
本文介绍了如何通过手工方式使用Transformer库训练情感分类模型,包括数据预处理、模型构建、训练与验证等步骤,为后续引入高级组件做铺垫。...
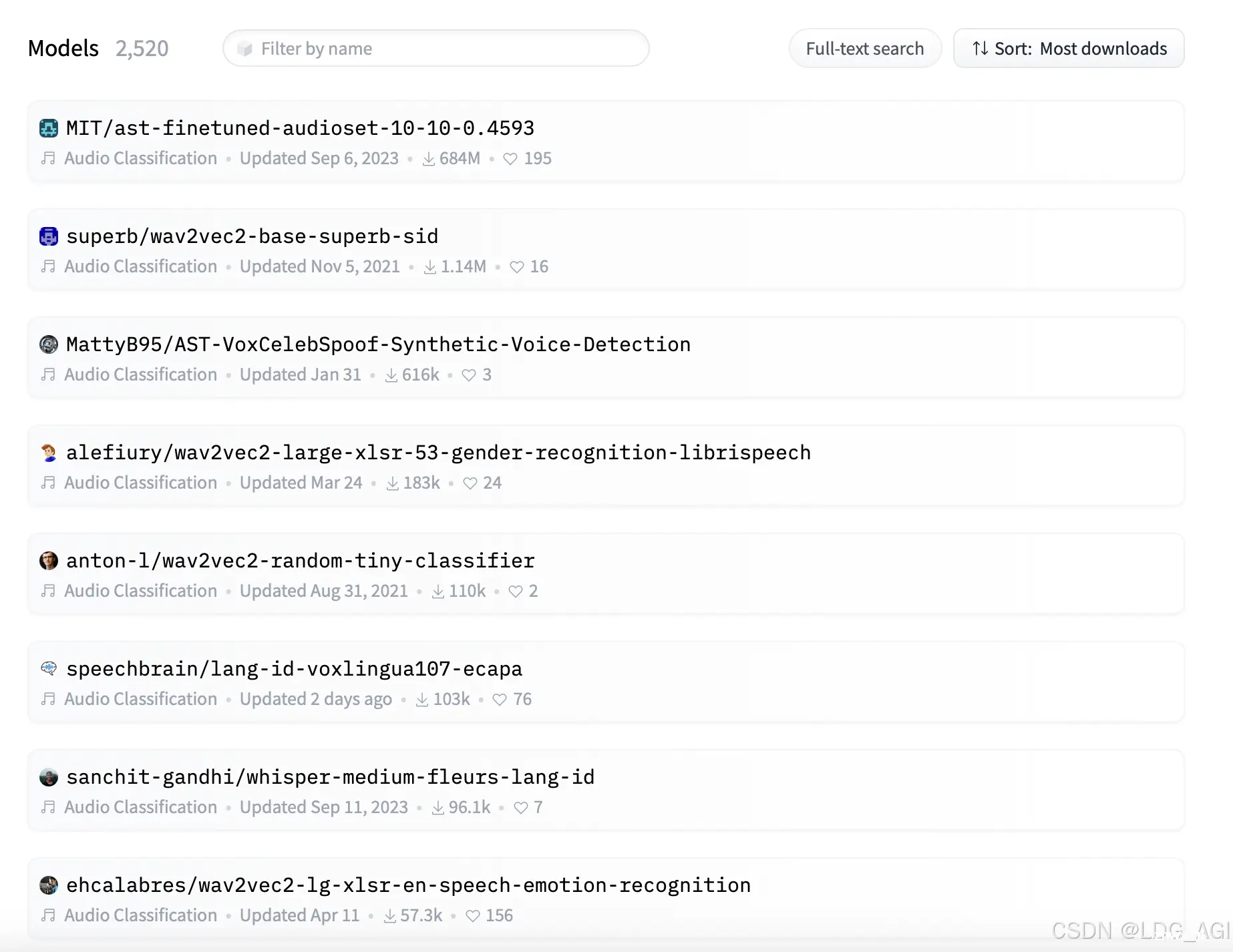
本文对transformers之pipeline的音频分类(audio-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipel...

整理|王启隆出品|AI科技大本营(ID:rgznai100)原文|https://www.youtube.com/watch?v=ZFmapxYBafY写出Transformer论文的那八个人,如今...

