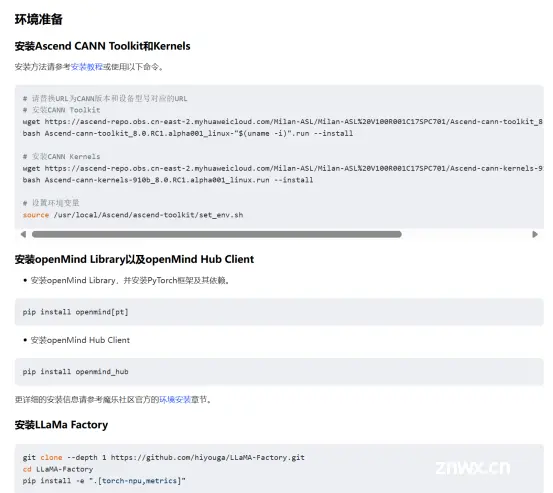
在2024年的AI领域,Meta发布的Llama3.1模型无疑成为了研究者和开发者的新宠。我有幸通过魔乐社区提供的资源,对这一模型进行了深入的学习和实践。在这个过程中,魔乐社区的资源和支持给我留下了深刻的印象。...
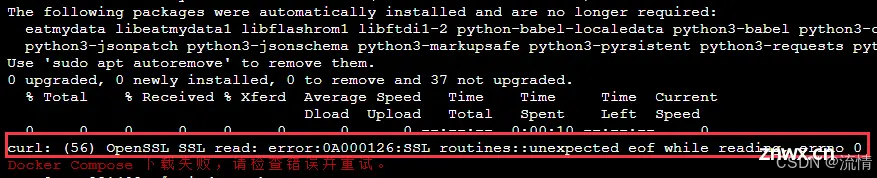
最近搞了一个测试服务器,捣鼓了下一键搭建dnmp集成环境,然后还搭建了一个Lyskpro图床服务,后面又看到了开源大模型,也试着搭建了一下,中间出了一点小插曲。不过也算搭建成功了。做一个小结汇总。_lskypro...

随着大型语言模型(LLM)的快速发展,它们为AI应用开发提供了强大的功能和灵活性。然而,在本地环境中部署和管理LLM仍然是一项挑战。Ollama和Dify两个开源项目为解决这一挑战提供了强大的解决方案...
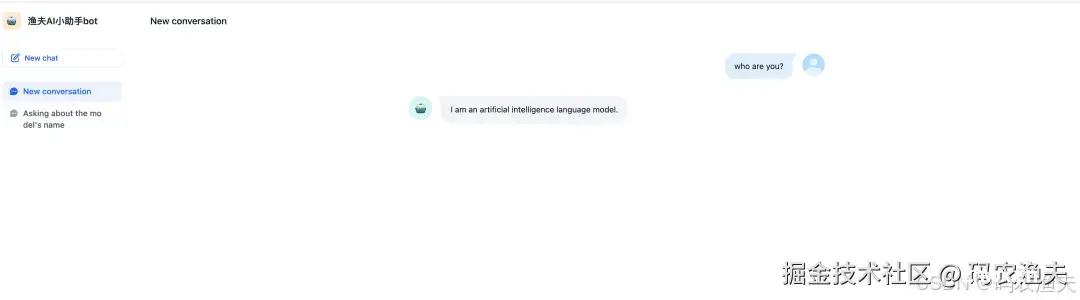
工欲善其事,必先利其器。AI是未来十年生产力的核心工具,要让AI真正转化为生产力,而不仅仅是围观一时的热潮。如果你对AI也很感兴趣,欢迎关注,共同探索AI的无限可能,与渔夫一起成长!今天聊聊AI智能...

整理|王启隆出品|AI科技大本营(ID:rgznai100)一分钟速览新闻点!苹果宣布9月10日举行发布会马斯克宣布将支持SB1047AI安全监管法案特朗普:没人比马斯克更懂AILlam...

GGUF格式的全名为(GPT-GeneratedUnifiedFormat),提到GGUF就不得不提到它的前身GGML(GPT-GeneratedModelLanguage)。GGML是专门为了...

通过llama.cpp运行7B.q4(4bit量化),7B.q8(8bit量化)模型,测量了生成式AI语言模型在多种硬件上的运行(推理)速度.根据上述测量结果,可以得到以下初步结论:(1...

LLM推理任务需要大量的算力,将现代GPU推向极限。过去两年,LLM训练和推理优化相关的研究进展速度惊人,每六个月就会出现新的突破。今天的分享主要,为大家介绍LLM推理领域所必备的一些基本数学与概念,...

下载OllamaOllama的官网地址Ollame的官网介绍。_ollamalinux安装...

LLaMA-Factory项目是一个专注于大模型训练、微调、推理和部署的开源平台。其主要目标是提供一个全面且高效的解决方案,帮助研究人员和开发者快速实现大模型的定制化需求。简化大模型训练流程:通过提供一系列预设的训练...