详解视觉Transformers
cv2016_DL 2024-09-02 10:31:02 阅读 79
一、什么是Vision Transformers?
从2017年在《Attention is All You Need》中首次提出以来,Transformer模型已经成为自然语言处理(NLP)领域的最新技术。在2021年,论文《An Image is Worth 16x16 Words》成功地将Transformer应用于计算机视觉任务。从那时起,基于Transformer的各种架构陆续被提出用于计算机视觉。
Transformer是一种利用注意力机制作为主要学习机制的机器学习模型,它很快成为了序列到序列任务(如语言翻译)的最新技术。论文《An Image is Worth 16x16 Words》成功地改造了《Attention is All You Need》中中提出的Transformer,用于解决图像分类任务,创建了Vision Transformer(ViT)。ViT基于与《Attention is All You Need》中中的Transformer相同的注意力机制。然而,与用于NLP任务的Transformers包含编码器和解码器两个注意力分支不同(当然现在主流的NLP如GPT只使用Decoder),ViT仅使用编码器。编码器的输出随后传递给一个神经网络“头”,进行预测。
《An Image is Worth 16x16 Words》中ViT的缺点是其最佳性能需要在大规模数据集上进行预训练。表现最好的模型是在专有的JFT-300M数据集上预训练的。在较小的开源数据集ImageNet-21k上预训练的模型,其性能与最新的卷积神经网络ResNet模型相当。《Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet》尝试通过引入一种新的预处理方法,将输入图像转换为一系列token,从而消除这种预训练需求。在本文中,我们将重点介绍《An Image is Worth 16x16 Words》中实现的ViT。
二、模型详解
本文遵循《An Image is Worth 16x16 Words》中描述的模型结构。然而,这篇论文中的代码没有公开。最新的Tokens-to-Token ViT的代码可以在GitHub上找到。Tokens-to-Token ViT(T2T-ViT)模型在一个基础的ViT骨干网络前加上了一个Tokens-to-Token(T2T)模块。本文中的代码基于Tokens-to-Token ViT GitHub代码中的ViT组件。本文所做的修改包括但不限于:允许输入非正方形图像,并去除了dropout层。下面是ViT模型的示意图。
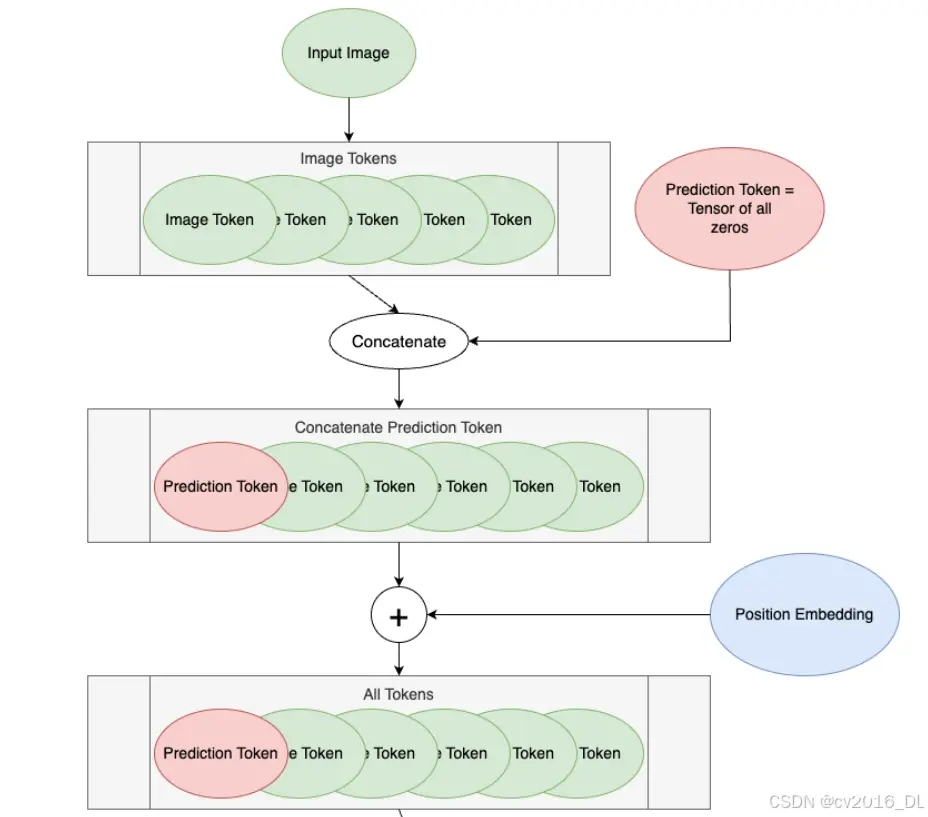
Vision Transformer (ViT) 工作流程(嵌入维度768):
1. Input Image(输入图像):
输入图像的尺寸是 <code>60 x 100 像素。
2. Image Tokens(图像Token):
将输入图像分割成多个 20 x 20 像素的块。图像的高度被分割成 60 / 20 = 3 行块。图像的宽度被分割成 100 / 20 = 5 列块。因此,总的块数为 3 * 5 = 15 个块。每个块被展平成一个长度为 20 * 20 = 400 的向量,所以我们有15个长度为400的图像Token。
3. Linearly Embed Patches(线性嵌入块):
将每个长度为400的图像Token通过一个线性变换映射到一个嵌入空间,生成长度为768的嵌入向量。768是经过Token化后的每个Token的维度或长度。在Vision Transformer (ViT) 中,每个图像块(Patch)在被展平并通过线性变换后,都会被映射到一个长度为768的嵌入向量。这意味着每个Token的表示是在768维的嵌入空间中。
这样,每个块就被表示为一个长度为768的嵌入向量。
4. Prediction Token(预测Token):
初始化一个全零的预测Token,长度为768(与每个图像Token的长度相同)。
5. Concatenate(拼接):
将预测Token与15个图像Token拼接在一起,形成一个包含16个Token的序列。序列的形式为:[预测Token, 图像Token1, 图像Token2, ..., 图像Token15],每个Token的长度为768。
6. Position Embedding and All Tokens(位置嵌入和所有Token):
