本专栏主要是提供一种国产化图像识别的解决方案,专栏中实现了YOLOv5/v8在国产化芯片上的使用部署,并可以实现网页端实时查看。根据自己的具体需求可以直接产品化部署使用。_yolo可在哪些芯片...

ASF-YOLO(Attention-basedSpatialFusionYOLO)是一种基于注意力机制的特征融合方法,旨在提高网络在处理不同尺度和语义信息时的能力。ASF-YOLO通过引入空间注意力机制和通道注意力机制,在特征融...

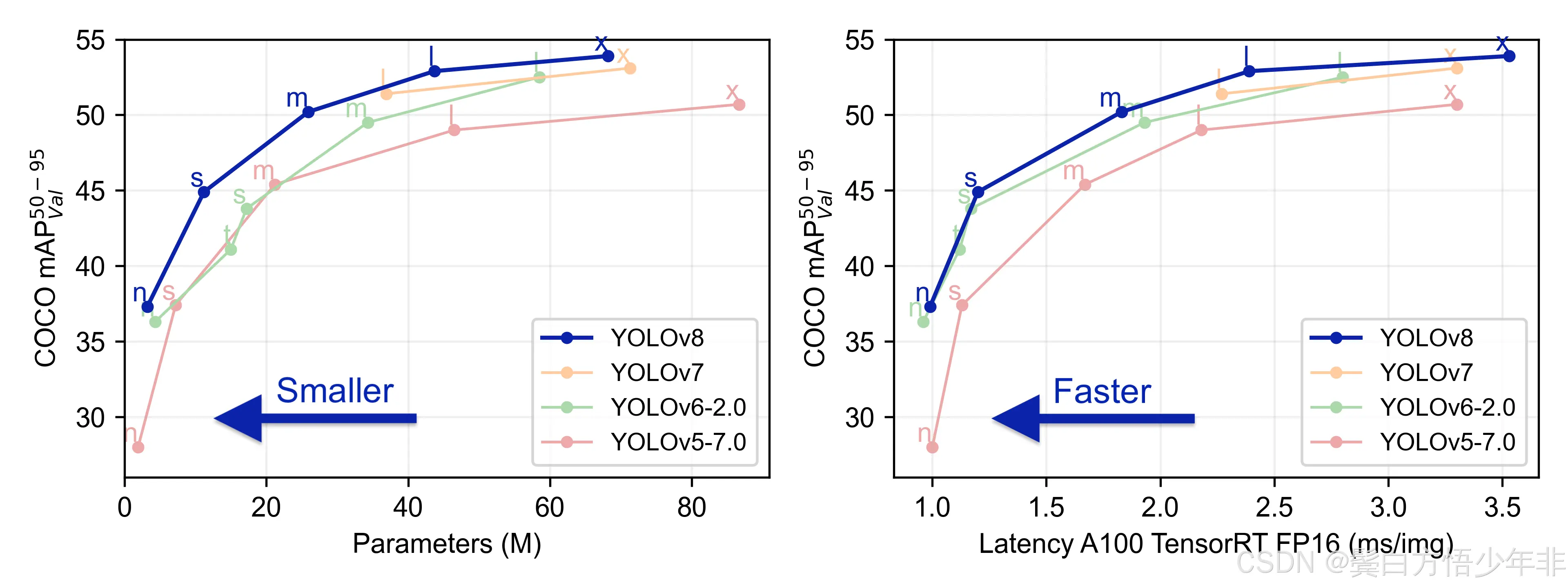
YOLO(YouOnlyLookOnce)系列模型以其端到端的检测能力和高效性广泛应用于目标检测任务。YOLOv8是YOLO系列中的最新版本,其改进了特征提取、特征融合和检测头设计等多个方面。YOLOv8的检测头主...
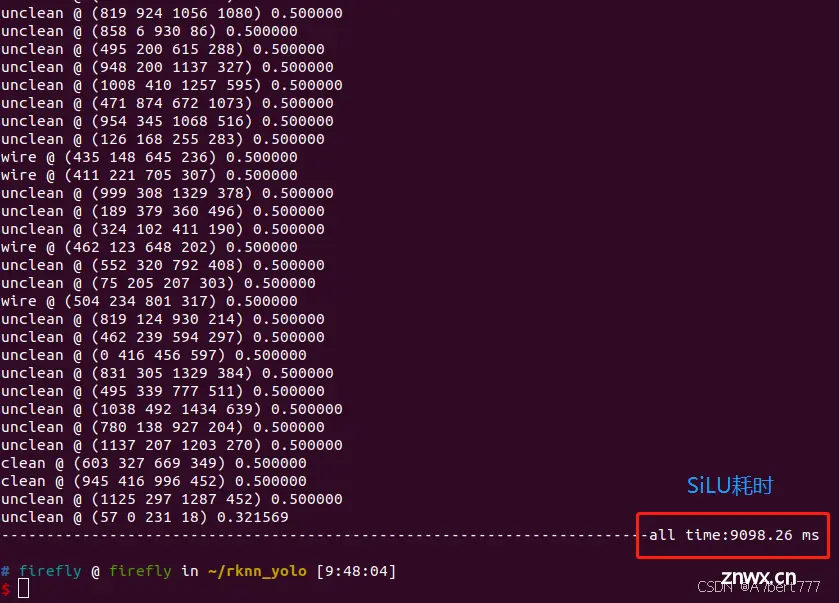
之前博主发布过YOLOv8转RKNN模型并在开发板上部署的流程,但是遇到了许多问题,发现很难修补,遂决定在官方项目下进行模型转换与部署(之前的转换是在Github个人博主的项目下进行的)OK,进入正题,模型转换需...

