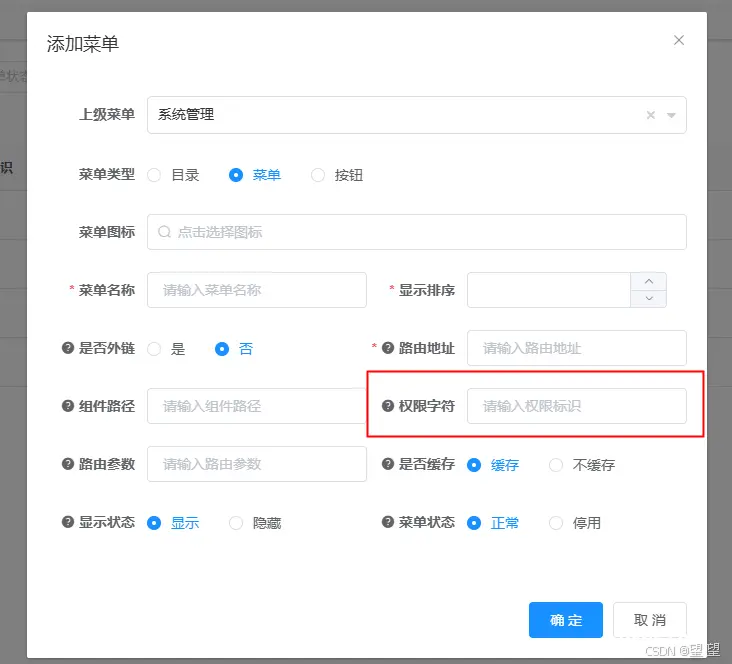
如此我们便可实现这些基本的接口级别的鉴权。整个实现下来,我们发现这必须要求整个系统在构建的伊始就必须要完善的配置结构,否则这个方案是很难流畅的使用的,所以我们在整个项目构建时就应该确定权限配置的基本结构。然后整个...
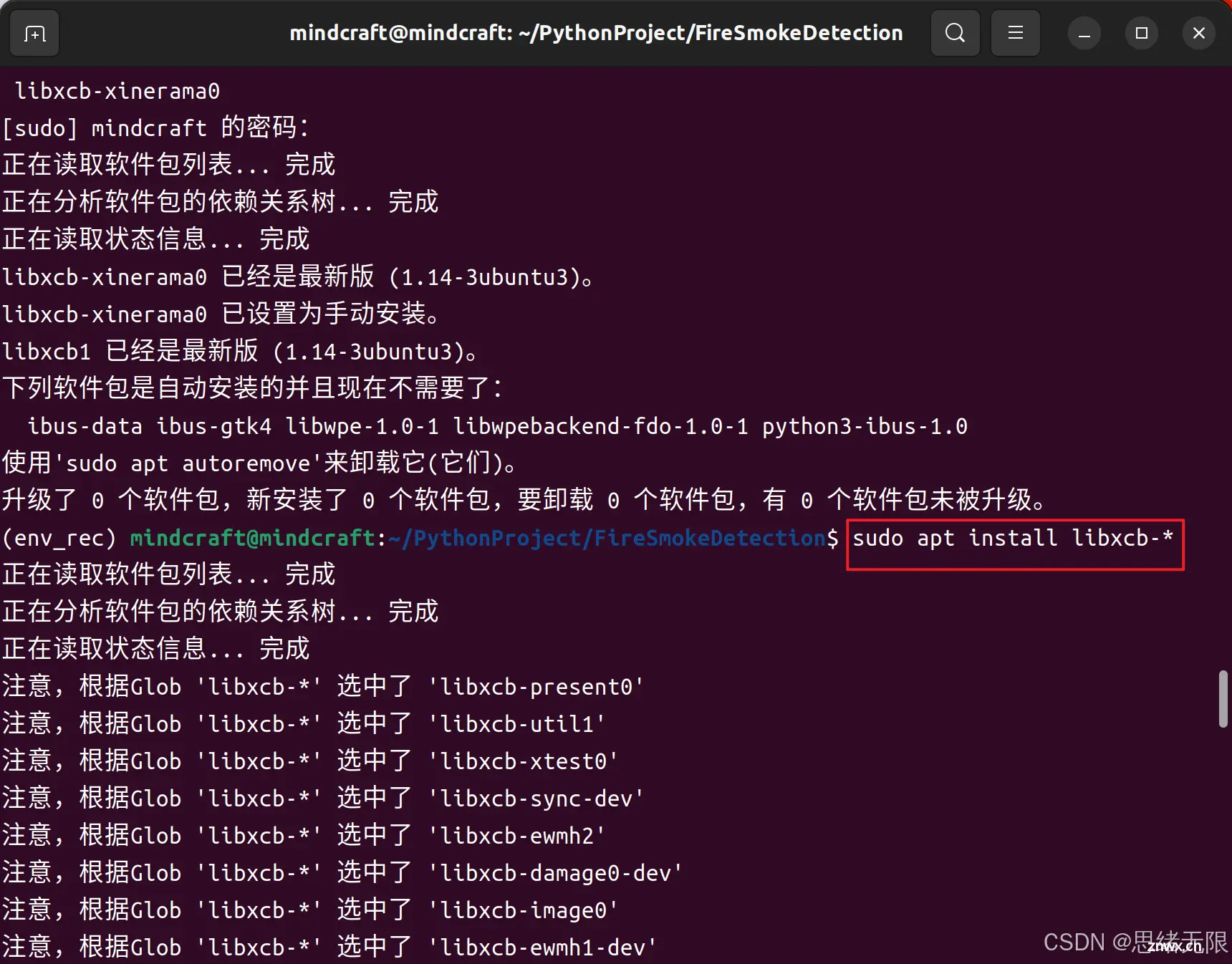
