DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition 中的空洞自注意力机制
Cpdr 2024-09-17 10:01:16 阅读 74
空洞自注意力机制
文章目录
摘要1. 模型解释1.1. 滑动窗口扩张注意力1.2. 多尺度扩张注意力
2. 代码3. 流程图3.1. MultiDilatelocalAttention3.2. DilateAttention3.3. MLP
摘要
本文针对DilateFormer中的空洞自注意力机制原理和代码进行详细介绍,最后通过流程图梳理其实现原理。
1. 模型解释
1.1. 滑动窗口扩张注意力
根据在普通视觉变换器(ViTs)中浅层全局注意力中观察到的局部性和稀疏性特性,我们提出了一种滑动窗口扩张注意力(SWDA) 操作,其中,keys和values被以query patch为中心的滑动窗口稀疏地选择。然后对这些代表性patches进行自注意力。我们的 SWDA 正式描述如下:
X
=
S
W
D
A
(
Q
,
K
,
V
,
r
)
(
1
)
\begin{aligned} &&&&&&&&&&&&& X = SWDA(Q,K,V,r) &&&&&&&&&&&&&&&& (1) \end{aligned}
X=SWDA(Q,K,V,r)(1)
其中,
Q
,
K
,
V
Q,K,V
Q,K,V分别代表query、key和value矩阵,三个矩阵的每一行表示一个query/key/value特征向量。对于原始特征图上
(
i
,
j
)
(i,j)
(i,j)位置的query,SWDA以尺寸为
w
×
w
w×w
w×w大小的滑动窗口,稀疏地选择key和value去指导自注意力。
而且,我们定义一个扩张率
r
ϵ
N
+
r \epsilon N^+
rϵN+去控制稀疏程度。特别地,对于位置
(
i
,
j
)
(i,j)
(i,j),SWDA计算的输出
X
X
X中的相应分量
x
i
j
x_{ij}
xij定义如下:
x
i
j
=
A
t
t
e
n
t
i
o
n
(
q
i
j
,
K
r
,
V
r
)
,
(
2
)
=
S
o
f
t
m
a
x
(
q
i
j
K
r
T
d
k
)
V
r
,
1
≤
i
≤
W
,
1
≤
i
≤
H
\begin{aligned} &&&&&&&&&&&& x_{ij} &= Attention(q_{ij},K_r,V_r), &&&&&&&&&&&&&&&& (2)\\ &&&&&&&&&&&&&=Softmax(\frac{q_{ij}K^T_r}{\sqrt{d_k}})V_r,& 1≤i≤W, 1≤i≤H \\ \end{aligned}
xij=Attention(qij,Kr,Vr),=Softmax(dk
qijKrT)Vr,1≤i≤W,1≤i≤H(2)
其中,
H
H
H 和
W
W
W 是特征图的高和宽。
K
r
K_r
Kr和
V
r
V_r
Vr表示从特征图
K
K
K 和
V
V
V 中选择的keys和values。
给定位于
(
i
,
j
)
(i,j)
(i,j)的query,位于坐标
(
i
′
,
j
′
)
(i', j')
(i′,j′) 下keys和values将被选择去指导自注意力(self-attetion):
{
(
i
′
,
j
′
)
∣
i
′
=
i
+
p
×
r
,
j
′
=
j
+
q
×
r
}
,
−
w
2
≤
p
,
q
≤
w
2
.
