Datawhale AI 夏令营 第三期逻辑推理学习笔记
非一般将来时 2024-08-27 08:31:02 阅读 87
目录
赛题介绍Task1——跑通baseline结果
Task2——baseline代码解析部分核心代码
Task3——lora微调、vllm部署、多路投票loravllm部署多路投票
总结todo整理当前上分记录具体
后续上分思路上分之路
Datawhale AI 夏令营 第三期逻辑推理学习笔记
本期此项目手册:
https://datawhaler.feishu.cn/wiki/NOVDw5OtLiKJhlkbmoXc8nCinMf
赛题介绍
本次比赛提供基于自然语言的逻辑推理问题,涉及多样的场景,包括关系预测、数值计算、谜题等,期待选手通过分析推理数据,利用机器学习、深度学习算法或者大语言模型,建立预测模型。
初赛数据集为逻辑推理数据,其中训练集中包含500条训练数据,测试集中包含500条测试数据。每个问题包括若干子问题,每个子问题为单项选择题,选项不定(最多5个)。目标是为每个子问题选择一个正确答案。推理答案基于闭世界假设(closed-world assumption),即未观测事实或者无法推断的事实为假。
具体的,每条训练数据包含 <code>content, questions字段,其中content是题干,questions为具体的子问题。questions是一个子问题列表,每个子问题包括options和answer字段,其中options是一个列表,包含具体的选项,按照ABCDE顺序排列,answer是标准答案。
数据集格式如下:
{ 'id': 'round_train_data_001',
'problem': '有一个计算阶乘的递归程序。该程序根据给定的数值计算其阶乘。以下是其工作原理:\n\n当数字是0时,阶乘是1。\n对于任何大于0的数字,其阶乘是该数字乘以其前一个数字的阶乘。\n根据上述规则,回答以下选择题:',
'questions': [
{ 'question': '选择题 1:\n3的阶乘是多少?\n',
'options': ('3', '6', '9', '12'),
'answer': 'B'},
{ 'question': '选择题 2:\n8的阶乘是多少?\n',
'options': ('5040', '40320', '362880', '100000'),
'answer': 'B'},
{ 'question': '选择题 3:\n4的阶乘是多少?\n',
'options': ('16', '20', '24', '28'),
'answer': 'C'},
{ 'question': '选择题 4:\n3的阶乘是9吗?\n',
'options': ('是', '否'),
'answer': 'B'}
]
}
测试集中不带answer字段,待推理阶段输出测试结果为提交文件。
本次评估指标为所有子问题的回答准确率,每个子问题权重相同。满分为1。
学习计划

Task1——跑通baseline
调用大模型api,推理输出结果文件提交评分
Task1用的baseline代码讲解见task2。——数据处理、多线程调用api等。
采用qwen1.5-1.8b-chat。灵积平台有其他限时免费开放的模型,如qwen2-1.5b-instruct。
申领大模型key:https://dashscope.console.aliyun.com/apiKey
(开通 DashScope(阿里云灵积平台) 可以获赠一些其他模型的限时免费使用额度,大部分有效期为30天。)算力平台使用魔搭notebook。选择CPU环境,此task是调用大模型的api进行访问,利用多线程提高效率。
结果
不做修改直接运行baseline,由于网络或其他原因,部分题目丢失,其子问题都默认选A。分值只有0.3494。
