大数据-150 Apache Druid 安装部署 单机启动 系统架构
CSDN 2024-10-23 16:07:03 阅读 90
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已更完)Kudu(已更完)Druid(正在更新…)
章节内容
上节我们完成了如下的内容:
Apache Druid 基本介绍Apache Druid 技术特点Apache Druid 应用场景

系统架构
Apache Druid 是一个高性能的实时分析数据库,专为快速聚合和查询大规模数据集而设计。它的架构由多个组件组成,每个组件在数据的存储、处理和查询中发挥重要作用。
(部分内容上节已经有了)
核心组件
数据摄取层 (Ingestion Layer)
数据源: Druid 支持多种数据源,如 Kafka、HDFS、Amazon S3 等。数据摄取可以是批处理(Batch)或实时流处理(Streaming)。任务管理: 使用任务协调器来管理数据摄取任务,确保数据流的顺畅和高可用性。
数据存储层 (Storage Layer)
Segment: Druid 将数据分为多个小块,称为“段”(Segment)。每个段通常包含一段时间内的数据,并被优化以支持快速查询。
时间分区: Druid 根据时间将数据分区,以提高查询性能。数据按时间戳索引,有助于高效的时间范围查询。
查询层 (Query Layer)
Broker: 负责接收用户的查询请求并将其路由到相应的数据节点(如历史节点和实时节点)。查询执行: Druid 支持多种查询类型,包括聚合查询、过滤查询和分组查询。查询结果会通过 Broker 返回给用户。
历史节点 (Historical Node)
存储并管理长时间的数据段,负责处理对历史数据的查询。
实时节点 (Real-time Node)
用于实时摄取数据,实时处理并生成可查询的段。适合需要低延迟数据访问的应用。
协调节点 (Coordinator Node)
负责管理 Druid 集群的各个节点,监控节点的健康状态、数据分布和负载均衡。
数据流动
