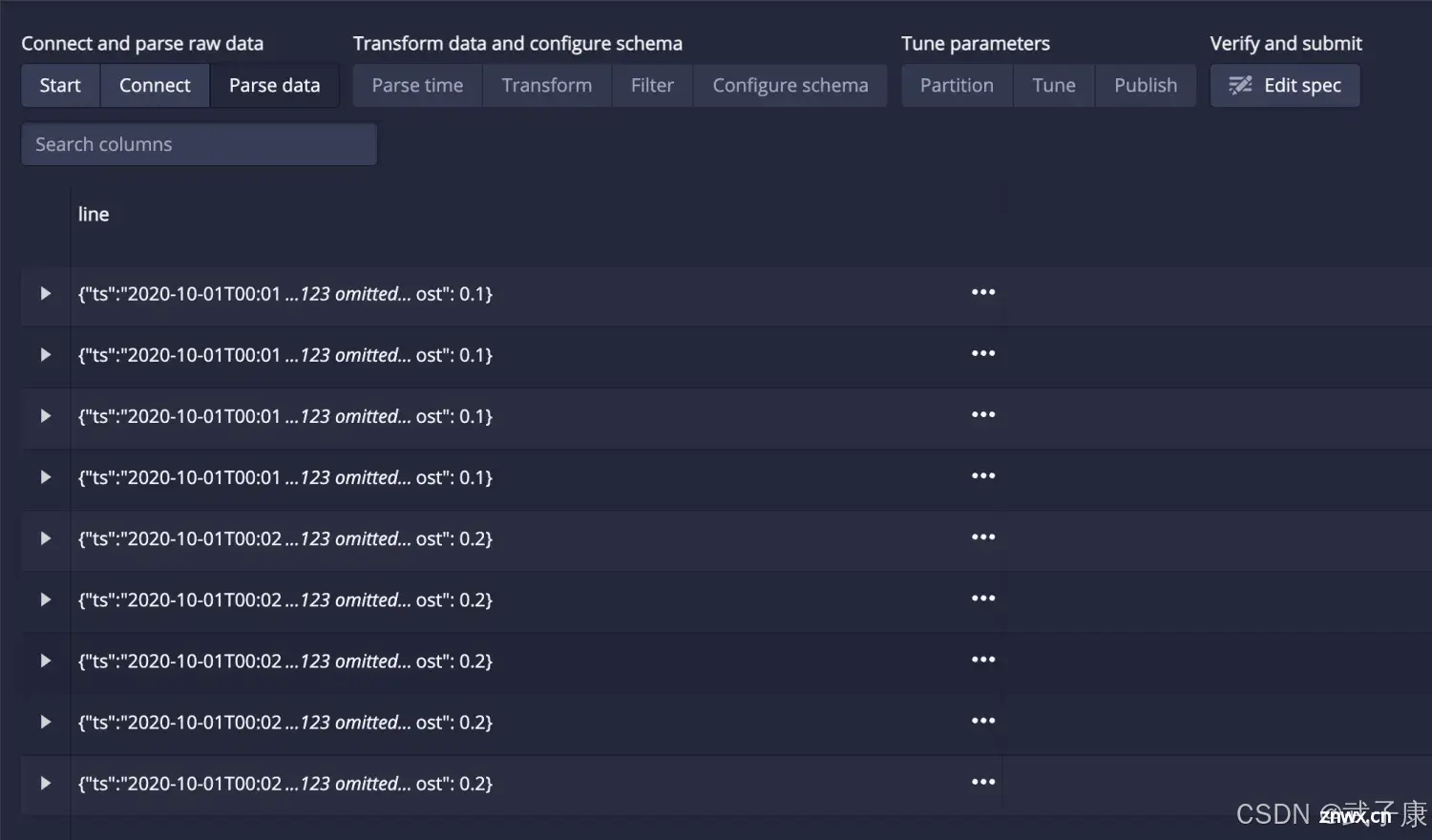
数据虽然加载了,但是格式不对,我们在右侧选择:JSON:
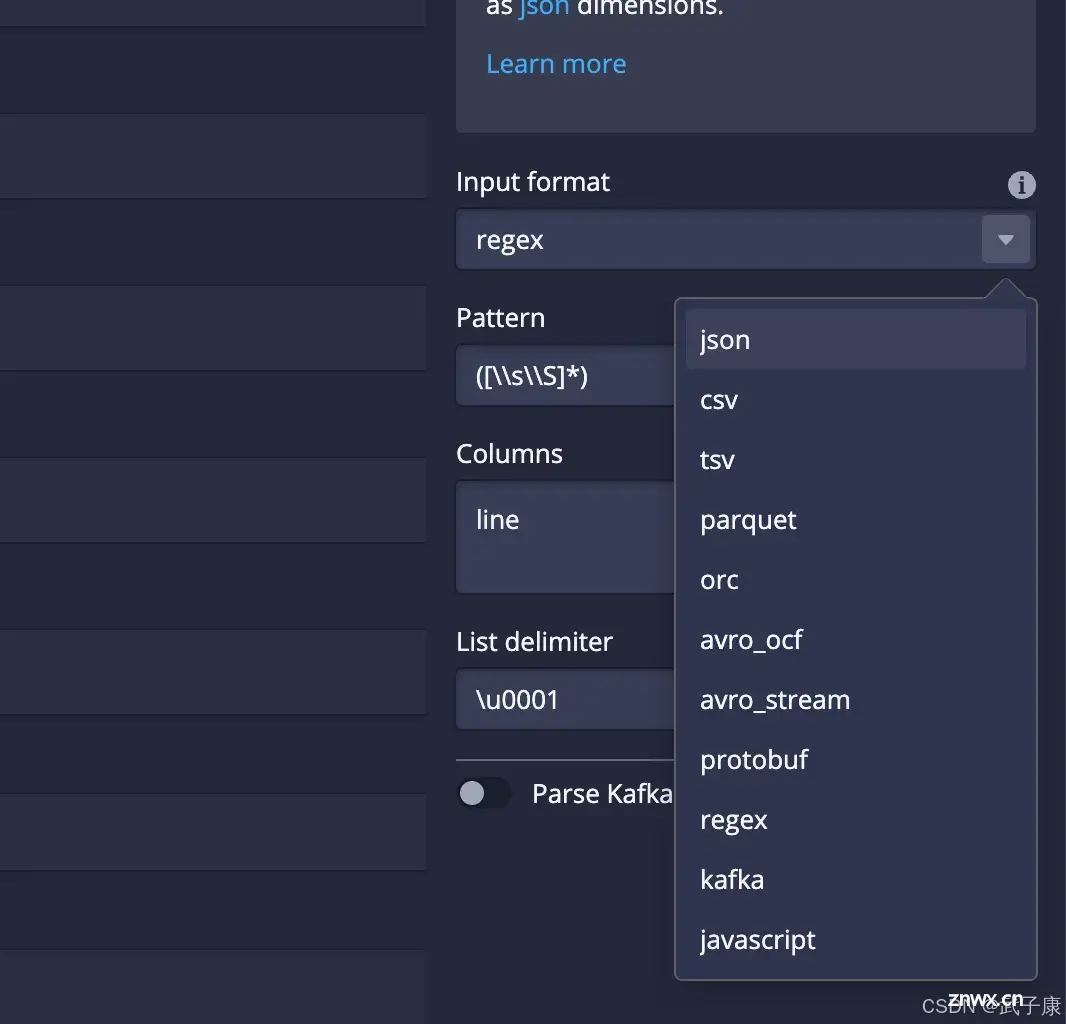
点击之后,可以看到,(如果你解析不顺利,可以用这个尝试)点击 Add column flattening
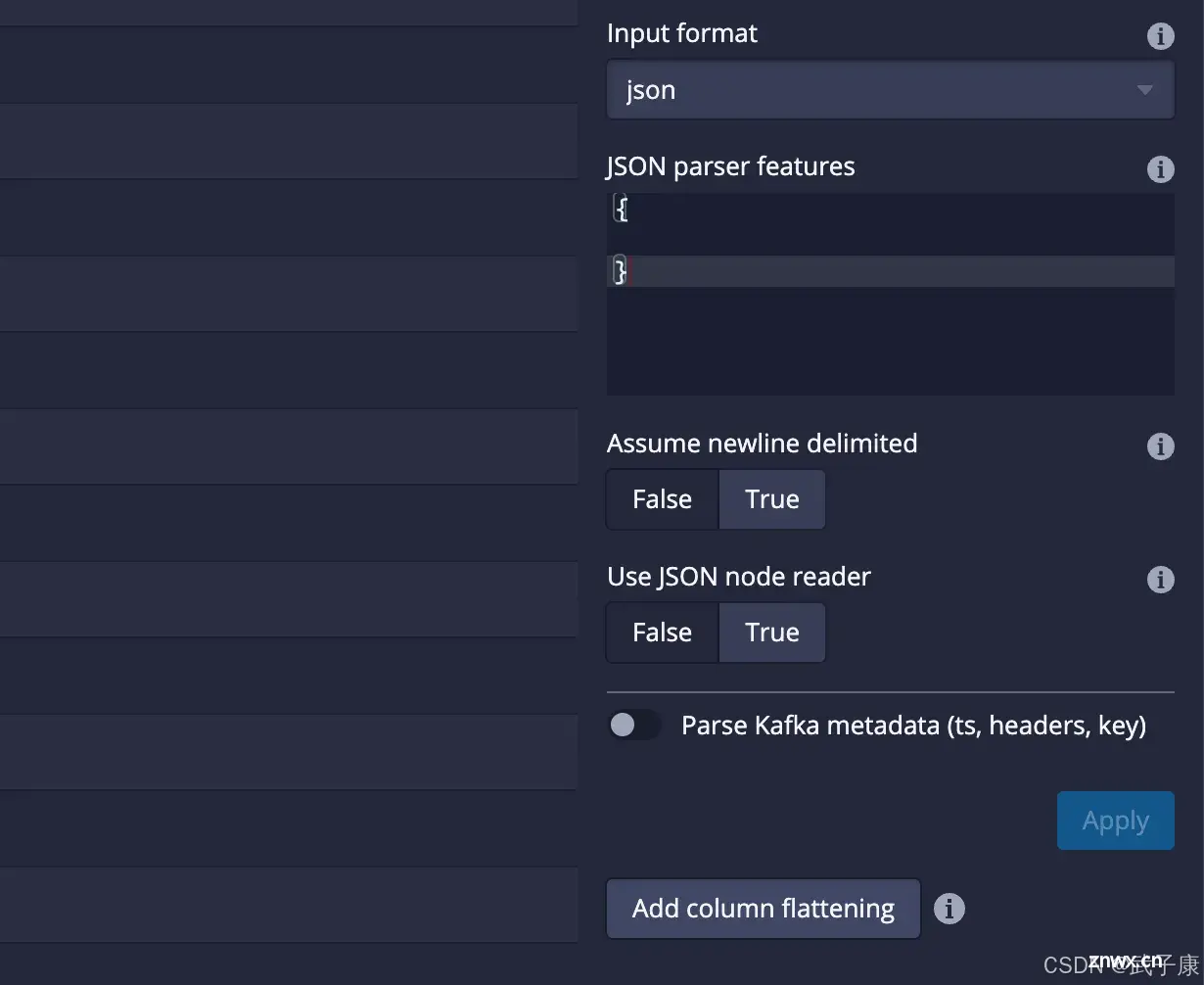
如果正常解析,数据应该是这个样子:
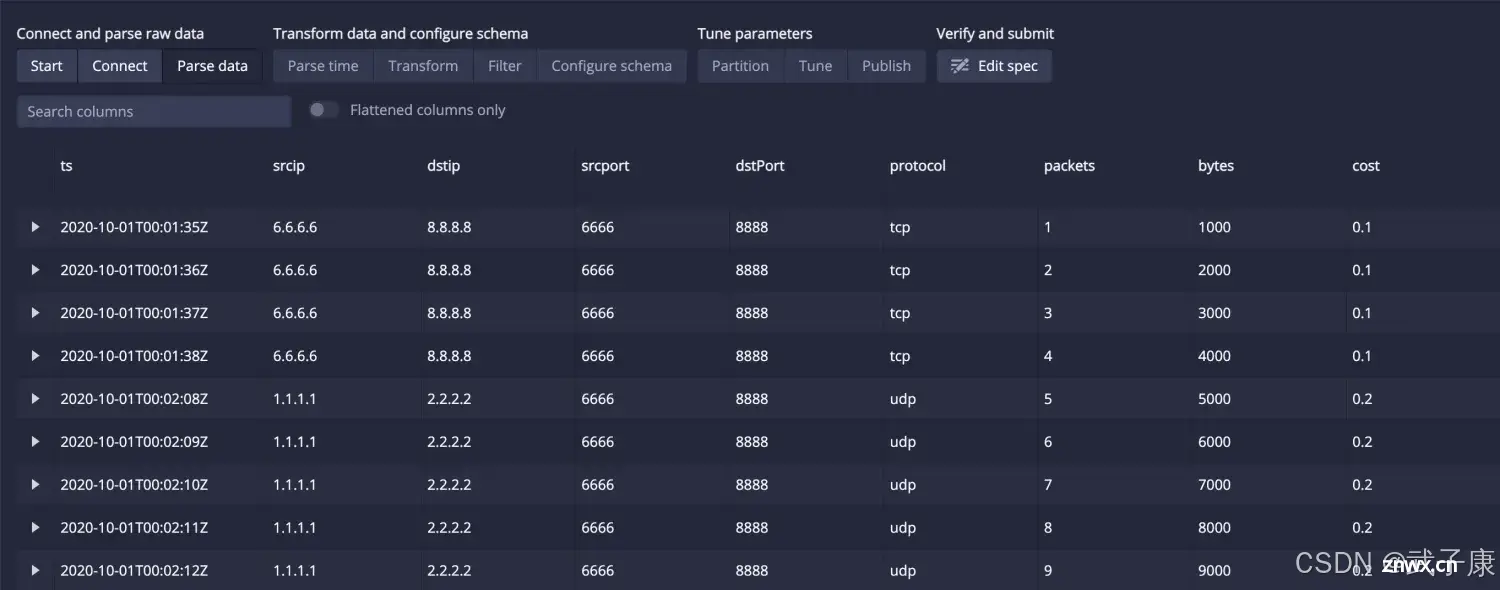