听群内说72B大模型能到0.8+,而7B加微调也能到0.8。
Task2——baseline代码解析
对task1的baseline代码进行讲解https://datawhaler.feishu.cn/wiki/CvNRwdXDHimxJskZaArcvYqDnIc
整体代码介绍
整体代码主要包括答案生成和纠错与结果文件生成两个大模块。
答案生成部分包括大模型的处理函数、大模型返回结果抽取、多线程处理及答案生成的启动。
这里代码核心是大模型部分,动手能力强的小伙伴可以从这里入手开始自己的上分之路~为了保证整体代码性能使用多线程处理请求。
纠错与结果生成部分存在的目的是由于目前使用了api调用在线开源大模型,因为网络、模型能力等原因会导致有一些结果会出现缺失。(比如大模型回答时,没有明确给出ABCD的结果,而返回的空值。也有时因为网络retry模块机会使用结束后,依然没有提取到结果会跳过某个问题。)
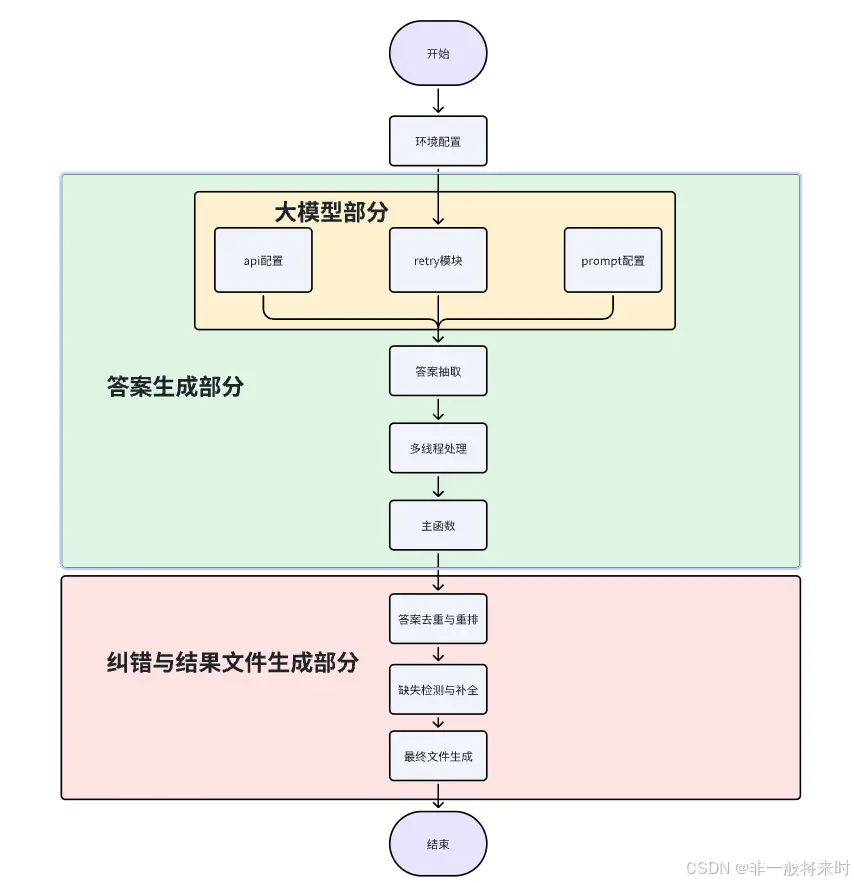
部分核心代码
注意以下为ipynb的内容,按顺序执行,启动函数后,才逐步执行去重、纠错、补错、存储结果文件(略)。
——注意官方代码与后台评分机制契合,无需过多在意数据构成和保存方式。可自己加入一些策略上分,最后保存内容符合后台评分所需即可。
环境
<code>!pip install scipy openai tiktoken retry dashscope loguru
# 注意:这里需要填入阿里云灵积平台申请的key。
dashscope.api_key="sk-"code>
import包略……
api调用大模型
def call_qwen_api(MODEL_NAME, query):
# 这里采用dashscope的api调用模型推理,通过http传输的json封装返回结果
messages = [
{ 'role': 'user', 'content': query}]
response = dashscope.Generation.call(
MODEL_NAME,
messages=messages,
result_format='message', # set the result is message format.code>
)
if response.status_code == HTTPStatus.OK:
print(response)
return response['output']['choices'][0]['message']['content']
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
raise Exception()
api_retry 这个函数是当大模型调用api时可能会导致出错中断的问题,为了保证每个问题都被大模型处理过,我们需要设置一个反复尝试的函数。# 最大尝试次数5次 # 再次尝试等待时间 60秒。如果出现错误我们存储到日志文件。
def api_retry(MODEL_NAME, query):
# 最大尝试次数
max_retries = 5
# 再次尝试等待时间
retry_delay = 60 # in seconds
attempts = 0
while attempts < max_retries:
try:
return call_qwen_api(MODEL_NAME, query)
except Exception as e:
attempts += 1
if attempts < max_retries:
logger.warning(f"Attempt { attempts} failed for text: { query}. Retrying in { retry_delay} seconds...")