在Ubuntu22.04中安装OpenCV后,遇到“loadtheQtplatformplugin\"xcb\"insite-packages/cv2/qt/plugins\"eventhou...
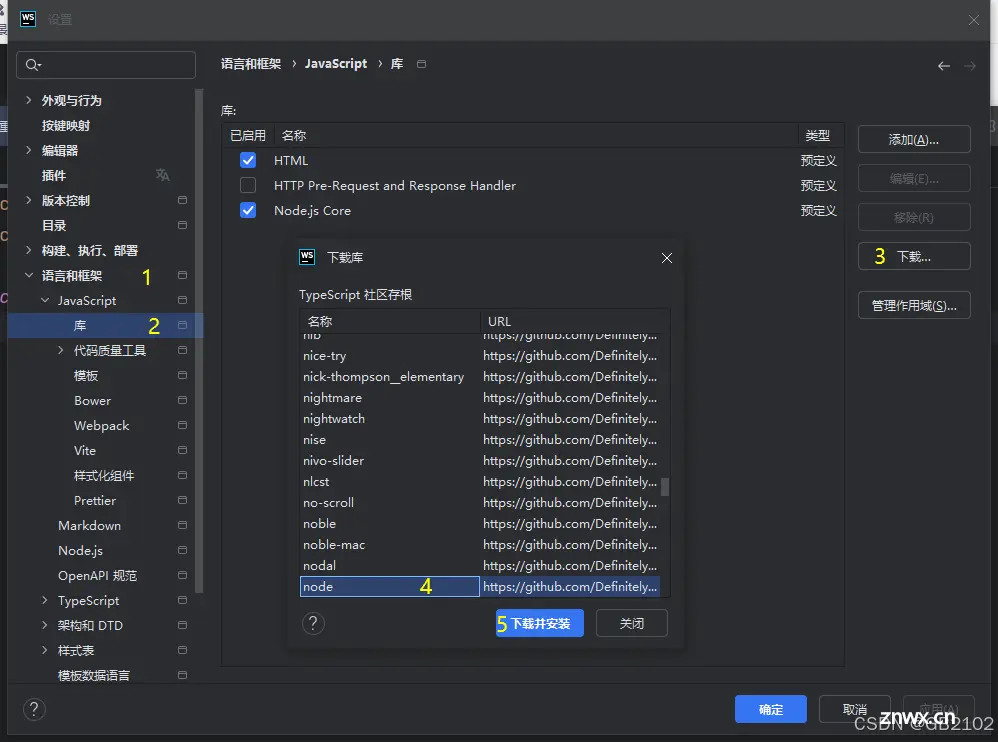
如何在webstorm配置nodejs的代码提示_webstorm设置node.js编码协助?...