为16个Token(包括预测Token和图像Token)添加位置嵌入。位置嵌入是一个与Token序列长度相同的向量,用于表示每个Token在序列中的位置。位置嵌入的维度也是768。添加位置嵌入后的序列仍然是16个Token,每个Token的长度为768。这一步确保所有Token(包括预测Token和图像Token)都已经添加了位置信息,并且准备好进行下一步的编码块处理。
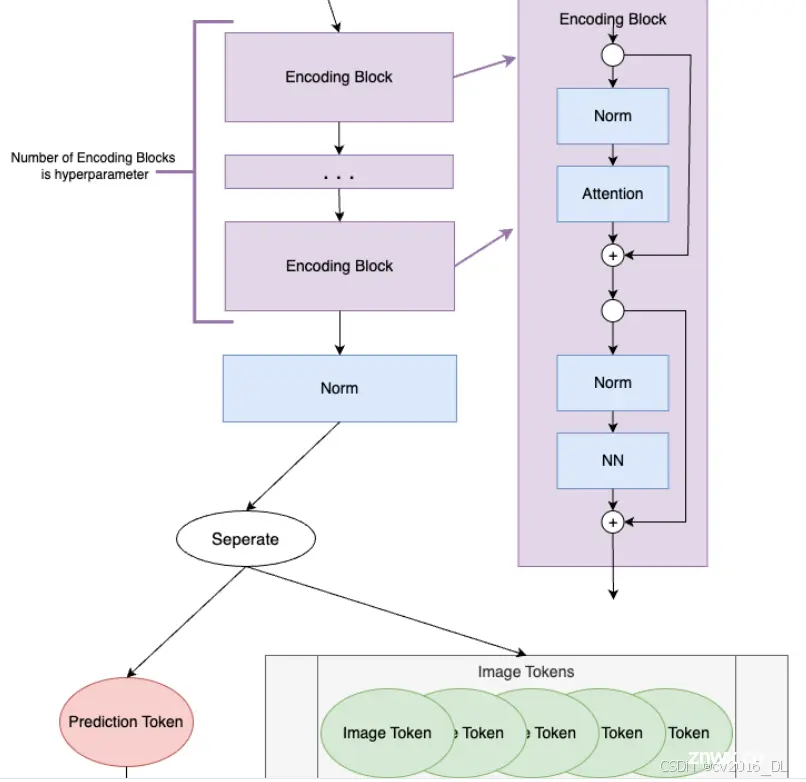
7. Encoding Block(编码块):
这些Token序列通过一系列的编码块进行处理。在你的代码示例中,编码块的数量是12(由depth参数指定)。每个编码块包含以下组件:
Norm(规范化层):对输入进行规范化,确保输入数据在不同维度上的分布更加均匀。
Attention(注意力层):应用多头自注意力机制来捕捉Token之间的关系。注意力机制允许每个Token与其他Token交换信息,从而捕捉图像的全局特征。
Norm(规范化层):再次进行规范化,确保在经过注意力层之后的数据继续保持均匀分布。
NN(神经网络):一个小型的前馈神经网络,由一个全连接层、一个激活层和另一个全连接层组成。前馈神经网络进一步处理和转换Token信息。
经过12个编码块的处理后,每个Token(包括预测Token)都被充分处理和转换,捕捉到了输入图像的丰富特征信息。
8. Seperate(分离):
从编码块输出的16个Token序列中分离出预测Token和图像Token。此时,预测Token已经通过多个编码块获取了输入图像的信息。分离操作通常是通过索引来实现的,例如:
# 从编码块输出的Token序列中提取预测Token prediction_token = encoded_tokens[:, 0] # 提取图像Token image_tokens = encoded_tokens[:, 1:]
通过这种方式,我们可以得到一个包含预测信息的预测Token和15个图像Token。
9. Prediction Token(预测Token):
提取后的预测Token,已经从编码块中获取了输入图像的信息。这个Token包含了用于最终预测的所有必要信息。由于预测Token在多个编码块中与其他图像Token进行了交互,它已经聚合了整个图像的全局特征。
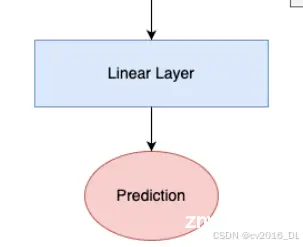
10. Linear Layer(线性层):
预测Token通过一个线性层来生成最终的预测结果。这个线性层将预测Token映射到输出空间,输出形状根据具体的学习任务进行设置。例如:
对于分类任务,输出是一个长度为类数的向量,每个元素表示对应类别的概率。
对于回归任务,输出是一个或多个预测值。
# 假设我们有一个线性层用于分类任务 linear_layer = nn.Linear(768, num_classes) prediction = linear_layer(prediction_token)
11. Prediction(预测结果):
最终的预测结果。例如,在图像分类任务中,预测结果可以是一个包含所有类别概率的向量,然后选择概率最高的类别作为最终分类结果。
# 对于分类任务,选择概率最高的类别作为最终预测结果 predicted_class = torch.argmax(prediction, dim=-1)
解释
图像Token:每个图像块被展平成一个Token,然后通过线性变换映射到嵌入空间,生成长度为768的嵌入向量。
预测Token:初始时是全零,但在经过多个编码块的处理后,它会逐渐聚合图像中的信息,最终用于预测。
注意力机制:在编码块中,注意力机制允许每个Token(包括预测Token)与其他Token交互,从而捕捉图像的全局特征。
嵌入维度768:所有Token(包括图像Token和预测Token)在嵌入空间中的表示长度都是768,这使得它们能够在编码块中进行有效的交互和处理。
通过这个过程,ViT模型不仅提取图像的局部特征(通过图像Token),还通过预测Token聚合这些特征并用于最终的预测。
那为什么图像token是15个 而预测token只是一个?预测token中最终会包含什么信息?
让我们详细解释为什么图像Token有15个,而预测Token只有一个,以及预测Token最终会包含什么信息。
1. 图像Token的数量
图像Token的数量是由图像分割成的块(patch)的数量决定的。在你的例子中:
