
函数来获取所有工作表的名称,然后循环读取每个工作表。包可以写入Excel文件。读取Excel文件中的特定工作表,可以使用。对Excel文件中的特定列感兴趣,可以使用。对Excel文件中的特定行感兴趣,可以使用。在E...
本文还有配套的精品资源,点击获取简介:本项目通过Zigbee无线通信技术采集四种传感器的数据,并利用ESP8266作为网关进行Wi-Fi传输,将数据发送至基于Flask框架的Web服务器。服务器后端采用uws...
Flask+Pyecharts+大数据集群:数据可视化大屏的实现一、相关技术介绍及相关模块安装1.相关技术介绍(1)Flask(2)Pyecharts(3)大数据集群(4)Pycharm编程工具2.相关模块安装...

增量构建的Cube需要指定分割时间列,例如:将日期分区字段添加到维度列中:DataModel:NewJoinCondition,需要配置好几个:配置成如下的结果:维度配置如下图所示:填写名字等跳过,维度需要...
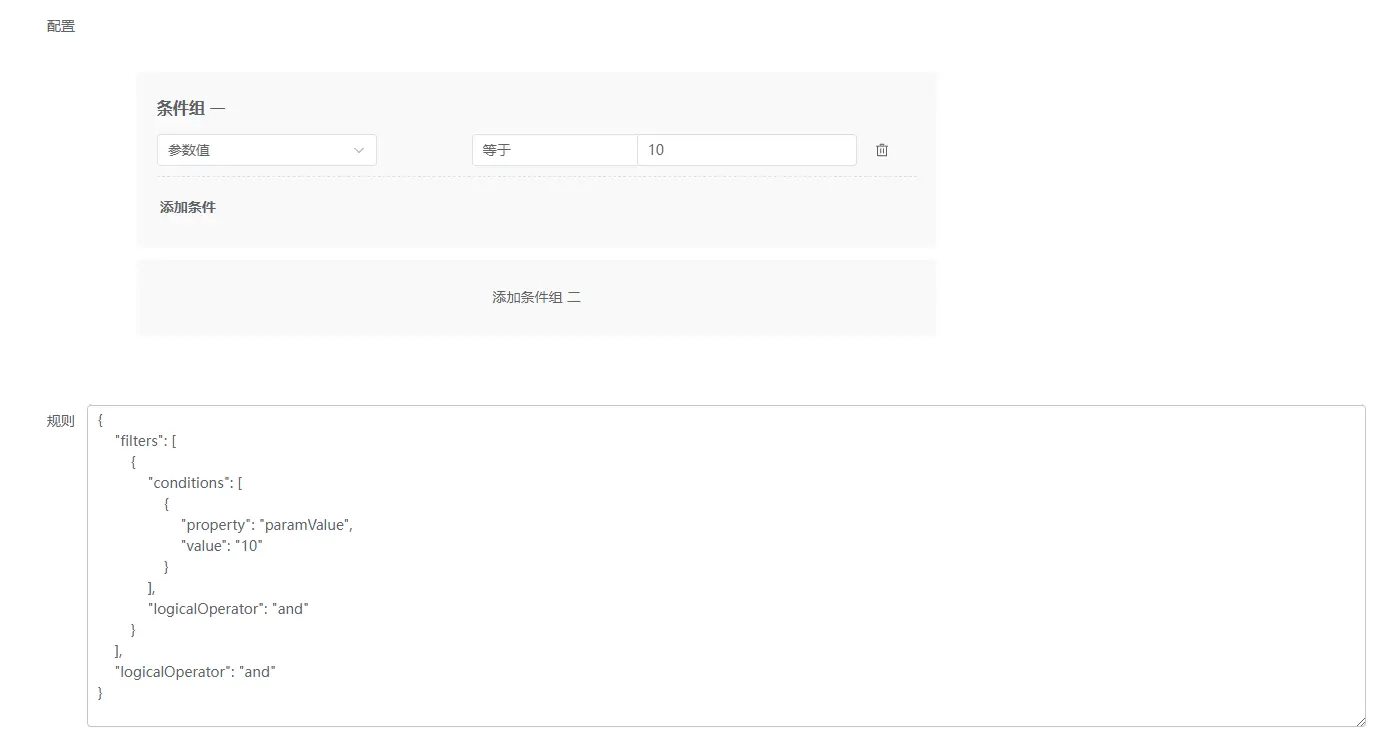
至此,已完成了数据权限的整体框架开发,但也只是框架,各环节还有大量的工作需要完善,主要包括以下几点:1.配置规则时需要增加用户、部门、角色等维度2.将数据筛选器生成的各种场景下的复杂规则转换为SQL片段3...