ParserTime
继续点击 Next Parse Time:
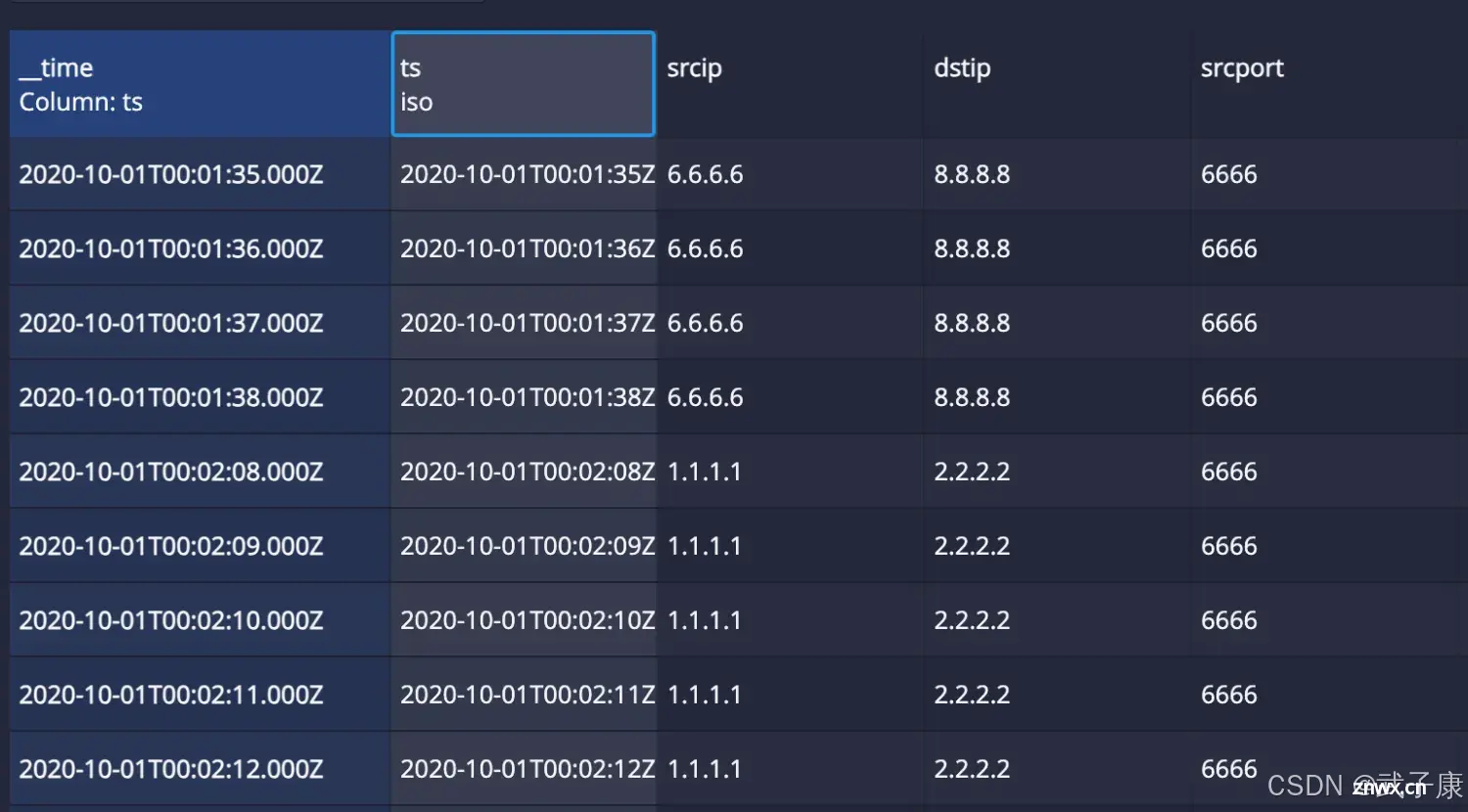
Transform
继续点击 Next Transform:
不建议在Druid中进行复杂的数据变化操作,可考虑将这些操作放在数据预处理的过程中处理这里没有定义数据转换
Filter
继续点击 Next Filter:
不建议在Druid中进行复杂的数据过滤操作,可以考虑将这些操作放在数据预处理中这里没有定义数据过滤