输入图像的尺寸是 60 x 100 像素。
每个块的尺寸是 20 x 20 像素。
图像的高度被分割成 60 / 20 = 3 行块。
图像的宽度被分割成 100 / 20 = 5 列块。
因此,总的块数是 3 * 5 = 15 个块。
每个块被展平成一个长度为 20 * 20 = 400 的向量,所以我们有15个长度为400的图像Token。
2. 预测Token的数量
预测Token只有一个,这是设计ViT模型的一部分。这个单一的预测Token初始时是全零的,长度为400(与每个图像Token的长度相同)。
3. 预测Token的作用
预测Token的主要作用是通过注意力机制和编码块来聚合所有图像Token中的信息,最终用于生成预测结果。具体来说:
初始阶段:预测Token是一个全零的向量,长度为400。
编码块处理:在每个编码块中,预测Token与所有图像Token进行交互(通过注意力机制)。注意力机制允许每个Token与其他Token交换信息。
信息聚合:通过多个编码块的处理,预测Token逐渐聚合了所有图像Token的信息。这意味着预测Token在多个编码块处理之后,包含了整个图像的全局特征。
4. 预测Token最终包含的信息
经过多个编码块的处理后,预测Token会包含以下信息:
全局特征:预测Token聚合了所有图像Token的信息,表示整个图像的全局特征。
上下文信息:通过注意力机制,预测Token能够捕捉到图像的上下文信息和不同部分之间的关系。
5. 预测Token如何用于最终预测
最终的预测步骤如下:
提取预测Token:从编码块输出的Token序列中提取预测Token。
线性层:预测Token通过一个线性层生成最终的预测结果。这个线性层的输出形状根据具体的学习任务设置。例如:
对于分类任务,输出是一个长度为类数的向量。
对于回归任务,输出是一个或多个预测值。
预测结果:最终的预测结果。例如,在图像分类任务中,预测结果可以是一个包含所有类别概率的向量,然后选择概率最高的类别作为最终分类结果。
总结起来,单一的预测Token通过多个编码块的处理,聚合了所有图像Token的信息,包含了整个图像的全局特征和上下文信息。这个预测Token最终用于生成模型的预测结果。
接下来,我们详细介绍上述关键步骤以及代码实现。
三、图像标记化 Image Tokenization
ViT的第一步是从输入图像创建tokens。Transformers在一系列tokens上操作;在NLP中,这通常是一句话中的单词。对于计算机视觉来说,ViT将图像转换为tokens,使得每个token代表图像的一个局部区域——或称为patch。他们描述了将高度为H、宽度为W、通道数为C的图像重新排列为N个大小为P的patch tokens:

每个token的长度为 P²∗C。
让我们来看一个patch tokenization的示例,这里使用的是Luis Zuno (@ansimuz)的像素艺术作品《Mountain at Dusk》。原始作品已经被裁剪并转换为单通道图像。这意味着每个像素的值在零到一之间。单通道图像通常以灰度显示;然而,我们将以紫色配色方案显示它,因为这样更容易看清。
<code>mountains =np.load(os.path.join(figure path,"mountains.npy"))
H= mountains.shape[0]
W= mountains.shape[1]
print('Mountain at Dusk is H=',H,'and W =',W,'pixels.')code>
print('\n')
fig = plt.figure(figsize=(10,6))
plt.imshow(mountains,cmap='Purples_r')code>
plt.xticks(np.arange(-0.5,W+1,10),labels=np.arange(0, W+1, 10))
plt.yticks(np.arange(-0.5,H+1,10),labels=np.arange(0, H+1, 10))
plt.clim([e,1])
cbar_ax= fig.add_axes([0.95,.11,0.05,0.77])
plt.clim([e,1])
plt.colorbar(cax=cbar_ax);
#plt.savefig(os.path.join(figure path, 'mountains.png'),bbox inches='tight')code>
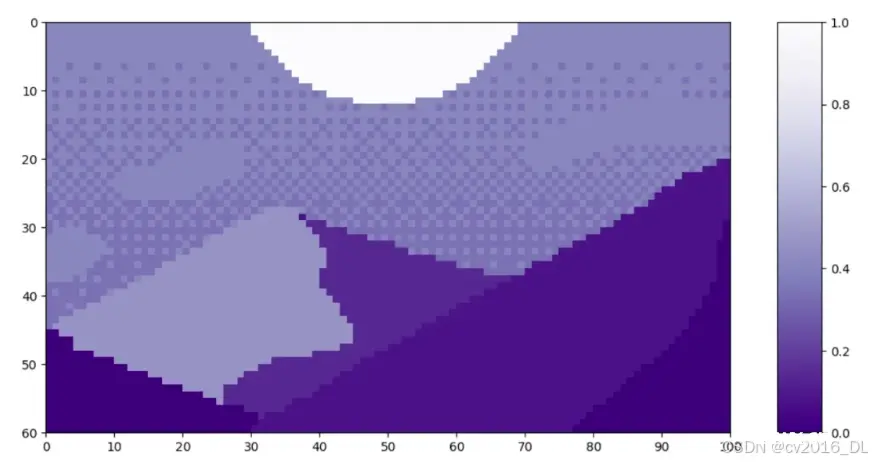