time.sleep(retry_delay)
else:
logger.error(f"All { max_retries} attempts failed for text: { query}. Error: { e}")
raise
get_prompt prompt的模版函数,通过字符串处理的方式拼接完整的prompt(markdown格式的)
# 这里定义了prompt推理模版
def get_prompt(problem, question, options):
# 枚举生成对应格式的选项文本
options = '\n'.join(f"{ 'ABCDEFG'[i]}. { o}" for i, o in enumerate(options))
# prompt模板,字符串拼接,格式化
prompt = f"""你是一个逻辑推理专家,擅长解决逻辑推理问题。以下是一个逻辑推理的题目,形式为单项选择题。所有的问题都是(close-world assumption)闭世界假设,即未观测事实都为假。请逐步分析问题并在最后一行输出答案,最后一行的格式为"答案是:A"。题目如下:
### 题目:
{ problem}
### 问题:
{ question}
{ options}
"""
# print(prompt)
return prompt
抽取大模型回答答案
通过抽取函数可以将大语言模型生成的结果抽取成答案对应的选项,这里的匹配原则和prompt呼应。可以看到prompt要求【最后一行的格式为"答案是:A"】这样的规范,那么采用正则表达式re.compile方法匹配到答案对应的选项。当匹配为空时,默认选"A"。
# 这里使用extract抽取模获得抽取的结果
def extract(input_text):
ans_pattern = re.compile(r"答案是:(.)", re.S)
problems = ans_pattern.findall(input_text)
# print(problems)
if(problems == ''):
return 'A'
return problems[0]
多线程发送api调用
def process_datas(datas,MODEL_NAME):
results = []
# 定义线程池 选择16线程
with ThreadPoolExecutor(max_workers=16) as executor:
# 这里我们使用future_data 存储每个线程的数据
future_data = { }
# 这里的lens记录了调用api的次数,也就是我们每个问题背景下的所有子问题之和。
lens = 0
# 送入多线程任务
# 这里每个data下是一个问题背景,其中包含多个子问题。
for data in tqdm(datas, desc="Submitting tasks", total=len(datas)):code>
problem = data['problem']
# 这里面我们用enumerate方法每次循环得到问题的序号id和实际的问题。
for id,question in enumerate(data['questions']):
prompt = get_prompt(problem,
question['question'],
question['options'],
)
# 这里送入线程池等待处理,使用api_retry,向api_retry传入MODEL_NAME, prompt参数
# future是Futrue对象,代表异步任务
future = executor.submit(api_retry, MODEL_NAME, prompt)
# 每个线程我们存储对应的json问题数据以及问题序号id,这样我们就能定位出执行的是哪个子问题
future_data[future] = (data,id)
time.sleep(0.6) # 控制每0.6秒提交一个任务 防止接口超过并发数
lens += 1
# 处理多线程任务
for future in tqdm(as_completed(future_data), total=lens, desc="Processing tasks"):code>
# print('data',data)
# 取出每个线程中的字典数据及对应的问题id
data = future_data[future][0]