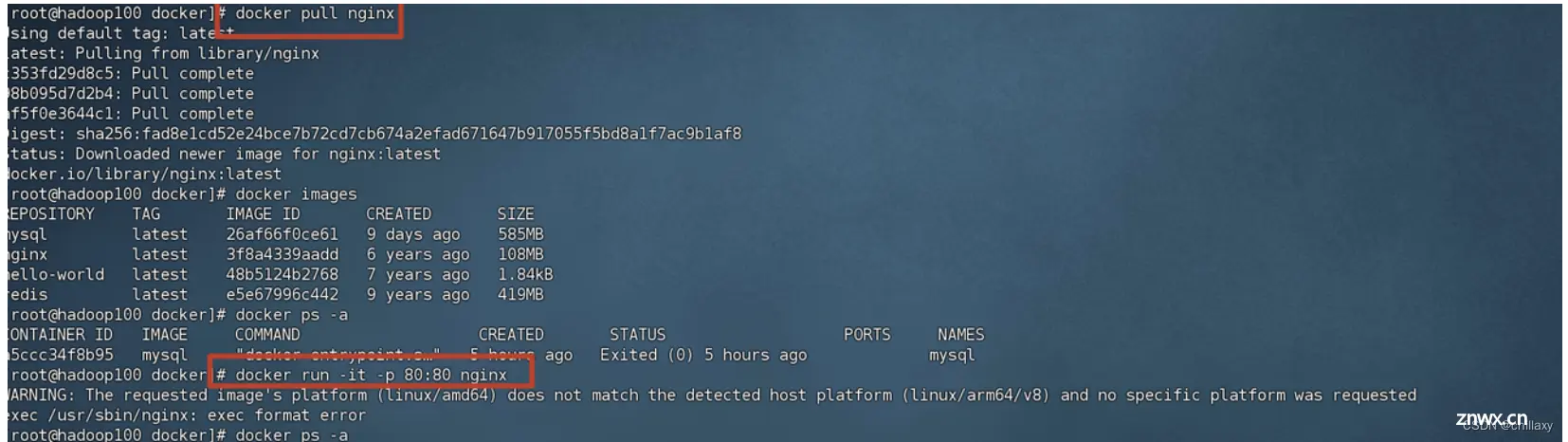
Therequestedimage\'splatform(linux/amd64)doesnotmatchthedetectedhostplatform(linux/arm64/v8)an...

Slurm支持定义和调度任意通用RESources的功能(GRES)。为特定GRES类型启用了其他内置功能,包括图形处理单元(GPU)、CUDA多进程服务(MPS)设备,并通过可扩展的插件机制进...
![[医疗 AI ] 3D TransUNet:通过 Vision Transformer 推进医学图像分割](/uploads/2024/09/17/1726549266226012434.webp)
医学图像分割在推进医疗保健系统的疾病诊断和治疗计划中起着至关重要的作用。U形架构,俗称U-Net,已被证明在各种医学图像分割任务中非常成功。然而,U-Net基于卷积的操作本身限制了其有效建模远程依赖关系的能力。...