(
3
)
\begin{aligned} &&&&&&&&&&&&& \{(i',j')|i'=i+p×r, j'=j+q×r \}, \frac{-w}{2}≤p, q≤\frac{w}{2}. &&&&&&&&&&&&&&&& (3) \end{aligned}
{(i′,j′)∣i′=i+p×r,j′=j+q×r},2−w≤p,q≤2w.(3)
我们的 SWDA 以滑动窗口的方式对所有query patches进行自注意力操作。对于特征图边缘的query,我们简单地使用卷积运算中常用的 补零策略 来保持特征图的大小。通过稀疏地选择以queries为中心的keys和values,所提出的 SWDA 明确满足局部性和稀疏性属性,并且可以有效地对远程依赖关系进行建模
1.2. 多尺度扩张注意力
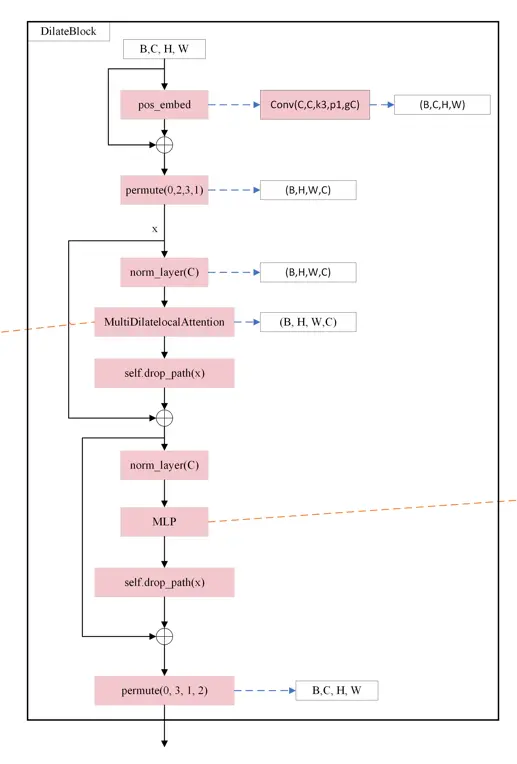
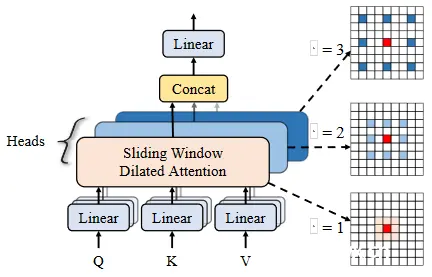
图4. 多尺度空洞注意力。
首先,特征图的通道被划分不同的heads。然后,自注意力操作是在红色查询块周围的窗口中的彩色块之间执行的,在不同的头中使用不同的膨胀率。此外,不同heads中的特征被连接在一起,然后输入到线性层中。默认情况下,我们使用 3 × 3 的内核大小,膨胀率 r = 1、2 和 3,不同头中参与感受野的大小为 3 × 3、5 × 5 和 7 × 7。
为了利用块级自注意力机制在不同尺度上的稀疏性,我们进一步提出了多尺度扩张注意力(MSDA) 块来提取多尺度语义信息。如图4所示,给定特征图
X
X
X,我们通过 线性投影(linear projection) 获得相应的query、kay和value。之后,我们将特征图的通道划分到
n
n
n 个不同的
h
e
a
d
s
heads
heads,并在不同的
h
e
a
d
s
heads
heads中以不同的膨胀率(dilation rates)执行多尺度SWDA。具体来说,我们的MSDA计算如下:
h
i
=
S
W
D
A
(
Q
i
,
K
i
,
V
i
,
r
i
)
,
1
≤
i
≤
n
,
(
4
)
X
=
L
i
n
e
a
r
(
C
o
n
c
a
t
[
h
1
,
.
.
.
,
h
n
]
)
,
(
5
)
\begin{aligned} &&&&&&&&&&&&& h_i=SWDA(Q_i,K_i,V_i,r_i), &1≤i≤n, &&&&&&&&&&&&&&&& (4)\\ &\\ &&&&&&&&&&&&& X=Linear(Concat[h_1,...,h_n]), &&&&&&&&&&&&&&&&& (5) \end{aligned}
hi=SWDA(Qi,Ki,Vi,ri),X=Linear(Concat[h1,...,hn]),1≤i≤n,(4)(5)
其中,
r
i
r_i
ri是第
i
i
i 个
h
e
a
d
head
head的扩张率,
Q
i
,
K
i
Q_i,K_i
Qi,Ki 和
V
i
V_i
Vi 代表馈入第
i
i
i 个
h
e
a
d
head
head的特征图切片。输出
{
h
i
}
i
=
1
n
\{h_i\}_{i=1}^n
{ hi}i=1n被concat到一起,然后送到线性层进行特征聚合。
通过为不同的
h
e
a
d
s
heads
heads 设置不同的扩张率,我们的 MSDA 有效地聚合了参与感受野内不同尺度的语义信息,并有效地减少了自注意力机制的冗余,而无需复杂的操作和额外的计算成本。
2. 代码
<code>import torch
import torch.nn as nn
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
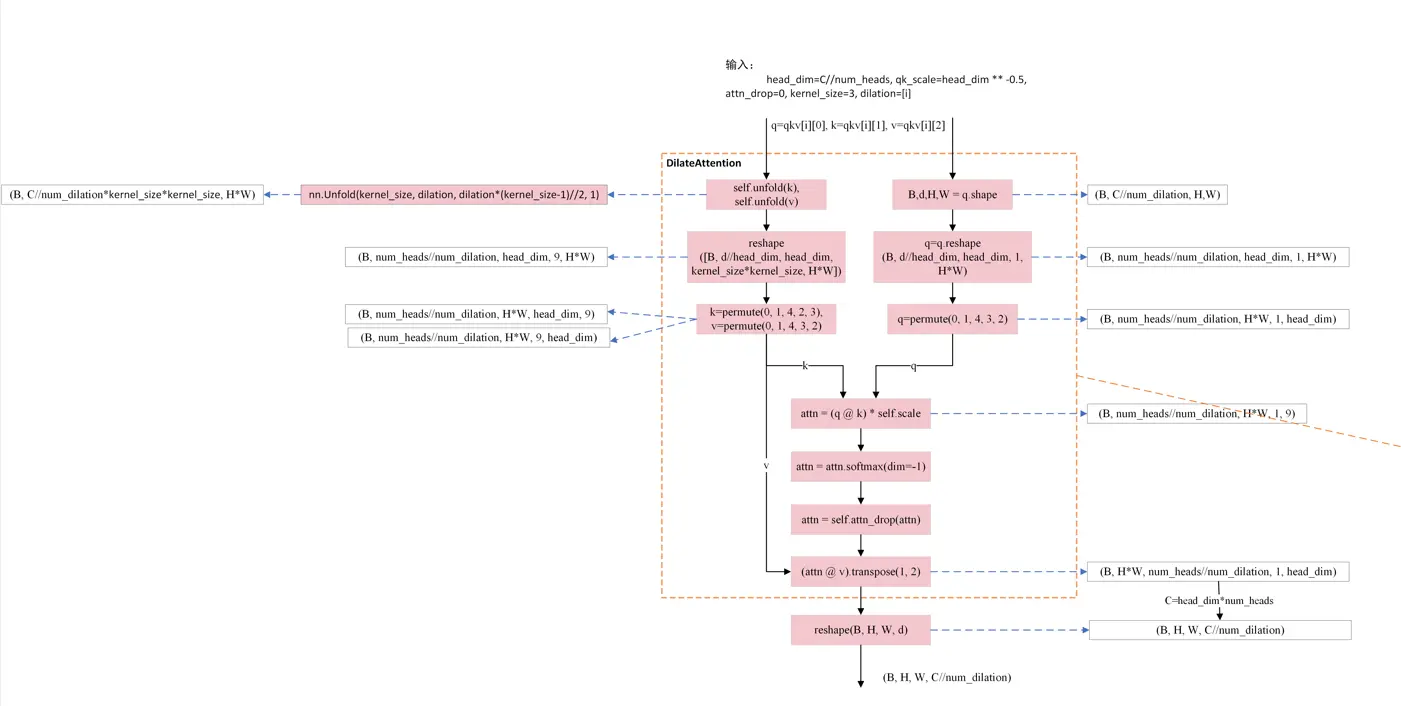
class DilateAttention(nn.Module):
"Implementation of Dilate-attention"
def __init__(self, head_dim, qk_scale=None, attn_drop=0, kernel_size=3, dilation=1):
super().__init__()
self.head_dim = head_dim
self.scale = qk_scale or head_dim ** -0.5
self.kernel_size=kernel_size