数据摄取: 数据从外部源流入 Druid(如 Kafka 消息队列),经过任务管理和转换后被摄取。数据存储: 数据被分段并存储在历史节点和实时节点中,按时间分区和压缩以优化存储。查询处理: 用户通过查询接口(如 SQL 或 Druid 特定的查询语言)发送查询请求,Broker 节点将请求分发到相应的数据节点,聚合和处理查询结果后返回。
查询优化
列式存储: Druid 采用列式存储格式,提高了压缩率和查询性能。索引: Druid 会为每个字段建立索引,加速过滤和聚合操作。预聚合: 对常用的聚合操作进行预计算,以减少实时查询的计算负担。
可扩展性与高可用性
Druid 支持横向扩展,可以根据需求添加更多的节点来处理更大的数据集和更高的查询负载。数据冗余和节点监控机制确保了系统的高可用性。
下载解压
官方目前已经到了版本30了
<code>wget https://dlcdn.apache.org/druid/30.0.0/apache-druid-30.0.0-bin.tar.gz
直接结果如下图所示:

进行解压:
<code>tar -zxvf apache-druid-30.0.0-bin.tar.gz
执行结果如下图所示:
移动到目标目录:
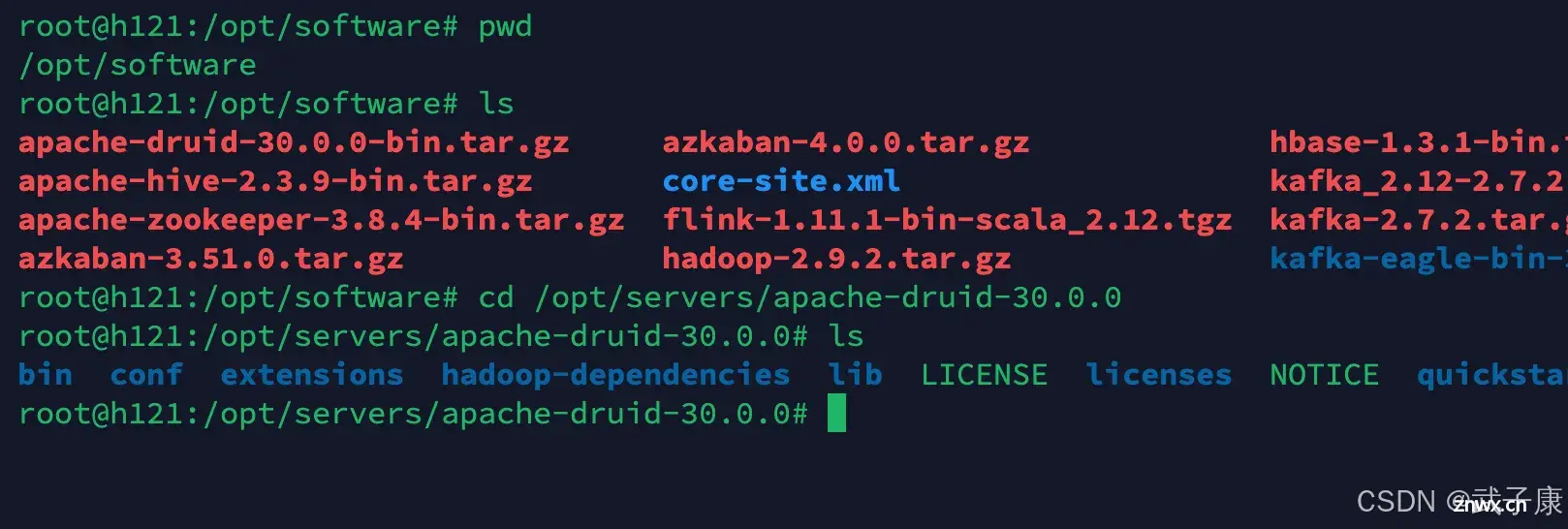
<code>mv apache-druid-30.0.0 /opt/servers/
cd /opt/servers/apache-druid-30.0.0
ls
执行结果如下图所示:
单机部署
配置文件
单服务器部署的配置文件如下:
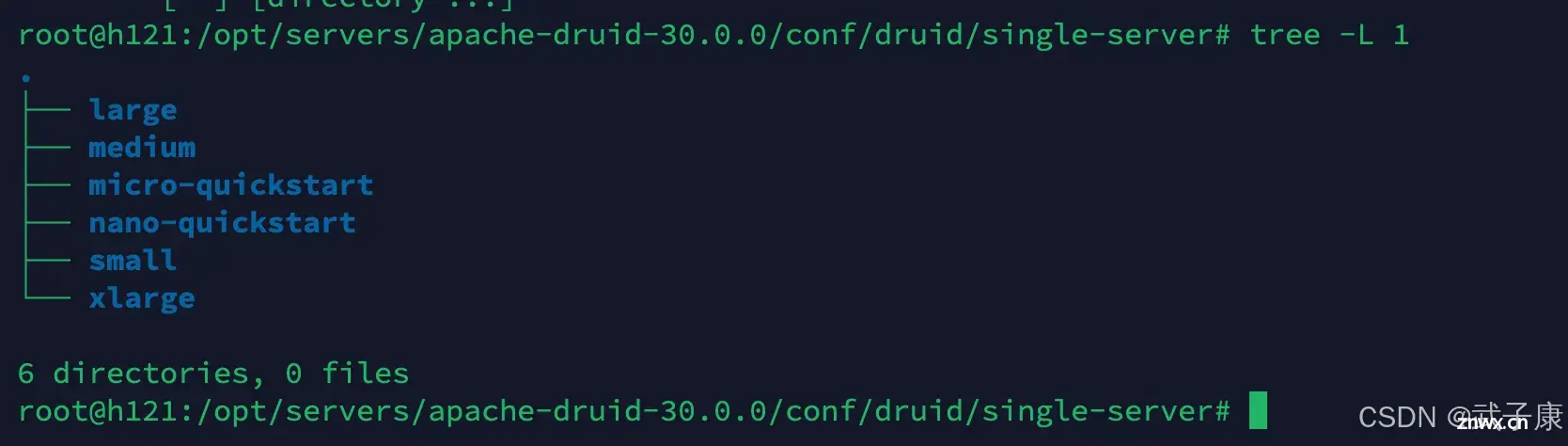
<code>conf/druid/single-server/
├── large
├── medium
├── micro-quickstart
├── nano-quickstart
├── small
└── xlarge
文件的路径如下图所示:

启动要求
单服务器的要求如下:
<code>Nano-Quickstart:1个CPU,4GB RAM
启动命令: bin/start-nano-quickstart
配置目录: conf/druid/single-server/nano-quickstart/*