iAFF是一种基于注意力机制的特征融合方式,旨在逐步迭代特征图中的空间和通道维度信息。通过多个层次的注意力机制,该方法能够有效地融合来自不同尺度的特征信息,增强模型对小目标和细节的捕捉能力。相比传统的融合方法,iAFF不仅考虑了特征图中...

ConvNeXtV2是ConvNeXt系列的改进版,通过优化卷积层和掩码自编码器技术,进一步提高了网络的表示能力。全卷积掩码自编码器(FCM)在处理高维特征图时具有出色的性能,尤其是在细粒度特征提取和上下文信息建模方面。YOLOv8引入...
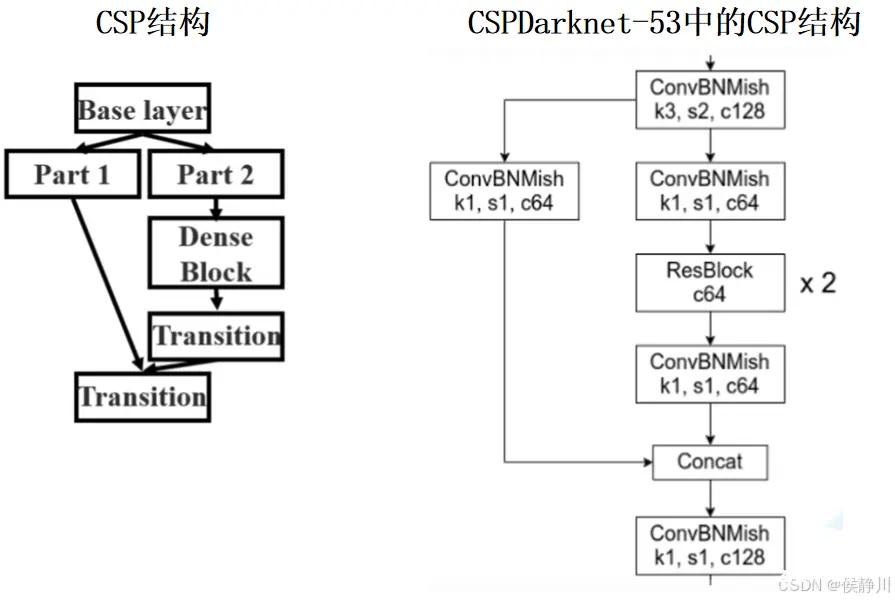
目标检测:YOLOv4、YOLOv5与YOLOv6理论知识笔记,根据B站up霹雳吧啦Wz与CSDN博主路人贾的目标检测相关博文总结。_yolov4和yolov5对比...

在目标检测领域,YOLO(YouOnlyLookOnce)系列凭借其实时性和高效性得到了广泛应用。然而,YOLO在处理小目标检测时,往往表现出一定的局限性。为了解决这一问题,Gold-YOLO提出了针对...

DynamicHead是YOLOv8中一个重要的改进组件,主要用于提高检测头的灵活性和适应性。该改进通过动态调整卷积核和特征图,从而更好地适应不同大小和形状的目标物体。DynamicHead的核心思想是根据输入图像的...

ASFF是一种基于自适应特征融合的策略,能够动态调整不同尺度特征的融合权重,适应场景中不同大小的目标。传统的YOLOv8检测头使用固定的特征融合策略,而ASFF则通过引入学习参数,使得网络能够根据输入图像的特征自适应地选择不同尺度特征的...