Datawhale AI夏令营(第三期)逻辑推理TASK1笔记
Uniproton 2024-08-19 08:01:02 阅读 100
各位同学大家好,我是第三期的学员Proton,我本身非计算机专业。
但是学业过程中用到大量计算机知识,因此正在艰难自学的过程中。
看到很多非计算机专业的同学与朋友。
对于本次夏令营的实践内容有疑问,包括TASK1究竟在做什么充满疑惑,
因此分享一下我的一些理解。
专业大佬可以直接离去,不能浪费大佬们的时间(膜拜大佬)
一、本次夏令营究竟在做什么?
作为一个有一点python语言基础,但是从未在运行代码层面去使用过大模型的同学,这是一次很好去了解如何调用大模型来解决自身问题的机会。
为什么我在这里说的是使用和调用,是因为大部分情况下,非相关专业的同学不可能自身从0开始去训练一个大模型出来,或者说手搓敲代码敲出来。不仅有专业知识上的鸿沟,也有训练硬件的不足。
所以可能存在的需要纠正的第一个误区就是:本次夏令营不是教你如何手搓大模型的,我们大部分人也不具有这个能力。
那么我们究竟在做什么?
如果说,将大模型比作一把枪,或许可以帮助我们理解:
① 在参加本次夏令营前,我们应该都使用过ChatGPT或者是国内的一些大模型。
就好比我们知道拿住枪,瞄准,扣动扳机,就能达到我们射击的目的。
② 我们的夏令营则是在告诉我们(指初次接触的同学们),我们如何通过代码,来调用网络上公开免费开源的模型,通过调节参数和给予适当的prompt(提示词)来解决我们需要的问题。
即定制化与应用(当然距离形成软件或真正意义上的定制化还有很大的距离)
就好比教我们如何真正地在特殊的场景挑一次枪,用一次枪,保养枪。
③ 而我们之前提到的误区,手搓大模型就好比让我们从材料开始制造枪
对于大部分同学与朋友来说,没有必要也不大可能。
二、通过什么方式去学会定制与应用
这就是引入这个比赛的原因
很多同学搞不清,我们这个到底是比赛还是夏令营,比赛任务到底是夏令营中的比赛还是其他东西
①首先,这个比赛是独立的,面对全国乃至全球的,是有真正的大佬在其中,训练模型,调整模型,改进模型的。
②我们的夏令营是把这个比赛作为参加者的实践过程,带给大家。
当码农必须要多敲代码,才能成为好码农。最好的学习就是在实践过程中学习。
那么这次比赛的就是很好的一个实践。
简单概括这个比赛就是:主办方出了一套卷子
参赛者需要用自主选择调试训练的模型,去写卷子
主办方在给你的卷子去打分数
这就是一次很好的,通过选择、调试、训练合适的模型,去解决一个实际问题的过程。
那同学们说:我还不会啊,哪里可以搞到模型,怎么去调参,去训练?我没基础。
因此夏令营就给出了TASK1的任务,给出了一个baseline
你要学保养枪,选择枪,改造枪,就得先学会用枪。
第一次课就是为了让我们亲手去打开一个能够解决比赛问题的写好的代码,去跑出一个结果(做出一份卷子),给主办方改一次。
就像跑拉力赛,你先走一遍赛道,到达过一次终点,再去考虑怎么更快,更安全地参加比赛。
三、TASK1要我们在做什么?
代码的部分有python基础的同学,自然看的懂,我这里只分享baseline的逻辑,以及学习baseline有什么用。
如果说完全看不懂代码的同学,或者一知半解的同学可以看看我的分享,去理解思路。
第一步:找到答题的学生和考场
做卷子需要答题的学生,我们解决这个比赛问题需要找到一个模型。
我们去申领的大模型API就是找到了一个学生。
这个学生是阿里训练出来的。
我们用API在自己的程序代码中用,相当于找他要了个分身,来帮我们解决问题。
找到了学生还要给他答题的场地,我们都知道大模型运行过程中需要显卡设备,代码运行需要相关的环境配置,我们的设备与设备中的环境可能不足以满足它的要求。
怎么办?好办,我没有就去租。
魔搭notebook就相当于租给我们一个考场,不过是免费和公用的。
第二步:拿到考卷
ok考场和考生有了,可以开始答题了吧,于是我们下载了两个文件,一个是Round1_test_data.jsonl,这个文件就是考卷。
baseline01.ipynb里面的代码,则好比是夏令营给我们的一些答题思路和模板,这个学生要在这个模板下去解答问题,因为他不够智能,你得告诉他,答题该用什么格式,遇到不会写的题怎么办等等。
第三步:写试卷
就是我们运行这个程序,我们已经告诉他该怎么写了,那剩下的事情就是等他写完,这个过程就是在运行代码,调用远在千里之外的阿里大模型,来做题目。做题目需要时间,而且做题的只是一个分身,它要一心多用,这就是我们等待这么久的原因。
第四步:提交试卷,获得分数
运行完毕,也就是考生写完题目,保存下来的upload.jsonl就是我们的答卷,我们提交给主办方,它就会给我们一个分数。
四、baseline里面的代码在做什么?
