
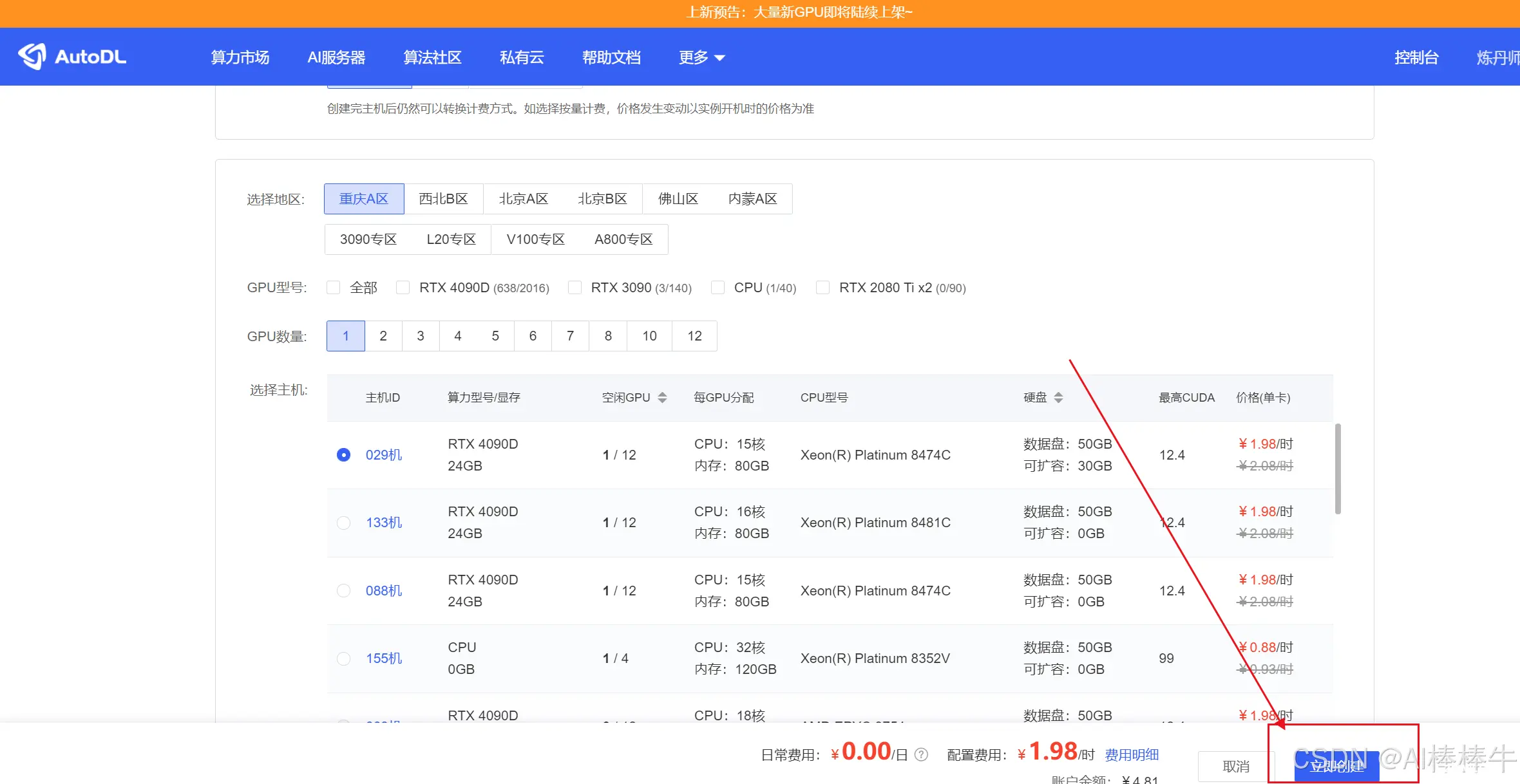
高通AIEngine使用教程_qnnsdk...

通过llama.cpp运行7B.q4(4bit量化),7B.q8(8bit量化)模型,测量了生成式AI语言模型在多种硬件上的运行(推理)速度.根据上述测量结果,可以得到以下初步结论:(1...

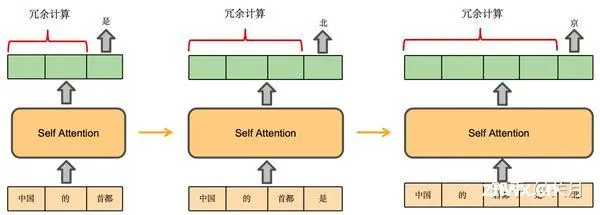
LLM推理任务需要大量的算力,将现代GPU推向极限。过去两年,LLM训练和推理优化相关的研究进展速度惊人,每六个月就会出现新的突破。今天的分享主要,为大家介绍LLM推理领域所必备的一些基本数学与概念,...
Ai学术叫叫兽全网最新创新点改进系列:YOLOv10环境搭建,一镜到底,手把手教学,傻瓜式操作,一分钟完全掌握yolov10安装、使用、训练大全,从环境搭建到模型训练、推理,从入门到精通!...
大模型推理加速的目标是高吞吐量、低延迟。吞吐量为一个系统可以并行处理的任务量。延时,指一个系统串行处理一个任务时所花费的时间。调研了一些大模型推理的框架。_大模型推理框架加速...
北京时间4月19日凌晨,Meta在官网上官宣了Llama-3,作为继Llama1、Llama2和CodeLlama之后的第三代模型,Llama3在多个基准测试中实现了全面领先,性能优于业界同类最先进的模型,你有没有...