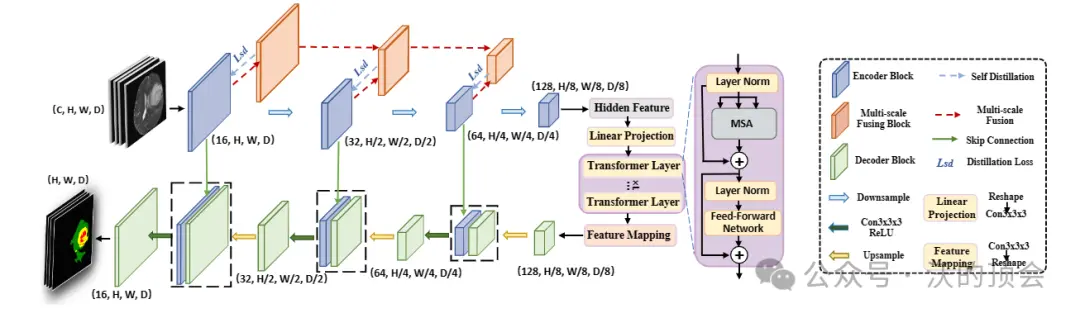
在此框架内,CrossTransformer模块采用可扩展采样来计算两种模态之间的结构关系,从而重塑一种模态的结构信息,以与SwinTransformer同一局部窗口内两种模态的相应结构保持一致。在编码器...
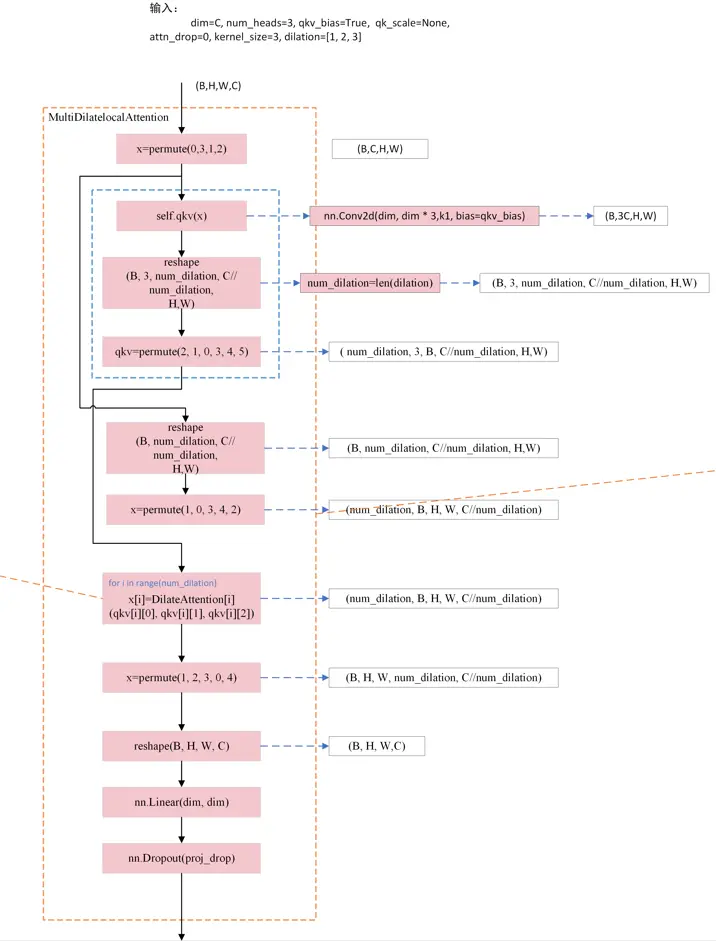
本文针对DilateFormer中的空洞自注意力机制原理和代码进行详细介绍,最后通过流程图梳理其实现原理。_multidilatelocalattention...