这幅图像的高度 H=60,宽度 W=100。我们将 P 设置为 20,因为它能够整除 H 和 W。
表示“patch size”,即图像分割成小块(patch)的尺寸。在Vision Transformer (ViT)模型中,图像被分割成大小相同的patch,然后每个patch被转换成一个token。每个token将被输入到Transformer模型中进行处理。
具体来说:
H:图像的高度。
W:图像的宽度。
P:patch的尺寸,即每个patch的高度和宽度。
当你将图像分割成大小为P×P的patch时,图像将被划分成多个小块,每个小块都是一个P×P的子图像。对于每个patch,都可以将其展平并转换为一个向量,这个向量就是一个token。然后,这些token将作为输入传递给Transformer模型。
在这个示例中,图像的高度H是60,宽度W是100。选择P=20,因为20能够整除60和100,这样可以确保图像被均匀地分割成不重叠的patch。具体来说,图像将被分割成(60 / 20)×(100 / 20)= 3 × 5 = 15个patch。

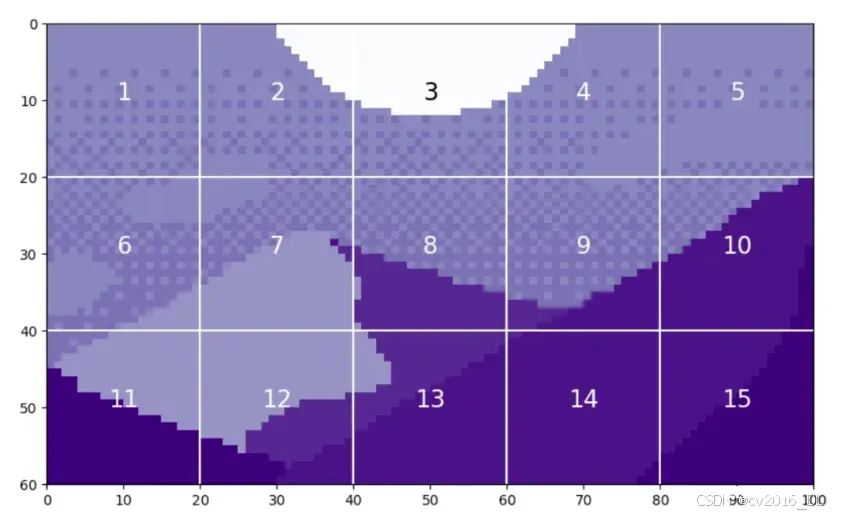
通过将这些小块展平,我们可以看到生成的tokens。我们以第12个小块为例进行观察,因为它包含了四种不同的色调。

每个 patch将产生一个长度为 400 的令牌。

从图像中提取tokens之后,通常会使用线性投影来改变这些tokens的长度。这通过一个可学习的线性层来实现。tokens的新长度被称为潜在维度、通道维度或者token长度。经过投影后,这些tokens不再能从视觉上识别为原始图像中的某个小块。现在我们已经理解了这个概念,我们可以来看一下在代码中如何实现小块token化。
在代码中,Patch Tokenization(块标记化)是通过一个自定义的PyTorch模块实现的,该模块首先将图像分割成小块,然后将每个小块展平并通过线性变换映射到指定的嵌入空间。让我们详细解析一下代码中是如何实现Patch Tokenization的。
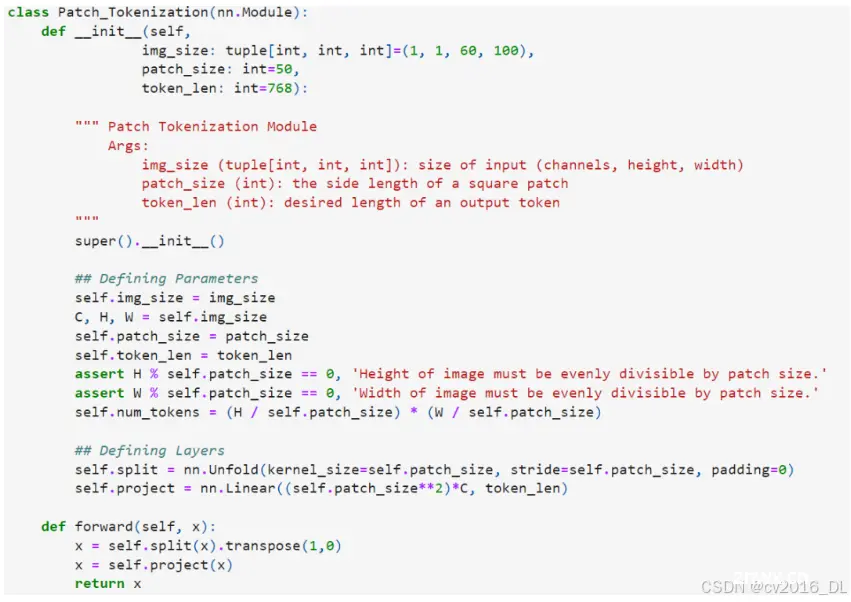
请注意,这里的两个断言语句确保了图像的尺寸可以被小块的大小整除。实际将图像分割成小块的操作是通过 <code>torch.nn.Unfold 层实现的。
我们将使用裁剪后的、单通道版本的《Mountain at Dusk》运行这个代码示例。我们应该能看到上面提到的token数量和初始token大小的值。我们将使用 token_len=768 作为投影后的长度,这是ViT基础版本的尺寸。在Vision Transformer (ViT) 模型中,出现的数字768通常是指Token的嵌入维度(embedding dimension)。
下面代码块的第一行将《Mountain at Dusk》从NumPy数组转换为Torch张量。我们还需要对张量进行 unsqueeze 操作,以创建一个通道维度和一个批次大小维度。如上所述,我们只有一个通道。由于只有一张图像,批次大小 batchsize 为1。
x = torch.from_numpy(mountains).unsqueeze(0).unsqueeze(0).to(torch.float32)
token_len = 768
print('Input dimensions are\n\tbatchsize:', x.shape[0], '\n\tnumber of input channels:', x.shape[1], '\n\timage size:', (x.shape[2], x.shape[3]))
# Define the Module
patch_tokens = Patch_Tokenization(img_size=(x.shape[1], x.shape[2], x.shape[3]),
patch_size = P,
token_len = token_len)
Input dimensions are
batchsize: 1
number of input channels: 1
image size: (60, 100)
现在,我们将把图像分割成tokens。
x = patch_tokens.split(x).transpose(2,1)print('After patch tokenization, dimensions are\n\tbatchsize:', x.shape[0], '\