problem_id = future_data[future][1]
try:
# result()获取api运行结果,如果future未完成会阻塞
res = future.result()
# 抽取大语言模型返回结果
extract_response = extract(res)
# print('res',extract_response)
# 装入answer字段
data['questions'][problem_id]['answer'] = extract_response
# 在结果列表中新增数据字典
results.append(data)
# print('data',data)
except Exception as e:
logger.error(f"Failed to process text: { data}. Error: { e}")
return results
启动函数
读取数据集转为json,然后调用process_datas函数(根据数据构造prompt、多线程发起api请求、抽取回答最终返回list)。
回答去重与排序
可能是网络延迟与重试机制导致有重复。
将一个问题背景下的所有问题存入同一个字典,并按id序号排序。
def has_complete_answer(questions):
# 这里假设完整答案的判断逻辑是:每个question都有一个'answer'键
for question in questions:
if 'answer' not in question:
return False
return True
def filter_problems(data):
result = []
problem_set = set()
for item in data:
# print('处理的item' ,item)
problem = item['problem']
if problem in problem_set:
# 找到已存在的字典
for existing_item in result:
if existing_item['problem'] == problem:
# 如果当前字典有完整答案,替换已存在的字典
if has_complete_answer(item['questions']):
existing_item['questions'] = item['questions']
existing_item['id'] = item['id']
break
else:
# 如果当前字典有完整答案,添加到结果列表
if has_complete_answer(item['questions']):
result.append(item)
problem_set.add(problem)
return result
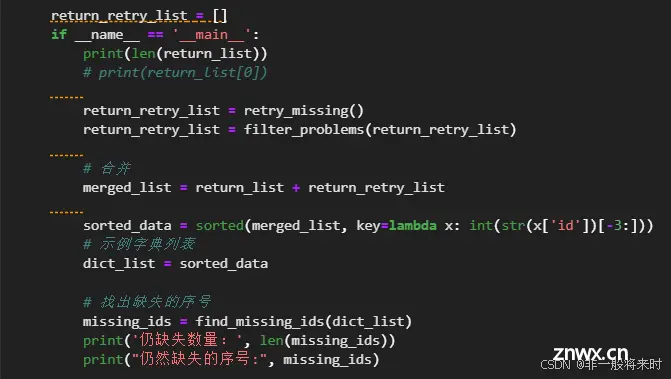
return_list = filter_problems(return_list)
# 排序工作 通过id字段后三位代表序号
sorted_data = sorted(return_list, key=lambda x: int(str(x['id'])[-3:]))
print(sorted_data)
纠错
找到丢失的问题。
def find_missing_ids(dict_list):
# 提取所有序号(后三位即可,一共500个)
extracted_ids = { int(d['id'][-3:]) for d in dict_list}
# 创建0-500的序号集合
all_ids = set(range(500))
# 找出缺失的序号
missing_ids = all_ids - extracted_ids
return sorted(missing_ids)
# 示例字典列表
dict_list = sorted_data
# 找出缺失的序号
missing_ids = find_missing_ids(dict_list)
print("缺失的序号:", missing_ids)
len(missing_ids)
补错
针对空缺的列表我们进行补错,让每个answer字段默认填充为A(就全蒙A,效果肯定好不了哪里去),也可考虑重新发起请求处理一遍。
data = []