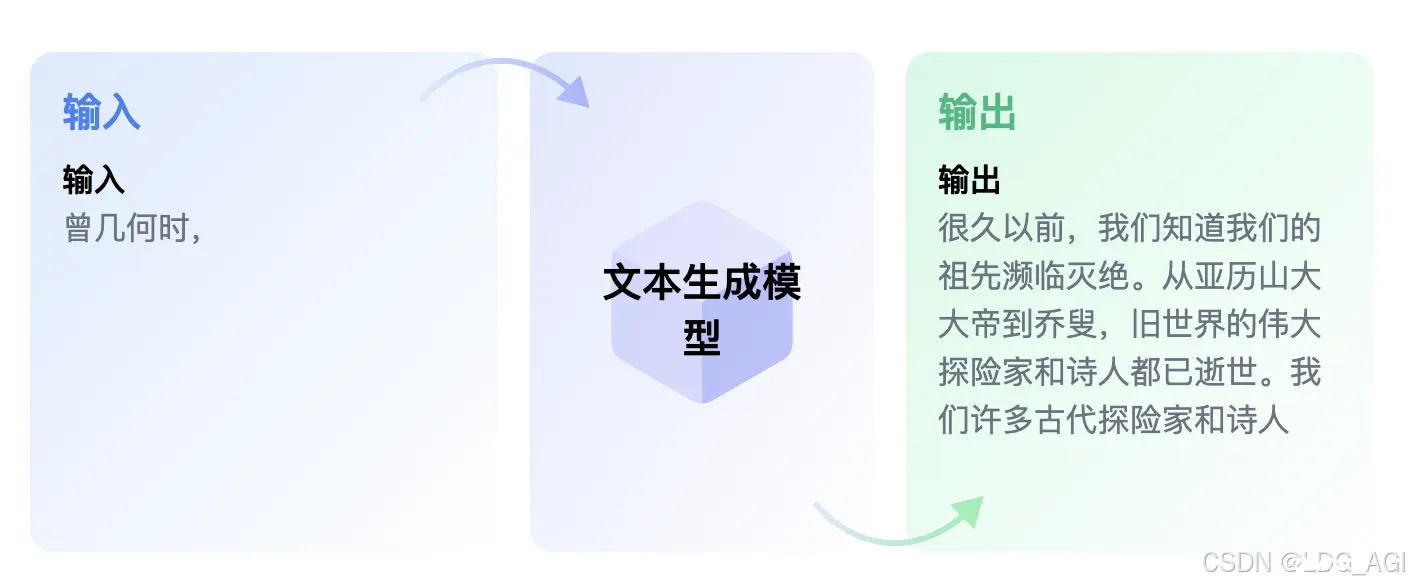
本文对transformers之pipeline的文本生成(text-generation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中...
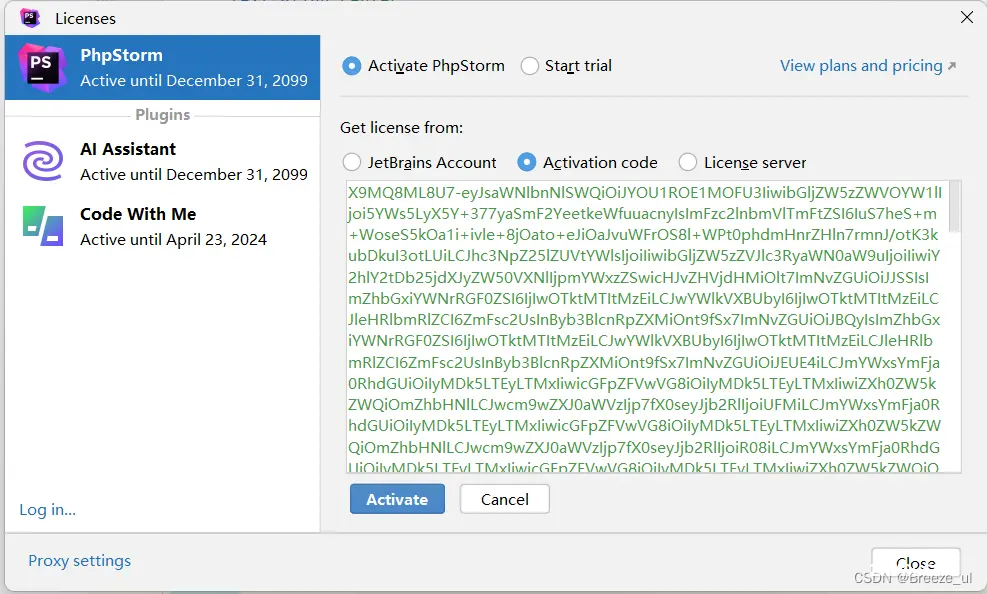
本文介绍了如何从官方下载最新版本的PHPStorm2023.3.6,提供激活码获取方法,并详细说明了如何完成安装过程以获得长期有效的许可证。...