现在我们已经得到了tokens,接下来我们可以继续进行ViT的处理。
四、Token处理 Token Processing
接下来我们使用另外的例子,而不再是上面《Mountain at Dusk》的例子。
在编码块之前的ViT的接下来的两个步骤,我们称之为“Token Processing”。下图展示了ViT图示中的Token Processing部分。
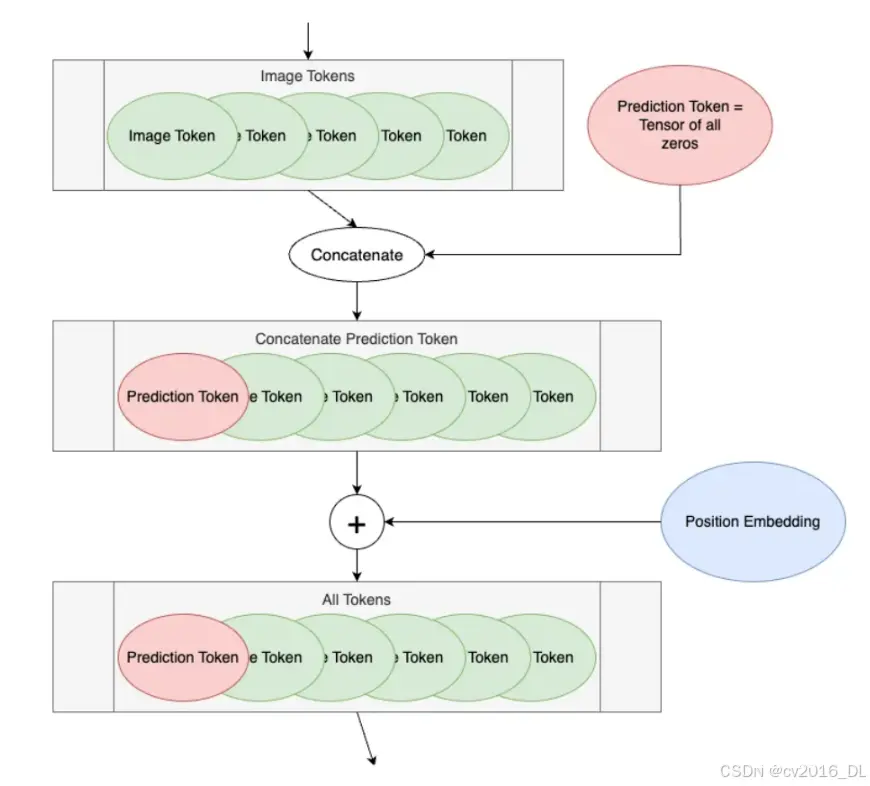
第一步是在图像tokens前添加一个空白token,称为预测token。这个token将在编码块的输出中用于做出预测。它一开始是空白的,这样它可以从其他图像tokens中获取信息。
我们将从175个tokens开始。每个token的长度为768,这是ViT基础版本的尺寸。我们使用批次大小为13,因为它是质数,不会与其他参数混淆。
<code># Define an Inputnum_tokens = 175token_len = 768batch = 13x = torch.rand(batch, num_tokens, token_len)print('Input dimensions are\n\tbatchsize:', x.shape[0], '\n\tnumber of tokens:', x.shape[1], '\n\ttoken length:', x.shape[2])
# Append a Prediction Tokenpred_token = torch.zeros(1, 1, token_len).expand(batch, -1, -1)print('Prediction Token dimensions are\n\tbatchsize:', pred_token.shape[0], '\n\tnumber of tokens:', pred_token.shape[1], '\n\ttoken length:', pred_token.shape[2])
x = torch.cat((pred_token, x), dim=1)print('Dimensions with Prediction Token are\n\tbatchsize:', x.shape[0], '\n\tnumber of tokens:', x.shape[1], '\n\ttoken length:', x.shape[2])

现在,我们为我们的tokens添加位置嵌入。位置嵌入允许transformer理解图像tokens的顺序。请注意,这里是相加操作,而不是连接操作。位置嵌入的具体细节是一个较为复杂的话题,留待以后再详细讨论。 def get_sinusoid_encoding(num_tokens, token_len):
<code> """ Make Sinusoid Encoding Table
Args: num_tokens (int): number of tokens token_len (int): length of a token
Returns: (torch.FloatTensor) sinusoidal position encoding table """
def get_position_angle_vec(i): return [i / np.power(10000, 2 * (j // 2) / token_len) for j in range(token_len)]
sinusoid_table = np.array([get_position_angle_vec(i) for i in range(num_tokens)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
PE = get_sinusoid_encoding(num_tokens+1, token_len)print('Position embedding dimensions are\n\tnumber of tokens:', PE.shape[1], '\n\ttoken length:', PE.shape[2])
x = x + PEprint('Dimensions with Position Embedding are\n\tbatchsize:', x.shape[0], '\n\tnumber of tokens:', x.shape[1], '\n\ttoken length:', x.shape[2])