Configuration Schema
点击 Next Configuration Schema:
定义指标列、维度列定义如何在维度列上进行计算定义是否在摄取数据时进行数据的合并(即RollUp),以及RollUp的粒度
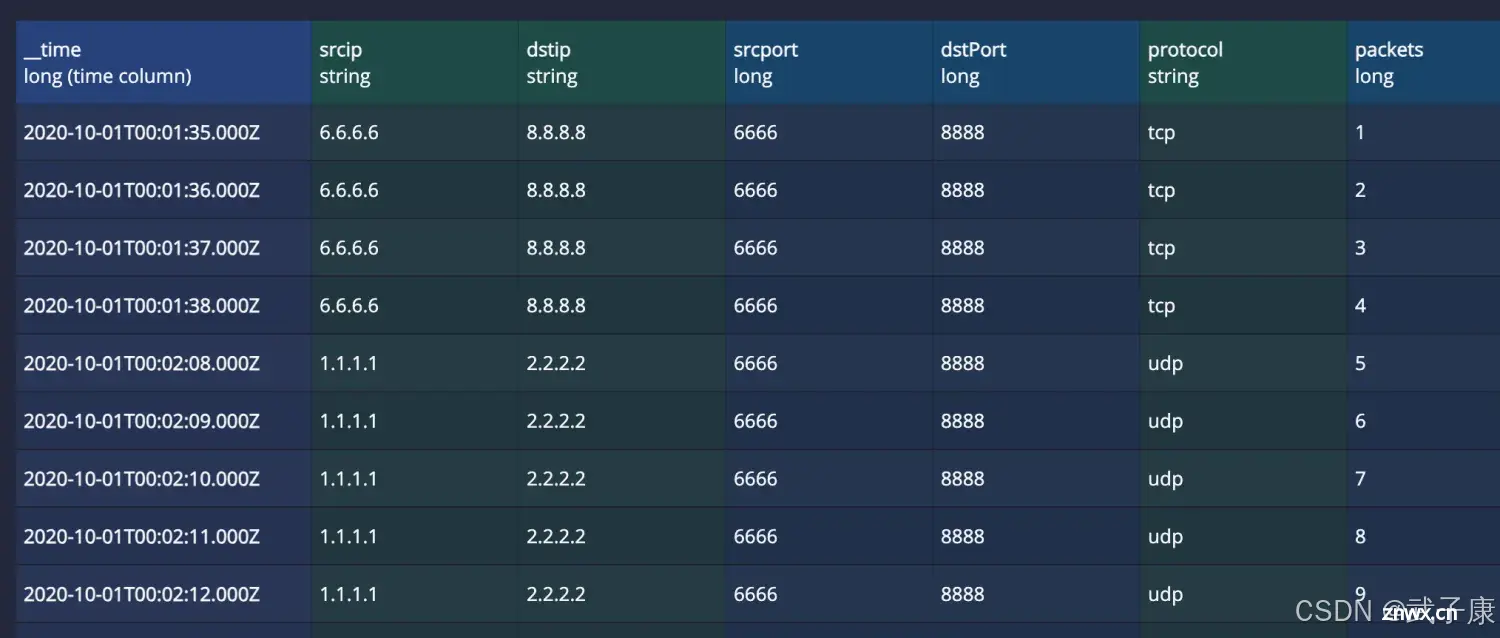
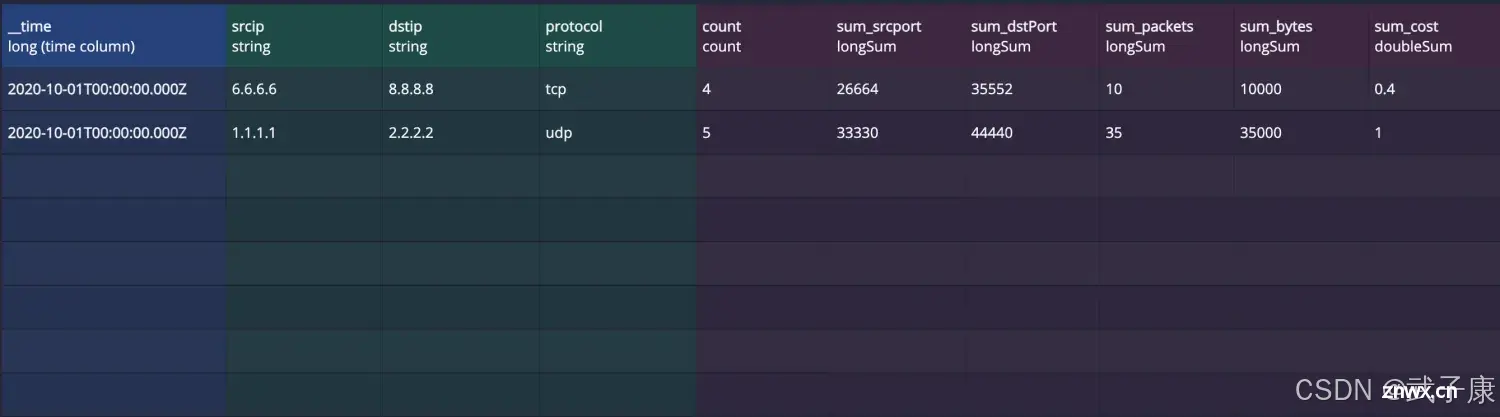
此时点击右侧的:RollUp,会看到数据被聚合成了两条:
聚合结果:
Partition