with open('round1_test_data.jsonl') as reader:
for id,line in enumerate(reader):
if(id in missing_ids):
sample = json.loads(line)
for question in sample['questions']:
question['answer'] = 'A'
sorted_data.append(sample)
sorted_data = sorted(sorted_data, key=lambda x: int(str(x['id'])[-3:]))
Task3——lora微调、vllm部署、多路投票
baseline2涉及内容:lora微调、vllm加速、多路投票
操作流程:git代码、lora微调、vllm加速保持部署、baseline2main推理d(evaluate评估-按需)、提交文件。
官方教程文档
https://datawhaler.feishu.cn/wiki/TyQZw9lZSiN1V5kTKIocgJOvnag
此task的代码和数据文件:
https://www.modelscope.cn/datasets/bald0wang/Complex_reasoning_ability_assessment_qwen2-7b-lora/files
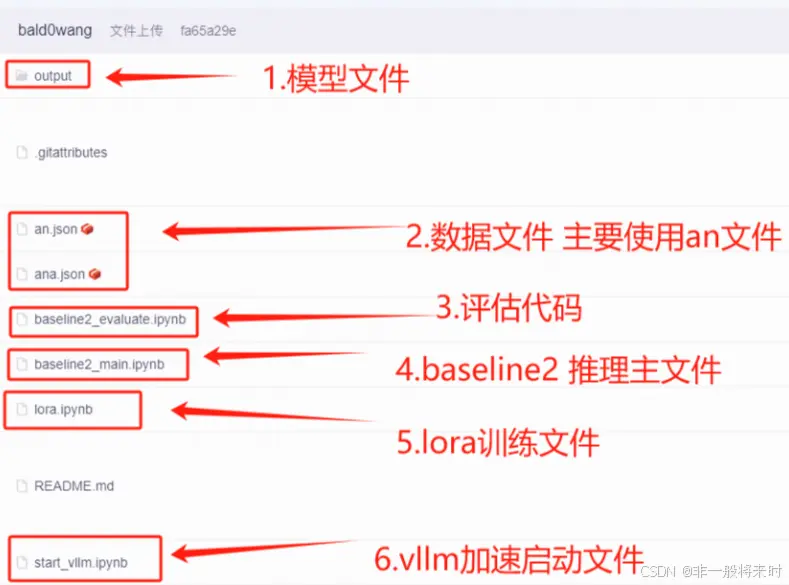
lora
<code>(lora笔记单独整理在csdn学习笔记)
peft的lora。
预处理微调数据(满足qwen大模型输入输出的数据格式)、配置LoraConfig、获取PeftModel训练、推理测试、合并保存模型权重和tokenizer等。
vllm部署
记得确保有足够的显存。notebook的GPU环境,如果先lora再使用vllm部署记得重启notebook释放显存,否则影响vllm启动。(——重启前记得保存模型。)
这里实测不管用,,,只能restart kernel释放显存。
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{ DEVICE}:{ DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
vLLM(Virtual Large Language Model)是一个由伯克利大学LMSYS组织开源的大规模语言模型高速推理框架。它的设计目标是在实时应用场景中大幅提升语言模型服务的吞吐量和内存使用效率。vLLM的特点包括易于使用、与Hugging Face等流行工具无缝集成以及高效的性能。
打开start_vllm.ipynb,执行后我们通过vllm的类openai接口成功将微调后的模型部署到8000端口。
即执行以下命令行启动vllm:
!python -m vllm.entrypoints.openai.api_server --model ./merged_model_an --served-model-name Qwen2-7B-Instruct-lora --max-model-len=4096
!python -m vllm.entrypoints.openai.api_server
这是一个 Python 命令,用于启动 VLLM (Very Large Language Model) 项目中的 OpenAI API 服务器入口点。
指定了使用 OpenAI 的 API 规范来部署和调用这个 VLLM 模型。
可以很容易地被其他遵循 OpenAI API 的应用程序所访问和使用。
还有其他规范:fastapi、http_json(HTTP/JSON原生)、cli(命令行交互式)、自定义。model ./merged_model_an
这个参数指定了要加载的模型路径,在本例中是
./merged_model_an。这个路径对应于之前你使用 PEFT 库保存模型的位置。served-model-name Qwen2-7B-Instruct-lora
这个参数指定了要为这个模型设置的名称,在本例中是 Qwen2-7B-Instruct-lora。这是一个自定义的名称,用于在 API 服务中标识这个模型。max-model-len=4096
这个参数设置了模型能够处理的最大输入长度,在本例中是 4096 个 token。这个值根据你的模型的最大输入长度进行设置,以确保模型能够正确处理输入。