现在,我们的tokens已经准备好进入编码块。
五、编码块 Encoding Block Prerequisite Code
编码块是模型实际从图像tokens中学习的地方。编码块的数量是由用户设置的超参数。下面是编码块的示意图。
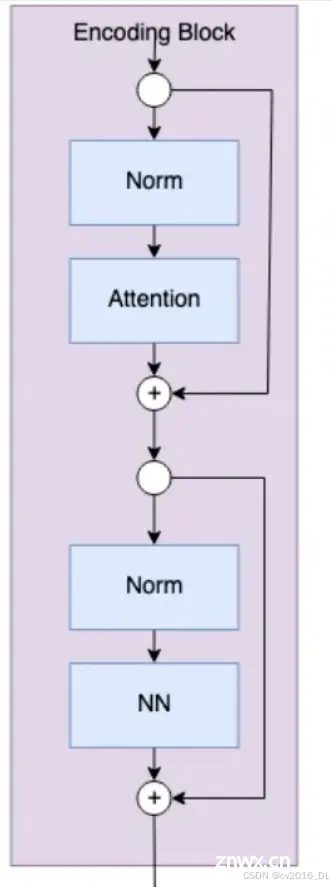
编码块的代码如下所示。
<code>
class Encoding(nn.Module):
def __init__(self,
dim: int,
num_heads: int=1,
hidden_chan_mul: float=4.,
qkv_bias: bool=False,
qk_scale: NoneFloat=None,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
""" Encoding Block
Args:
dim (int): size of a single token
num_heads(int): number of attention heads in MSA
hidden_chan_mul (float): multiplier to determine the number of hidden channels (features) in the NeuralNet component
qkv_bias (bool): determines if the qkv layer learns an addative bias
qk_scale (NoneFloat): value to scale the queries and keys by;
if None, queries and keys are scaled by ``head_dim ** -0.5``
act_layer(nn.modules.activation): torch neural network layer class to use as activation
norm_layer(nn.modules.normalization): torch neural network layer class to use as normalization
"""
super().__init__()
## Define Layers
self.norm1 = norm_layer(dim)
self.attn = Attention(dim=dim,
chan=dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale)
self.norm2 = norm_layer(dim)
self.neuralnet = NeuralNet(in_chan=dim,
hidden_chan=int(dim*hidden_chan_mul),
out_chan=dim,
act_layer=act_layer)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.neuralnet(self.norm2(x))
return x
num_heads、qkv_bias 和 qk_scale 参数定义了注意力模块的组件。
hidden_chan_mul 和 act_layer 参数定义了神经网络模块的组件。激活层可以是任何 torch.nn.modules.activation 层。
norm_layer 可以从任何 torch.nn.modules.normalization 层中选择。
现在我们将逐步解析图示中的每个蓝色块及其对应的代码。我们将使用长度为768的176个tokens。我们将使用批次大小为13,因为它是质数,不会与其他参数混淆。我们将使用4个注意力头,因为它可以整除token的长度;不过,在编码块中你不会看到注意力头的维度。
# Define an Inputnum_tokens = 176token_len = 768batch = 13heads = 4x = torch.rand(batch, num_tokens, token_len)print('Input dimensions are\n\tbatchsize:', x.shape[0], '\n\tnumber of tokens:', x.shape[1], '\n\ttoken length:', x.shape[2])
# Define the ModuleE = Encoding(dim=token_len, num_heads=heads, hidden_chan_mul=1.5, qkv_bias=False, qk_scale=None, act_layer=nn.GELU, norm_layer=nn.LayerNorm)E.eval();

现在,我们将通过一个规范化层和一个注意力模块。编码块中的注意力模块经过参数化处理,因此不会改变token的长度。在注意力模块之后,我们实现了第一个分离连接。