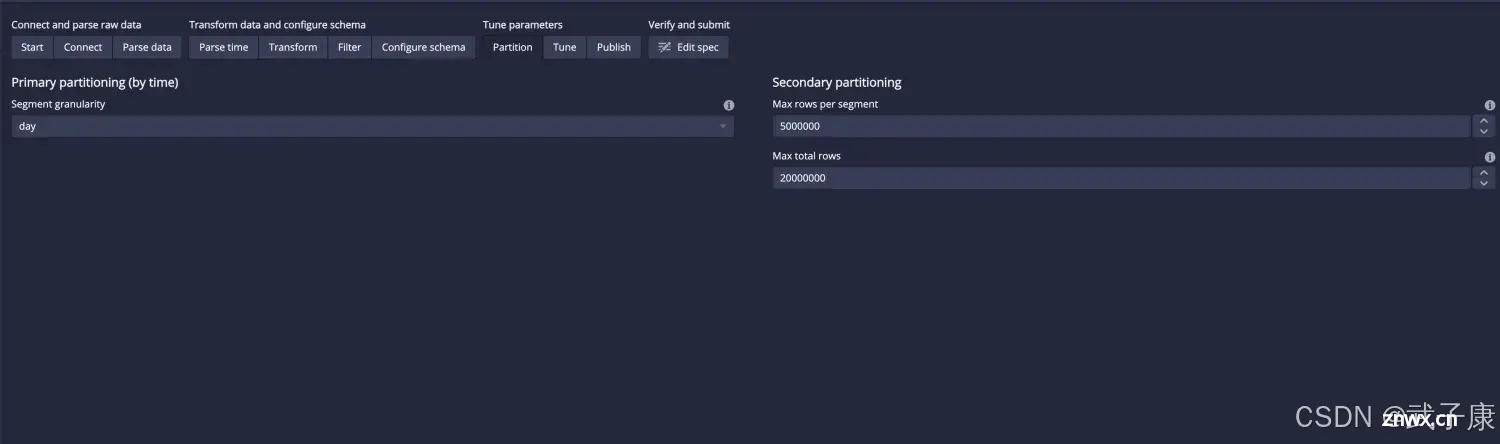
点击 Next Partition:
定义如何进行数据分区Primary partitioning 有两种方式:方式1:uniform,以一个固定的时间间隔聚合函数数据,建议使用这种方式,这里将每天的数据作为一个分区方式2:arbitary,尽量保证每个 segements大小一致,时间间隔不固定Secondary Partitioning参数1:Max rows per segment,每个Segment最大的数据条数参数2:Max