微型快速入门:4个CPU,16GB RAM
启动命令: bin/start-micro-quickstart
配置目录: conf/druid/single-server/micro-quickstart/*
小型:8 CPU,64GB RAM(〜i3.2xlarge)
启动命令: bin/start-small
配置目录: conf/druid/single-server/small/*
中:16 CPU,128GB RAM(〜i3.4xlarge)
启动命令: bin/start-medium
配置目录: conf/druid/single-server/medium/*
大型:32 CPU,256GB RAM(〜i3.8xlarge)
启动命令: bin/start-large
配置目录: conf/druid/single-server/large/*
大型X:64 CPU,512GB RAM(〜i3.16xlarge)
启动命令: bin/start-xlarge
配置目录: conf/druid/single-server/xlarge/*
环境变量
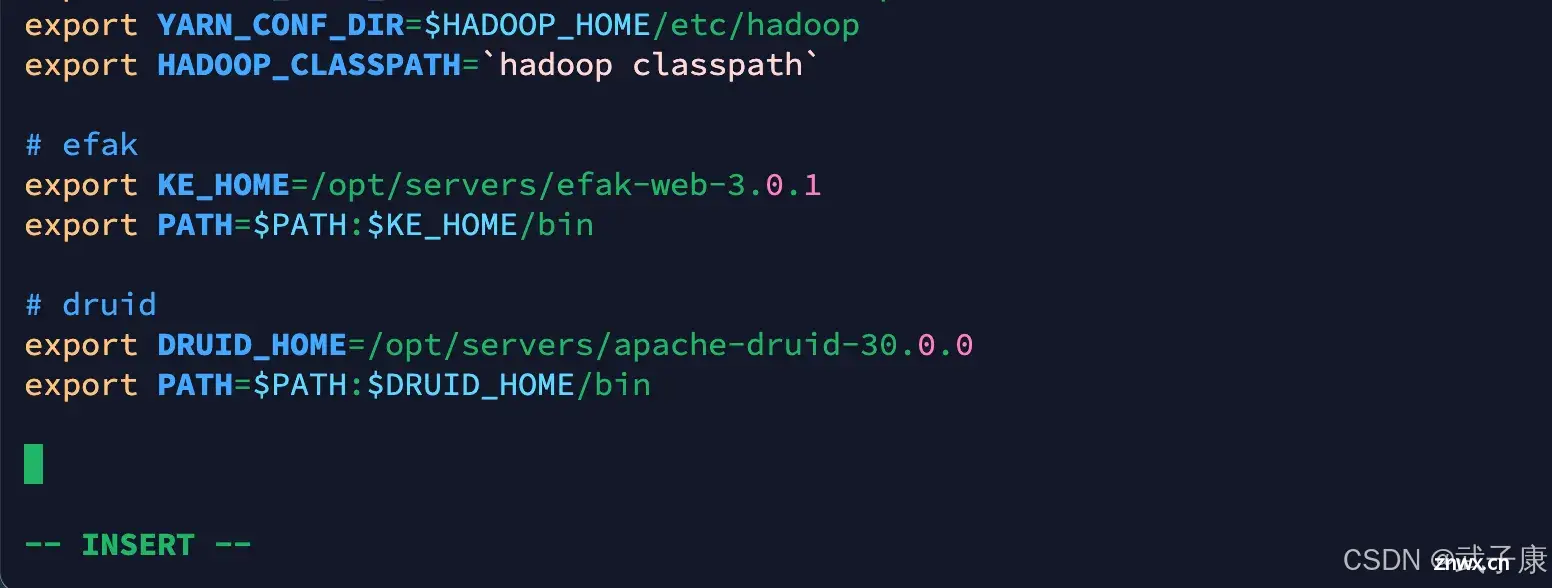
vim /etc/profile
写入如下的内容,记得刷新环境变量:
# druid
export DRUID_HOME=/opt/servers/apache-druid-30.0.0
export PATH=$PATH:$DRUID_HOME/bin
写入内容如下图所示:
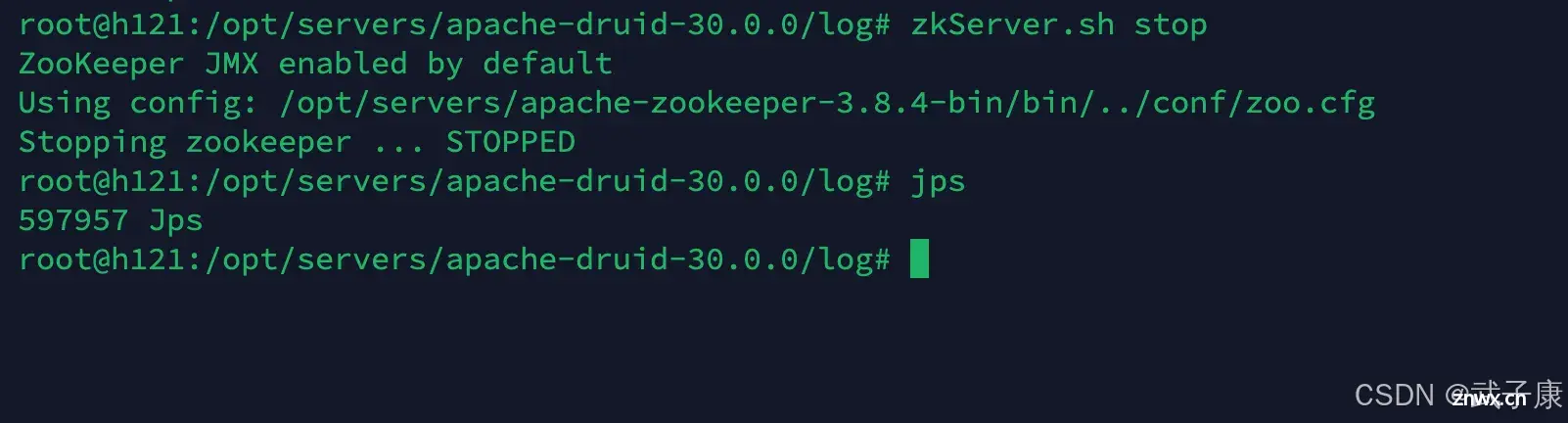
(这里注意,要关闭其他的服务,比如ZK什么的,不然会提示2181端口会占用)
<code>zkServer.sh stop
执行结果如下图所示:
接着进行启动,启动结果如下图所示:
查看页面
<code>http://h121.wzk.icu:8888/
页面结果显示如下图:

PS:官方建议大型系统采用集群模式部署,以此来实现容错和减少资源的争抢。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。