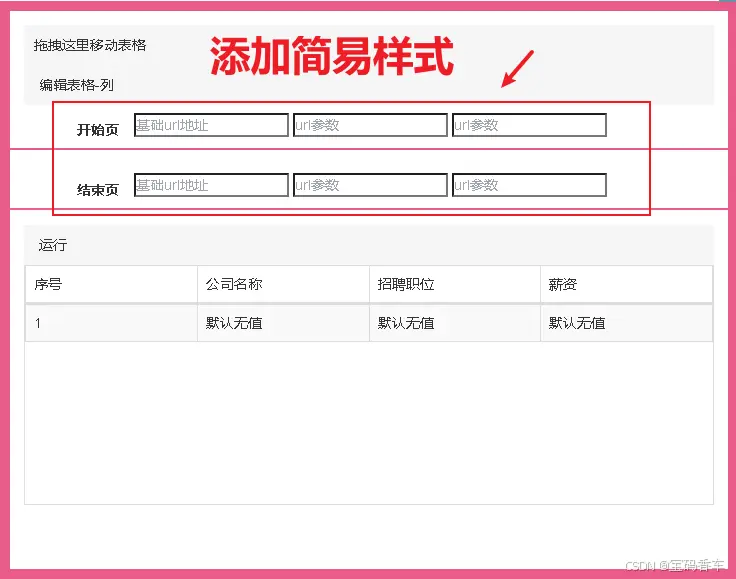
附具体完整代码,深入理解,彻底掌握!_油猴脚本...
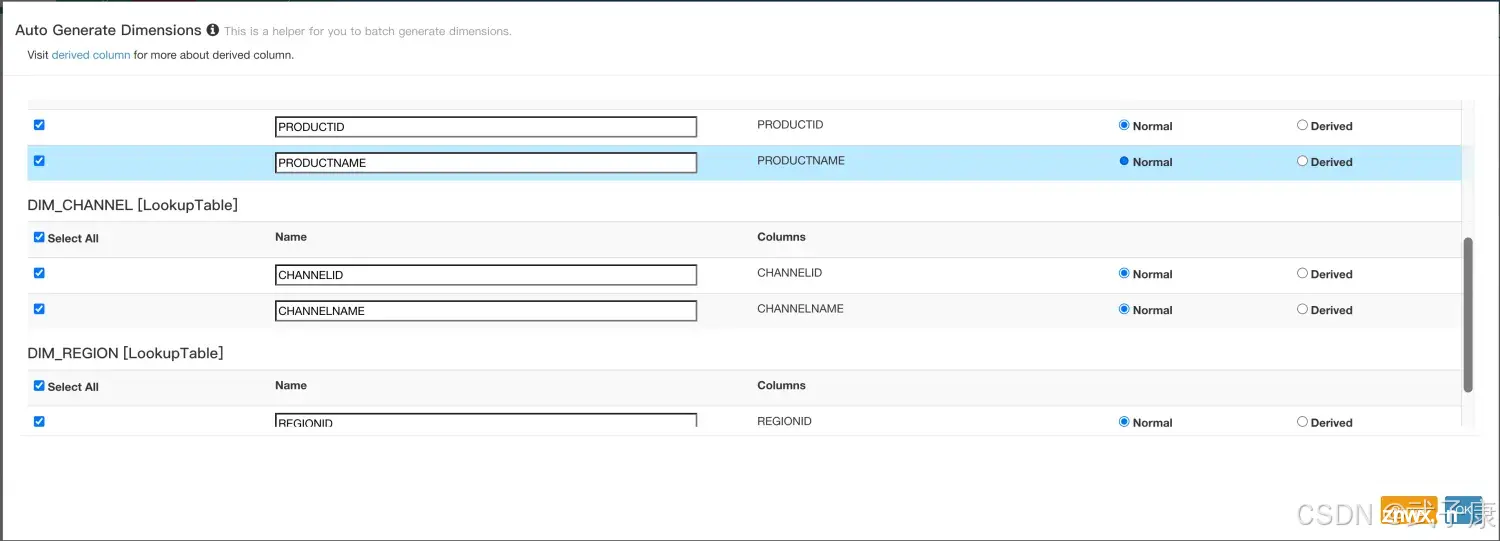
省略Model等操作。构建前面Cube4类似的Cube7,仅在维度定义有区别。(我这里是CloneCube4,然后修改的)wzk_test_kylin_cube_7的字段中,都是Normal:在单个聚合组中,可...