之前lora保存模型保存到了
./merged_model_an
# 模型合并存储
new_model_directory = "./merged_model_an"
merged_model = model.merge_and_unload()
# 将权重保存为safetensors格式的权重, 且每个权重文件最大不超过2GB(2048MB)
merged_model.save_pretrained(new_model_directory, max_shard_size="2048MB", >safe_serialization=True)code>
save_pretrained()————保存模型的文件名是由 save_pretrained() 函数自动生成的,无需手动指定文件名
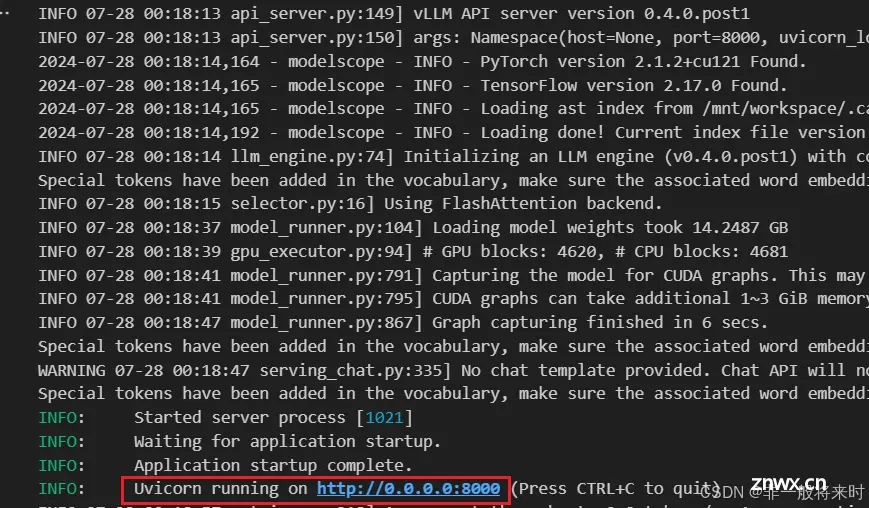
执行后会部署在本地http://0.0.0.0:8000,修改原来的<code>call_qwen_api代码,通过openAI库的api,即可调用这个经过微调的模型了!
def call_qwen_api(MODEL_NAME, query):
# 这里采用dashscope的api调用模型推理,通过http传输的json封装返回结果
client = OpenAI(
base_url="http://localhost:8000/v1",code>
api_key="sk-xxx", # 随便填写,只是为了通过接口参数校验code>
)
completion = client.chat.completions.create(
model=MODEL_NAME,
messages=[
# {'role':'system','content':'你是一个解决推理任务的专家,你需要分析出问题中的每个实体以及响应关系。然后根据问题一步步推理出结果。并且给出正确的结论。'},
{ "role": "user", "content": query}
]
)
return completion.choices[0].message.content
多路投票
思路
所谓的“多路召回策略”就是指采用不同的策略、特征或者简单模型,分别召回一部分候选集,然后再把这些候选集混合在一起后供后续排序模型使用的策略。
此项目就是调用多次api(同一个模型、同输入)。
实现
设计投票函数:
通过三次结果推理,将选择答案最多的结果作为最终结果:
def most_frequent_char(char1, char2, char3):
# 创建一个字典来存储每个字符的出现次数
frequency = { char1: 0, char2: 0, char3: 0}
# 增加每个字符的出现次数
frequency[char1] += 1
frequency[char2] += 1
frequency[char3] += 1
# 找到出现次数最多的字符
most_frequent = max(frequency, key=frequency.get)
return most_frequent
设计多路LLM:
改写process函数,三次调用llm,做出现次数统计,最终返回投票数最多的结果。
def process_datas(datas,MODEL_NAME):
results = []
# 送入多线程任务
for data in tqdm(datas, desc="Submitting tasks", total=len(datas)):code>
problem = data['problem']
for id,question in enumerate(data['questions']):
prompt = get_prompt(problem,
question['question'],
question['options'],
)
# 统一使用llm 三次调用
res,res1,res2 = api_retry(MODEL_NAME, prompt),api_retry(MODEL_NAME, prompt),api_retry(MODEL_NAME, prompt)
# 统一做结果抽取
extract_response,extract_response1,extract_response2 = extract(res),extract(res1),extract(res2)