total rows,Segment等待发布的最大数据条数
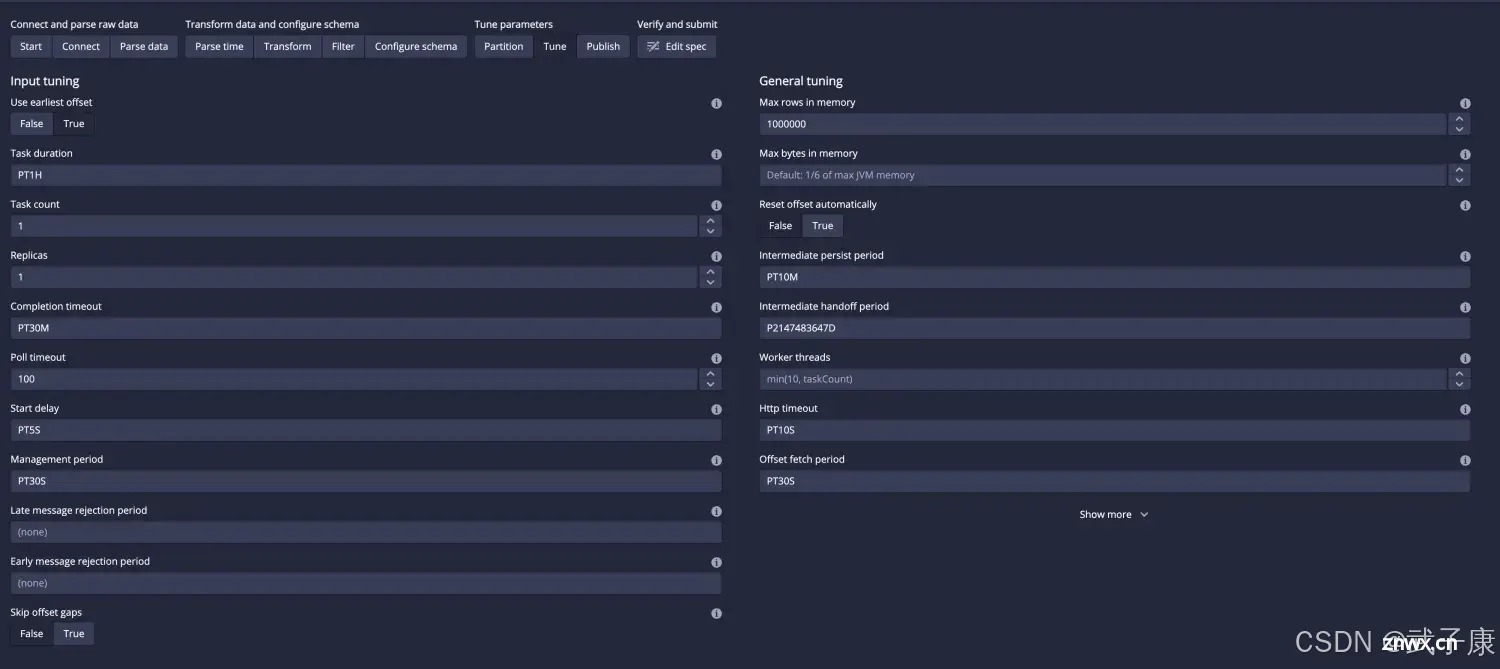
Tune
点击 Next Tune:
定义任务执行和优化相关的参数
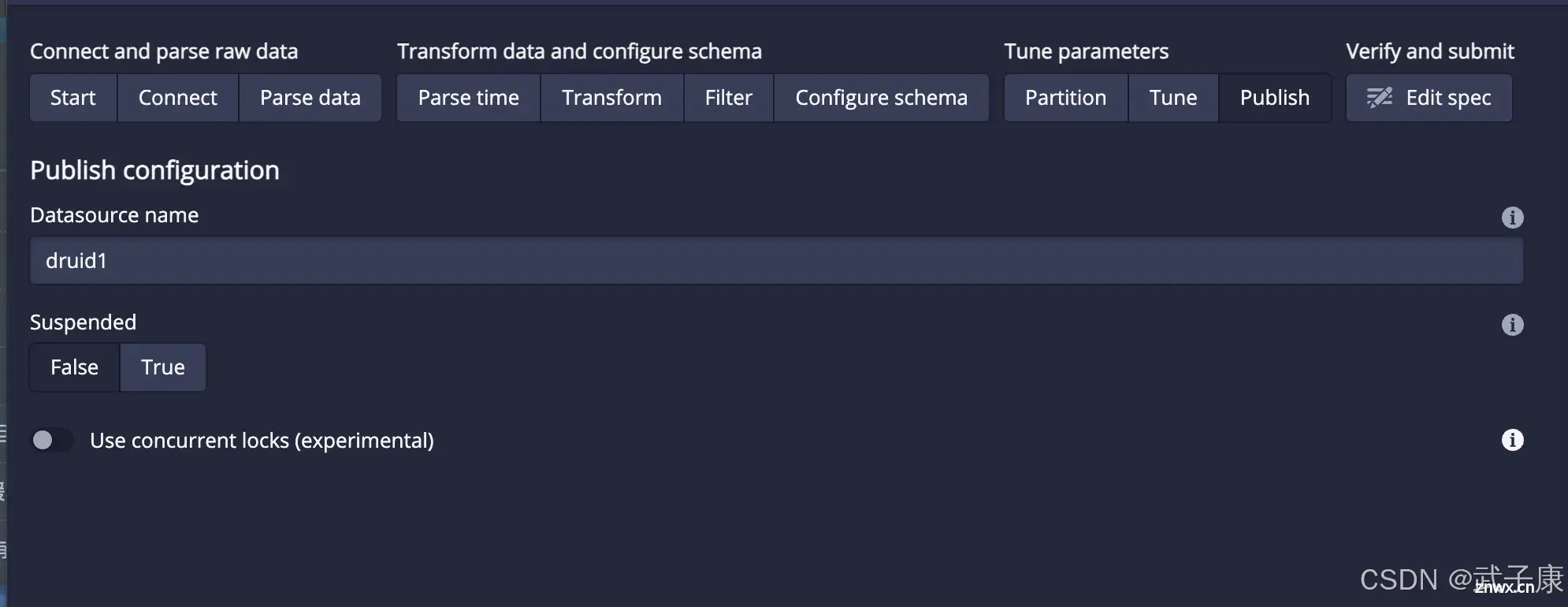
Publish
点击 Next Publish:
定义Datasource的名称定义数据解析失败后采取的动作
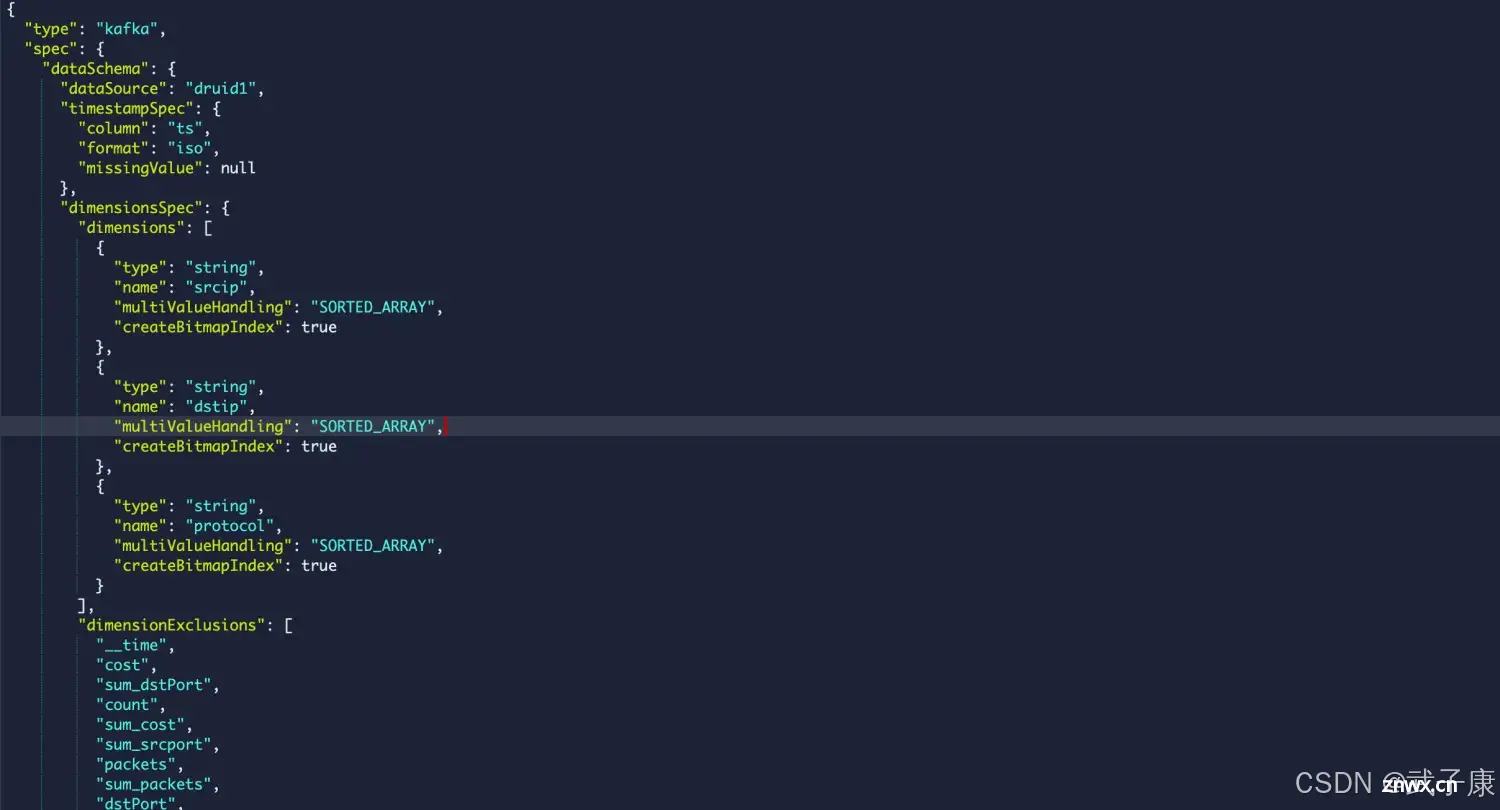