接下来,我们来理解一下baseline做了一些什么
①第一个大块pip,是在安装我们整个程序需要的一个能力,相当于在给这个学生灌输知识体系
②第二个部分import了许多库,就是告诉学生我们要用到这些知识
③这里对API进行了调用,告诉学生,你要让这个大模型来上你的身,用它的脑子来解决问题

④api_retry就是告诉学生,如果这个大模型的脑子没反应,你就多叫它几次试试
⑤call_qwen_api是在确认这个学生与阿里的大模型的信息传输方式,以及用哪种大模型
⑥这里是一个重点,这的功能是在告诉这个被调用过来的大模型,你今天是个什么身份,要去解决什么问题,怎么理解题目,怎么回答问题。
也就是给大模型prompt(提示词),让他更好的完成你布置的任务。一定程度上,它完成任务的效果取决于你给他的prompt,如果你没有相关的知识基础,不会挑选模型,换模型,调节模型的参数。
未来最大的分数提升,就是在prompt的修改上,通过准确、有效、完善且具有识别度的提示内容,使它的能力提升。在这次比赛中,你告诉它,它是一个逻辑推理专家,其他问题就是别的提示词。
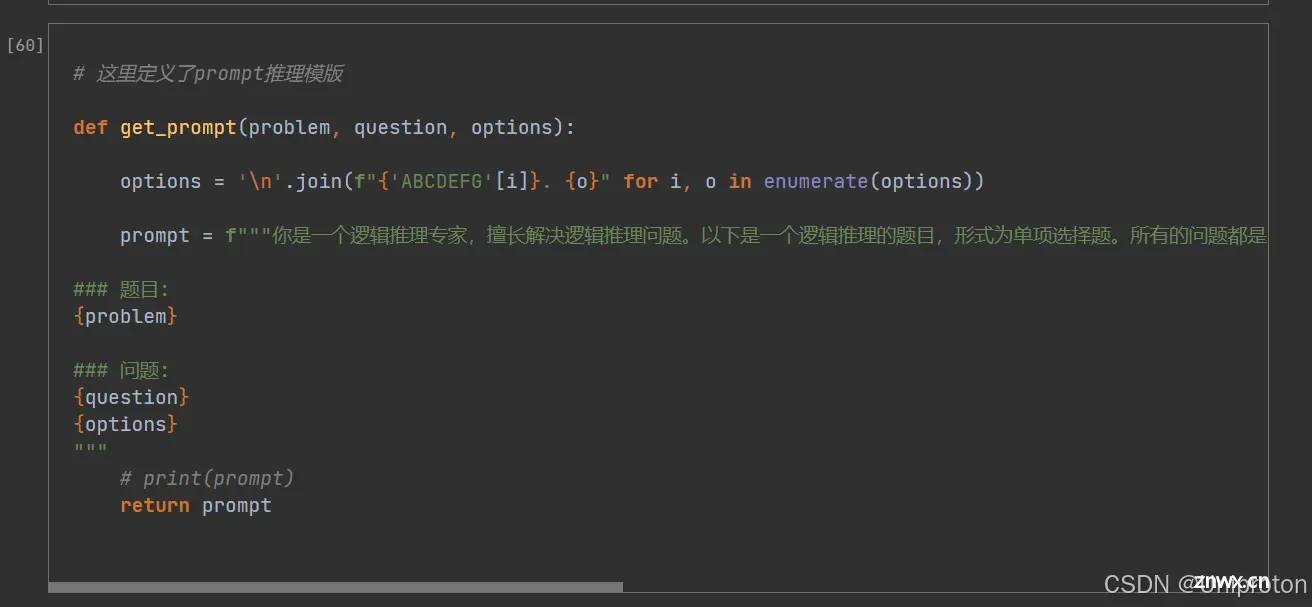
后续的内容,就是一些功能模块,时间原因我简要说明不再代码一一列举,详细的可以观看第一次课程的回放,专业助教的代码讲解。
包括给它一个例题,告诉它该怎么答题。
拿到一份卷子,怎么把里面杂乱的内容,整理成大模型可以理解的题目格式
给它一份包含答案的训练卷子,让它自己写,并对照答案订正,自我训练
包括完成答题之后,输出的格式应该是怎么样的
判断自己有多少道题不会,再给这些题目蒙一个答案(baseline中的代码是让不会的都选A)
最后提交答卷。
五、我们能做怎样的改进
没有相关基础的同学,主要还是跟着课程看看夏令营后续叫我们怎么用新的baseline去答卷,怎么修改prompt让它有更好的表现。
以及大佬们怎么去让自己的分数更高。
比如换其他公司训练出来的开源模型,用本地自己训练的小模型,调整模型里的参数(总之就是换个脑子)等等。
遇到不会写的题目,用别的“科学方法”去蒙一个,还是说,尝试去识别不会的原因,再重复做等等。
总而言之,就是想方设法让我们交出的卷子分数更高,也就是我们将大模型的定制化,更专业,更成功,更智能。
非常感谢您能看到这里(应该没有几个人,甚至没有人),我也只是一个有一点点python基础的小白,上述解释和理解中可能有许多错误与不到位的地方,还请大家多多批评指正,也希望能像优秀的群友们学习,学到更多的知识,一同拥抱智能时代的到来!
上一篇: 程序 · 杂谈 | DeepSeek发布最强开源数学定理证明模型
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。