
机器学习(MachineLearning,ML)和人工智能(ArtificialIntelligence,AI)是紧密相关但又有区别的两个概念。(1)AI是一个广泛的领域,旨在实现机器的智能化。(2)机...

任重而道远。_java.lang.numberformatexception:forinputstring:...

如果上述方法都不行,作为一种临时解决方案,你可以直接修改mmcv源码,去掉verify参数。这个问题通常是因为yapf版本不兼容导致的。mmcv使用了yapf来格式化代码,但可能是mmcv的版本与...
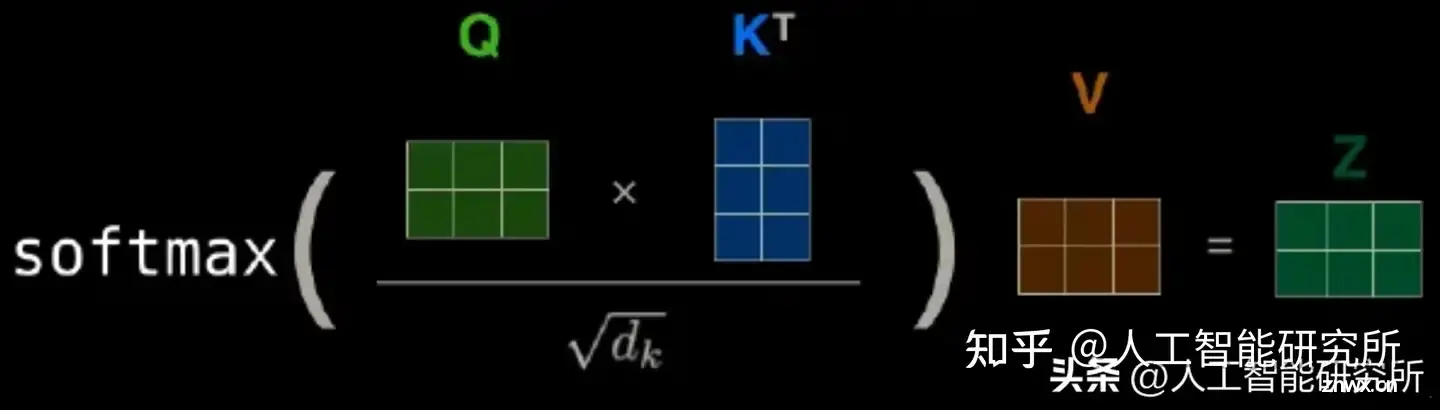
Mamba是一种新的状态空间模型架构,在语言建模等信息密集数据上显示出良好的性能,而以前的二次模型在Transformers方面存在不足。Mamba基于结构化状态空间模型的,并使用FlashAttention...

我们已经知道SCTranform的实际Normalize过程是调用的sctransform::vst函数,第一步拟合的代码在下面,可以发现实际代码是get_model_pars函数,get_model_pars中可以...
请注意,WebView2控件需要有效的Internet连接来下载Chromium相关的资源,并且在某些系统上可能需要额外的配置步骤。在实际部署应用程序之前,请确保检查WebView2的系统要求和部署注意事项。在.NE...
从2017年在《AttentionisAllYouNeed》中首次提出以来,Transformer模型已经成为自然语言处理(NLP)领域的最新技术。在2021年,论文《AnImageisWorth1...

vit的使用,读者可以自己修改超参数用到自己的数据集上面_transformer调用cifar-10...
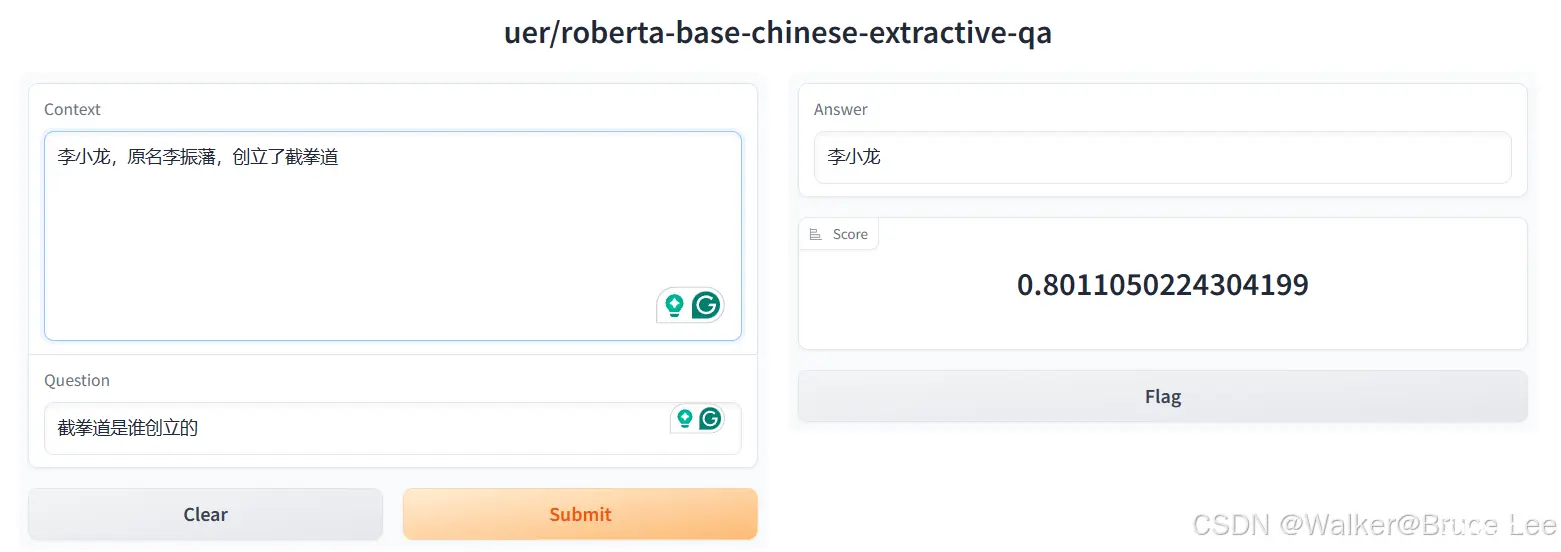
Transformer是大语言模型(LargeLanguageModel,LLM)的基础架构Transformers库是HuggingFace开源的可以完成各种语言、音频、视频、多模态任务情感分析文本生成命名...
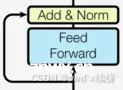
编码器部分:由N个编码器层堆叠而成,每个编码器层由两个子层连接结构组成,第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接,第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接�...