Edit Special
点击 Next Edit spec:
JSON串为数据摄取规范,可返回之前的步骤中进行修改,也可以直接编辑规范内容,并在之前的步骤可以看到修改的结果摄取规范定义完成后,点击Submit会创建一个数据摄取的任务
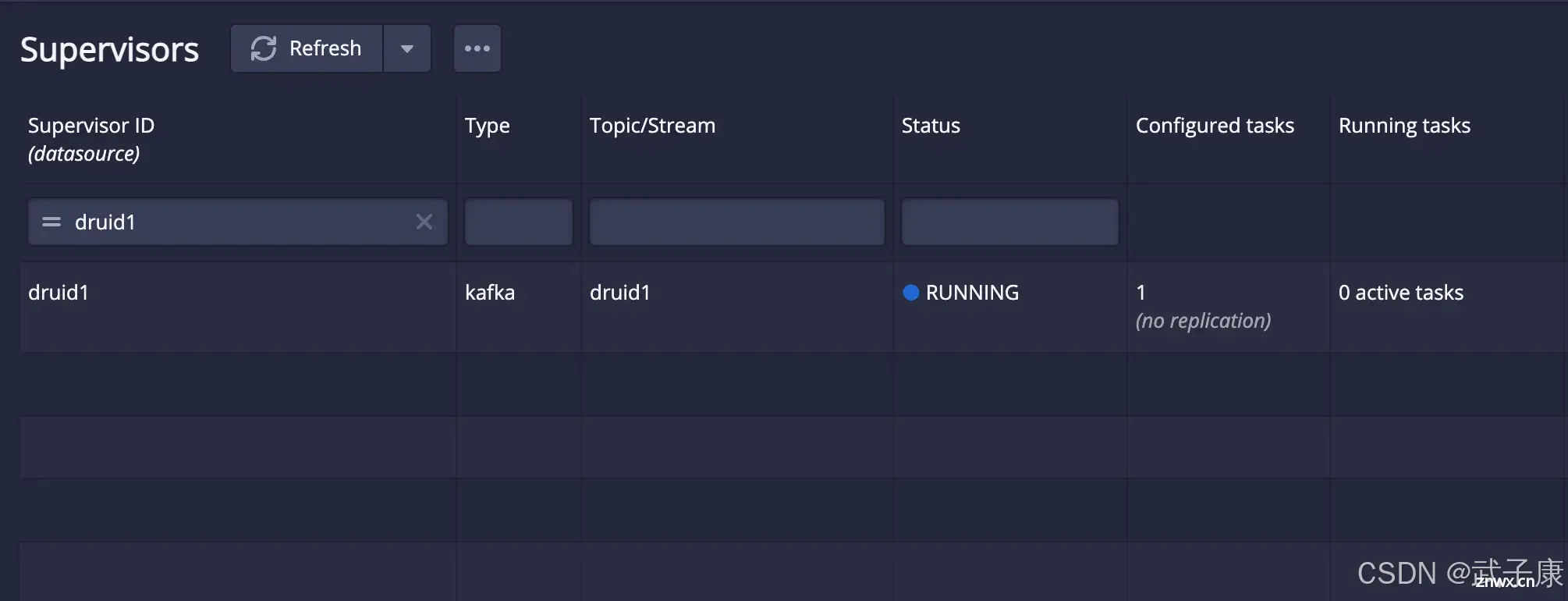
Submit
点击 Submit 按钮:
数据查询
数据摄取规范发布后生成SupervisorSupervisor会启动一个Task,从kafka中摄取数据
