2024-07-25 08:05:04
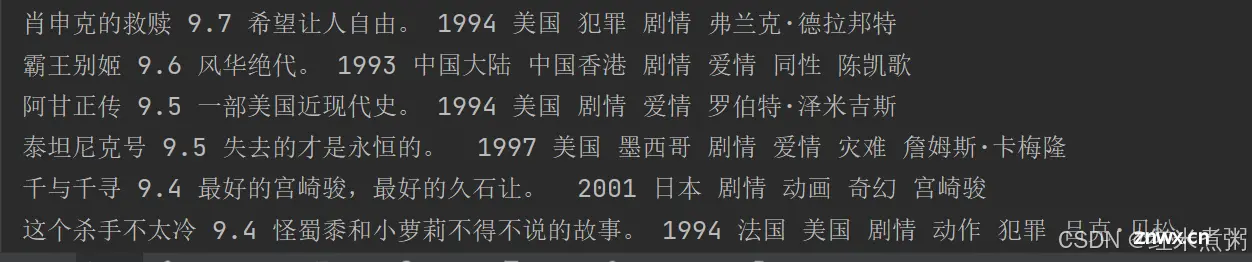
下面是一个简单的爬虫实例,使用Python的requests库来发送HTTP请求,并使用lxml库来解析HTML页面内容。这个爬虫的目标是抓取一个电影网站,并提取每部电影的主义部分。首先,确保你已经安装了requ...
浏览 60 次 标签: python—爬虫爬取电影页面实例
下面是一个简单的爬虫实例,使用Python的requests库来发送HTTP请求,并使用lxml库来解析HTML页面内容。这个爬虫的目标是抓取一个电影网站,并提取每部电影的主义部分。首先,确保你已经安装了requ...
浏览 60 次 标签: python—爬虫爬取电影页面实例