# 通过投票函数获取最终结果并返回
ans = most_frequent_char(extract_response,extract_response1,extract_response2)
data['questions'][id]['answer'] = ans
results.append(data)
return results
多路投票的整体推理代码在baseline01.ipynb。当微调结束后,启动vllm后,运行baseline01.ipynb就可以可以推理完成后直接返回最终结果。提交’upload.jsonl’文件即可。
总结
官方文档统计:
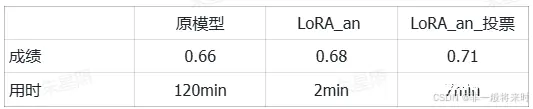
以上原模型是所有样本没缺失,都正常请求的分数。
关键点:
prompt工程(此文档教程还未涉及,可以考虑从此方面上分)微调vllm加速多路投票
todo整理
以上基本都是官方教程和知识点笔记。待加入自己的上分想法。todo
当前上分记录
修改补错代码,发现没什么用,模型太低级了,不如解决本质问题,换个大点的模型会解决确实问题。
根据task3微调+投票,然后自己更改微调参数多训练几轮。能到0.78+
具体
qwen1.5-1.8b-chat替换为qwen2-1.5b-instruct,分数无明显变化。主要变化源自缺失的问题数量。
前者缺失326,分数0.3494;后者缺失322,分数0.3592。
prompt
可以考虑在prompt中说明给出的是选项序号。因为审查数据发现有个答案抽取是F,选项一共四个不可能有F,然后正确选项内容是F开头的人名,我估计回答是选项内容而不是序号了。
task2源码了解:
tqdm进度条
线程池,as_completed(xxx)
代码
纠错修改:再提交一次缺失的问题。如果还没有成功再默认选A。
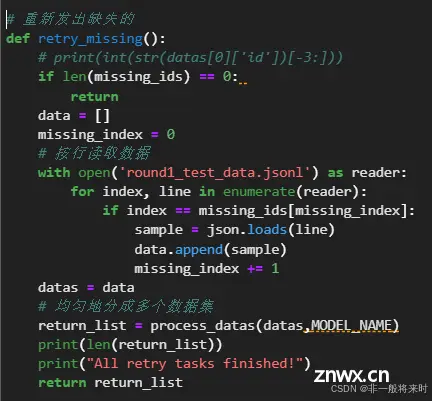
注意

429超出限流QPM。查手册发现是60QPM的服务,而sleep(0.6)是100QPM了。可以考虑增大sleep时间.sleep(1)。也可以考虑换一个限流更高的模型。
接口计量手册

改为sleep(1)后,429报错明显减少。
可以试一下限时免费的qwen-1.8b-chat,其QPM120。
查日志、加打印
主要还是因为模型太小,很难按照要求输出回答然后抽取匹配到答案。再就是有些会抛出错误(未知,打印日志的error为空字符串,奇怪得很)导致缺失。正常情况下不会出现缺失。
待换task3用其他模型跑。
task3跑lora,要用<code>an.json数据集,ana.json微调后,大模型输出太多内容,baseline02_main.ipynb推理阶段非常耗时!前者10分钟,后者n小时。
可以增大epoch或修改其他参数。
TrainingArguments参数可参考
https://blog.csdn.net/duzm200542901104/article/details/132762582
后续上分思路
其他思路尝试:
记得文件大小不超过50GB、运行显存32GB,基本20B以下模型
推理时间要3h内
【数据集角度】
train数据集有错误数据,需要清洗。ana数据集(Qwen2-72B回答的带分析过程的train题目)的question为1024,比原1300+少,官方抛去了错误回答。
test数据集中有人也无法回答的问题(缺少必要信息如id:328题,需要RAG加入球队比赛结果信息,但是像这样针对每个题找特定的信息做RAG,是不现实的。)
扩展数据-开源的、gpt生成,扩展question、problem。
【prompt】
prompt引导选选项。
针对回答错的题目改prompt
system-prompt
数据集step中加入闭世界假设的反例分析,或者prompt中加入,如*由原文只说吃了花生,但并不能得出他俩喜欢花生*。
目前prompt新增强调:“未提到则不成立”,但第一题花生题推断错误还是选错(之前情况也没选对)。
或许pormpt改为“无法推断即为假”比较好一点?☆☆☆☆☆——确实很关键,改之后对了,之前好几次都不对。
【借鉴】
交流会prompt提到https://www.promptingguide.ai/zh/applications/workplace_casestudy
思维链?