已解决javax.xml.transform.TransformerFactoryConfigurationError异常的正确解决方法,亲测有效!!!_javax.xml.transformer...
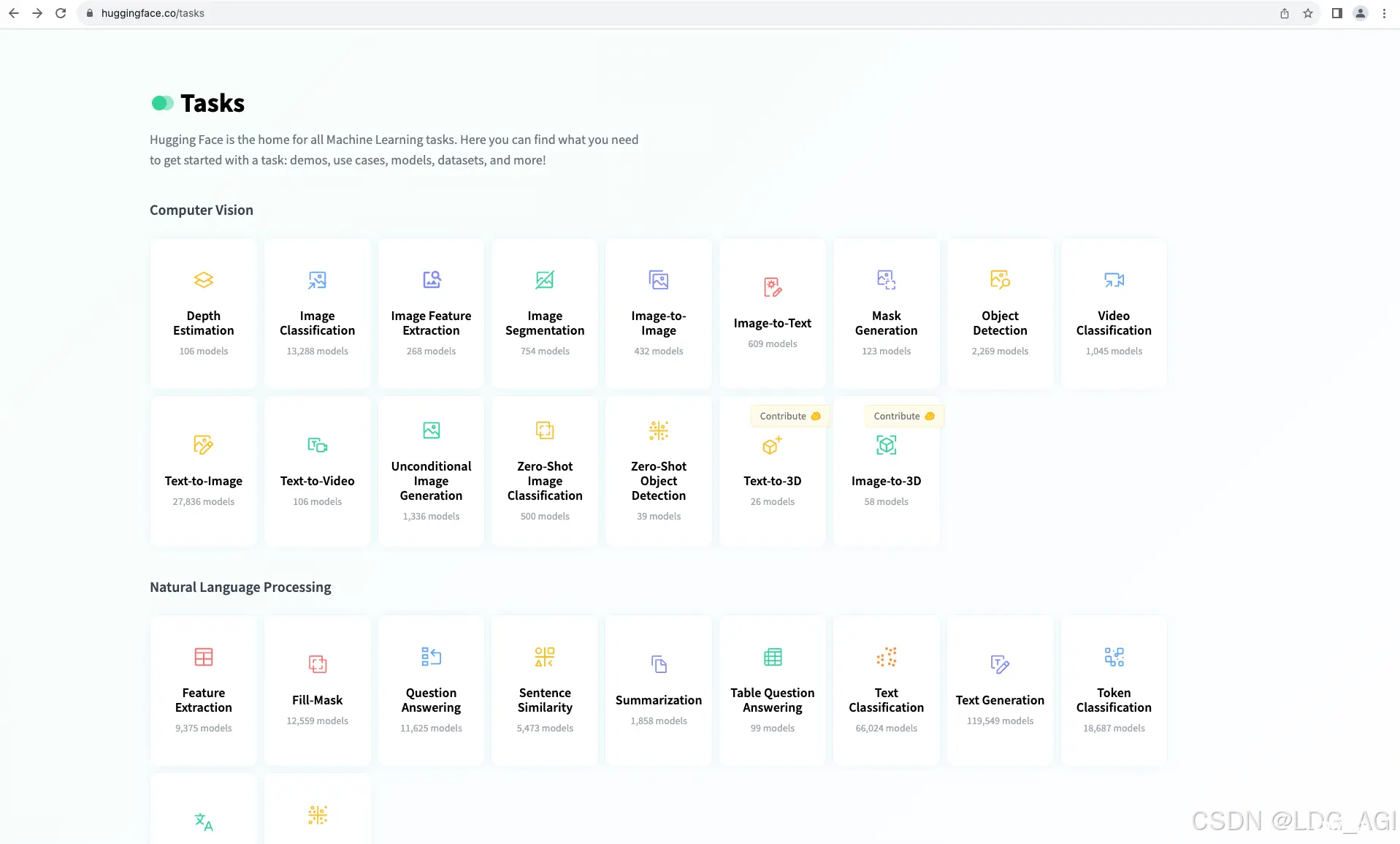
本文为transformers之pipeline专栏的第0篇,后面会以每个task为一篇,共计讲述28+个tasks的用法,通过28个tasks的pipeline使用学习,可以掌握语音、计算机视觉、自然语言处理...
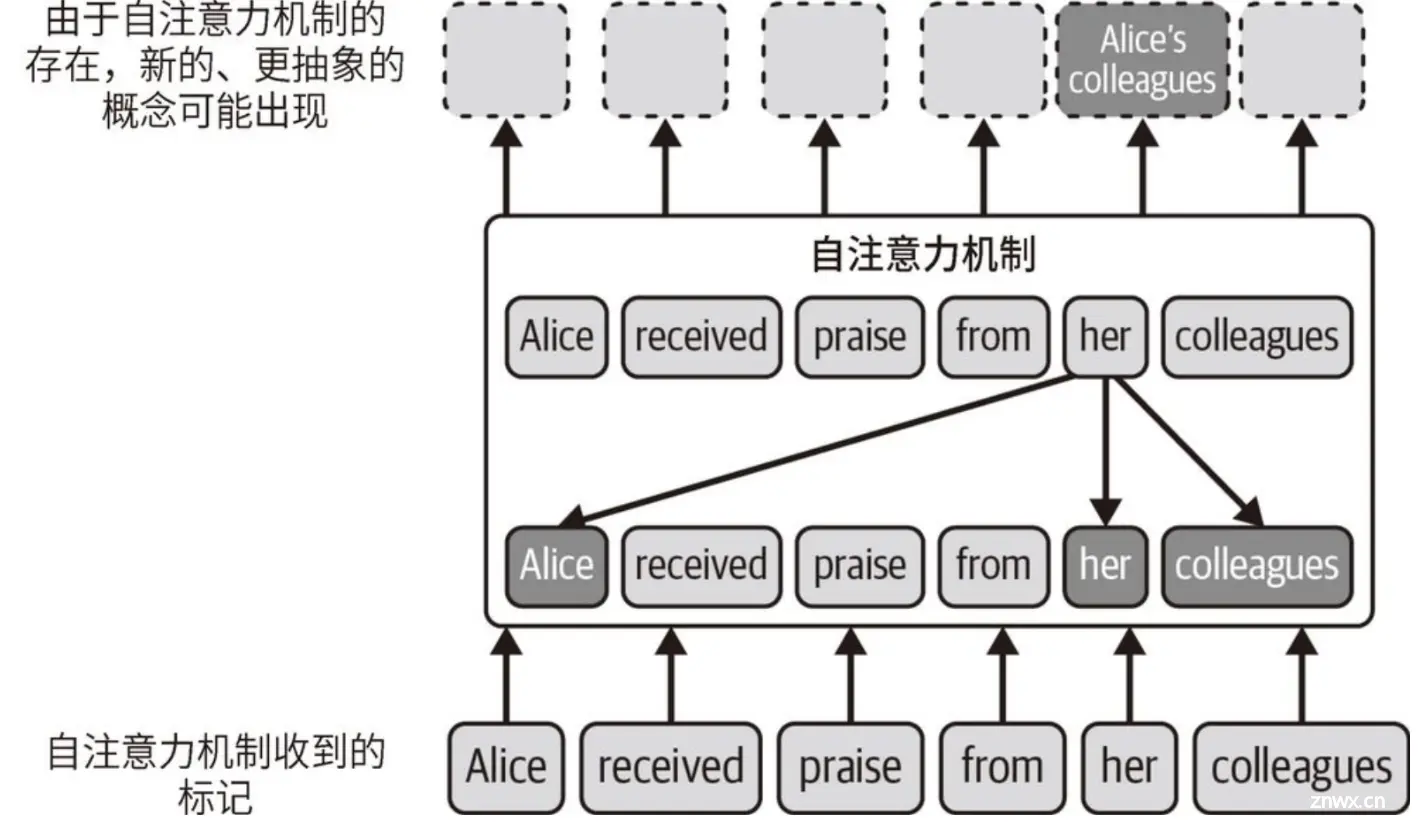
【大模型应用极简开发入门(1)】LLM概述:LLM在AI中所处位置、NLP技术的演变、Transformer与GPT、以及GPT模型文本生成逻辑_根据给定的输入文本(称为提示词)生成连贯且相关的输出文本...

首先是代码,然后是理论。建议读者先看代码,后学理论~我出于需要还是喜欢学习?如果我要解决某件问题,我会广泛获取所需的信息、研究、理解它,然后采取行动。例如,我的目标是复现最新的模型(如盘古模型),这涉及到从头开始编写...

在自然语言处理(NLP)的世界里,文本数据的处理和理解是至关重要的一环。为了使得计算机能够理解和处理人类的自然语言,我们需要将原始的、对人类可读的文本转化为机器可以理解的格式。这就是Tokenizer,或者我们...
BERT是一种基于Transformer的预训练语言模型,它的最大创新之处在于引入了双向Transformer编码器,这使得模型可以同时考虑输入序列的前后上下文信息。GPT也是一种基于Transformer的预训练语...

RWKV在多语言处理、小说写作、长期记忆保持等方面表现出色,可以主要应用于自然语言处理任务,例如文本分类、命名实体识别、情感分析等。...