<code>y = E.norm1(x)print('After norm, dimensions are\n\tbatchsize:', y.shape[0], '\n\tnumber of tokens:', y.shape[1], '\n\ttoken size:', y.shape[2])y = E.attn(y)print('After attention, dimensions are\n\tbatchsize:', y.shape[0], '\n\tnumber of tokens:', y.shape[1], '\n\ttoken size:', y.shape[2])y = y + xprint('After split connection, dimensions are\n\tbatchsize:', y.shape[0], '\n\tnumber of tokens:', y.shape[1], '\n\ttoken size:', y.shape[2])

现在,我们通过另一个规范化层,然后是神经网络模块。最后,我们完成第二个分离连接。
<code>z = E.norm2(y)print('After norm, dimensions are\n\tbatchsize:', z.shape[0], '\n\tnumber of tokens:', z.shape[1], '\n\ttoken size:', z.shape[2])z = E.neuralnet(z)print('After neural net, dimensions are\n\tbatchsize:', z.shape[0], '\n\tnumber of tokens:', z.shape[1], '\n\ttoken size:', z.shape[2])z = z + yprint('After split connection, dimensions are\n\tbatchsize:', z.shape[0], '\n\tnumber of tokens:', z.shape[1], '\n\ttoken size:', z.shape[2])

这就是一个编码块的全部内容。由于最终的维度与初始维度相同,模型可以轻松地将tokens传递通过多个编码块,这由深度超参数设置。
六、神经网络模块
神经网络(NN)模块是编码块的一个子组件。NN模块非常简单,由一个全连接层、一个激活层和另一个全连接层组成。激活层可以是任何 <code>torch.nn.modules.activation 层,并作为输入传递给模块。NN模块可以配置为改变输入的形状,或者保持相同的形状。我们不会逐步解析这段代码,因为神经网络在机器学习中非常常见,并不是本文的重点。然而,下面是NN模块的代码。
class NeuralNet(nn.Module):
def __init__(self,
in_chan: int,
hidden_chan: NoneFloat=None,
out_chan: NoneFloat=None,
act_layer = nn.GELU):
""" Neural Network Module
Args:
in_chan (int): number of channels (features) at input
hidden_chan (NoneFloat): number of channels (features) in the hidden layer;
if None, number of channels in hidden layer is the same as the number of input channels
out_chan (NoneFloat): number of channels (features) at output;
if None, number of output channels is same as the number of input channels