【rag】
由于训练集和测试集共性很大(甚至有重复题目(其实表述不太一样)),采用rag_ana。但是和an微调不搭配。an也不能stepByStep,所以也用ana微调。(ana是更高级模型的输出。
采用GTE文本向量(自定义类继承langchain向量模型基类Embeddings)+chroma(langchain集成的)。最后结果0.66+反而比微调降低了不少。推测模型太小rag的prompt复杂了。还是要从数据集、prompt角度下手。
用的GTE(起初想用新的sota-acge但是网络连接不到huggingface.io就算了):https://modelscope.cn/models/iic/nlp_gte_sentence-embedding_chinese-base
另外批量推理应该是还没跑起来,推理很慢。:
【推理】
vllm批量推理:https://zhuanlan.zhihu.com/p/676635585?utm_campaign=shareopn&utm_medium=social&utm_psn=1802473078393024512&utm_source=wechat_session
、提高KVcache命中率
为了使用批量推理,不再使用openaiAPI,而是直接调用模型。
起初3路投票,batch是3路加了rag的prompt,rag k=3,每路用不同召回内容,prompt不一样。但是推理太慢,于是最后取消了多路投票,而是一个problem下所有question作为一个batch(size在1~4左右)、预估时间减短一些了(主要因为取消了三路投票,batchSize基本无变化)。而且由于出现了复读问题,调整max_tokens等部署参数,也适当减少了一些时间。批量应该加多一点。
【其他】
正则匹配仍有不合规答案,如rag方案中出现19个非预期答案(2汉字、17换行,应该不是被max_tokens截断了,否则直接匹配不到默认为A),外加一个四选项选了E的。
换模型,可大模型量化,注意模型微调输入模板不一样,看说明。
测试集格式有个例格式问题,修改。
同时改微调的prompt、微调用了system,推理也加上。降低温度。恢复多路,增大batch含3个problem(加上三路投票后question在10~30左右)。【分低了】
tip:批量在10时有明显加速。
第一次交流会经验分享记录(看的录播大致记一下,感谢各位大佬)
他人分享经验:
微调数据集小,对于小模型可能更有效。
量化int8还可以,int4就掉精度了。
大模型加量化存储能类似小模型,但是推理速度慢。
数据集题目好像可以分下类,有的是假设封闭性有的是数学逻辑。针对性写prompt,然后单独扩充某一类问题数据集应该也会有效。
回答不好的数据集有共性,特别复杂。
目前训练集测试集很像、数据量不大,所以可以不用外接数据库,直接文本相似度。但是如果复赛增加新题目或者要引入外部数据,那还要搞一个向量数据库。
文本太长推理会变慢。
微调时加入rag、prompt如何?——建议微调也加入好的prompt,会改变概率分布
如果说想外接一个模型辅助调整prompt,两个模型对话。但是文件上传有限制。可以考虑一个基座、两个lora对应两个模型,lora文件存储不大的。
ana微调结果慢的原因:vllm启动方式有问题,一次只回答一个prompt。不如不用api直接给model批量prompt。或者直接做成列表往vllm送?
问题转换成数学符号语言应该会好一点。
最后可以提交更大的模型、task4有模型榜单。
记得更新本地
个人note:
再跑模型记得task替换lora和baseline2两个代码文件、
训练参数:
改epoch或最大steps、合并时的lora-ckpt地址
如果换微调数据集要改数据集path:ana.json、lora_model_path、改两个new_model_dir、改vllm的new_model_dir、改抽取函数
上分之路
小模型,多线程、符合qpm、纠错。
换7B模型。
微调
ana,学习大模型,删去错误回答。
an,减少时间,但不符合cot。
vllm,openaiAPI部署。
多路投票。2epoch:0.78+。
ana微调+anaRAG。chroma、GTE。分降低了。
改离线批量推理;取消三路投票换批量方式。
prompt选序号,封闭世界概念强调。prompt修改调优。
测试数据集有无法回答的问题,要十分精准的外部数据才有可能。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。