自定义数据集实现一个从Spark到PyTorch流数据的自定义数据集。features=torch.tensor([row[col]forcolinself.feature_cols],dt...

-预期市盈率:109倍;)-预期市盈率:100倍;)-预期市盈率:19倍;)-预期市盈率:99倍;)-预期市盈率:30倍;)-预期市盈率:37倍;)-预期市盈率:41倍;)...
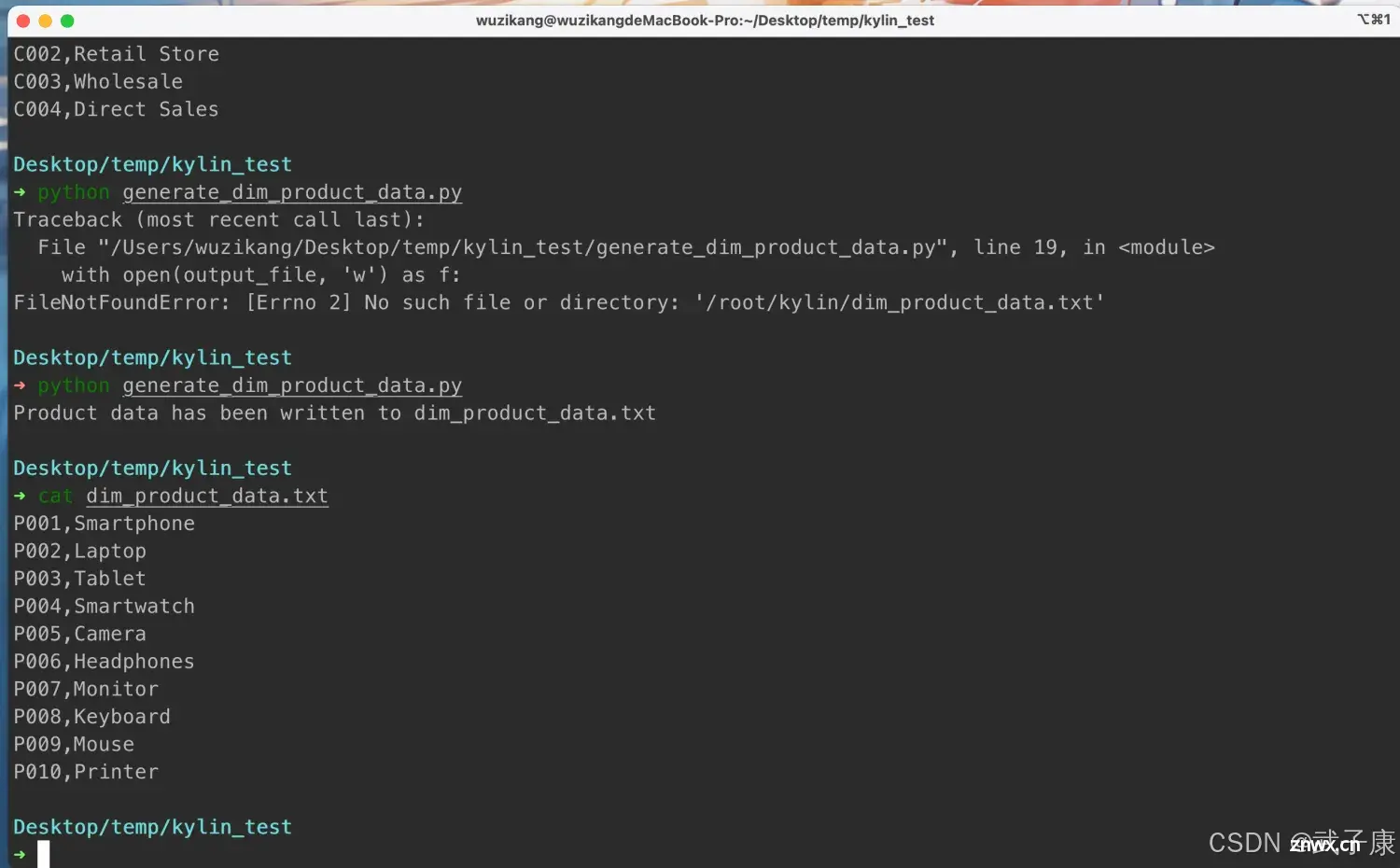
ApacheKylin是一个开源的分布式分析引擎,专注于提供大数据的实时OLAP(在线分析处理)能力。Cube(立方体)是ApacheKylin的核心概念之一,通过预计算大规模数据的多维数据集合,加速复杂...