
介绍如何通过Ollama+Docker在本地部署大模型_ollamadocker...

ollama可提供openAI一样的API接口_ollama端口...
![【开发心得】Dify部署ollama模型的坑[1]](/uploads/2024/08/21/1724227266523006227.webp)
本文接续上次的文章经过几次调试,目前部署终于稳定下来,由于算力问题产生的300timeout也逐渐减少了。因此,把后续在测试过程中碰到的一些坑和怎么爬出来,做一个记录。暂时就收集了3个问题,今后碰到再续写。_...

Ollama是一款强大的本地运行大型语言模型(LLM)的框架,它允许用户在自己的设备上直接运行各种大型语言模型,包括Llama2、Mistral、DolphinPhi等多种模型,无需依赖网络连接。此外,Ol...

等,进一步支撑你的行动,以提升本文的帮助力。_获取openwebui的请求头...
大家好,2024年4月,Meta公司开源了Llama3AI模型,迅速在AI社区引起轰动。紧接着,Ollama工具宣布支持Llama3,为本地部署大型模型提供了极大的便利。本文将介绍如何利用Ollama工具,实现L...

本地部署了大模型,下一步任务便是如何调用的问题,实际场景中个人感觉用http请求的方式较为合理,本篇文章也将通过http请求的方式来调用我们本地部署的大模型,正文开始。_ollamapython调用...

Ollama是一个强大的工具,适用于希望在本地环境中探索和使用大型语言模型的用户,特别是那些对AI技术有深入兴趣和需求的专业人士。_ollma...
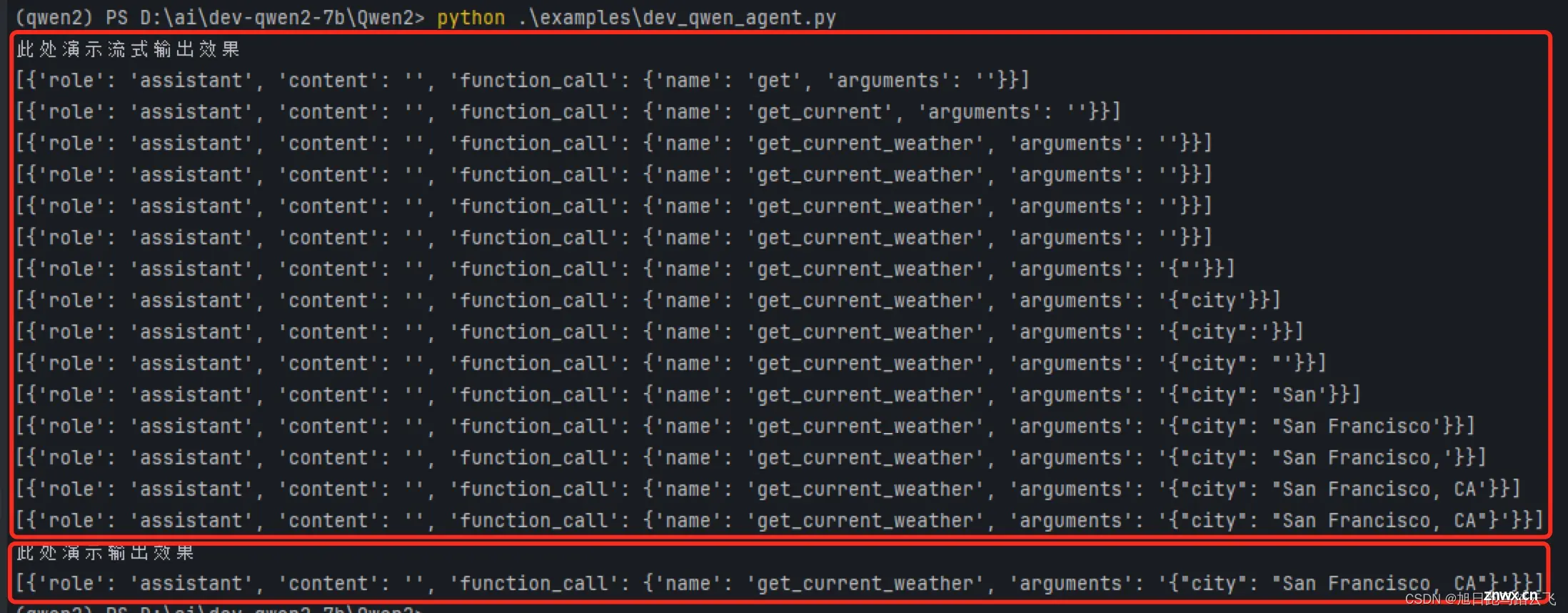
在目前AI的世界里,各大模型都还是跟着OpenAI在跑,API也尽量跟OpenAI保持一致。所以这里大致会有三个场景:OpenAI,其余模型自身的封装-这里选择qwen-agent,以及通用封装框架-这里选择La...
整个过程需要准备三个工具:Ollama:用于运行本地大模型的管理:llama3,qwen2等Docker:用于运行AnythingLLM。AnythingLLM:知识库运行平台,提供知识库构建及运行的功能。_ol...