self.unfold = nn.Unfold(kernel_size, dilation, dilation*(kernel_size-1)//2, 1)
self.attn_drop = nn.Dropout(attn_drop)
def forward(self,q,k,v):
#B, C//3, H, W
q, k, v = q.detach(), k.detach(), v.detach() # todo:!!!
B,d,H,W = q.shape
q = q.reshape([B, d//self.head_dim, self.head_dim, 1 ,H*W]).permute(0, 1, 4, 3, 2) # B,h,N,1,d
k = self.unfold(k).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 2, 3) #B,h,N,d,k*k
attn = (q @ k) * self.scale # B,h,N,1,k*k
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
v = self.unfold(v).reshape([B, d//self.head_dim, self.head_dim, self.kernel_size*self.kernel_size, H*W]).permute(0, 1, 4, 3, 2) # B,h,N,k*k,d
x = (attn @ v).transpose(1, 2).reshape(B, H, W, d)
return x
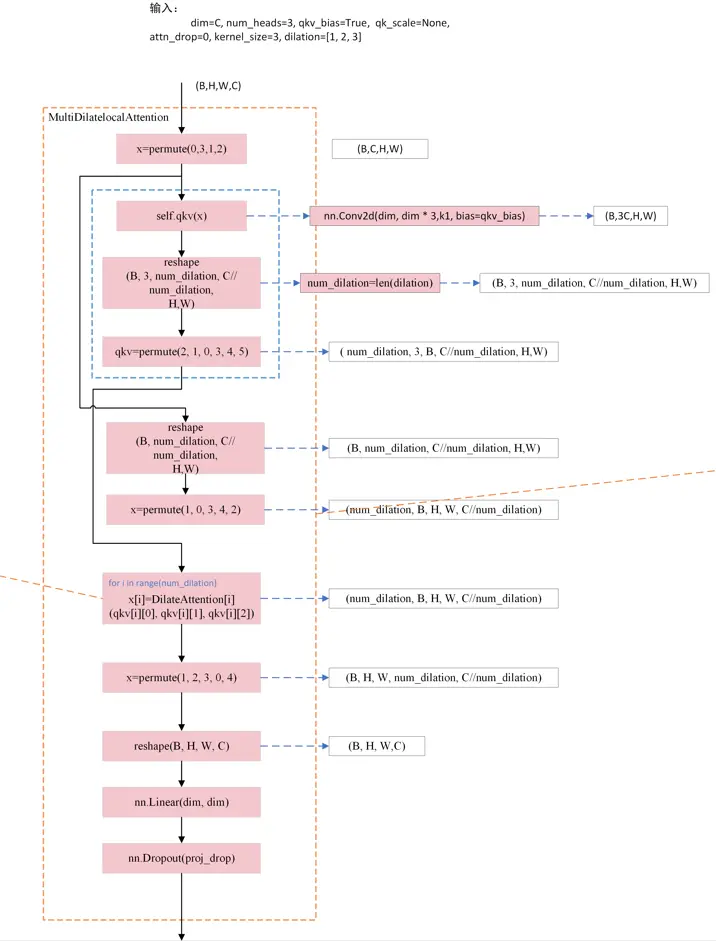
class MultiDilatelocalAttention(nn.Module):
"Implementation of Dilate-attention"
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None,
attn_drop=0.,proj_drop=0., kernel_size=3, dilation=[1, 2, 3]):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.dilation = dilation
self.kernel_size = kernel_size
self.scale = qk_scale or head_dim ** -0.5
self.num_dilation = len(dilation)
assert num_heads % self.num_dilation == 0, f"num_heads{ num_heads} must be the times of num_dilation{ self.num_dilation}!!"
self.qkv = nn.Conv2d(dim, dim * 3, 1, bias=qkv_bias)
self.dilate_attention = nn.ModuleList(
[DilateAttention(head_dim, qk_scale, attn_drop, kernel_size, dilation[i])
for i in range(self.num_dilation)])
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
x = x.permute(0, 3, 1, 2)# B, C, H, W
qkv = self.qkv(x).reshape(B, 3, self.num_dilation, C//self.num_dilation, H, W).permute(2, 1, 0, 3, 4, 5)
#num_dilation,3,B,C//num_dilation,H,W
x = x.reshape(B, self.num_dilation, C//self.num_dilation, H, W).permute(1, 0, 3, 4, 2 )
# num_dilation, B, H, W, C//num_dilation
for i in range(self.num_dilation):
x[i] = self.dilate_attention[i](qkv[i][0], qkv[i][1], qkv[i][2])# B, H, W,C//num_dilation