act_layer(nn.modules.activation): torch neural network layer class to use as activation
"""
super().__init__()
## Define Number of Channels
hidden_chan = hidden_chan or in_chan
out_chan = out_chan or in_chan
## Define Layers
self.fc1 = nn.Linear(in_chan, hidden_chan)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_chan, out_chan)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
return x
预测处理
在通过编码块之后,模型必须做的最后一件事就是进行预测。下面展示的是ViT图中的“预测处理”组件。
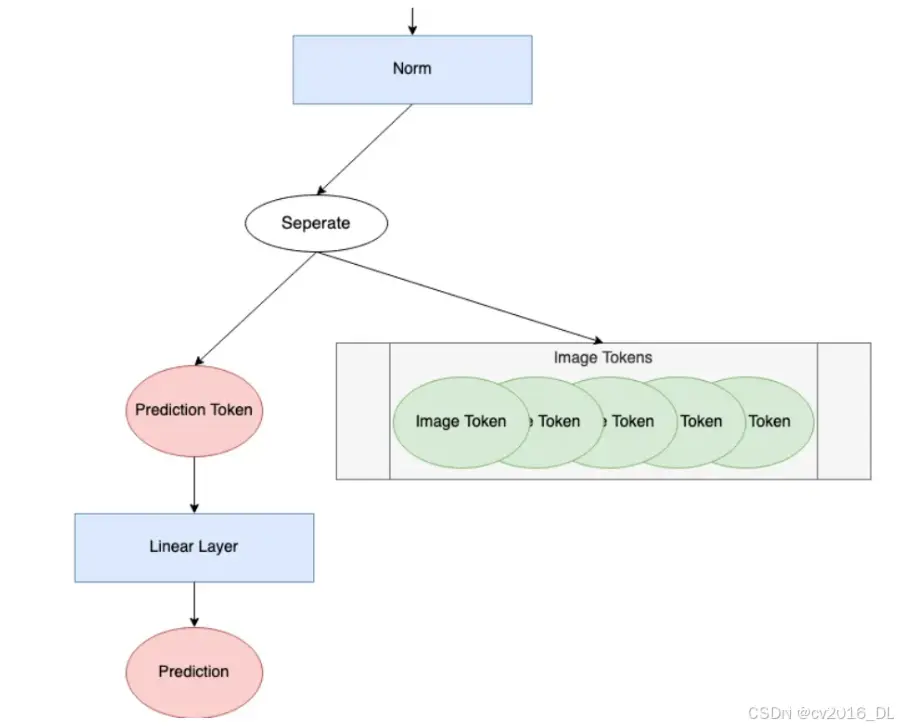
我们将查看此过程的每一步。我们将继续使用长度为768的176个tokens。为了说明单个预测是如何进行的,我们将使用批次大小为1。批次大小大于1时,则会并行计算这些预测。
<code># Define an Inputnum_tokens = 176token_len = 768batch = 1x = torch.rand(batch, num_tokens, token_len)print('Input dimensions are\n\tbatchsize:', x.shape[0], '\n\tnumber of tokens:', x.shape[1], '\n\ttoken length:', x.shape[2])

首先,所有的token都通过一个norm layer.。norm = nn.LayerNorm(token_len)
<code>x = norm(x)print('After norm, dimensions are\n\tbatchsize:', x.shape[0], '\n\tnumber of tokens:', x.shape[1], '\

接下来,我们将预测token与其余的tokens分离。在整个编码块过程中,预测token变得非零并获取了关于输入图像的信息。我们将仅使用这个预测token来进行最终预测。
<code>pred_token = x[:, 0]print('Length of prediction token:', pred_token.shape[-1])
Length of prediction token: 768
最后,预测token会通过head来进行预测。head通常是某种神经网络,其形式取决于具体模型。在《An Image is Worth 16x16 Words》中,他们在预训练期间使用了一个带有隐藏层的多层感知器(MLP),而在微调期间使用了一个单一的线性层。在《Tokens-to-Token ViT》³中,他们使用了一个单一的线性层作为head。这个示例中也将使用一个单一的线性层。
需要注意的是,head的输出形状是根据学习问题的参数设置的。对于分类任务,输出通常是一个长度为类数的one-hot编码向量。对于回归任务,输出则是任意整数个预测参数。在这个示例中,将使用输出形状为1来表示单个估计的回归值。head = nn.Linear(token_len, 1)
pred = head(pred_token)print('Length of prediction:', (pred.shape[0], pred.shape[1]))print('Prediction:', float(pred))
Length of prediction: (1, 1)
Prediction: -0.5474240779876709
参考文章:
https://towardsdatascience.com/vision-transformers-explained-a9d07147e4c8
https://github.com/lanl/vision_transformers_explained/blob/main/notebooks/VisionTransformersExplained.ipynb
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。