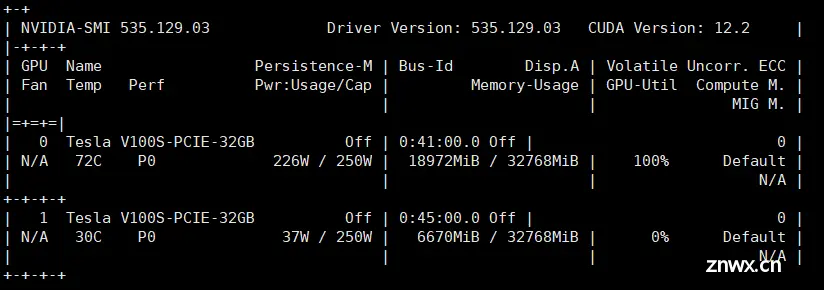
HuggingFace的库支持自动模型(AutoModel)的模型实例化方法,来自动载入并使用GPT、ChatGLM等模型。在方法中的device_map参数,可实现单机多卡推理。_transformer多卡推理...
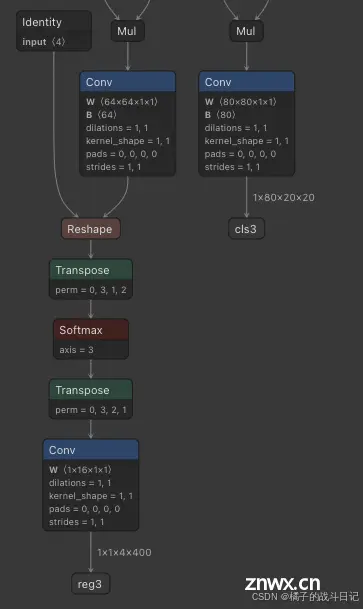
本专栏主要是提供一种国产化图像识别的解决方案,专栏中实现了YOLOv5/v8在国产化芯片上的使用部署,并可以实现网页端实时查看。根据自己的具体需求可以直接产品化部署使用。_yolov8rk3588fps...
本次比赛提供基于自然语言的逻辑推理问题,涉及多样的场景,包括关系预测、数值计算、谜题等,期待选手通过分析推理数据,利用机器学习、深度学习算法或者大语言模型,建立预测模型。初赛数据集为逻辑推理数据,其中训练集中包含50...
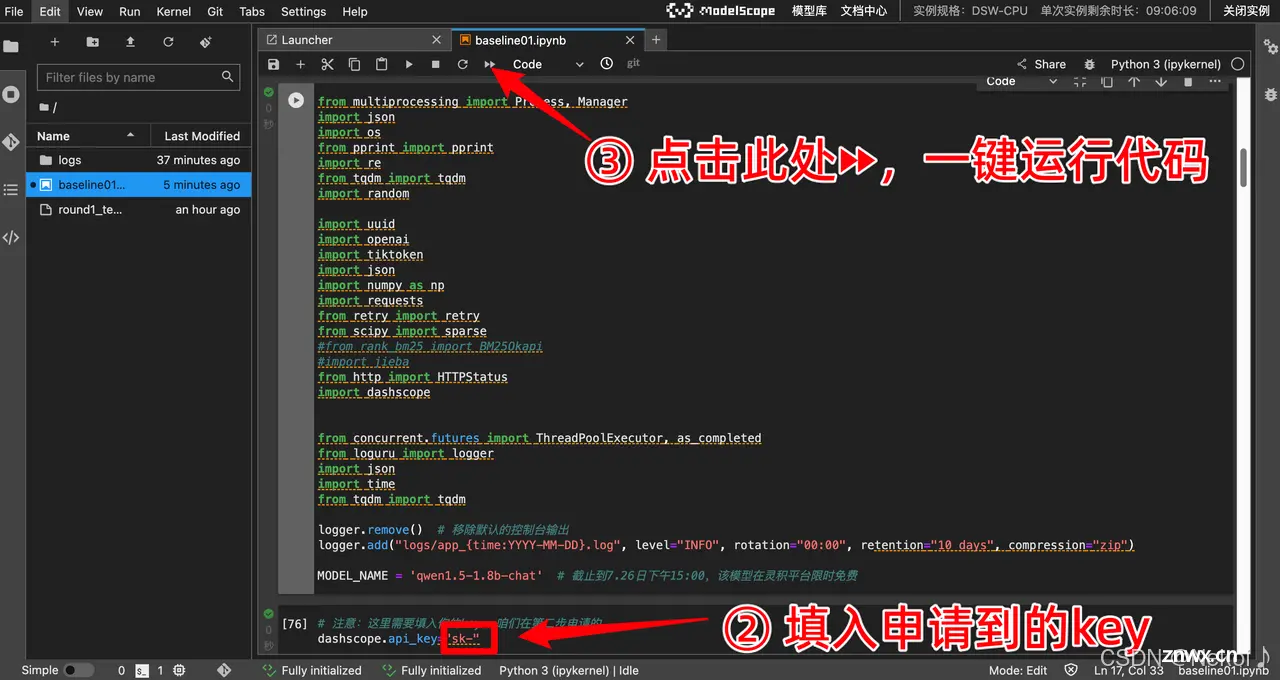
AI+逻辑推理比赛是由上海科学智能研究院、复旦大学联合阿里云在上智院·天池平台发布“第二届世界科学智能大赛”的逻辑推理赛道:复杂推理能力评估,该比赛聚焦于通过解决复杂的逻辑推理题,测试大型语言模型的逻辑推理能力。选手...