x = x.permute(1, 2, 3, 0, 4).reshape(B, H, W, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class DilateBlock(nn.Module):
"Implementation of Dilate-attention block"
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0., attn_drop=0.,
drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, kernel_size=3, dilation=[1, 2, 3],
cpe_per_block=False):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
self.kernel_size = kernel_size
self.dilation = dilation
self.cpe_per_block = cpe_per_block
if self.cpe_per_block:
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.attn = MultiDilatelocalAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, kernel_size=kernel_size, dilation=dilation)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
def forward(self, x):
if self.cpe_per_block:
x = x + self.pos_embed(x)
x = x.permute(0, 2, 3, 1)
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.permute(0, 3, 1, 2)
#B, C, H, W
return x
if __name__ == "__main__":
x = torch.rand([2,72,56,56])
B, C, H, W = x.shape
dim = C
num_heads = 3
head_dim = dim // num_heads
#######################
drop_path=0.1
depths = [2, 2, 6, 2]
num_layers = len(depths)
dpr = [x.item() for x in torch.linspace(0, drop_path, sum(depths))]
for i_layer in range(num_layers):
drop_paths = dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])]
#######################
m = DilateBlock(dim=C,
num_heads=num_heads,
kernel_size=3,
dilation=[1,2,3],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=head_dim ** -0.5,
drop=0.,
attn_drop=0.,
drop_path=drop_paths[1] if isinstance(drop_paths, list) else drop_paths,
norm_layer=nn.LayerNorm, act_layer=nn.GELU, cpe_per_block=True)
y = m(x)
print(y.shape)
3. 流程图

3.1. MultiDilatelocalAttention
3.2. DilateAttention
3.3. MLP
完整流程图如下:
上一篇: AI智能行为分析预警系统技术方案
下一篇: 1.Windows11下安装WSL2子系统、Nvidia驱动、CUDA Toolkit(2024-07)
本文标签
DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition 中的空洞自注意力机制
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。