需要等待一段时间,Datasource才会创建完毕,选择 【Datasources】板块:
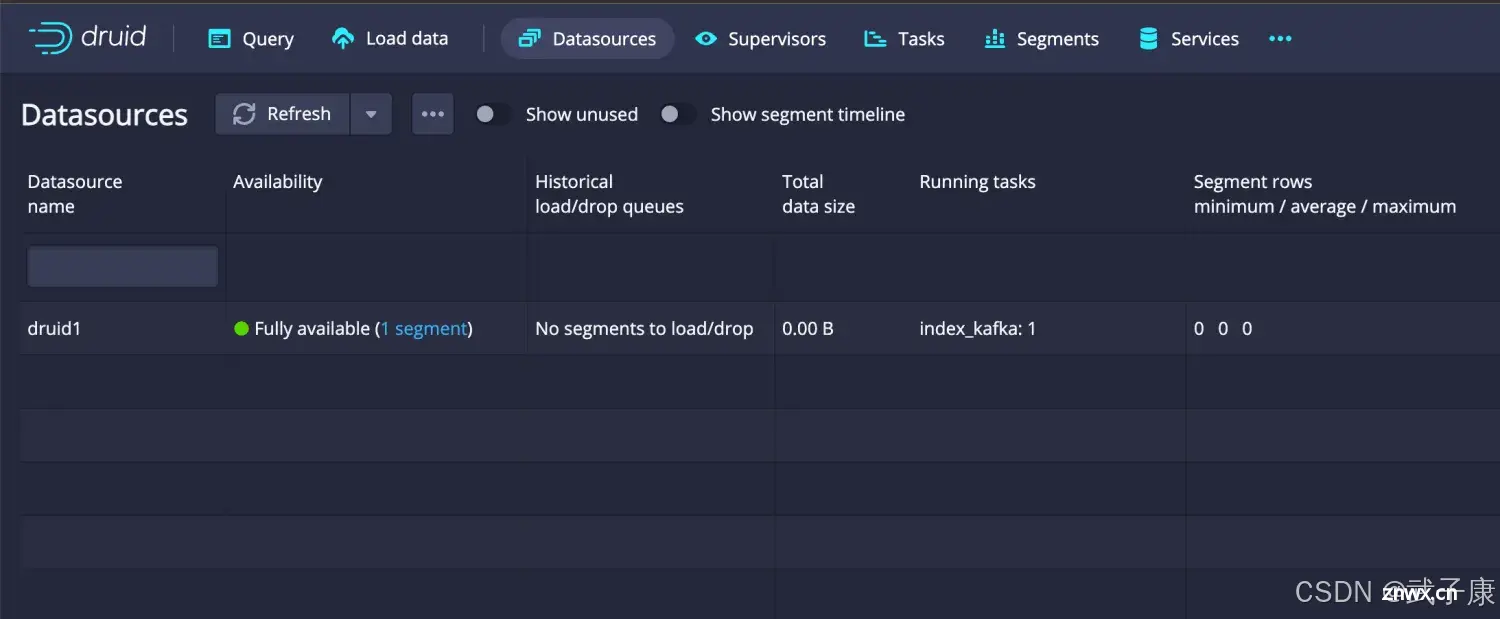
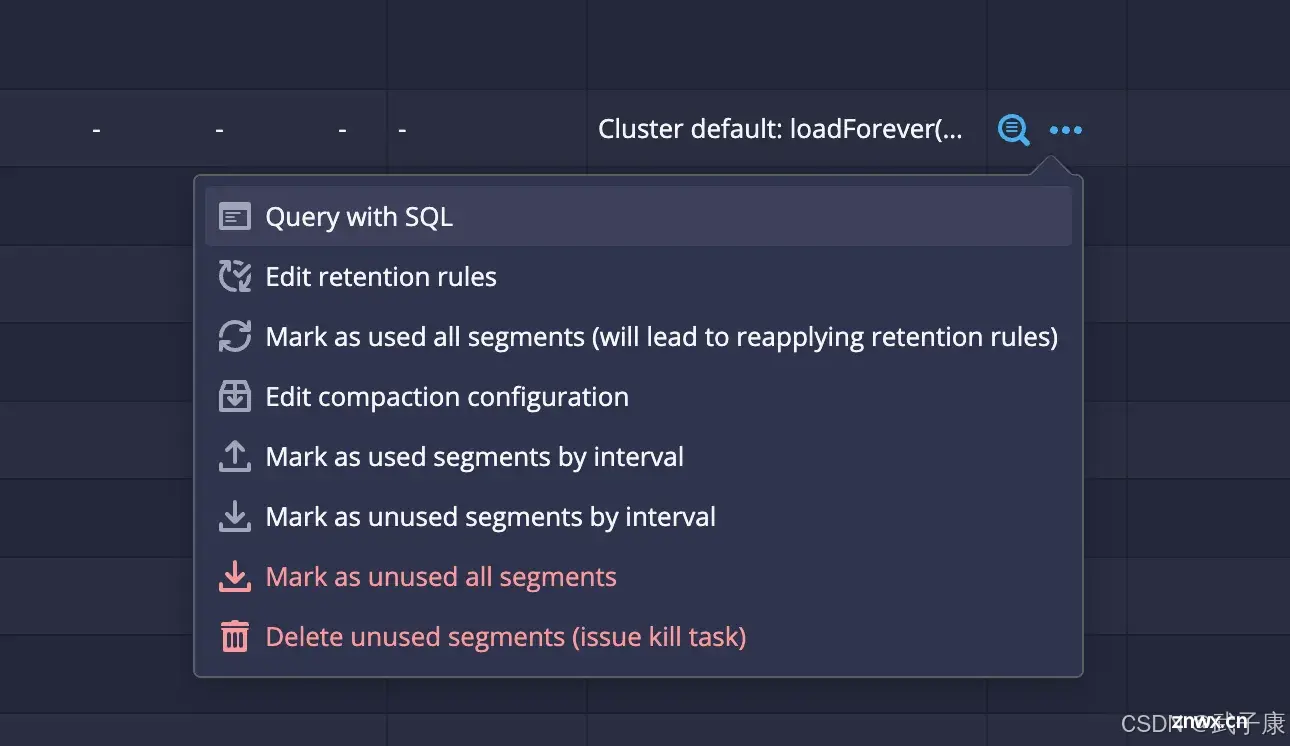
点击末尾的三个小圆点,选择 Query With SQL:
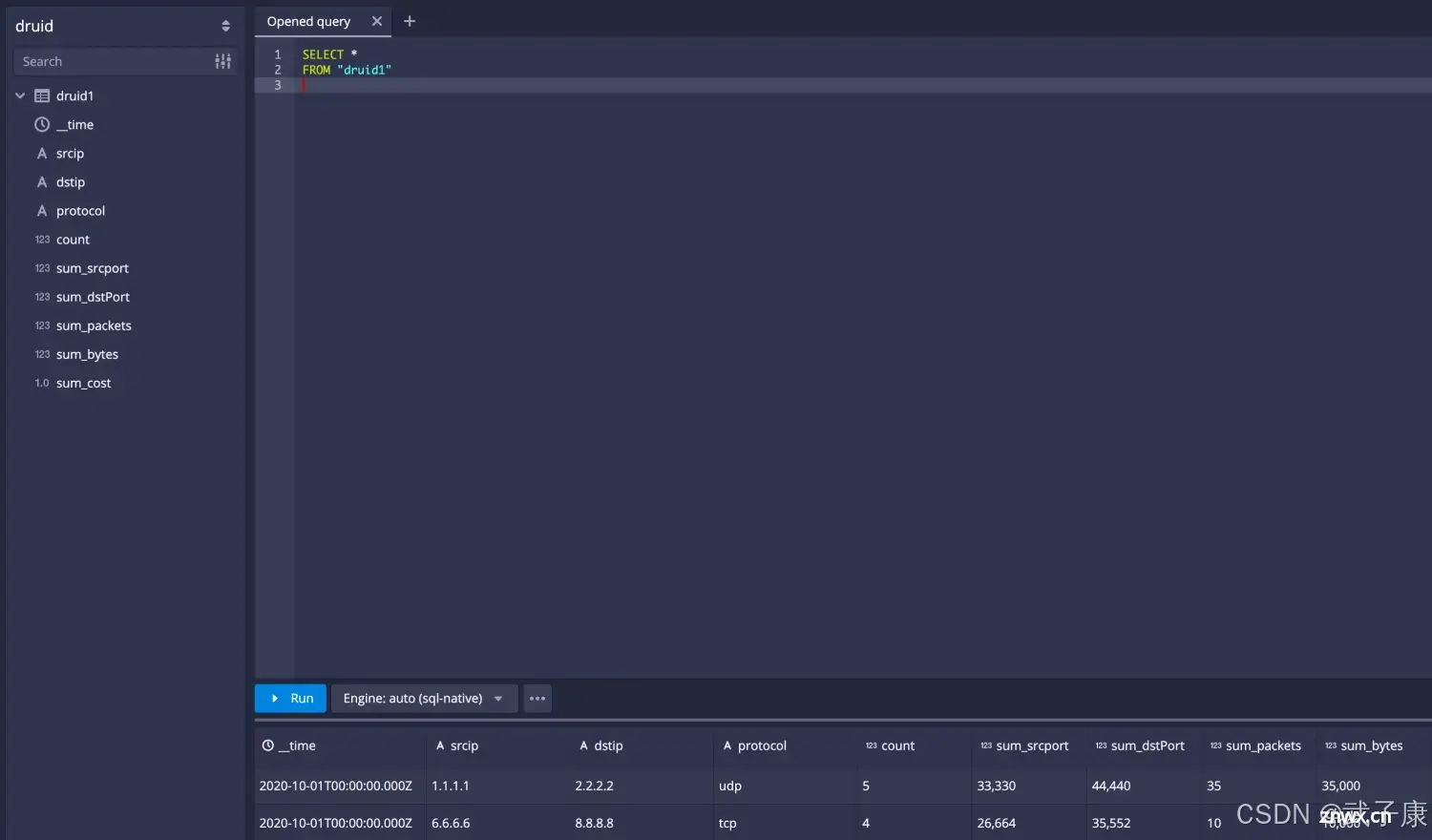
会出现如下的界面,我们写入SQL,并运行:
<code>SELECT
*
FROM
"druid1"
执行结果如下图:
数据摄取规范
<code>{
"type":"kafka",
"spec":{
"ioConfig":Object{ ...},
"tuningConfig":Object{ ...},
"dataSchema":Object{ ...}
}
}
dataSchema:指定传入数据的SchemaioConfig:指定数据的来源和去向tuningConfig:指定各种摄取参数
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。